Tradução de arquiteturas de redes neuraisAtualmente, os algoritmos de redes neurais profundas ganharam grande popularidade, o que é amplamente garantido pela arquitetura bem pensada. Vamos dar uma olhada na história de seu desenvolvimento nos últimos anos. Se você estiver interessado em uma análise mais profunda, consulte
este trabalho .
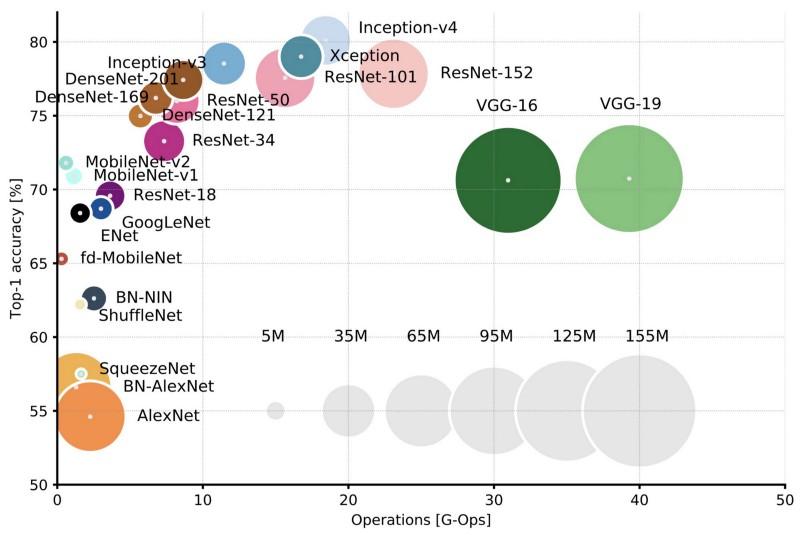 Comparação de arquiteturas populares para a melhor precisão de uma colheita e o número de operações necessárias para uma passagem direta. Mais detalhes aqui .
Comparação de arquiteturas populares para a melhor precisão de uma colheita e o número de operações necessárias para uma passagem direta. Mais detalhes aqui .Lenet5
Em 1994, uma das primeiras redes neurais convolucionais foi desenvolvida, que lançou as bases para o aprendizado profundo. Este trabalho pioneiro de Yann LeCun, após muitas iterações bem-sucedidas desde 1988, foi chamado
LeNet5 !

A arquitetura LeNet5 tornou-se fundamental para o aprendizado profundo, especialmente em termos da distribuição das propriedades da imagem por toda a imagem. Convoluções com parâmetros de aprendizado permitiram o uso de vários parâmetros para extrair eficientemente as mesmas propriedades de lugares diferentes. Naqueles anos, não havia placas de vídeo que pudessem acelerar o processo de aprendizado, e até os processadores centrais eram lentos. Portanto, a principal vantagem da arquitetura era a capacidade de salvar parâmetros e resultados de cálculos, em contraste com o uso de cada pixel como dados de entrada separados para uma grande rede neural multicamada. No LeNet5, os pixels não são usados na primeira camada, porque as imagens são fortemente correlacionadas espacialmente, portanto, o uso de pixels individuais como propriedades de entrada não permitirá que você aproveite essas correlações.
Recursos do LeNet5:
- Uma rede neural convolucional usando uma sequência de três camadas: camadas de convolução, camadas de pool e camadas de não linearidade -> desde a publicação do trabalho de Lekun, essa talvez seja uma das principais características do aprendizado profundo em relação às imagens.
- Usa convolução para recuperar propriedades espaciais.
- Subamostragem usando a média do mapa espacial.
- Não linearidade na forma de tangente hiperbólica ou sigmóide.
- O classificador final na forma de uma rede neural multicamada (MLP).
- A matriz esparsa de conectividade entre as camadas reduz a quantidade de computação.
Essa rede neural formou a base de muitas arquiteturas subseqüentes e inspirou muitos pesquisadores.
Desenvolvimento
De 1998 a 2010, as redes neurais estavam em estado de incubação. A maioria das pessoas não percebeu suas capacidades crescentes, embora muitos desenvolvedores aprimorassem gradualmente seus algoritmos. Graças ao auge das câmeras de celular e ao baixo custo das câmeras digitais, mais e mais dados de treinamento se tornaram disponíveis para nós. Ao mesmo tempo, os recursos de computação aumentaram, os processadores se tornaram mais poderosos e as placas de vídeo se tornaram a principal ferramenta de computação. Todos esses processos permitiram o desenvolvimento de redes neurais, embora de maneira bastante lenta. O interesse em tarefas que poderiam ser resolvidas com a ajuda de redes neurais estava crescendo e, finalmente, a situação se tornou óbvia ...
Dan ciresan net
Em 2010, Dan Claudiu Ciresan e Jurgen Schmidhuber publicaram uma das primeiras descrições da implementação de
redes neurais da
GPU . O trabalho deles continha a implementação direta e reversa de uma rede neural de 9 camadas na
NVIDIA GTX 280 .
Alexnet
Em 2012, Alexei Krizhevsky publicou o
AlexNet , uma versão detalhada e ampliada do LeNet, que venceu por uma ampla margem no concurso ImageNet.
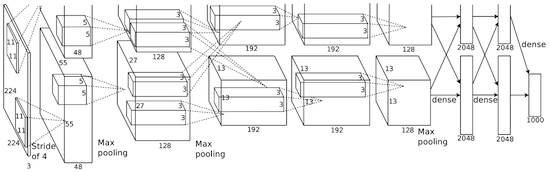
Na AlexNet, os resultados dos cálculos do LeNet são redimensionados em uma rede neural muito maior, capaz de estudar objetos muito mais complexos e suas hierarquias. Recursos desta solução:
- Uso de unidades de retificação linear (ReLU) como não linearidades.
- O uso de técnicas de descarte para ignorar seletivamente neurônios individuais durante o treinamento, o que evita o excesso de treinamento do modelo.
- Sobreposição de pool máximo, que evita os efeitos da média de pool médio.
- Usando o NVIDIA GTX 580 para acelerar o aprendizado.
Naquela época, o número de núcleos nas placas de vídeo havia crescido significativamente, o que lhes permitiu reduzir o tempo de treinamento em cerca de 10 vezes e, como resultado, tornou-se possível usar conjuntos de dados e imagens muito maiores.
O sucesso da AlexNet lançou uma pequena revolução: redes neurais convolucionais se transformaram em um cavalo de batalha de aprendizado profundo - este termo agora significa "grandes redes neurais que podem resolver problemas úteis".
Overfeat
Em dezembro de 2013, o laboratório da NYU de Jan Lekun publicou uma descrição do
Overfeat , uma variante do AlexNet. Além disso, o artigo descreveu as caixas delimitadoras treinadas e, posteriormente, muitos outros trabalhos sobre esse tópico foram publicados. Acreditamos que é melhor aprender a segmentar objetos, em vez de usar caixas delimitadoras artificiais.
Vgg
Nas redes
VGG desenvolvidas em Oxford, em cada camada convolucional, pela primeira vez, foram utilizados filtros 3x3, e mesmo essas camadas foram combinadas em uma sequência de convoluções.
Isso contradiz os princípios estabelecidos no LeNet, segundo os quais grandes convoluções foram usadas para extrair as mesmas propriedades de imagem. Em vez dos filtros 9x9 e 11x11 usados no AlexNet, começaram a ser usados filtros muito menores, perigosamente próximos às convoluções 1x1, que os autores da LeNet tentaram evitar, pelo menos nas primeiras camadas da rede. Mas a grande vantagem do VGG foi a descoberta de que várias convoluções 3x3 combinadas em uma sequência podem emular campos receptivos maiores, por exemplo, 5x5 ou 7x7. Essas idéias serão usadas posteriormente nas arquiteturas Inception e ResNet.
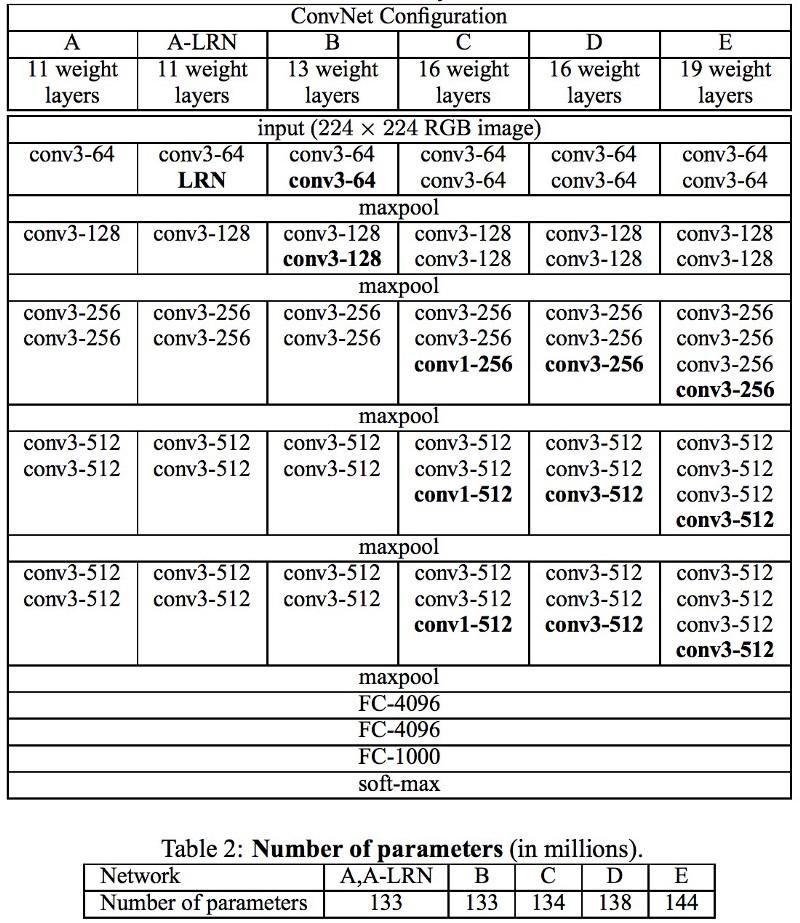
As redes VGG usam várias camadas convolucionais 3x3 para representar propriedades complexas. Preste atenção aos blocos 3, 4 e 5 no VGG-E: para extrair propriedades mais complexas e combiná-las, são usadas seqüências de filtro 256 × 256 e 512 × 512 3 × 3. Isso é equivalente a um classificador convolucional grande de 512x512 com três camadas! Isso nos dá um grande número de parâmetros e excelentes habilidades de aprendizado. Mas foi difícil aprender essas redes; tive que dividi-las em redes menores, adicionando camadas uma a uma. O motivo foi a falta de maneiras eficazes de regularizar modelos ou de alguns métodos para limitar um grande espaço de pesquisa, promovido por muitos parâmetros.
O VGG em muitas camadas usa um grande número de propriedades, portanto, o treinamento era
computacionalmente caro . A carga pode ser reduzida reduzindo o número de propriedades, como é feito nas camadas de gargalo da arquitetura Inception.
Rede em rede
A arquitetura
Rede em rede (NiN) é baseada em uma idéia simples: usando convoluções 1x1 para aumentar a combinatória de propriedades em camadas convolucionais.
No NiN, após cada convolução, as camadas espaciais de MLP são usadas para combinar melhor as propriedades antes de passar para a próxima camada. Pode parecer que o uso de convoluções 1x1 contradiga os princípios originais do LeNet, mas, na realidade, permite combinar propriedades melhor do que apenas encher camadas mais convolucionais. Essa abordagem é diferente de usar pixels nus como entrada para a próxima camada. Nesse caso, convoluções 1x1 são usadas para combinação espacial de propriedades após a convolução na estrutura dos mapas de propriedades, para que você possa usar muito menos parâmetros comuns a todos os pixels dessas propriedades!
O MLP pode aumentar bastante a eficácia das camadas convolucionais individuais, combinando-as em grupos mais complexos. Essa ideia foi usada posteriormente em outras arquiteturas, como ResNet, Inception e suas variantes.
GoogLeNet e Iniciação
O Google Christian Szegedy está preocupado com a redução de cálculos em redes neurais profundas e, como resultado, criou o
GoogLeNet, a primeira arquitetura de Iniciação .
No outono de 2014, os modelos de aprendizado profundo tornaram-se muito úteis na categorização do conteúdo da imagem e dos quadros dos vídeos. Muitos céticos reconheceram os benefícios do aprendizado profundo e das redes neurais, e os gigantes da Internet, incluindo o Google, ficaram muito interessados em implantar redes grandes e eficientes nas capacidades de seus servidores.
Christian estava procurando maneiras de reduzir a carga computacional nas redes neurais, alcançando o desempenho mais alto (por exemplo, no ImageNet). Ou preservando a quantidade de computação, mas ainda aumentando a produtividade.
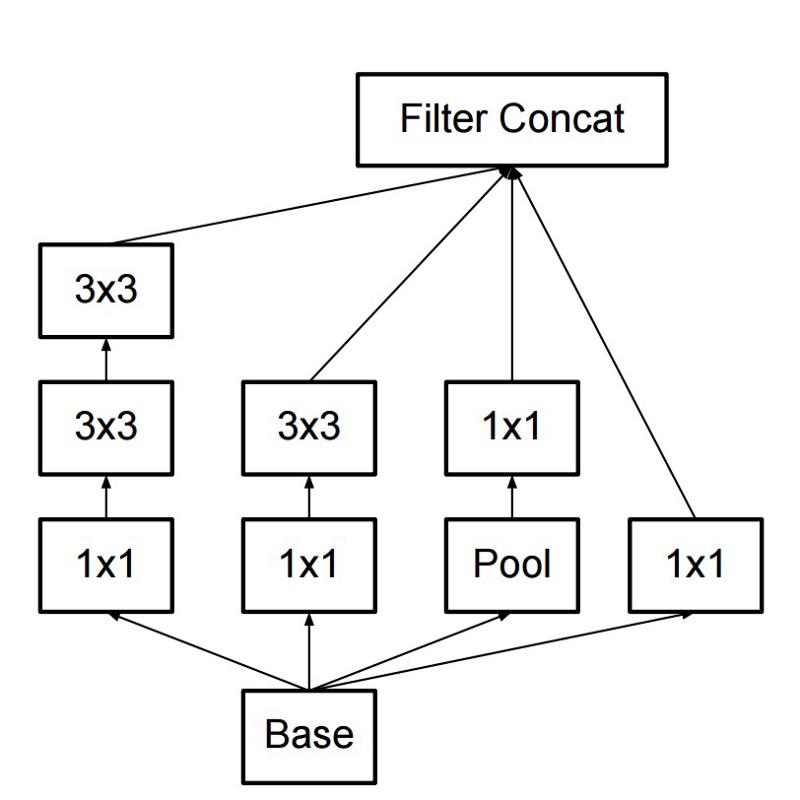
Como resultado, o comando criou um módulo de Iniciação:

À primeira vista, essa é uma combinação paralela de filtros convolucionais 1x1, 3x3 e 5x5. Mas o destaque foi o uso dos blocos de convolução 1x1 (NiN) para reduzir o número de propriedades antes de servir nos blocos paralelos "caros". Geralmente, essa parte é chamada de gargalo, é descrita em mais detalhes no próximo capítulo.
O GoogLeNet usa uma haste sem módulos de iniciação como a camada inicial e também usa pool médio e um classificador softmax semelhante ao NiN. Este classificador executa muito poucas operações em comparação com AlexNet e VGG. Também ajudou a criar uma
arquitetura de rede neural muito eficiente .
Camada de gargalo
Essa camada reduz o número de propriedades (e, portanto, operações) em cada camada, para que a velocidade de obtenção do resultado possa ser mantida em um nível alto. Antes de transferir dados para módulos convolucionais "caros", o número de propriedades é reduzido, digamos, 4 vezes. Isso reduz bastante a quantidade de computação, o que tornou a arquitetura popular.
Vamos descobrir. Suponha que tenhamos 256 propriedades na entrada e 256 na saída e permita que a camada de Iniciação execute apenas convoluções 3x3. Temos convoluções 256x256x3x3 (589.000 operações de multiplicação de acumulação, ou seja, operações MAC). Isso pode ir além de nossos requisitos de velocidade computacional; digamos que uma camada seja processada em 0,5 milissegundos no Google Server. Em seguida, reduza o número de propriedades para dobrar para 64 (256/4). Nesse caso, primeiro executamos uma convolução 1x1 de 256 -> 64, depois outra convolução 64 em todas as ramificações do Inception e, em seguida, novamente aplicamos uma convolução 1x1 de 64 -> 256 propriedades. Número de operações:
- 256 × 64 × 1 × 1 = 16.000
- 64 × 64 × 3 × 3 = 36.000
- 64 × 256 × 1 × 1 = 16.000
Apenas cerca de 70.000 reduziram o número de operações em quase 10 vezes! Mas, ao mesmo tempo, não perdemos a generalização nessa camada. As camadas de gargalo mostraram excelente desempenho no conjunto de dados do ImageNet e foram usadas em arquiteturas posteriores, como o ResNet. A razão do sucesso deles é que as propriedades de entrada estão correlacionadas, o que significa que você pode se livrar da redundância combinando corretamente as propriedades com as convoluções 1x1. E depois de dobrar com menos propriedades, você poderá implantá-las novamente em uma combinação significativa na próxima camada.
Iniciação V3 (e V2)
Christian e sua equipe provaram ser pesquisadores muito eficazes. Em fevereiro de 2015, a arquitetura
Inception normalizada em lote foi introduzida como a segunda versão do
Inception . A normalização em lote calcula a média e o desvio padrão de todos os mapas de distribuição de propriedades na camada de saída e normaliza suas respostas com esses valores. Isso corresponde ao "branqueamento" dos dados, ou seja, as respostas de todos os mapas neurais estão no mesmo intervalo e com média zero. Essa abordagem facilita o aprendizado, porque a próxima camada não é necessária para lembrar as compensações dos dados de entrada e pode procurar apenas as melhores combinações de propriedades.
Em dezembro de 2015, uma
nova versão dos módulos Inception e a arquitetura correspondente foram lançadas . O artigo do autor explica melhor a arquitetura original do GoogLeNet, que conta muito mais sobre as decisões tomadas. Ideias-chave:
- Maximizar o fluxo de informações na rede devido ao cuidadoso equilíbrio entre sua profundidade e largura. Antes de cada pool, os mapas de propriedades aumentam.
- Com o aumento da profundidade, o número de propriedades ou a largura da camada também aumenta sistematicamente.
- A largura de cada camada aumenta para aumentar a combinação de propriedades antes da próxima camada.
- Na medida do possível, apenas convoluções 3x3 são usadas. Dado que os filtros 5x5 e 7x7 podem ser decompostos usando múltiplos 3x3
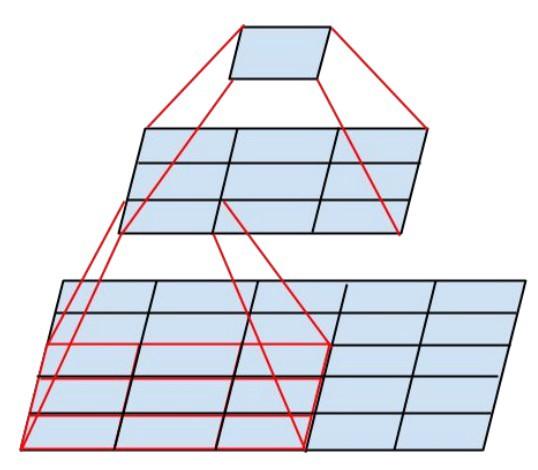
O novo módulo de iniciação é assim:
- Os filtros também podem ser decompostos usando convoluções suavizadas em módulos mais complexos:

- Os módulos de iniciação podem reduzir o tamanho dos dados usando o pool durante os cálculos de iniciação. É semelhante a realizar convolução com passos paralelos a uma camada de pool simples:

O início usa a camada de pool com softmax como classificador final.
Resnet
Em dezembro de 2015, aproximadamente ao mesmo tempo em que a arquitetura Inception v3 foi introduzida, ocorreu uma revolução - eles publicaram a
ResNet . Ele contém idéias simples: envie a saída de duas camadas convolucionais bem-sucedidas e ignore a entrada da próxima camada!

Tais idéias já foram propostas, por exemplo,
aqui . Mas, neste caso, os autores ignoram DUAS camadas e aplicam a abordagem em larga escala. Ignorar uma camada não oferece muitos benefícios e ignorar duas é uma descoberta fundamental. Isso pode ser visto como um pequeno classificador, como rede em rede!
Foi também o primeiro exemplo de treinamento de uma rede de várias centenas, até milhares de camadas.
O MulNet ResNet usou uma camada de gargalo semelhante à usada no Inception:

Essa camada reduz o número de propriedades em cada camada, primeiro usando uma convolução 1x1 com uma saída menor (geralmente um quarto da entrada), depois uma camada 3x3 e, novamente, convertendo 1x1 em um número maior de propriedades. Como no caso dos módulos Inception, isso economiza recursos computacionais enquanto mantém uma variedade de combinações de propriedades. Compare com os caules mais complexos e menos óbvios no Inception V3 e V4.
O ResNet usa uma camada de pool com softmax como classificador final.
Todos os dias, informações adicionais sobre a arquitetura ResNet são exibidas:
- Pode ser considerado como um sistema de módulos paralelos e seriais simultaneamente: em muitos módulos o sinal de entrada é paralelo e os sinais de saída de cada módulo são conectados em série.
- O ResNet pode ser considerado como vários conjuntos de módulos paralelos ou seriais .
- Descobriu-se que o ResNet geralmente opera com blocos de profundidade relativamente pequenos de 20 a 30 camadas trabalhando em paralelo, em vez de executar seqüencialmente ao longo de todo o comprimento da rede.
- Como o sinal de saída volta e é alimentado como entrada, como é feito na RNN, o ResNet pode ser considerado um modelo plausível aprimorado do córtex cerebral .
Início V4
Christian e sua equipe se destacaram novamente com uma
nova versão do Inception .
O módulo de criação a seguir é o mesmo que no Inception V3:

Nesse caso, o módulo Inception é combinado com o módulo ResNet:

Essa arquitetura acabou sendo, para mim, mais complicada, menos elegante e também cheia de soluções heurísticas opacas. É difícil entender por que os autores tomaram essas ou aquelas decisões e é igualmente difícil fazer qualquer tipo de avaliação.
Portanto, o prêmio por uma rede neural limpa e simples, fácil de entender e modificar, vai para o ResNet.
Squeezenet
SqueezeNet publicado recentemente. Este é um remake de uma nova maneira de muitos conceitos do ResNet e do Inception. Os autores demonstraram que melhorar a arquitetura reduz o tamanho da rede e o número de parâmetros sem algoritmos de compactação complexos.
ENet
Todos os recursos das arquiteturas recentes são combinados em uma rede muito eficiente e compacta, usando muito poucos parâmetros e poder de computação, mas, ao mesmo tempo, oferecendo excelentes resultados. A arquitetura foi chamada
ENet , foi desenvolvida por Adam Paszke (
Adam Paszke ). Por exemplo, nós o usamos para marcar objetos de maneira muito precisa na tela e analisar cenas.
Alguns exemplos de Enet . Esses vídeos não estão relacionados ao
conjunto de dados de treinamento .
Aqui você pode encontrar os detalhes técnicos da ENet. É uma rede baseada em codificador e decodificador. O codificador é construído no esquema usual de categorização da CNN e o decodificador é uma rede de upsampling projetada para segmentação, espalhando as categorias de volta à imagem em tamanho original. Para a segmentação de imagens, foram utilizadas apenas redes neurais, sem outros algoritmos.
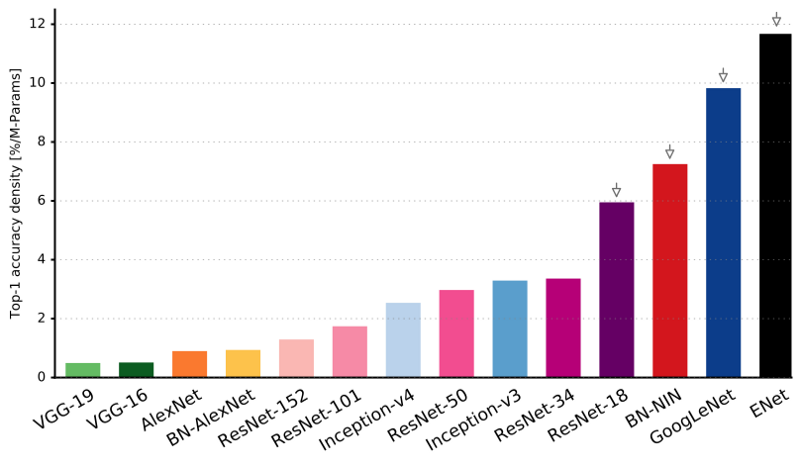
Como você pode ver, o ENet tem a maior precisão específica em comparação com todas as outras redes neurais.
O ENet foi projetado para usar o mínimo de recursos possível desde o início. Como resultado, o codificador e o decodificador juntos ocupam apenas 0,7 MB com precisão fp16. E com um tamanho tão pequeno, o ENet não é inferior à precisão da segmentação ou superior a outras soluções de rede puramente neurais.
Análise de módulo
Publicou uma avaliação sistemática dos módulos da CNN. Acabou sendo benéfico:
- Use a não linearidade da ELU sem normalização do lote (batchnorm) ou ReLU com normalização.
- Aplique a transformação aprendida do espaço de cores RGB.
- Use uma política de redução linear da taxa de aprendizado.
- Use a soma da camada média e máxima do pool.
- Use um mini-pacote de 128 ou 256. Se isso for demais para sua placa de vídeo, reduza a velocidade de aprendizado proporcionalmente ao tamanho do pacote.
- Use camadas totalmente conectadas como camadas convolucionais e previsões médias para fornecer a solução final.
- Se você aumentar o tamanho do conjunto de dados de treinamento, verifique se você não atingiu um platô no treinamento. A limpeza dos dados é mais importante que o tamanho.
- Se você não puder aumentar o tamanho da imagem de entrada, reduzir o passo nas camadas subseqüentes, o efeito será aproximadamente o mesmo.
- Se sua rede possui uma arquitetura complexa e altamente otimizada, como no GoogLeNet, modifique-a com cuidado.
Xception
A Xception introduziu uma arquitetura mais simples e elegante no módulo Inception, que não é menos eficiente que o ResNet e o Inception V4.
É assim que o módulo Xception se parece:
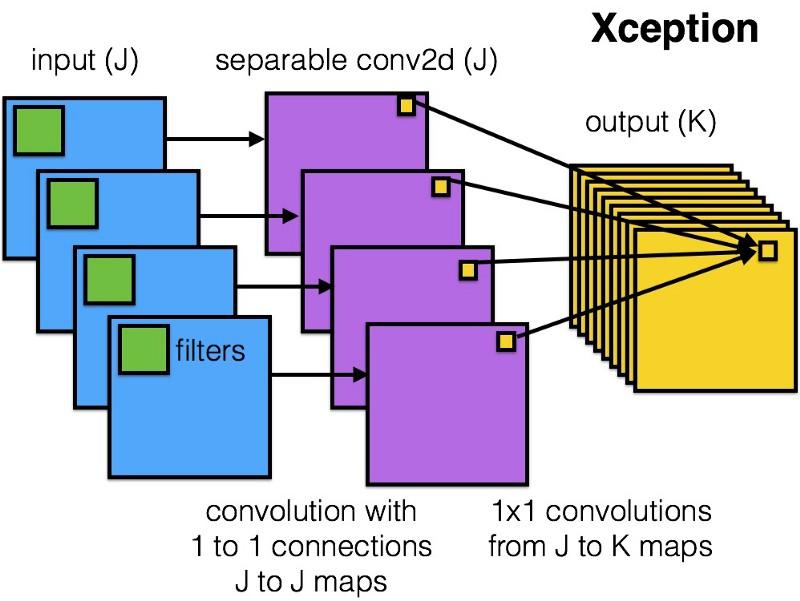
Qualquer pessoa gostará desta rede devido à simplicidade e elegância de sua arquitetura:

Ele contém 36 etapas de convolução e é semelhante ao ResNet-34. Ao mesmo tempo, o modelo e o código são simples, como no ResNet, e muito mais agradáveis do que no Inception V4.
Uma implementação torch7 dessa rede está disponível
aqui , enquanto uma implementação Keras / TF está disponível aqui.
Curiosamente, os autores da recente arquitetura Xception também foram inspirados pelo
nosso trabalho em filtros convolucionais separáveis .
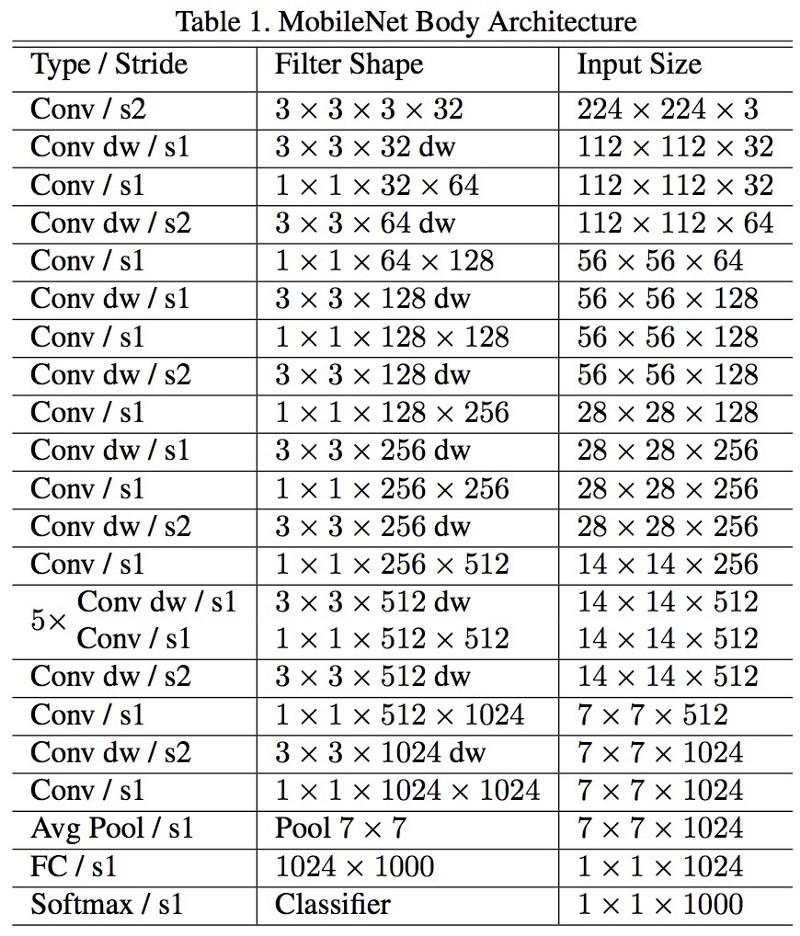
MobileNets
A nova arquitetura do M
obileNets foi lançada em abril de 2017. Para reduzir o número de parâmetros, ele usa convoluções destacáveis, o mesmo que no Xception. Também é afirmado no trabalho que os autores foram capazes de reduzir bastante o número de parâmetros: cerca de metade no caso do FaceNet. :
, 1 (batch of 1) Titan Xp. :
- resnet18: 0,002871
- alexnet: 0,001003
- vgg16: 0,001698
- squeezenet: 0,002725
- mobilenet: 0,033251
! , .
FractalNet , ImageNet ResNet.
, . , .
, , , , ? , .
.
, . , .
, .
.