No início do ano, decidimos aprender a armazenar e ler os logs de depuração VK com mais eficiência do que antes. Os logs de depuração são, por exemplo, logs de conversão de vídeo (basicamente a saída do comando ffmpeg e uma lista de etapas para o pré-processamento de arquivos), que às vezes precisamos apenas de 2 a 3 meses após o processamento do arquivo com problema.
Naquela época, tínhamos duas maneiras de armazenar e processar logs - nosso próprio mecanismo de logs e o rsyslog, que usamos em paralelo. Começamos a considerar outras opções e percebemos que o ClickHouse da Yandex é bastante adequado para nós - decidimos implementá-lo.
Neste artigo, falarei sobre como começamos a usar o ClickHouse no VKontakte, que tipo de rake eles pisaram e o que são KittenHouse e LightHouse. Ambos os produtos são apresentados em links de código aberto no final do artigo.
Tarefa de coleta de log
Exigências do sistema:
- Armazenamento de centenas de terabytes de logs.
- Armazenamento por meses ou (raramente) anos.
- Alta velocidade de gravação.
- Alta velocidade de leitura (a leitura é rara).
- Suporte ao Índice
- Suporte para cadeias longas (> 4 Kb).
- Simplicidade de operação.
- Armazenamento compacto.
- A capacidade de inserir a partir de dezenas de milhares de servidores (o UDP será uma vantagem).
Possíveis soluções
Vamos listar brevemente as opções que consideramos e seus contras:
Mecanismo de logs
Nosso microsserviço auto-escrito para logs.
- Capaz de fornecer apenas as últimas N linhas que cabem na RAM.
- Armazenamento não muito compacto (sem compactação transparente).
Hadoop
- Nem todos os formatos têm índices.
- A velocidade de leitura pode ser maior (dependendo do formato).
- A complexidade das configurações.
- Não há possibilidade de inserção a partir de dezenas de milhares de servidores (são necessários Kafka ou análogos).
Arquivos Rsyslog +
- sem índices.
- Baixa velocidade de leitura (grep / zgrep regular).
- Seqüências de arquitetura não suportadas> 4 Kb, UDP ainda menos (1,5 Kb).
± O armazenamento compacto é obtido com o logrotate sobre a coroa
Usamos o rsyslog como um substituto para o armazenamento de longo prazo, mas as linhas longas foram truncadas, portanto dificilmente pode ser chamado de ideal.
Arquivos LSD +
- sem índices.
- Baixa velocidade de leitura (grep / zgrep regular).
- Não é especialmente projetado para inserção em dezenas de milhares de servidores.
± O armazenamento compacto é obtido com o logrotate sobre a coroa.
As diferenças do rsyslog no nosso caso são que o LSD suporta seqüências longas, mas alterações significativas no protocolo interno são necessárias para a inserção de dezenas de milhares de servidores, embora isso possa ser feito.
Elasticsearch
- problemas com a operação.
- gravação instável.
- Sem UDP.
- Má compressão.
A pilha ELK já é quase o padrão do setor para armazenamento de logs. Em nossa experiência, tudo está bem com a velocidade da leitura, mas há problemas com a escrita, por exemplo, ao mesclar índices.
O ElasticSearch foi desenvolvido principalmente para pesquisa de texto completo e solicitações de leitura relativamente frequentes. Para nós, a gravação estável e a capacidade de ler nossos dados mais ou menos rapidamente são mais importantes e por coincidência exata. O índice no ElasticSearch é aprimorado para pesquisa de texto completo, e o espaço em disco é bastante grande comparado ao gzip do conteúdo original.
Clickhouse
- Sem UDP.
Em geral, a única coisa que não nos convinha na ClickHouse era a falta de comunicação UDP. De fato, das opções acima, apenas o rsyslog o possuía, mas o rsyslog não suporta linhas longas.
De acordo com outros critérios, o ClickHouse veio até nós e decidimos usá-lo, e os problemas com o transporte foram resolvidos no processo.
Por que o KittenHouse é necessário
Como você provavelmente sabe, o VKontakte funciona em PHP / KPHP, com "mecanismos" (microsserviços) em C / C ++ e um pouco em Go. O PHP não tem um conceito de "estado" entre solicitações, exceto talvez para memória compartilhada e conexões abertas.
Como temos dezenas de milhares de servidores dos quais queremos poder enviar logs para o ClickHouse, seria inútil manter conexões abertas de cada trabalhador PHP (pode haver mais de 100 trabalhadores para cada servidor). Portanto, precisamos de algum tipo de proxy entre ClickHouse e PHP. Chamamos esse proxy de KittenHouse.
KittenHouse, v1
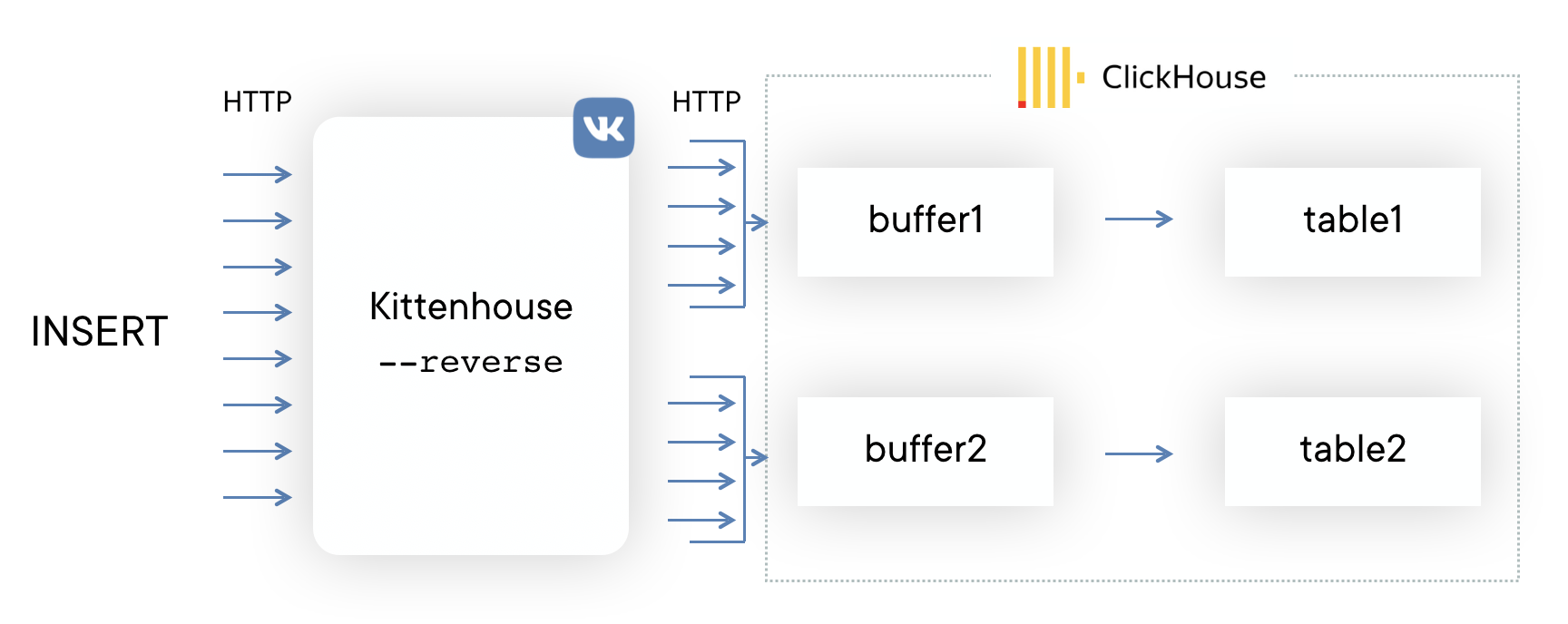
Primeiro, decidimos tentar o esquema mais simples possível para entender se nossa abordagem funcionará ou não. Se Kafka vier à sua mente ao resolver esse problema, você não estará sozinho. No entanto, não queremos usar servidores intermediários adicionais - nesse caso, poderíamos descansar facilmente no desempenho desses servidores, e não no ClickHouse. Além disso, coletamos logs e precisávamos de um pequeno e previsível atraso na inserção de dados. O esquema é o seguinte:

Em cada um dos servidores, nosso proxy local (kittenhouse) está instalado e cada instância mantém estritamente uma conexão HTTP com o servidor ClickHouse necessário. A colagem é feita em tabelas em spool, pois geralmente não é recomendável inserir o MergeTree.
Funções KittenHouse, v1
A primeira versão do KittenHouse sabia um pouco, mas isso foi suficiente para testar:
- Comunicação através do nosso RPC (TL Scheme).
- Mantenha 1 conexão TCP / IP por servidor.
- Buffer na memória por padrão, com um tamanho de buffer limitado (o restante é descartado).
- A capacidade de gravar em disco, neste caso, há uma garantia de entrega (pelo menos uma vez).
- O intervalo de inserção é uma vez a cada 2 segundos.
Primeiros problemas
Encontramos o primeiro problema quando "reembolsamos" o servidor ClickHouse por várias horas e o ligamos novamente. Abaixo, você pode ver a média de carga no servidor após o "aumento":
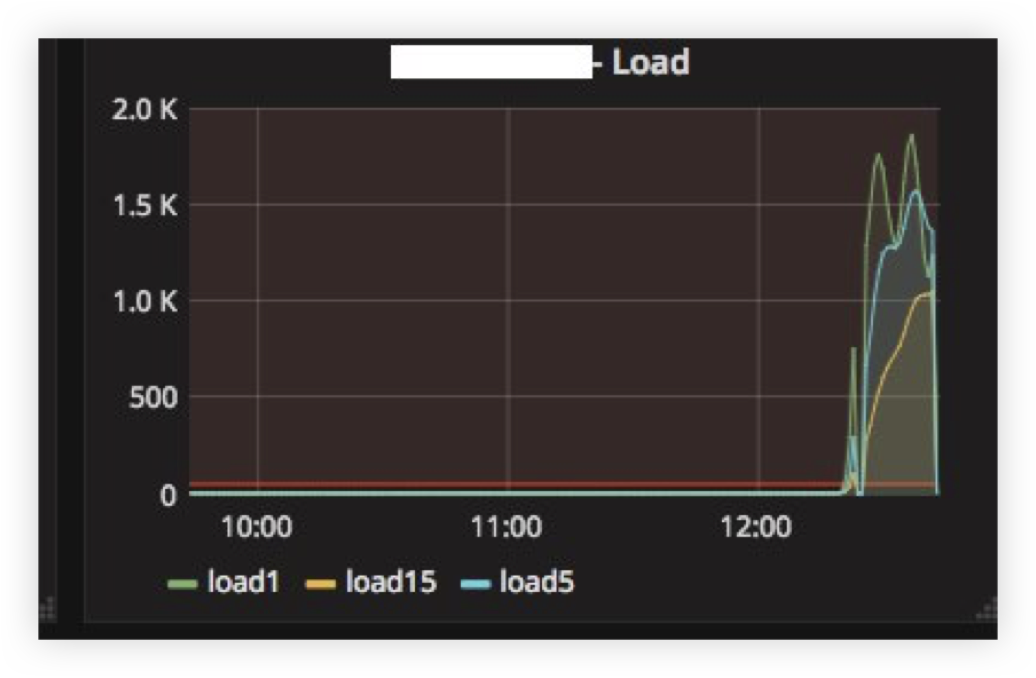
A explicação é bem simples: o ClickHouse possui uma rede por modelo de encadeamento; portanto, quando tento inserir INSERT a partir de milhares de nós ao mesmo tempo, houve uma concorrência muito forte pelos recursos da CPU e o servidor mal responde. No entanto, todos os dados foram inseridos e nada caiu.
Para resolver esse problema, colocamos o nginx na frente do ClickHouse e, em geral, ajudou.
Desenvolvimento adicional
Durante a operação, encontramos vários problemas, principalmente relacionados ao ClickHouse, mas à nossa maneira de operá-lo. Aqui está outro rake em que pisamos:
Um grande número de "partes" de tabelas de buffer leva a freqüentes descargas de buffer no MergeTree
No nosso caso, havia 16 pedaços de buffer e um intervalo de redefinição a cada 2 segundos, e havia 20 pedaços de tabelas, que forneciam até 160 inserções por segundo. Isso periodicamente afetava muito o desempenho da inserção - havia muitas mesclagens em segundo plano e a utilização do disco atingia 80% ou mais.
Solução: aumente o intervalo de redefinição do buffer padrão, reduza o número de peças para 2.
Nginx retorna 502 quando as conexões com a extremidade upstream
Isso por si só não é um problema, mas em combinação com a liberação frequente do buffer, isso fornece um fundo bastante alto de 502 erros ao tentar inserir em qualquer uma das tabelas, bem como ao tentar executar SELECT.
Solução: eles escreveram seu proxy reverso usando a biblioteca
fasthttp , que agrupa a inserção em tabelas e consome conexões de maneira econômica. Também distingue entre SELECT e INSERT e possui conjuntos de conexões separados para inserção e leitura.
Falta de memória com inserção intensiva
A biblioteca fasthttp tem suas vantagens e desvantagens. Uma das desvantagens é que a solicitação e a resposta são totalmente armazenadas em buffer na memória antes de dar controle ao manipulador de solicitações. Para nós, isso resultou no fato de que, se a inserção no ClickHouse "não tivesse tempo", os buffers começaram a crescer e, eventualmente, toda a memória do servidor acabou, o que levou à eliminação do proxy reverso pelo OOM. Os colegas desenharam um desmotivador:
 Solução:
Solução: corrigir o fasthttp para oferecer suporte ao streaming do corpo da solicitação POST acabou sendo uma tarefa assustadora, por isso decidimos usar as conexões Hijack () e atualizar a conexão para o nosso protocolo se a solicitação vier com o método HTTP KITTEN. Como o servidor deve responder ao MEOW em resposta, se ele entender esse protocolo, todo o esquema será chamado de protocolo KITTEN / MEOW.
Lemos apenas 50 conexões aleatórias por vez, portanto, graças ao TCP / IP, o restante dos clientes “espera” e não gastamos memória em buffers até que a fila atinja os respectivos clientes. Isso reduziu o consumo de memória em pelo menos 20 vezes e não tivemos mais esses problemas.
As tabelas ALTER podem demorar muito se houver consultas longas
O ClickHouse possui um ALTER sem bloqueio, no sentido de que não interfere nas consultas SELECT e INSERT. Mas ALTER não pode ser iniciado até que termine de executar as consultas nesta tabela enviadas antes de ALTER.
Se o servidor tiver um plano de fundo de consultas "longas" para algumas tabelas, você poderá encontrar uma situação em que ALTER nesta tabela não terá tempo para executar em um tempo limite padrão de 60 segundos. Mas isso não significa que ALTER falhará: será executado assim que essas consultas SELECT forem concluídas.
Isso significa que você não sabe em que momento ALTER realmente ocorreu e não poderá recriar automaticamente as tabelas de buffer para que seu layout seja sempre o mesmo. Isso pode levar a problemas de inserção.

 Solução:
Solução: Como resultado, planejamos abandonar completamente o uso de tabelas de buffer. Em geral, as tabelas de buffer têm um escopo, até o momento as usamos e não temos grandes problemas. Mas agora finalmente chegamos ao ponto em que é mais fácil implementar a funcionalidade de tabelas de buffer no lado do proxy reverso do que continuar atendendo suas deficiências. Um exemplo de circuito será semelhante a este (a linha tracejada mostra a assincronia do ACK no INSERT).

Lendo dados
Digamos que descobrimos a inserção. Como ler esses logs do ClickHouse? Infelizmente, não encontramos nenhuma ferramenta conveniente e fácil de usar para ler dados brutos (sem gráficos e outros) do ClickHouse, por isso criamos nossa própria solução - LightHouse. Suas capacidades são bastante modestas:
- Visualização rápida do conteúdo da tabela.
- Filtragem, classificação.
- Editando uma consulta SQL.
- Ver estrutura da tabela.
- Mostra o número aproximado de linhas e espaço em disco usado.
No entanto, o LightHouse é rápido e capaz de fazer o que precisamos. Aqui estão algumas capturas de tela:
Exibir estrutura da tabela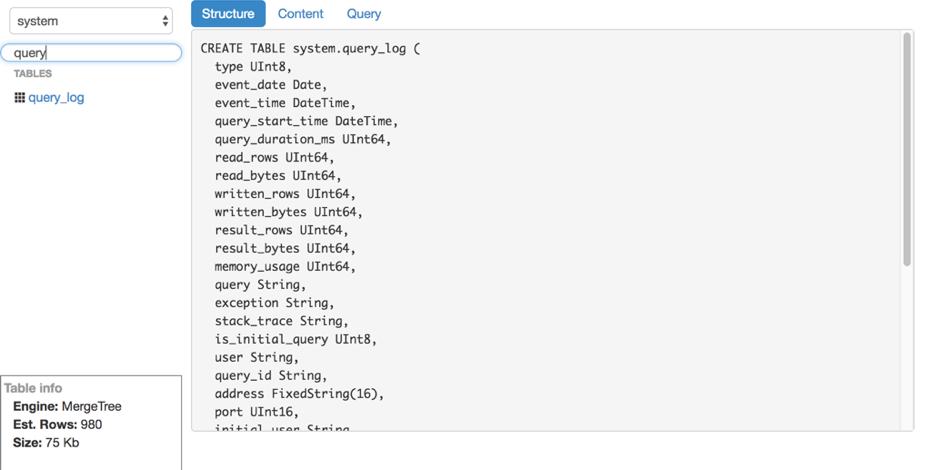 Filtragem de Conteúdo
Filtragem de Conteúdo
Resultados
O ClickHouse é praticamente o único banco de dados de código aberto que se estabeleceu no VKontakte. Estamos satisfeitos com a rapidez do seu trabalho e estamos prontos para suportar as deficiências, que serão discutidas abaixo.
Dificuldade no trabalho
Em suma, o ClickHouse é um banco de dados muito estável e muito rápido. No entanto, como em qualquer produto, especialmente tão jovem, há características no trabalho que precisam ser consideradas:
- Nem todas as versões são igualmente estáveis: não atualize diretamente para a nova versão em produção; é melhor aguardar várias versões de correções.
- Para um desempenho ideal, é altamente recomendável configurar o RAID e outras coisas de acordo com as instruções. Isso foi relatado recentemente em alta carga .
- A replicação não possui limites de velocidade internos e pode causar uma degradação significativa no desempenho do servidor se você não o limitar (mas eles prometem corrigi-lo).
- O Linux possui um recurso desagradável do mecanismo de memória virtual: se você grava ativamente no disco e os dados não têm tempo para serem liberados, em algum momento o servidor entra em ação completamente, começa a liberar ativamente o cache da página no disco e bloqueia quase completamente o processo ClickHouse. Às vezes, isso acontece com mesclagens grandes, e você precisa monitorar isso, por exemplo, periodicamente, você mesmo libera os buffers ou faz a sincronização.
Código aberto
O KittenHouse e o LightHouse agora estão disponíveis em código aberto no nosso repositório github:
Obrigada
Yuri Nasretdinov, desenvolvedor do departamento de infraestrutura de back-end da VKontakte