Na primeira parte, nos familiarizamos com os métodos de adaptação de domínio por meio de aprendizado profundo. Conversamos sobre os principais conjuntos de dados, bem como abordagens não-geradoras baseadas em discrepâncias e baseadas em contraditórios. Esses métodos funcionam bem para algumas tarefas. E desta vez, analisaremos os métodos mais complexos e promissores baseados em adversários: modelos generativos, bem como algoritmos que mostram os melhores resultados no conjunto de dados VisDA (adaptações de dados sintéticos a fotos reais).

Modelos generativos
A base dessa abordagem é a capacidade do GAN de gerar dados a partir da distribuição necessária. Graças a essa propriedade, você pode obter a quantidade certa de dados sintéticos e usá-los para treinamento. A idéia principal dos métodos da família de modelos generativos é gerar dados usando o domínio de origem o mais semelhante possível aos representantes do domínio de destino. Assim, os novos dados sintéticos terão os mesmos rótulos que os representantes do domínio original com base nos quais foram obtidos. Em seguida, o modelo para o domínio de destino é simplesmente treinado nesses dados gerados.
Introduzido na ICML-2018, o método CyCADA: Adaptação de Domínio Adversarial Consistente em Ciclo ( código ) é um membro representativo da família de modelos generativos. Ele combina várias abordagens bem-sucedidas de GANs e adaptação de domínio. Uma parte importante disso é o uso da perda de consistência do ciclo, introduzida pela primeira vez em um artigo no CycleGAN . A idéia da perda de consistência do ciclo é que a imagem obtida pela geração do domínio de origem para o destino, seguida pela transformação inversa, esteja próxima da imagem inicial. Além disso, o CyCADA inclui adaptação no nível de pixel e no nível de representações vetoriais, além de perda semântica para salvar a estrutura na imagem gerada.
Vamos fT e fS - redes para os domínios de destino e de origem, respectivamente, XT e XS - domínios de destino e de origem, YS - marcação no domínio de origem, GS−>T e GT−>S - geradores da origem ao domínio de destino e vice-versa, DT e DS - discriminadores de pertencer aos domínios de destino e de origem, respectivamente. Então a função de perda, que é minimizada no CyCADA, é a soma de seis funções de perda (o esquema de treinamento com números de perda é apresentado abaixo):
- Ltarefa(fT,GS−>T(XS),YS) - classificação do modelo fT nos dados gerados e nos pseudo-rótulos do domínio de origem.
- LGAN(GS−>T,DT,XT,XS) - perda adversária para treinamento de geradores GS−>T .
- LGAN(GT−>S,DS,XS,XT) - perda adversária para treinamento de geradores GT−>S .
- Lcyc(GS−>T,GT−>S,XS,XT) (perda de consistência do ciclo) - L1 , garantindo que as imagens obtidas de GS−>T e GT−>S estará perto.
- LGAN(fT,Dfeat,fS(GS−>T(XS)),XT) - perda antagônica para representações vetoriais fT e fS nos dados gerados (semelhante ao que é usado no ADDA).
- Lsem(GS−>T,GT−>S,XS,XT,fS) (perda de consistência semântica) - L1 perda, responsável pelo fato de que fS funcionará da mesma forma que nas imagens obtidas de GS−>T ambos de GT−>S .
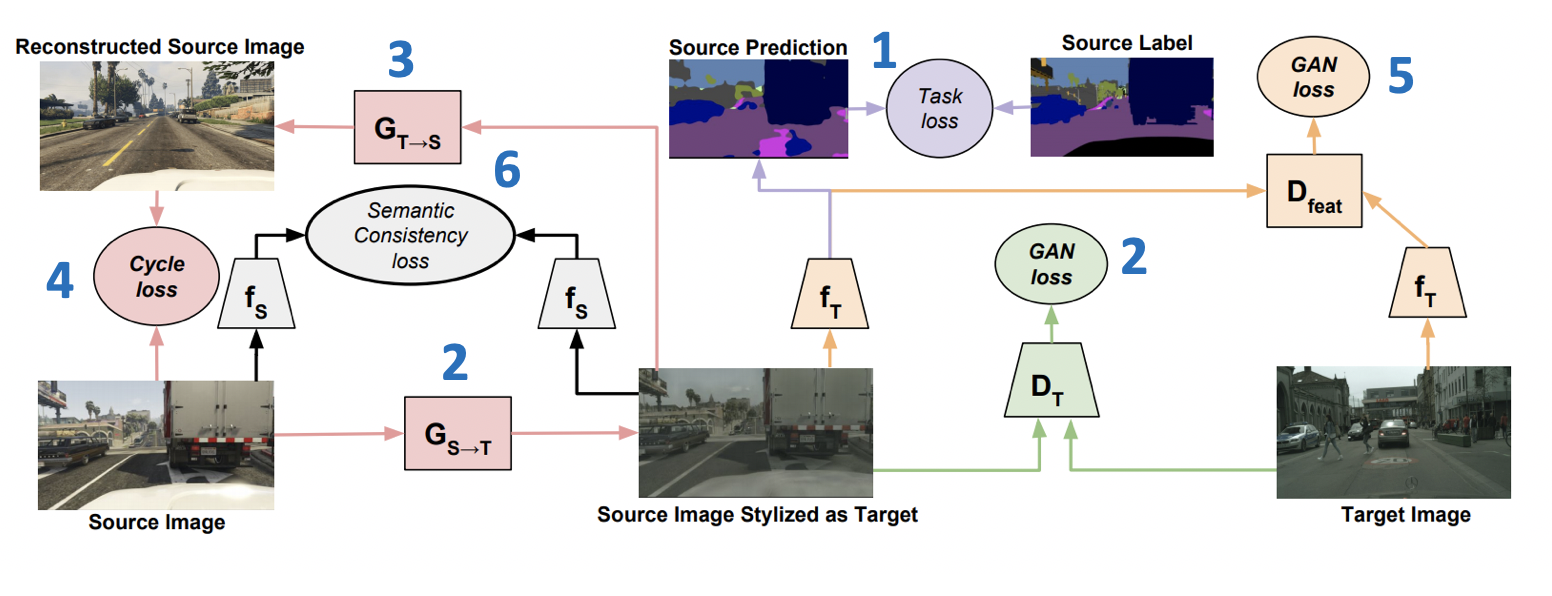
Resultados do CyCADA:
- Em um par de domínios digitais do USPS -> MNIST: 95,7%.
- Na tarefa de segmentação GTA 5 -> Cityscapes: IoU média = 39,5%.
Como parte da abordagem, Gerar para adaptar: alinhar domínios usando redes adversas generativas ( código ) treina esse gerador G para que na saída produza imagens próximas ao domínio original. Tais G permite converter dados do domínio de destino e aplicar o classificador treinado nos dados marcados do domínio de origem a eles.
Para treinar esse gerador, os autores usam um discriminador modificado D do artigo AC-GAN . Característica deste D consiste no fato de que ele não apenas responde 1 se a entrada veio do domínio de origem e 0, caso contrário, mas também no caso de uma resposta positiva, ele classifica os dados de entrada de acordo com as classes do domínio de origem.
Nós denotamos F como uma rede convolucional que produz uma representação vetorial de uma imagem, C - um classificador que funciona em um vetor derivado de F . Algoritmos de aprendizagem e inferência:
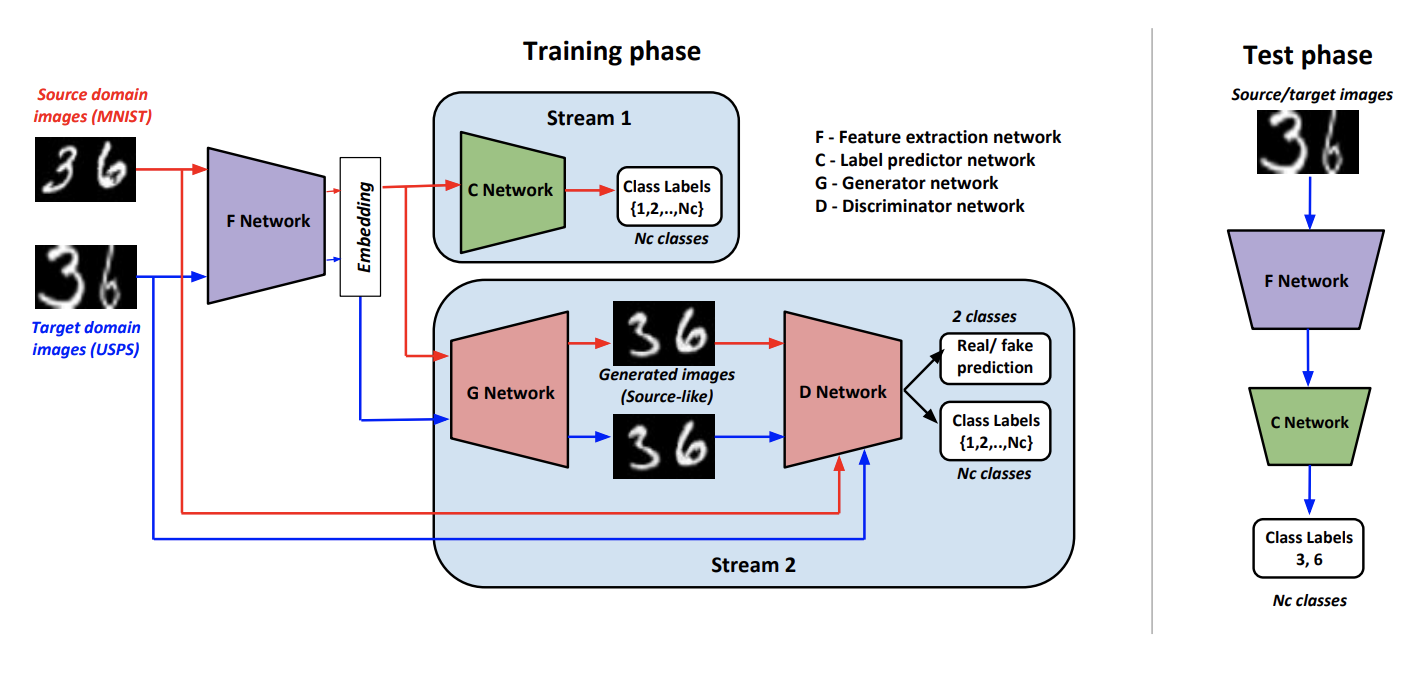
O procedimento de treinamento consiste em vários componentes:
- Discriminador D aprende a determinar o domínio para todos os recebidos de G dados e para o domínio de origem, ainda é adicionada uma perda de classificação, conforme descrito acima.
- Em dados do domínio de origem G usando uma combinação de perda de concorrência e perda de classificação, é treinado para gerar um resultado semelhante ao domínio de origem e classificado corretamente D .
- F e C Aprenda a classificar dados do domínio de origem. Também F com a ajuda de outra perda de classificação, é alterado para aumentar a qualidade da classificação D .
- Usando perda de adversário F aprende a "trapacear" D nos dados do domínio de destino.
- Os autores concluíram empiricamente que antes de submeter à G faz sentido concatenar um vetor de F com ruído normal e vetor de classe quente ( K+1 para dados de destino).
Os resultados do método em benchmarks:
- Nos domínios digitais do USPS -> MNIST: 90,8%.
- No conjunto de dados do Office, a qualidade média de adaptação para pares de domínios da Amazon e Webcam é de 86,5%.
- No conjunto de dados VisDA, o valor médio da qualidade para 12 categorias sem uma classe desconhecida é 76,7%.
No artigo Da origem ao destino e vice-versa: GAN adaptativo bidirecional simétrico ( código ), foi introduzido o modelo SBADA-GAN, que é bastante semelhante ao CyCADA e cuja função de destino, como CyCADA, consiste em 6 componentes. Na notação dos autores Gst e Gts - geradores do domínio de origem até o destino e vice-versa, Ds e Dt - discriminadores que distinguem dados reais dos gerados nos domínios de origem e de destino, respectivamente, Cs e Ct - classificadores que são treinados em dados do domínio de origem e em suas versões transformados no domínio de destino.
O SBADA-GAN, como o CyCADA, usa a idéia do CycleGAN, perda de consistência e pseudo-rótulos para os dados gerados no domínio de destino, compondo a função de destino a partir dos termos correspondentes. Os recursos do SBADA-GAN incluem:
- A imagem + ruído é alimentada na entrada para os geradores.
- O teste usa uma combinação linear de previsões do modelo de destino e o modelo de origem com base na transformação Gst .
Esquema de treinamento SBADA-GAN:
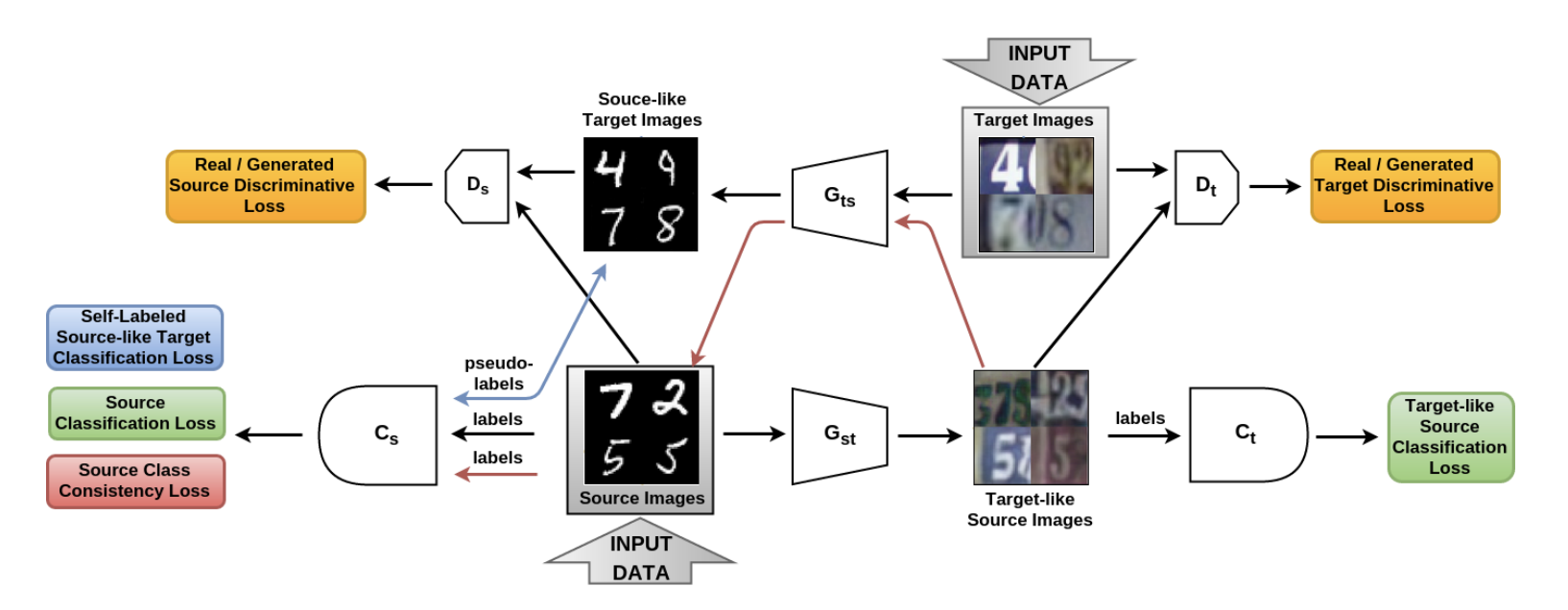
Os autores do SBADA-GAN realizaram mais experimentos que os autores do CyCADA e obtiveram os seguintes resultados:
- Nos domínios USPS -> MNIST: 95,0%.
- Nos domínios MNIST -> SVHN: 61,1%.
- Nos sinais de trânsito Synth Signs -> GTSRB: 97,7%.
Da família de modelos generativos, faz sentido considerar os seguintes artigos significativos:
Desafio de adaptação do domínio visual
Como parte do workshop, as conferências ECCV e ICCV organizam um concurso de adaptação de domínio do Visual Domain Adaptation Challenge . Nele, os participantes são convidados a treinar o classificador em dados sintéticos e adaptá-lo aos dados não alocados do ImageNet.
O algoritmo apresentado no Auto-conjunto para adaptação do domínio visual ( código ) venceu no VisDA-2017. Este método baseia-se na idéia de auto-montagem: existe uma rede de professores (modelo de professor) e uma rede de estudantes. A cada iteração, a imagem de entrada é executada em ambas as redes. O aluno é treinado usando a soma da perda de classificação e perda de consistência, em que a perda de classificação é a entropia cruzada usual com um rótulo de classe bem conhecido e a perda de consistência é a diferença quadrática média entre as previsões do professor e do aluno (diferença quadrática). Os pesos da rede de professores são calculados como a média móvel exponencial dos pesos da rede de alunos. Este procedimento de treinamento é ilustrado abaixo.
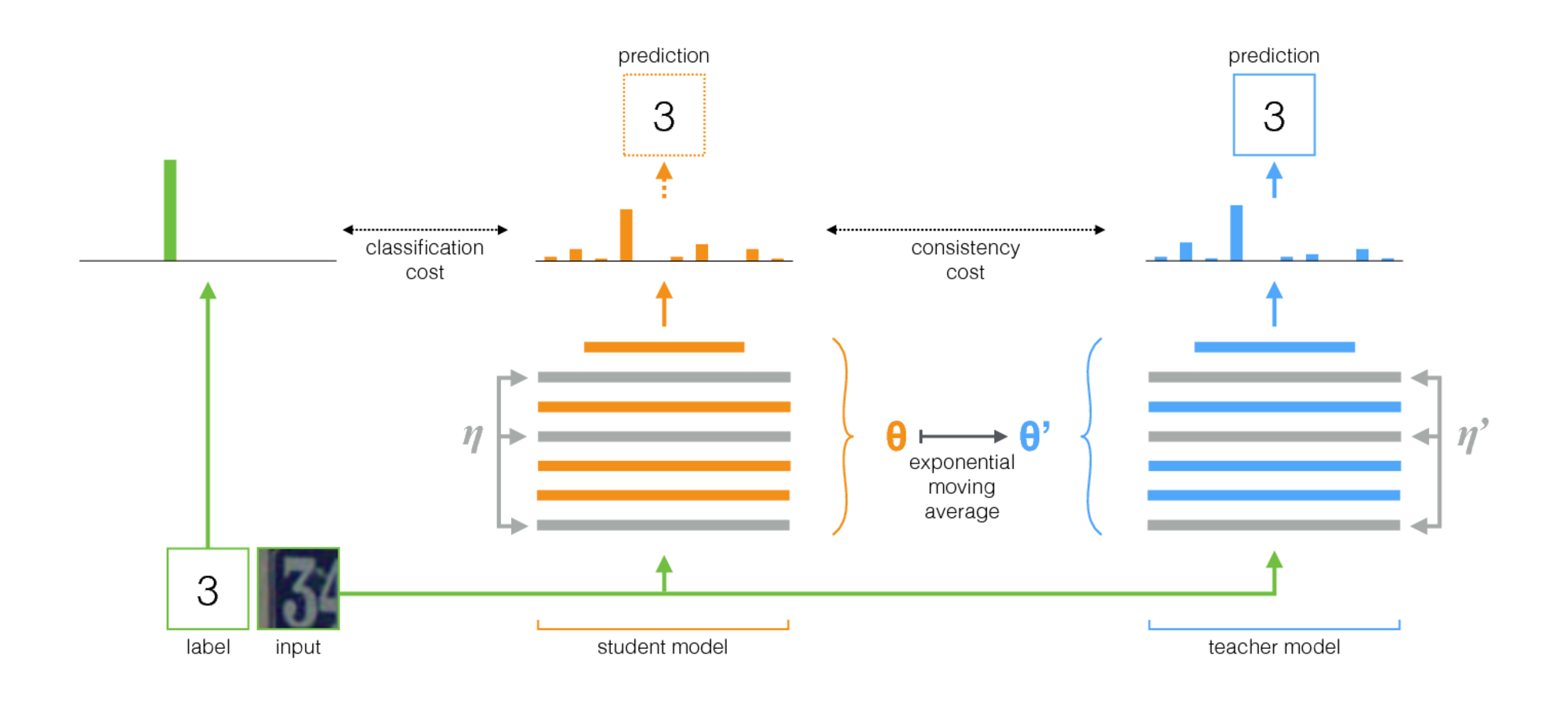
Recursos importantes da aplicação deste método para adaptação de domínio são:
- No lote de treinamento, os dados do domínio de origem são misturados xSi com rótulos de classe ySi e dados do domínio de destino xTi sem tags.
- Antes de inserir imagens nas redes neurais, são aplicados vários aumentos fortes: ruídos gaussianos, transformações afins etc.
- Ambas as redes usavam métodos fortes de regularização (como desistência).
- zTi - saída da rede de estudantes, widetildezTi - professores da rede. Se a entrada era do domínio de destino, apenas a perda de consistência entre zTi e widetildezTi , perda de entropia cruzada = 0.
- Para a sustentabilidade do aprendizado, o limiar de confiança é usado: se a previsão do professor for menor que o limiar (0,9), perda de consistência = 0.
Esquema do procedimento descrito:

Nos principais conjuntos de dados, o algoritmo alcançou alto desempenho. É verdade que os autores selecionaram separadamente um conjunto de aprimoramentos para cada tarefa.
- USPS -> MNIST: 99,54%.
- MNIST -> SVHN: 97,0%.
- Números Synth -> SVHN: 97,11%.
- Nos sinais de trânsito Synth Signs -> GTSRB: 99,37%.
- No conjunto de dados VisDA, o valor médio da qualidade para 12 categorias sem a classe Desconhecida é 92,8%. É importante observar que esse resultado foi obtido usando um conjunto de 5 modelos e o aumento do tempo de teste.
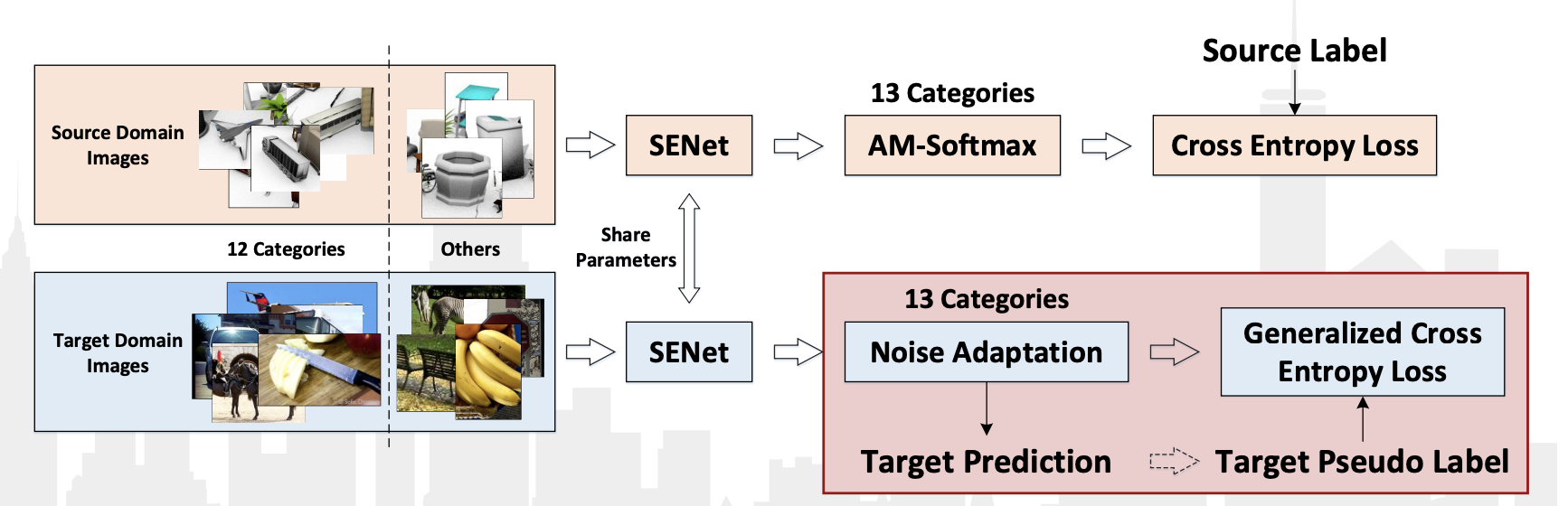
A competição VisDA-2018 foi realizada este ano como parte da conferência ECCV-2018. Dessa vez, eles adicionaram a 13ª classe: Desconhecida, que conseguiu tudo que não se enquadrava em 12 classes. Além disso, foi realizada uma competição separada para detectar objetos pertencentes a essas 12 classes. Nas duas categorias, a equipe chinesa JD AI Research venceu. No concurso de classificação, eles alcançaram um resultado de 92,3% (o valor médio da qualidade em 13 categorias). Não há publicações com uma descrição detalhada de seu método, há apenas uma apresentação do workshop .
Das características de seu algoritmo podem ser observadas:
- Usando pseudo-rótulos para dados do domínio de destino e treinando novamente o classificador neles, juntamente com dados do domínio de origem.
- Usando a camada de adaptação da rede de convolução SE-ResNeXt-101, AM-Softmax e Noise, perda generalizada de entropia cruzada para dados do domínio de destino.
Diagrama de algoritmo da apresentação:
Conclusão
Na maioria das vezes, discutimos métodos de adaptação com base na abordagem baseada no contraditório. No entanto, nas duas últimas competições do VisDA, ganhou algoritmos que não estavam relacionados a ela e usando treinamento em pseudo-rótulos e modificações de métodos mais clássicos de aprendizado profundo. Na minha opinião, isso se deve ao fato de que os métodos baseados em GANs ainda estão apenas no início de seu desenvolvimento e são extremamente instáveis. Mas todos os anos obtemos mais e mais novos resultados que melhoram o trabalho dos GANs. Além disso, o foco de interesse da comunidade científica no campo da adaptação de domínios se concentra principalmente em métodos contraditórios, e novos artigos estudam principalmente essa abordagem. Portanto, é provável que os algoritmos associados aos GANs venham gradualmente à frente em questões de adaptação.
Mas a pesquisa sobre abordagens não-contraditórias também está em andamento. Aqui estão alguns artigos interessantes desta área:
Os métodos baseados em discrepâncias podem ser classificados como "históricos", mas muitas das idéias usadas nos métodos mais recentes: MMD, pseudo-rótulos, aprendizado de métricas etc. Além disso, às vezes em problemas simples de adaptação, faz sentido aplicar esses métodos devido à relativa facilidade de treinamento e melhor interpretabilidade dos resultados.
Concluindo, quero observar que os métodos de adaptação de domínio ainda estão procurando sua aplicação em campos aplicados, mas as tarefas prospectivas que exigem o uso de adaptação estão gradualmente se tornando cada vez mais. Por exemplo, a adaptação de domínio é ativamente usada no treinamento de módulos de carros autônomos : como é caro e demorado coletar dados reais nas ruas da cidade para o treinamento de pilotos automáticos, os carros autônomos usam dados sintéticos (os bancos de dados SYNTHIA e GTA 5 servem como exemplos), em particular. resolver o problema de segmentação do que a câmera “vê” do carro.
A obtenção de modelos de alta qualidade com base em treinamento aprofundado na Computer Vision depende em grande parte da disponibilidade de grandes conjuntos de dados rotulados para treinamento. A marcação quase sempre exige muito tempo e dinheiro, o que aumenta significativamente o ciclo de desenvolvimento de modelos e, como resultado, produtos baseados neles.
Os métodos de adaptação do domínio visam solucionar esse problema e podem potencialmente contribuir para uma inovação em muitos problemas aplicados e na inteligência artificial em geral. Transferir conhecimento de um domínio para outro é uma tarefa realmente difícil e interessante, que atualmente está sendo estudada ativamente. Se você sofre de falta de dados em suas tarefas e pode emular dados ou encontrar domínios semelhantes, recomendo tentar métodos de adaptação de domínio!