Como engenheiro de infraestrutura da equipe de desenvolvimento da plataforma em nuvem , tive a oportunidade de trabalhar com muitos sistemas de armazenamento distribuído, incluindo aqueles indicados no cabeçalho. Parece que há um entendimento de seus pontos fortes e fracos, e tentarei compartilhar meus pensamentos com você sobre esse assunto. Por assim dizer, vamos ver quem tem a função hash por mais tempo.

Isenção de responsabilidade: No início deste blog, você podia ver artigos sobre o GlusterFS. Não tenho nada a ver com esses artigos. Este é o blog do autor da equipe de projeto de nossa nuvem e cada um de seus membros pode contar sua história. O autor desses artigos é um engenheiro do nosso grupo de operações e ele tem suas próprias tarefas e sua experiência, que ele compartilhou. Leve isso em consideração se de repente você perceber uma diferença de opinião. Aproveito esta oportunidade para expressar meus cumprimentos ao autor desses artigos!
O que será discutido
Vamos falar sobre sistemas de arquivos que podem ser criados com base no GlusterFS e no CephFS. Discutiremos a arquitetura desses dois sistemas, olharemos para eles de diferentes ângulos e, no final, correrei o risco de tirar conclusões. Outros recursos do Ceph, como RBD e RGW, não serão afetados.
Terminologia
Para tornar o artigo completo e compreensível para todos, vejamos a terminologia básica dos dois sistemas:
Terminologia do Ceph:
O RADOS (Reliable Autonomic Distributed Object Store) é um armazenamento de objetos independente, que é a base do projeto Ceph.
CephFS , RBD (RADOS Block Device), RGW (RADOS Gateway) - gadgets de alto nível para o RADOS, que fornecem aos usuários finais várias interfaces para o RADOS.
Especificamente, o CephFS fornece uma interface de sistema de arquivos compatível com POSIX. De fato, os dados do CephFS são armazenados no RADOS.
OSD (Object Storage Daemon) é um processo que serve um armazenamento de disco / objeto separado em um cluster RADOS.
Pool RADOS (pool) - vários OSDs unidos por um conjunto comum de regras, como, por exemplo, uma política de replicação. Do ponto de vista da hierarquia de dados, um pool é um diretório ou um espaço para nome separado (plano, sem subdiretórios) para objetos.
PG (Placement Group) - apresentarei o conceito de PG um pouco mais tarde, no contexto, para uma melhor compreensão.
Como o RADOS é a base sobre a qual o CephFS é construído, geralmente falarei sobre isso e isso se aplicará automaticamente ao CephFS.
Terminologia do GlusterFS (a seguir gl):
Brick é um processo que serve um único disco, um análogo do OSD na terminologia RADOS.
Volume - volume no qual os tijolos estão unidos. Tom é um analógico de pool no RADOS, também possui uma topologia de replicação específica entre tijolos.
Distribuição de dados
Para tornar mais claro, considere um exemplo simples que pode ser implementado pelos dois sistemas.
A configuração a ser usada como exemplo:
- 2 servidores (S1, S2) com 3 discos de volume igual (sda, sdb, sdc) em cada um;
- volume / pool com replicação 2.
Ambos os sistemas precisam de pelo menos 3 servidores para operação normal. Mas fechamos os olhos para isso, pois esse é apenas um exemplo para um artigo.
No caso de gl, será um volume Replicado Distribuído que consiste em 3 grupos de replicação:

Cada grupo de replicação possui dois tijolos em servidores diferentes.
De fato, verifica-se o volume que combina os três RAID-1.
Ao montá-lo, obter o sistema de arquivos desejado e começar a gravar arquivos nele, você descobrirá que cada arquivo que você escreve cai em um desses grupos de replicação como um todo.
A distribuição de arquivos entre esses grupos distribuídos é feita pelo DHT (Distributed Hash Tables), que é essencialmente uma função de hash (retornaremos a ele mais tarde).
No "diagrama", ficará assim:
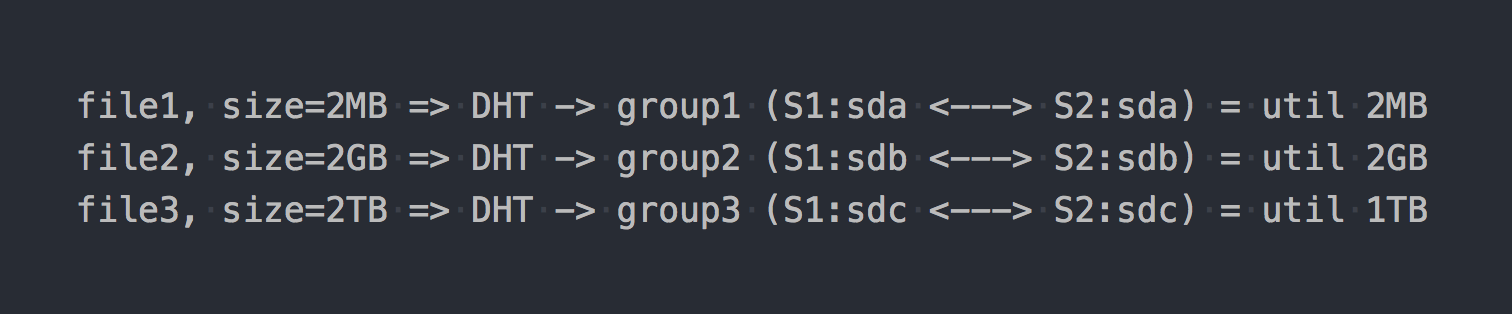
Como se os primeiros recursos arquitetônicos já estivessem manifestados:
- o local em grupos é descartado de maneira desigual, depende do tamanho do arquivo;
- ao escrever um arquivo, o IO vai para apenas um grupo, o restante fica ocioso;
- Você não pode obter o pedido de entrada / saída do volume inteiro ao escrever um único arquivo;
- se não houver espaço suficiente no grupo para gravar o arquivo, você receberá um erro, o arquivo não será gravado e será redistribuído para outro grupo.
Se você usar outros tipos de volumes, por exemplo, Replicado com distribuição distribuída ou até Disperso (codificação de eliminação), somente a mecânica da distribuição de dados em um grupo será fundamentalmente alterada. O DHT também decomporá os arquivos inteiramente nesses grupos e, no final, teremos os mesmos problemas. Sim, se o volume consistir em apenas um grupo ou se você tiver todos os arquivos aproximadamente do mesmo tamanho, não haverá problema. Mas estamos falando de sistemas normais, com centenas de terabytes de dados, incluindo arquivos de tamanhos diferentes, por isso acreditamos que há um problema.
Agora vamos dar uma olhada no CephFS. Os RADOS mencionados acima entram em cena. No RADOS, cada disco é servido por um processo separado - OSD. Com base em nossa configuração, obtemos apenas 6 deles, 3 em cada servidor. Em seguida, precisamos criar um pool para os dados e definir o número de PGs e o fator de replicação de dados nesse pool - no nosso caso 2.
Digamos que criamos um pool com 8 PG. Esses PGs serão distribuídos de maneira uniforme no OSD:
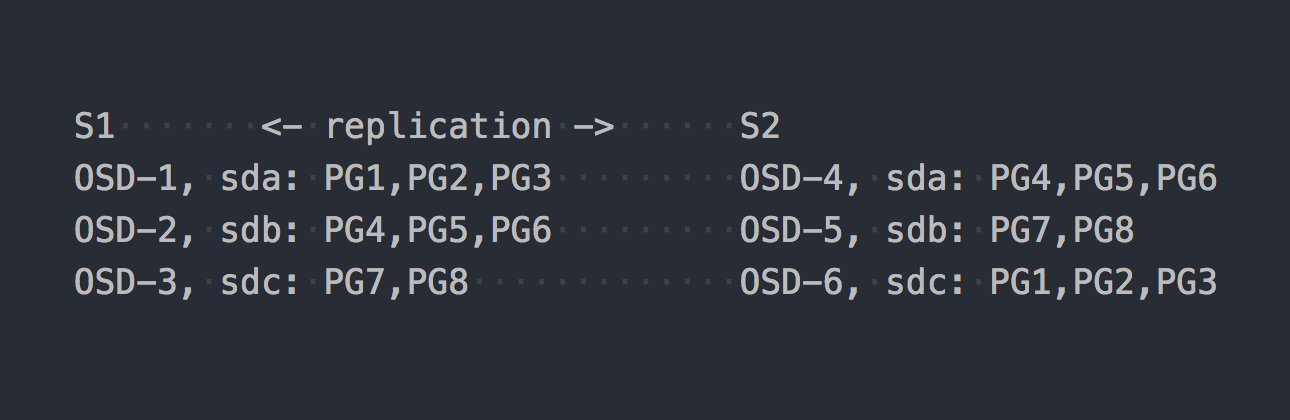
É hora de esclarecer que o PG é um grupo lógico que combina vários objetos. Como definimos o fato 2 da replicação, cada PG possui uma réplica em outro OSD em outro servidor (por padrão). Por exemplo, PG1, que está no OSD-1 no servidor S1, possui um gêmeo no S2 no OSD-6. Em cada par de PG (ou triplo, se a replicação 3) é PG PRIMÁRIO, que está sendo gravado. Por exemplo, PRIMARY para PG4 está em S1, mas PRIMARY para PG3 está em S2.
Agora que você sabe como o RADOS funciona, podemos passar a gravar arquivos em nosso novo pool. Embora o RADOS seja um armazenamento completo, não é possível montá-lo como um sistema de arquivos ou usá-lo como um dispositivo de bloco. Para gravar dados diretamente, você precisa usar um utilitário ou biblioteca especial.
Escrevemos os mesmos três arquivos que no exemplo acima:
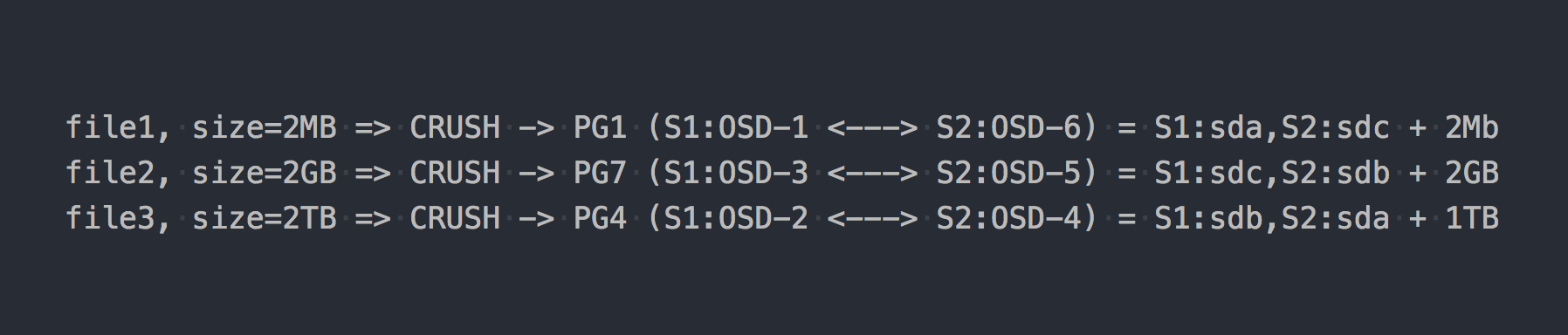
No caso do RADOS, tudo se tornou um pouco mais complicado, concorda.
Em seguida, CRUSH (Replicação Controlada sob Hashing Escalável) apareceu na cadeia. CRUSH é o algoritmo no qual o RADOS repousa (voltaremos a ele mais tarde). Nesse caso em particular, usando esse algoritmo, é determinado onde o arquivo deve ser gravado no qual PG. Aqui CRUSH executa a mesma função que DHT na gl. Como resultado dessa distribuição pseudo-aleatória de arquivos no PG, tivemos os mesmos problemas que o gl, apenas em um esquema mais complexo.
Mas, deliberadamente, fiquei em silêncio sobre um ponto importante. Quase ninguém usa o RADOS em sua forma pura. Para um trabalho conveniente com o RADOS, foram desenvolvidas as seguintes camadas: RBD, CephFS, RGW, que eu já mencionei.
Todos esses tradutores (clientes RADOS) fornecem uma interface de cliente diferente, mas são semelhantes em seu trabalho com o RADOS. A semelhança mais importante é que todos os dados que passam por eles são cortados em pedaços e colocados no RADOS como objetos RADOS separados. Por padrão, os clientes oficiais cortam o fluxo de entrada em pedaços de 4 MB. Para RBD, o tamanho da faixa pode ser definido ao criar o volume. No caso do CephFS, esse é o atributo (xattr) do arquivo e pode ser gerenciado no nível de arquivos individuais ou para todos os arquivos de catálogo. Bem, o RGW também tem um parâmetro correspondente.
Agora, suponha que empilhamos o CephFS em cima do pool RADOS que foi apresentado no exemplo anterior. Agora, os sistemas em questão estão em pé de igualdade e fornecem uma interface de acesso a arquivos idêntica.
Se gravarmos nossos arquivos de teste no novo CephFS, encontraremos uma distribuição de dados completamente diferente e quase uniforme no OSD. Por exemplo, o arquivo2 de tamanho de 2 GB será dividido em 512 partes, que serão distribuídas por diferentes PGs e, como resultado, por diferentes OSDs quase uniformemente, e isso praticamente resolve os problemas com a distribuição de dados descritos acima.
No nosso exemplo, apenas 8 PG são usados, embora seja recomendável ter ~ 100 PG em um OSD. E você precisa de dois pools para o CephFS funcionar. Você também precisa de alguns daemons de serviço para que o RADOS funcione em princípio. Não pense que tudo é tão simples, eu especificamente omito muito, para não me afastar da essência.
Então agora o CephFS parece mais interessante, certo? Mas não mencionei outro ponto importante, desta vez sobre gl. O Gl também possui um mecanismo para cortar arquivos em pedaços e executá-los através do DHT. O chamado sharding ( sharding ).
História de cinco minutos
Em 21 de abril de 2016, a equipe de desenvolvimento do Ceph lançou "Jewel", o primeiro lançamento do Ceph no qual o CephFS é considerado estável.
Agora está tudo à esquerda e à direita gritando sobre o CephFS! E há 3-4 anos atrás usá-lo seria pelo menos uma decisão duvidosa. Procuramos outras soluções e gl com a arquitetura descrita acima não era boa. Mas acreditamos nisso mais do que no CephFS e esperamos o sharding, que estava se preparando para o lançamento.
E aqui está o dia X:
4 de junho de 2015 - A Comunidade Gluster anunciou hoje a disponibilidade geral do software de armazenamento definido por software aberto GlusterFS 3.7.
3.7 - a primeira versão do gl, na qual o sharding foi anunciado como uma oportunidade experimental. Eles tinham quase um ano antes do lançamento estável do CephFS, a fim de ganhar uma posição no pódio ...
Então sharding significa. Como tudo no gl, isso é implementado em um tradutor separado, que ficava acima do DHT (também tradutor) na pilha. Como é maior que o DHT, o DHT recebe shards prontos na entrada e os distribui entre os grupos de replicação como arquivos regulares. O sharding é ativado no nível do volume individual. O tamanho do shard pode ser definido, por padrão - 4 MB, como loções Ceph.
Quando realizei os primeiros testes, fiquei encantado! Eu disse a todos que o gl agora é a melhor coisa e agora vamos viver! Com o sharding ativado, a gravação de um arquivo é paralela a diferentes grupos de replicação. A descompressão após a compressão "On-Write" pode ser incremental ao nível do shard. Na presença de gravação em cache também aqui, tudo se torna bom e os fragmentos individuais são movidos para o cache, e não para os arquivos inteiros. Em geral, eu me alegrei porque parecia que ele tinha conseguido um instrumento muito legal em suas mãos.
Resta aguardar as primeiras correções e o status de "pronto para produção". Mas tudo acabou não sendo tão otimista ... Para não esticar o artigo com uma lista de bugs críticos relacionados ao sharding, que surgem de vez em quando nas próximas versões, só posso dizer que o último "grande problema" com a seguinte descrição:
A expansão de um volume de gluster fragmentado pode causar corrupção de arquivo. Os volumes fragmentados são normalmente usados para imagens de VM; se esses volumes forem expandidos ou possivelmente contratados (por exemplo, adicionar / remover tijolos e reequilibrar), há relatórios de imagens de VM corrompidas.
foi fechado no release 3.13.2, 20 de janeiro de 2018 ... talvez este não seja o último?
Comentários sobre um de nossos artigos sobre isso, por assim dizer, em primeira mão.
O RedHat em sua documentação para o RedHat Gluster Storage 3.4 atual observa que o único caso de sharding que eles suportam é o armazenamento de discos de VM.
O Sharding possui um caso de uso suportado: no contexto de fornecer o Red Hat Gluster Storage como um domínio de armazenamento para o Red Hat Enterprise Virtualization, para fornecer armazenamento para imagens ativas de máquinas virtuais. Observe que o sharding também é um requisito para este caso de uso, pois fornece melhorias significativas de desempenho em relação às implementações anteriores.
Não sei por que essa restrição, mas você deve admitir, é alarmante.
Agora eu tenho tudo aqui para você
Ambos os sistemas usam uma função hash para distribuir dados pseudo-aleatoriamente entre discos.
Para o RADOS, é algo parecido com isto:
PG = pool_id + "." + jenkins_hash(object_name) % pg_coun # eg pool id=5 => pg = 5.1f OSD = crush_hash_based_on_jenkins(PG) # eg pg=5.1f => OSD = 12
Gl usa o chamado hash consistente . Cada tijolo recebe um "intervalo dentro de um espaço de hash de 32 bits". Ou seja, todos os tijolos compartilham todo o espaço de hash do endereço linear sem intervalos ou furos cruzados. O cliente executa o nome do arquivo através da função hash e determina em qual intervalo de hash o hash recebido se enquadra. Assim, o tijolo é selecionado. Se houver vários tijolos no grupo de replicação, todos eles terão o mesmo intervalo de hash. Algo assim:
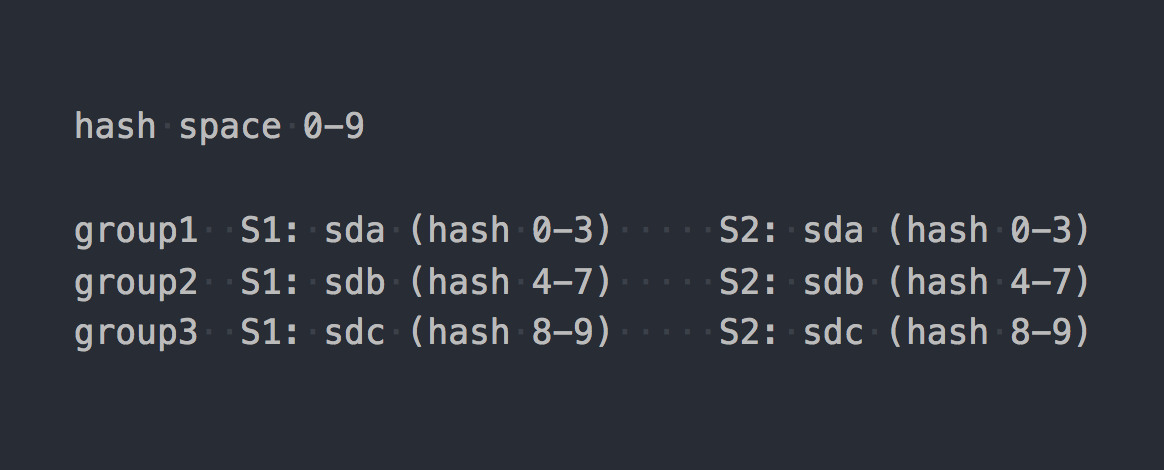
Se levarmos o trabalho de dois sistemas para uma determinada forma lógica, resultará algo assim:
file -> HASH -> placement_unit
onde a position_unit, no caso do RADOS, é PG, e no caso de gl, é um grupo de replicação de vários tijolos.
Portanto, uma função hash, então esta distribui, distribui arquivos e, de repente, verifica-se que uma unidade de posicionamento é utilizada mais que a outra. Essa é a característica fundamental dos sistemas de distribuição de hash. E enfrentamos uma tarefa muito comum - desequilibrar os dados.
O Gl é capaz de reconstruir, mas devido à arquitetura com intervalos de hash descritos acima, você pode executar a reconstrução o quanto quiser, mas nenhum intervalo de hash (e, como resultado, dados) não será alterado. O único critério para redistribuir intervalos de hash é uma alteração na capacidade do volume. E você tem uma opção restante - para adicionar tijolos. E se estamos falando de um volume com replicação, devemos adicionar um grupo inteiro de replicação, ou seja, dois novos tijolos em nossa configuração. Após expandir o volume, você pode começar a reconstruir - os intervalos de hash serão redistribuídos levando em consideração o novo grupo e os dados serão distribuídos. Quando um grupo de replicação é excluído, os intervalos de hash são alocados automaticamente.
RADOS tem um carro inteiro de possibilidades. Em um artigo da Ceph, reclamei muito sobre o conceito de PG, mas aqui, comparando com gl, é claro, RADOS a cavalo. Cada OSD tem seu próprio peso, geralmente é definido com base no tamanho do disco. Por sua vez, os PGs são distribuídos por OSD, dependendo do peso do último. Tudo, então apenas alteramos o peso do OSD para cima ou para baixo e o PG (junto com os dados) começa a se mover para outros OSDs. Além disso, cada OSD possui um peso de ajuste adicional, que permite equilibrar os dados entre os discos de um servidor. Tudo isso é inerente ao CRUSH. O principal lucro é que não é necessário expandir a capacidade do pool para desequilibrar melhor os dados. E não é necessário adicionar discos em grupos, você pode adicionar apenas um OSD e uma parte do PG será transferida para ele.
Sim, é possível que, ao criar um pool, eles não tenham criado PG suficiente e tenha acontecido que cada um dos PGs seja bastante grande em volume e, onde quer que eles se movam, o desequilíbrio permanecerá. Nesse caso, você pode aumentar o número de PG, e eles são divididos em menores. Sim, se o cluster estiver cheio de dados, dói, mas o principal em nossa comparação é que existe essa oportunidade. Agora, apenas um aumento no número de PGs é permitido e, com isso, você precisa ter mais cuidado, mas na próxima versão do Ceph - Nautilus, haverá suporte para reduzir o número de PGs (pág. Mesclada).
Replicação de dados
Nossos conjuntos de testes e volumes têm um fator de replicação 2. Curiosamente, os sistemas em questão usam abordagens diferentes para atingir esse número de réplicas.
No caso do RADOS, o esquema de gravação é mais ou menos assim:
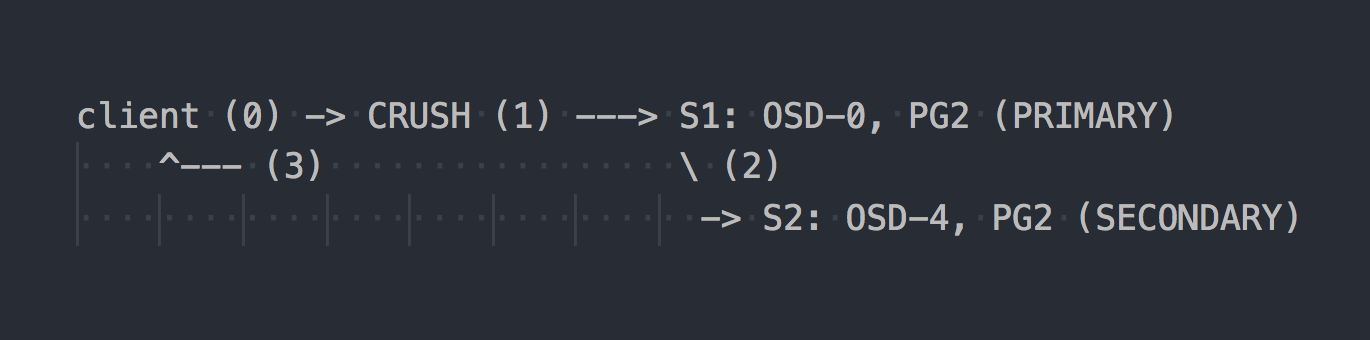
O cliente conhece a topologia de todo o cluster, usa CRUSH (etapa 0) para selecionar um PG específico para gravação, grava no PRIMARY PG no OSD-0 (etapa 1) e, em seguida, o OSD-0 replica os dados de forma síncrona no SECONDARY PG (etapa 2) e somente depois etapa 2 com ou sem êxito, o OSD confirma / não confirma a operação para o cliente (etapa 3). A replicação de dados entre dois OSDs é transparente para o cliente. OSDs geralmente podem usar um “cluster” separado, uma rede mais rápida para replicação de dados.
Se a replicação tripla estiver configurada, ela também será executada de forma síncrona com o OSD PRIMÁRIO em dois SECUNDÁRIOS, transparentes para o cliente ... bem, apenas essa permissão é maior.
Gl funciona de maneira diferente:
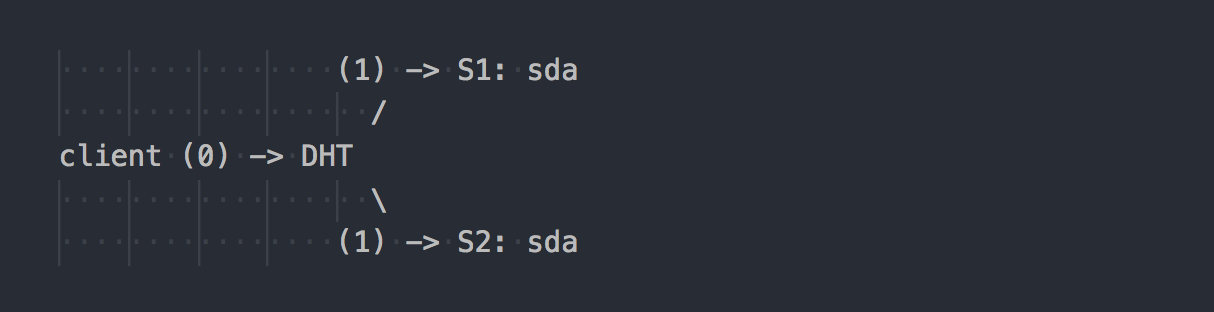
O cliente conhece a topologia do volume, usa DHT (etapa 0) para determinar o bloco desejado e, em seguida, grava nele (etapa 1). Tudo é simples e claro. Mas aqui lembramos que todos os tijolos no grupo de replicação têm o mesmo intervalo de hash. E esse recurso menor torna o feriado inteiro. O cliente grava em paralelo todos os tijolos que possuem um intervalo de hash adequado.
No nosso caso, com duplicação dupla, o cliente executa a gravação dupla em paralelo em dois tijolos diferentes. Durante a replicação tripla, a gravação tripla será realizada, respectivamente, e 1 MB de dados se transformará aproximadamente em 3 MB de tráfego de rede do cliente para o lado dos gl-servers. Concordo, os conceitos de sistemas são perpendiculares.
Nesse esquema, mais trabalho é atribuído ao cliente gl e, como resultado, ele precisa de mais CPU, bem, eu já disse sobre a rede.
A replicação é feita pelo tradutor AFP (Replicação Automática de Arquivos) - um xlator do lado do cliente que executa a replicação síncrona. Duplica as gravações em todos os tijolos da réplica → Usa um modelo de transação.
Se necessário, sincronize as réplicas no grupo (cura), por exemplo, após uma indisponibilidade temporária de um tijolo, os gl daemons fazem isso sozinhos usando o AFP interno, transparente para os clientes e sem a participação deles.
É interessante que, se você não trabalha com o gl client nativo, mas escreve com o servidor NFS embutido no gl, obteremos o mesmo comportamento do RADOS. Nesse caso, o AFP será usado nos gl daemons para replicar dados sem a intervenção do cliente. Mas o NFS interno é protegido na gl v4 e, se você deseja esse comportamento, é recomendável usar o NFS-Ganesha.
A propósito, devido a um comportamento tão diferente ao usar o NFS e o cliente nativo, você pode ver indicadores de desempenho completamente diferentes.
Você tem o mesmo cluster, apenas "no joelho"?
Muitas vezes vejo na Internet discussões de todos os tipos de configurações de rótulos, onde um cluster de dados é construído a partir do que está disponível. Nesse caso, uma solução baseada no RADOS pode oferecer mais liberdade ao escolher suas unidades. No RADOS, você pode adicionar unidades de praticamente qualquer tamanho. Cada disco terá um peso correspondente ao seu tamanho (geralmente) e os dados serão distribuídos pelos discos quase proporcionalmente ao seu peso. No caso de gl, não há conceito de "discos separados" em volumes com replicação. Os discos são adicionados em pares na replicação dupla ou tripla na tripla. Se houver discos de tamanhos diferentes em um grupo de replicação, você encontrará um local no menor disco do grupo e removerá a capacidade de discos grandes. Nesse esquema, gl assumirá que a capacidade de um grupo de replicação é igual à capacidade do menor disco do grupo, o que é lógico. Ao mesmo tempo, é permitido ter grupos de replicação consistindo em discos de tamanhos diferentes - grupos de tamanhos diferentes. Grupos maiores podem receber um intervalo de hash maior em relação a outros grupos e, como resultado, receber mais dados.
Vivemos com o Ceph pelo quinto ano. Começamos com discos do mesmo volume, agora apresentamos outros mais espaçosos. Com o Ceph, você pode remover o disco e substituí-lo por outro maior ou um pouco menor, sem dificuldades arquitetônicas. Com gl, tudo fica mais complicado - tirou um disco de 2 TB - coloque o mesmo, por favor. Bem, ou retire todo o grupo como um todo, o que não é muito bom, concorda.
Failover
Já nos familiarizamos um pouco com a arquitetura das duas soluções e agora podemos falar sobre como viver com ela e quais são os recursos ao fazer a manutenção.
Suponha que recusamos o sda no s1 - uma coisa comum.
No caso de gl:
- uma cópia dos dados no disco ativo restante no grupo não é redistribuída automaticamente para outros grupos;
- até que o disco seja substituído, apenas uma cópia dos dados permanece;
- ao substituir um disco com falha por um novo, a replicação é executada de um disco de trabalho para um novo (1 em 1).
É como servir uma prateleira com vários RAID-1s. Sim, com replicação tripla, se uma unidade falhar, não resta uma cópia, mas duas, mas ainda assim essa abordagem apresenta sérias desvantagens, e eu as mostrarei com um bom exemplo com o RADOS.
Suponha que falhemos sda no S1 (OSD-0) - uma coisa comum:
- Os PGs que estavam no OSD-0 serão remapeados automaticamente para outros OSDs após 10 minutos (padrão). No nosso exemplo, no OSD 1 e 2. Se houver mais servidores, em um número maior de OSD.
- Os PGs que armazenam a segunda cópia sobrevivente dos dados os replicam automaticamente para os OSDs para os quais os PGs restaurados são transferidos. Acontece replicação muitos-para-muitos, não replicação um-para-um como gl.
- Quando um novo disco é introduzido, em vez de um disco quebrado, alguns PGs serão acumulados de acordo com seu peso no novo OSD e os dados de outros OSDs serão redistribuídos.
Eu acho que não faz sentido explicar as vantagens arquitetônicas do RADOS. Você não pode se contorcer ao receber uma carta dizendo que a unidade falhou. E quando você chegar ao trabalho de manhã, descubra que todas as cópias ausentes já foram restauradas para dezenas de outros OSDs ou no processo. Em clusters grandes, onde centenas de PGs estão espalhados por vários discos, a recuperação de dados de um OSD pode ocorrer em velocidades muito superiores à velocidade de um disco, devido ao fato de que dezenas de OSDs estão envolvidos (leitura e gravação). Bem, você também não deve esquecer o balanceamento de carga.
Dimensionamento
Nesse contexto, provavelmente darei o pedestal gl. Em um artigo no Ceph, eu já escrevi sobre algumas das complexidades do dimensionamento do RADOS associadas ao conceito de PG. Se o aumento no PG com o crescimento do cluster ainda puder ser observado, o Ceph MDS não está claro. O CephFS é executado sobre o RADOS e usa um pool separado para metadados e um processo especial, o servidor de metadados seph (MDS), para atender os metadados do sistema de arquivos e coordenar todas as operações com o FS. Não estou dizendo que o MDS põe fim à escalabilidade do CephFS, não, especialmente porque você pode executar vários MDS no modo ativo-ativo. Eu só quero observar que gl é arquitetonicamente desprovido de tudo isso. Não possui contrapartida do PG, nada como o MDS. O Gl realmente escala perfeitamente, simplesmente adicionando grupos de replicação, quase linearmente.
Nos dias anteriores ao CephFS, projetamos a solução para petabytes de dados e analisamos o gl. Então tivemos dúvidas sobre a escalabilidade do gl e descobrimos através da lista de discussão. Aqui está uma das respostas (Q: minha pergunta):
Estou usando 60 servidores, cada um com discos de 26x8TB, volume total de 1560 discos 16 + 4 EC e 9PB de espaço útil.
P: Você usa libgfapi, FUSE ou NFS no lado do cliente?
Eu uso o FUSE e tenho quase 1000 clientes.
P: Quantos arquivos você tem no seu volume?
P: Os arquivos são maiores ou menores?
Eu tenho mais de 1 milhão de arquivos e% 13 do cluster é usado, o que torna o tamanho médio de 1 GB.
O tamanho mínimo / máximo do arquivo é 100 MB / 2 GB. Todos os dias, 10-20 TB de novos dados entram no volume.
P: Qual a rapidez com que "ls" funciona)?
As operações de metadados são lentas conforme o esperado. Eu tento não colocar mais de 2-3K arquivos em um diretório. Meu caso de uso é para backup / archive, por isso raramente faço operações de metadados.
Renomear arquivos
Voltar para as funções de hash novamente. Descobrimos como arquivos específicos são roteados para discos específicos e agora a pergunta se torna relevante, mas o que acontecerá ao renomear arquivos?
Afinal, se alterarmos o nome do arquivo, o hash em seu nome também mudará, o que significa o local desse arquivo em outro disco (em um intervalo de hash diferente) ou em outro PG / OSD no caso do RADOS. Sim, pensamos corretamente, e aqui em dois sistemas tudo é novamente perpendicular.
No caso de gl, ao renomear um arquivo, o novo nome é executado por meio de uma função hash, um novo bloco é definido e um link especial é criado nele para o bloco antigo, onde o arquivo permanece como antes. Topovka, certo? Para que os dados realmente sejam movidos para um novo local e o cliente não clicou no link desnecessariamente, é necessário fazer uma rebelião.
Mas o RADOS geralmente não possui um método para renomear objetos apenas devido à necessidade de seu movimento subsequente. É proposto o uso de cópias justas para renomear, o que leva ao movimento síncrono do objeto. E o CephFS, que roda sobre o RADOS, tem um trunfo na manga na forma de um pool com metadados e MDS. Alterar o nome do arquivo não afeta o conteúdo do arquivo no conjunto de dados.
Replicação 2.5
Gl tem um recurso muito interessante que eu gostaria de mencionar separadamente. Todo mundo entende que a replicação 2 não é uma configuração confiável, mas, no entanto, periodicamente é justificada. Para se proteger contra o cérebro dividido em tais esquemas e garantir a consistência dos dados, o gl permite criar volumes com a réplica 2 e um árbitro adicional. O árbitro é aplicável à replicação de 3 ou mais. Esse é o mesmo bloco no grupo que os outros dois, mas na verdade ele cria apenas uma estrutura de arquivos a partir de arquivos e diretórios. Os arquivos desse bloco são de tamanho zero, mas seus atributos estendidos do sistema de arquivos (atributos estendidos) são mantidos no estado sincronizado com arquivos de tamanho completo na mesma réplica. Eu acho que a ideia é clara. Eu acho que essa é uma oportunidade legal.
O único momento ... o tamanho do local no grupo de replicação é determinado pelo tamanho do menor tijolo, e isso significa que o árbitro precisa deslizar um disco pelo menos do mesmo tamanho que o resto do grupo. Para fazer isso, é recomendável criar tamanhos grandes e fictícios de LV fino (fino), para não usar um disco real.
E os clientes?
A API nativa dos dois sistemas é implementada na forma das bibliotecas libgfapi (gl) e libcephfs (CephFS). Ligações para idiomas populares também estão disponíveis. Em geral, com bibliotecas, tudo é igualmente bom. O onipresente NFS-Ganesha suporta as duas bibliotecas como o FSAL, que também é a norma. O Qemu também suporta a API gl nativa via libgfapi.
Mas o fio (Flexible I / O Tester) tem suportado o libgfapi por muito tempo e com êxito, mas não suporta o libcephfs. Este é um plus gl, porque usando fio é muito bom testar gl diretamente. Somente trabalhando no espaço do usuário através da libgfapi você obterá tudo o que pode da gl.
Mas se estamos falando sobre o sistema de arquivos POSIX e como montá-lo, o gl pode oferecer apenas o cliente FUSE e a implementação do CephFS no kernel upstream. É claro que no módulo do kernel você pode fazer um truque que o FUSE mostrará melhor desempenho. Mas, na prática, o FUSE é sempre uma sobrecarga na alternância de contexto. Eu pessoalmente vi mais de uma vez como o FUSE dobrou um servidor de soquete duplo com CSs sozinho.
De alguma forma, Linus disse:
Sistema de arquivos do espaço do usuário? O problema está aí. Sempre foi. As pessoas que pensam que os sistemas de arquivos do espaço do usuário são realistas para qualquer coisa, menos os brinquedos, são apenas equivocados.
Os desenvolvedores da Gl, pelo contrário, pensam que o FUSE é legal. Isso é dito para dar mais flexibilidade e desanexar das versões do kernel. Quanto a mim, eles usam o FUSE, porque gl não é velocidade. De alguma forma, está escrito - bem, é normal, e se preocupar com a implementação no kernel é realmente estranho.
Desempenho
Não haverá comparações).
Isso é muito complicado. Mesmo em uma configuração idêntica, é muito difícil realizar testes objetivos. De qualquer forma, haverá alguém nos comentários que fornecerá 100500 parâmetros que "aceleram" um dos sistemas e dizem que os testes são besteiras. Portanto, se estiver interessado, teste-se, por favor.
Conclusão
RADOS e CephFS, em particular, são uma solução mais complexa, tanto no entendimento, na configuração e na manutenção.
Mas, pessoalmente, eu gosto mais da arquitetura do RADOS e da execução no CephFS do que no GlusterFS. Mais identificadores (PG, peso OSD, hierarquia CRUSH etc.), os metadados do CephFS aumentam a complexidade, mas oferecem mais flexibilidade e tornam essa solução mais eficaz, na minha opinião.
O Ceph é muito mais adequado aos critérios atuais de SDS e me parece mais promissor. Mas esta é a minha opinião, o que você acha?