Velocity é uma conferência dedicada a sistemas distribuídos. É organizado pela editora O'Reilly e acontece três vezes por ano: uma na Califórnia, uma em Nova York e outra na Europa (e a cidade muda a cada ano).
Em 2018, a conferência foi realizada em Londres, de 30 de outubro a 2 de novembro. O escritório principal do Badoo está localizado lá, então meus colegas e eu tínhamos dois motivos para ir ao Velocity.
Seu dispositivo acabou sendo um pouco mais complicado do que o que encontrei nas conferências russas. Além dos habituais dois dias de apresentações, houve mais dois dias de treinamento, que podem ser realizados na íntegra, em parte ou não. Juntos, isso se transforma em uma séria busca para escolher o tipo de ingresso necessário.
Nesta revisão, falarei sobre os relatórios e masterclasses que me lembro. Anexo links para materiais adicionais a alguns relatórios. Em parte, esses são materiais aos quais os autores se referem e, em parte, materiais para estudos posteriores, aos quais me encontrei.
A impressão geral da conferência: os autores se saem muito bem (e as sessões principais são um show inteiro com palestrantes apresentando e subindo ao palco com a música), mas ao mesmo tempo me deparei com alguns relatórios que eram profundos do ponto de vista técnico.
O tópico mais quente desta conferência é o Kubernetes , mencionado em quase todos os segundos relatórios.
O trabalho com redes sociais é muito bem construído: na conta oficial do twitter durante a conferência, houve muitos retweets operacionais com relatórios. Isso permitiu uma rápida olhada no que estava acontecendo em outras salas.
Master classes
31 de outubro era o dia em que não havia relatórios, mas havia seis ou oito master classes de três horas de tempo puro cada, das quais duas tinham que ser escolhidas.
PS No original, eles são chamados de tutorial, mas parece-me correto traduzi-los como "master class".
Bootcamp de engenharia do caos
Apresentador: Ana Medina , Engenheira do Gremlin | Descrição do produto
O workshop foi dedicado à introdução da engenharia do caos. Ana contou com fluência o que é, quais benefícios ele traz, demonstrou como pode ser usado, que software pode ajudar e como começar a usá-lo em uma empresa.
Em geral, essa foi uma boa introdução para iniciantes, mas não gostei muito da parte prática, que foi a implantação de um aplicativo Web de demonstração em um cluster de várias máquinas usando o Kubernetes e danificando o monitoramento do DataDog para ele. O principal problema era que passamos quase metade do tempo da aula principal nisso e era necessário apenas brincar com scripts que simulam vários problemas no cluster por 5 a 10 minutos e observar as alterações nos gráficos.
Parece-me que, para o mesmo efeito, foi suficiente dar acesso a um DataDog pré-configurado e / ou demonstrar tudo da cena, e esse tempo deve ser gasto, por exemplo, em uma revisão mais detalhada e em exemplos de uso do mesmo Chaos Monkey, sobre o qual acabamos de falar literalmente algumas frases.


Interessante: nesta conferência, os oradores freqüentemente mencionavam o termo "raio de explosão", que eu nunca tinha visto antes. Eles designaram a parte do sistema afetada quando ocorre um problema específico.
Materiais adicionais:
Construindo infraestrutura evolutiva
Apresentador: Kief Morris , consultor de infraestrutura e autor de infraestrutura como código | Descrição do produto
Os pontos principais da classe master podem ser reduzidos a duas coisas:
- Os sistemas mudam o tempo todo, por isso é normal que a infraestrutura também precise mudar;
- Depois que a infraestrutura estiver mudando, você precisará garantir que seja simples e seguro, e isso só pode ser alcançado pela automação.
A parte principal de sua história foi dedicada especificamente à automação de alterações na infraestrutura, possíveis soluções para esse problema e teste de alterações. Não sou especialista neste tópico, mas me pareceu que ele estava falando com muita confiança e em detalhes (e muito rapidamente).
O ponto principal que me lembro dessa aula principal é a recomendação para maximizar a distinção entre ambientes (produção, preparação, etc.) do código em variáveis de ambiente. Isso reduzirá a probabilidade de erros na infraestrutura ao alterar o ambiente e o tornará mais testável.



Relatórios
1 e 2 de novembro foram dias de relatórios. Eles foram divididos em dois blocos principais: uma série de três ou quatro relatórios breves que foram apresentados em um fluxo pela manhã (e para eles um grande salão reunido por dois menores) e relatórios temáticos mais longos em cinco fluxos que passaram pelo resto do dia . Durante o dia, houve várias grandes pausas entre os relatórios, quando foi possível passear pela exposição com os estandes dos parceiros da conferência.
Evolução do Runtastic Backend
Simon Lasselsberger (Runtastic GmbH) | Descrição e slides
Um dos poucos relatos em que o autor não apenas contou como fazer algo, mas também mostrou detalhes de um projeto específico e o que aconteceu com ele.
No início, o Runtastic tinha um banco de dados comum do Percona Server e um monólito com código que atende a aplicativos móveis e um site. Então eles começaram a escrever em Cassandra (não me lembro por que estava) a parte dos dados para a qual o valor-chave do armazenamento era suficiente. Gradualmente, o banco de dados ficou inchado e eles adicionaram o MongoDB, no qual começaram a gravar dados da maioria dos serviços. Com o tempo, eles criaram um nível geral que atende solicitações de aplicativos da Web e móveis (algo como nosso aplicativo , pelo que entendi).
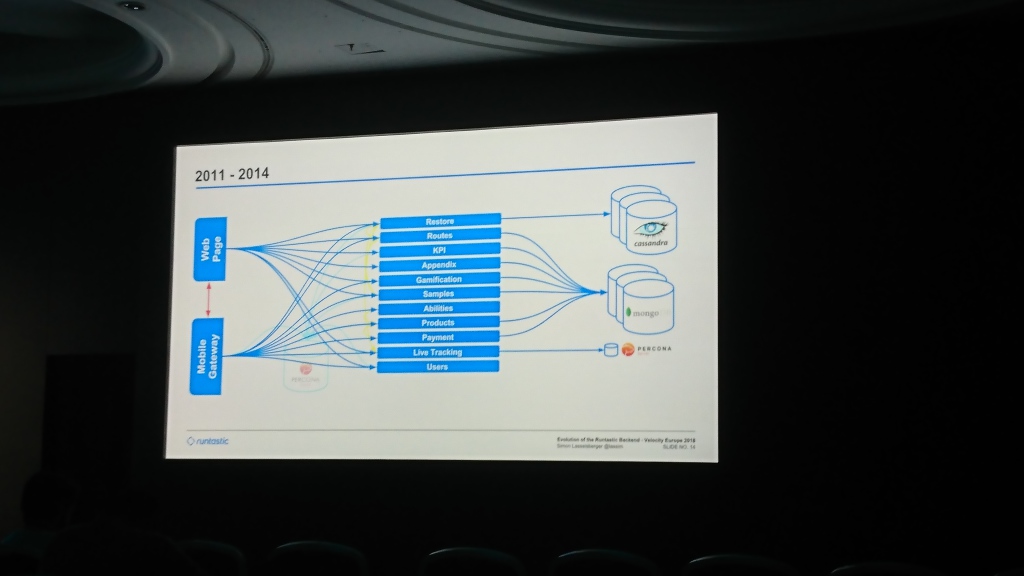
A maior parte do relatório foi dedicada à mudança entre data centers. Inicialmente, eles mantiveram o servidor em Hetzner, que após algum tempo foi considerado insuficientemente estável e os dados migraram para a T-Systems. Alguns anos depois, eles já enfrentavam falta de espaço e se mudaram novamente para a Linz AG. A parte mais interessante aqui é a migração de dados. Eles começaram a copiar dados que duraram vários meses. Eles não podiam esperar tanto porque eles estavam ficando sem espaço e não podiam adicioná-lo, então criaram um fallback no código, que tentava ler dados do antigo data center se não estivesse no novo.
No futuro, eles planejam dividir os dados em vários data centers separados (Simon disse várias vezes que isso é necessário para a Rússia e a China) e dividem rigidamente os bancos de dados por serviços separados (agora um pool comum é usado para todos os serviços).
Uma abordagem interessante para o design de módulos em um sistema, sobre o qual Simon mencionou casualmente: arquitetura hexagonal .
Permitir que um aplicativo seja igualmente orientado por usuários, programas, scripts de teste ou lote automatizados, e seja desenvolvido e testado isoladamente de seus dispositivos e bancos de dados em tempo de execução.
Alistair cockburn
Materiais adicionais:
Monitoramento de métricas personalizadas; ou Como aprendi a instrumentar primeiro e fazer perguntas depois
Maxime Petazzoni (SignalFx) | Descrição e apresentação
A história foi dedicada à coleta das métricas necessárias para entender o aplicativo. A principal mensagem era que as métricas RED habituais (taxa, erros e duração) não são suficientes e, além delas, é necessário coletar imediatamente outras pessoas que ajudarão a entender o que está acontecendo dentro do aplicativo.
Resumo, o autor sugeriu coletar contadores e temporizadores para algumas ações importantes no sistema (e necessariamente contadores de falhas), construindo gráficos e histogramas de distribuição a partir deles, determinando um metamodelo para métricas de usuário (para que métricas diferentes tenham o mesmo conjunto de parâmetros necessários) e os mesmos significados foram chamados iguais em todos os lugares).

É muito difícil recontar os detalhes em palavras, será mais fácil ver os detalhes e exemplos na apresentação, cujo link está na página do relatório no site da conferência.
Materiais adicionais:
Como o serverless muda o departamento de TI
Paul Johnston (Laboratórios da rotatória) | Descrição e apresentação
O autor se apresentou como CTO e ambientalista, disse que o servidor sem servidor não é uma solução tecnológica, mas uma solução comercial ("Você não paga nada se não for utilizado"). Em seguida, ele descreveu as práticas recomendadas para trabalhar com sem servidor, quais competências são necessárias para trabalhar com ele e como isso afeta a seleção de novos funcionários e o trabalho com os existentes.

O momento-chave da “influência no departamento de TI” que eu lembrei foi a mudança das competências necessárias, da escrita do código para o trabalho com a infraestrutura e sua automação (“mais” engenharia ”do que“ desenvolvimento ”). revisão de código, para documentar os fluxos de dados e eventos disponíveis para uso no sistema, para se comunicar mais e aprender rapidamente), mas por alguma razão o autor os atribuiu aos recursos sem servidor.

No geral, o relatório parecia um pouco misto. Muitas das coisas sobre as quais o orador falou podem ser atribuídas a qualquer sistema complexo que não se encaixe totalmente na cabeça.
Materiais adicionais:
Não entre em pânico! Como lidar agora que você é responsável pela produção
Euan Finlay (Financial Times) | Descrição e apresentação
Um relatório sobre como lidar com incidentes de produção, se algo der errado no momento. Os pontos principais foram divididos em partes por tempo.
Antes do incidente:
- diferencie alertas por criticidade - talvez alguns possam esperar e você não precise lidar com eles com urgência;
- Prepare um plano para analisar os incidentes com antecedência e mantenha a documentação atualizada;
- realizar exercícios - quebre algo e veja o que acontece (também conhecido como engenharia do caos);
- Estabeleça um único local onde todas as informações sobre mudanças e problemas sejam reunidas.
Durante o incidente:
- é normal que você não saiba tudo - atraia outras pessoas, se necessário;
- estabelecer um único local para a comunicação entre as pessoas que trabalham na solução do incidente;
- Procure a solução mais simples que retornará a produção à condição de trabalho e não tente resolver completamente o problema.
Após o incidente:
- descubra por que o problema surgiu e o que ele lhe ensinou;
- é importante escrever um relatório sobre isso ("relatório de incidente");
- identificar o que pode ser aprimorado e planejar ações específicas.
No final, Ewan contou uma história engraçada sobre o incidente no Financial Times, que surgiu porque a base de produção (chamada prod ) foi modificada por engano em vez da pré-produção ( pprod ), e recomendou evitar nomes semelhantes.
Aprendendo com a rede da vida (Keynote)
Claire Janisch (BiomimicrySA) | Descrição do produto
Eu estava atrasado para este relatório, mas no Twitter eles falaram muito bem sobre isso. Você precisa ver se isso acontece.
Vídeos com um fragmento do discurso podem ser visualizados no site da conferência .
Jane Adams (dois investimentos da Sigma) | Descrição do produto
Relatório filosófico sobre o tópico "podemos confiar nos algoritmos de tomada de decisão". A conclusão geral foi de que não: o algoritmo pode otimizar métricas específicas, mas ao mesmo tempo afeta seriamente o que é difícil de medir ou fica fora dessas métricas (como exemplo, houve discriminação no algoritmo de contratação de funcionários da Amazon, o que afetou negativamente a cultura da empresa e forçado a abandonar esse algoritmo).
A liberdade de Kubernetes (Keynote)
Kris Nova Descrição do produto
De lá, lembrei-me de dois pensamentos:
- flexibilidade não é liberdade, mas caos;
- a complexidade em si não é um problema se carrega algum valor (no original era chamado "complexidade necessária"), que excede o custo dessa complexidade.
O relatório era bastante filosófico, portanto, por um lado, eu não conseguia tirar muito proveito dele, mas, por outro lado, o que eu saí era aplicável não apenas ao Kubernetes.

O que muda quando ficamos offline primeiro? (Keynote)
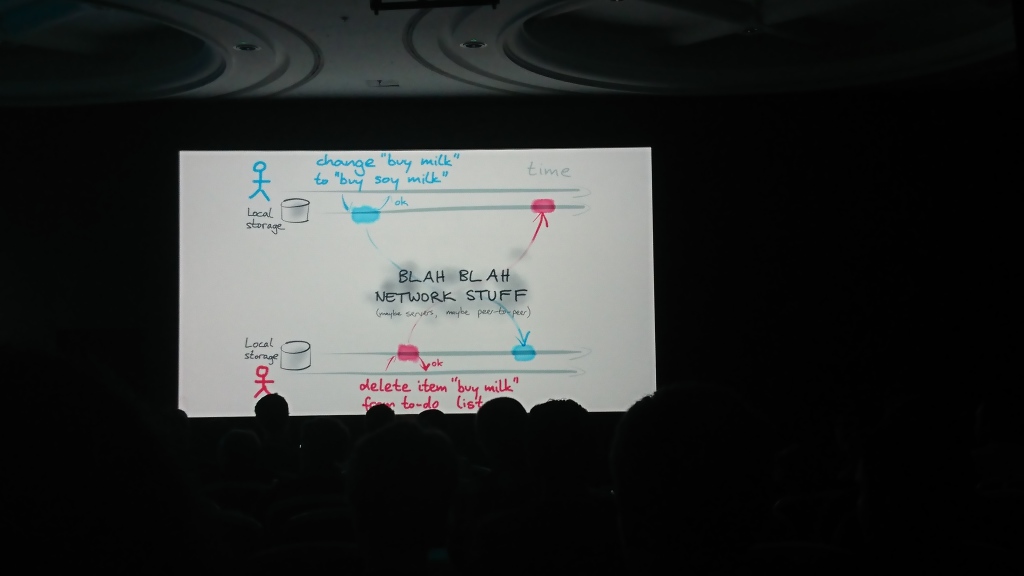
Martin Kleppmann (Universidade de Cambridge), autor de Designing Data-Intensive Applications | Descrição do produto
O relatório consistia em duas partes lógicas: na primeira, Martin falou sobre o problema de sincronizar dados entre si, que pode ser alterado independentemente em várias fontes, e na segunda, sobre possíveis soluções e algoritmos que podem ser usados para isso ( transformação operacional , OT , e tipo de dados replicado sem conflito , CRDT)) e propôs sua solução - a biblioteca automerge para resolver esses problemas.


Materiais adicionais:
Um guia do programador para conexões seguras
Palestrante: Liz Rice | Descrição e slides
O relatório foi realizado na forma de uma sessão de codificação ao vivo e nela Liz mostrou como o HTTPS funciona, quais erros podem ocorrer ao trabalhar com conexões seguras e como resolvê-los. Não houve grandes profundidades, mas a demonstração em si foi muito boa.
Mais útil: um slide com os principais erros ( também conhecido pelo relatório de Liz em outra conferência ):

Materiais adicionais:
Tudo o que você queria saber sobre monorepos, mas tinha medo de perguntar
Simon Stewart (Projeto Selenium) | Descrição do produto
A tese principal do relatório é que, no monorepo, é muito mais fácil gerenciar dependências no código, e isso cobre todas as vantagens de repositórios individuais. Ele apelou ao fato de que o Google e a Microsoft armazenam dados em um repositório (86 Tb e 300 Gb em tamanho, respectivamente), e o repositório do Facebook (arquivos de 54 Gb) usa "off the shell mercurial".
A sala "explodiu" após a pergunta "Quem tem mais repositórios na empresa do que funcionários?"
O argumento "com um grande repositório para trabalhar lentamente" foi quebrado da seguinte maneira:
- você não precisa levar todo o histórico de alterações para a máquina local: use o clone das sombras e o checkout esparso ;
- você não precisa usar todos os arquivos do repositório: organize a hierarquia dos arquivos e trabalhe apenas com o diretório necessário e exclua todo o resto.
Materiais adicionais:
Construindo um sistema de processamento de fluxo distribuído em tempo real
Amy Boyle (Nova Relíquia) | Descrição e apresentação
Uma boa história sobre como trabalhar com dados de streaming de um engenheiro da NewRelic (onde eles claramente têm muita experiência em trabalhar com esses dados). Amy disse que está trabalhando com dados de streaming, como eles podem ser agregados, o que pode ser feito com dados atrasados, como pode fragmentar fluxos de eventos e como reequilibrá-los em caso de falhas no processador, o que monitorar etc.
O relatório era muito material, não vou tentar recontá-lo, mas apenas recomendo ver a apresentação em si (já está no site da conferência).


Arquitetura para tv
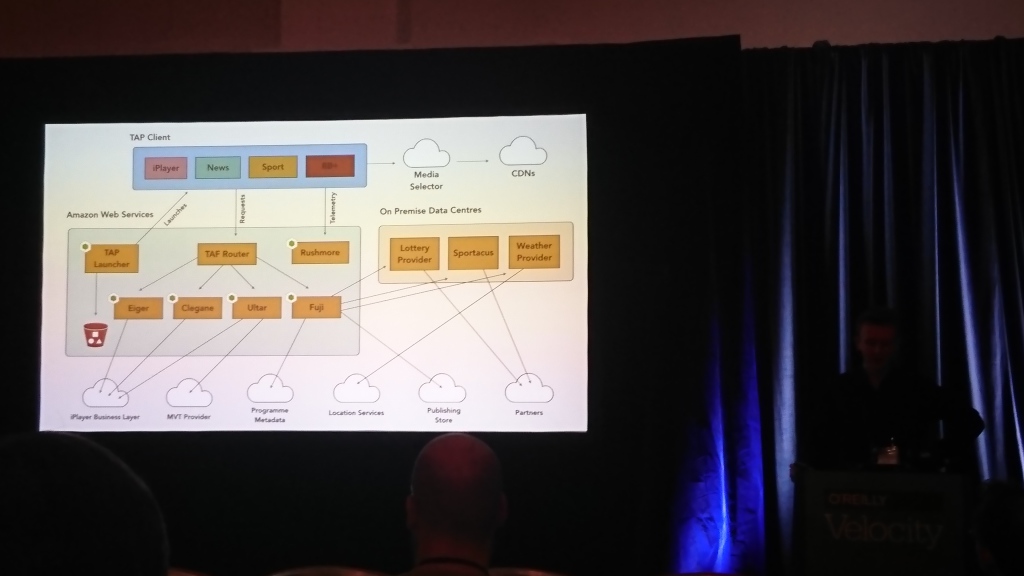
David Buckhurst (BBC), Ross Wilson (BBC) | Descrição do produto
A maior parte da conversa foi sobre o frontend da BBC. Os caras têm televisão interativa e muitas televisões e outros dispositivos (computadores, telefones, tablets) nos quais isso deve funcionar. Você precisa trabalhar com dispositivos diferentes de maneiras completamente diferentes, para que eles criem sua própria linguagem baseada em JSON para descrever interfaces e traduzi-la para o que um dispositivo específico pode entender.
A principal conclusão para mim é que, comparadas às pessoas da TV, os aplicativos móveis não têm problemas com clientes antigos.