
Olá Habr! Dois anos atrás,
escrevemos sobre como mudamos para o PHP 7.0 e economizamos um milhão de dólares. Em nosso perfil de carregamento, a nova versão mostrou ser duas vezes mais eficiente no uso da CPU: o carregamento que costumávamos atender a ~ 600 servidores, depois que a transição começou a servir ~ 300. Como resultado, por dois anos tivemos uma reserva de capacidades.
Mas o Badoo está crescendo. O número de usuários ativos está aumentando constantemente. Estamos melhorando e desenvolvendo nossa funcionalidade, graças à qual os usuários passam cada vez mais tempo no aplicativo. E isso, por sua vez, se reflete no número de solicitações, que nos últimos dois anos aumentaram de 2 a 2,5 vezes.
Nos encontramos em uma situação em que um ganho duplo de desempenho foi nivelado por mais de um aumento duplo de solicitações e novamente começamos a abordar os limites do cluster. No núcleo do PHP,
otimizações úteis (JIT, pré-carregamento) são novamente esperadas, mas são planejadas apenas para o PHP 7.4, e esta versão será lançada não antes de um ano. Portanto, o truque de transição não pode ser repetido agora - você precisa otimizar o próprio código do aplicativo.
Abaixo, mostrarei como abordamos essas tarefas, quais ferramentas usamos e mostrarei exemplos de otimizações, idéias e abordagens que aplicamos e que nos ajudaram em nosso tempo.
Por que otimizar
A maneira mais fácil e óbvia de resolver o problema de desempenho é adicionar ferro. Se o seu código for executado no mesmo servidor, a adição de mais um duplicará o desempenho do seu cluster. Transferindo esses custos para o tempo de trabalho do desenvolvedor, nos perguntamos: ele conseguirá um aumento duplo de produtividade durante esse período devido a otimizações? Talvez sim, mas talvez não: depende de quão otimamente o sistema já está funcionando e de quão bom é o desenvolvedor. Por outro lado, o servidor adquirido permanecerá propriedade da empresa e o tempo gasto não será devolvido.
Acontece que em pequenos volumes a solução correta será frequentemente a adição de ferro.
Mas leve a nossa situação. Agora, depois que o ganho da mudança para o PHP 7.0 foi compensado pelo crescimento da atividade e pelo número de usuários, novamente temos 600 servidores atendendo solicitações ao aplicativo PHP. Para aumentar a capacidade uma vez e meia, precisamos adicionar 300 servidores.
Tome como cálculo o custo médio de um servidor - US $ 4.000. 300 * 4000 = US $ 1.200.000 - o custo de aumentar a capacidade uma vez e meia.
Ou seja, em nossas condições, podemos investir uma quantidade significativa de tempo de trabalho na otimização do sistema, e ainda será mais lucrativo do que comprar ferro.
Planejamento de capacidade
Antes de empreender qualquer coisa, é importante entender se há algum problema. Se ela não estiver lá, vale a pena tentar prever quando ela poderá aparecer. Esse processo é chamado de planejamento de capacidade.
Um indicador concreto da presença de problemas de desempenho é o tempo de resposta. Na verdade, não importa se a CPU (ou outros recursos) é carregada em 6% ou 146%: se um cliente recebe um serviço da qualidade necessária em um tempo satisfatório, tudo funciona bem.
A desvantagem de se concentrar no tempo de resposta é que ele geralmente começa a aumentar apenas quando o problema já apareceu. Se ainda não é, é difícil prever sua aparência. Além disso, o tempo de resposta reflete os resultados da influência de todos os fatores (serviços de frenagem, rede, unidades, etc.) e não fornece uma compreensão das causas dos problemas.
No nosso caso, a CPU geralmente é o gargalo; portanto, ao planejar o tamanho e o desempenho dos clusters, prestamos atenção principalmente às métricas associadas ao seu uso. Coletamos o uso da CPU de todas as nossas máquinas e construímos gráficos com o valor médio, mediana, percentil 75 e 95:
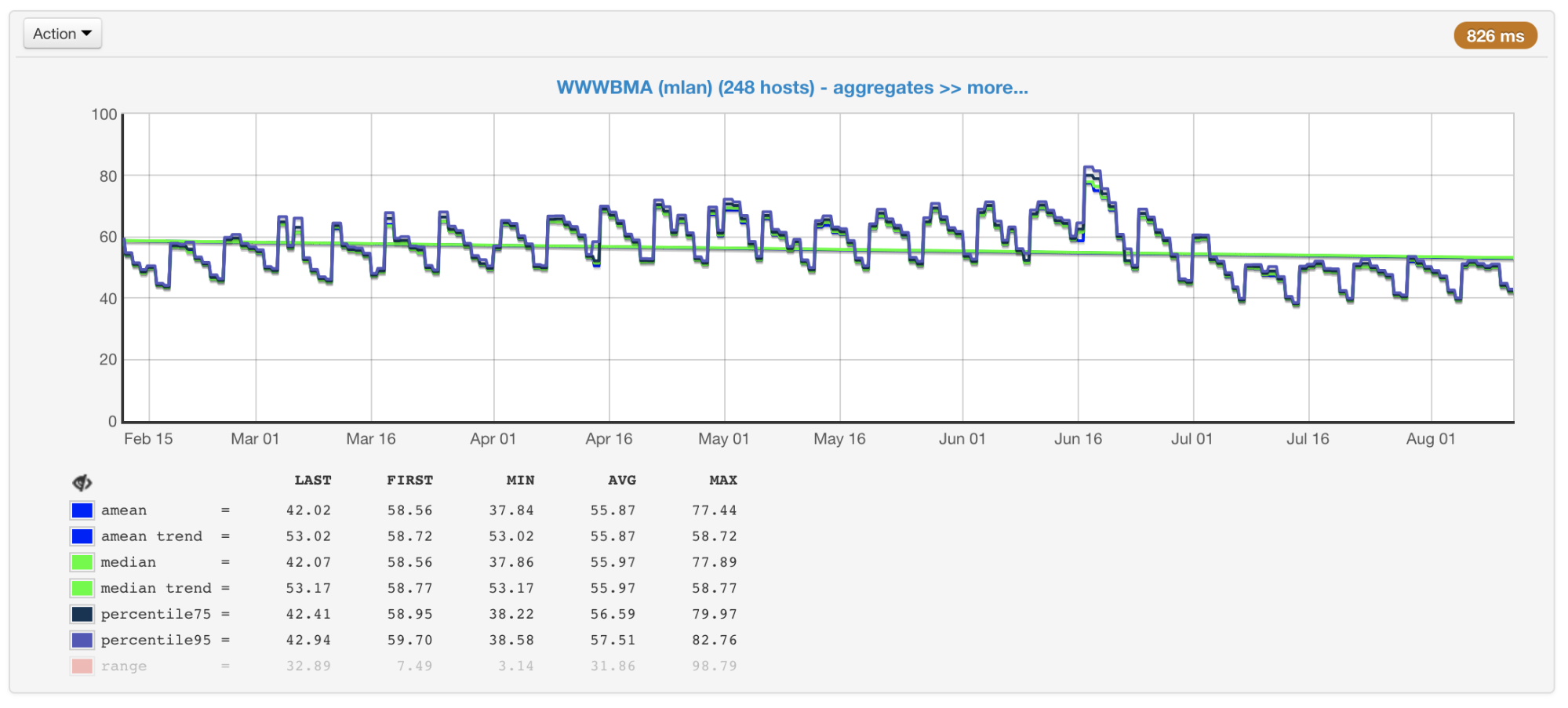 Utilização da CPU de máquinas de cluster em porcentagem: média, mediana, percentis
Utilização da CPU de máquinas de cluster em porcentagem: média, mediana, percentisExistem centenas de máquinas em nossos clusters que foram adicionadas lá por muitos anos. Eles são diferentes em configuração e desempenho (o cluster não é homogêneo). Nosso balanceador leva isso em consideração (
artigo e
vídeo ) e carrega as máquinas de acordo com suas capacidades. Para controlar esse processo, também temos um cronograma de máquinas com carga máxima e mínima.
 As máquinas de cluster mais e menos carregadas
As máquinas de cluster mais e menos carregadasSe você olhar esses gráficos (ou apenas a saída do comando top) e ver a carga da CPU de 50%, você pensaria que ainda temos uma margem para um aumento duplo na carga. Mas, na verdade, esse geralmente não é o caso. E aqui está o porquê.
Hyper threading
Imagine um único núcleo sem hiper-pisar. Nós o carregamos com um thread vinculado à CPU. Veremos 100% de carregamento na parte superior.
Agora ative a hiper-leitura neste kernel e carregue-o exatamente da mesma maneira. No topo, já veremos dois núcleos lógicos e a carga total será de 50% (geralmente em um 0% e no outro 100%).
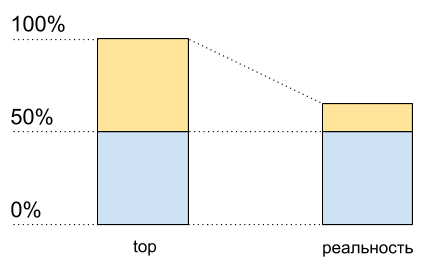 Utilização da CPU: principais dados e o que realmente acontece
Utilização da CPU: principais dados e o que realmente aconteceComo se o processador tivesse apenas 50% de carga. Mas fisicamente nenhum núcleo livre adicional apareceu. O Hypertreading permite,
em alguns casos, executar em um núcleo físico mais de um processo por vez. Mas isso está longe de dobrar o desempenho em situações típicas, embora no gráfico de uso da CPU pareça metade dos recursos: de 50% a 100%.
Isso significa que, após 50% do uso da CPU quando o hipertreading estiver ativado, ele não crescerá da mesma forma que antes.
Eu escrevi este código para demonstrar (este é algum tipo de caso sintético, na realidade os resultados serão diferentes):
Código de script<?php $concurrency = $_SERVER['argv'][1] ?? 1; $hashes = 100000000; $chunkSize = intval($hashes / $concurrency); $t1 = microtime(true); $children = array(); for ($i = 0; $i < $concurrency; $i++) { $pid = pcntl_fork(); if (0 === $pid) { $first = $i * $chunkSize; $last = ($i + 1) * $chunkSize - 1; for ($j = $first; $j < $last; $j++) { $dummy = md5($j); } printf("[%d]: %d hashes in %0.4f sec\n", $i, $last - $first, microtime(true) - $t1); exit; } else { $children[$pid] = 1; } } while (count($children) > 0) { $pid = pcntl_waitpid(-1, $status); if ($pid > 0) { unset($children[$pid]); } else { exit("Got a error pid=$pid"); } }
Eu tenho dois núcleos físicos no meu laptop. Execute esse código com diferentes dados de entrada para medir seu desempenho com um número diferente de processos C paralelos.
Traçamos os resultados dos lançamentos:
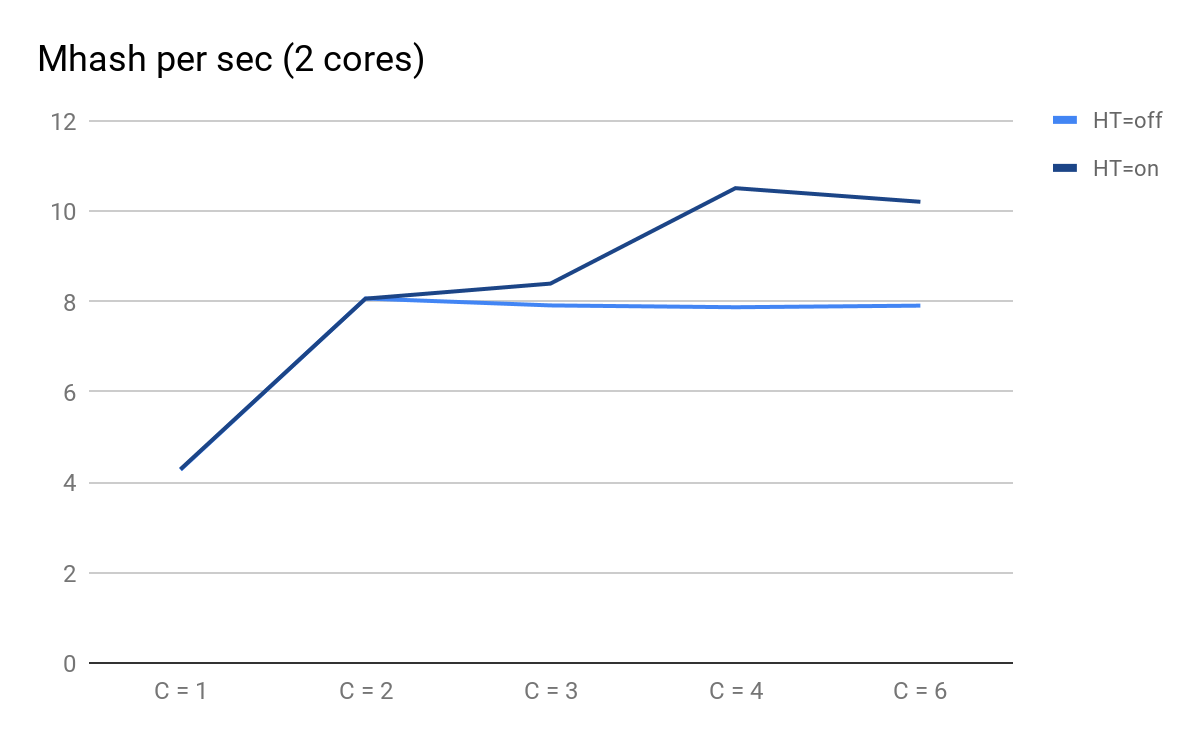 Desempenho do script, dependendo do número de processos paralelos
Desempenho do script, dependendo do número de processos paralelosNo que você pode prestar atenção:
- C = 1 e C = 2 são previsivelmente os mesmos para HT = ativado e HT = desativado, o desempenho duplica quando um núcleo físico é adicionado;
- em C = 3, as vantagens do HT tornam-se visíveis: para HT = ativado, conseguimos obter desempenho adicional, enquanto para HT = desativado com C = 3 em diante, ele começa a diminuir previsivelmente lentamente;
- em C = 4, vemos todos os benefícios da TH; conseguimos extrair 30% de produtividade adicional, mas em comparação com C = 2 no momento, o uso da CPU aumentou de 50% para 100%.
Total, vendo nos 50% superiores da carga da CPU, ao executar esse script, obtemos 8.065 Mhash / s e 100% - 10.511 Mhash / s. Isso significa que em cerca de 50% do topo, obtemos 8,065 / 10,511 ~ 77% do desempenho máximo do sistema e, de fato, temos cerca de 100% restantes na reserva - 77% = 23% e não 50%, como pode parecer.
Esse fato deve ser considerado no planejamento.
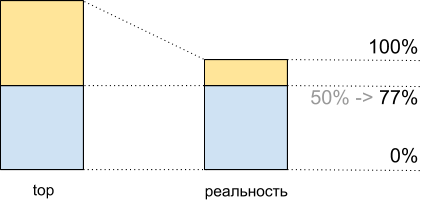 Utilização da CPU para demoscript: principais dados e o que realmente acontece
Utilização da CPU para demoscript: principais dados e o que realmente aconteceInconsistência no tráfego
Além da hipertrofia, o planejamento também complica a irregularidade do tráfego, dependendo da hora do dia, dia da semana, estação do ano e outras frequências. Para nós, por exemplo, o pico é domingo à noite.
 Número de pedidos por segundo, pico no domingo à noite
Número de pedidos por segundo, pico no domingo à noiteNem sempre o número de solicitações muda de maneira óbvia. Por exemplo, os usuários podem de alguma forma interagir com outros usuários: a atividade de alguns pode gerar push / email para outros e, portanto, envolvê-los no processo. Para isso, são adicionadas campanhas promocionais que aumentam o tráfego e para as quais você também precisa estar preparado.
Também é importante considerar tudo isso ao planejar: por exemplo, criar uma tendência nos dias de pico e ter em mente a possível não linearidade do pico de crescimento.
Ferramentas de perfil e medição
Suponha que descobrimos que há problemas de desempenho, entenda que esse não é o banco de dados / serviços / outras coisas e, no entanto, decidimos otimizar o código. Para fazer isso, primeiro de tudo, precisamos de um criador de perfil ou de algumas ferramentas para encontrar gargalos e, posteriormente, ver os resultados de nossas otimizações.
Infelizmente, para o PHP hoje, não existe uma boa ferramenta universal.
perf
perf é uma ferramenta de criação de perfil incorporada ao kernel do Linux. É um criador de perfil de
amostra que é iniciado por um processo separado, portanto, não adiciona diretamente uma sobrecarga ao programa que está sendo criado. As sobrecargas indiretamente adicionadas são uniformemente "borradas", de modo que não distorcem as medições.
Por todas as suas vantagens, o perf é capaz de trabalhar apenas com código compilado e com JIT e não é capaz de trabalhar com código em execução "em uma máquina virtual". Portanto, o próprio código PHP não pode ser perfilado nele, mas você pode ver claramente como o PHP funciona por dentro, incluindo várias extensões PHP e quanto recursos são gastos nele.
Por exemplo, com perf, encontramos vários gargalos, incluindo um local de compressão, que discutirei abaixo.
Um exemplo:
perf record --call-graph dwarf,65528 -F 99 -p $(pgrep php-cgi | paste -sd "," -) -- sleep 20
perf report(se o processo e o perf forem executados sob diferentes usuários, o perf precisará ser executado no sudo).
 Exemplo de saída de relatório Perf para PHP-FPM
Exemplo de saída de relatório Perf para PHP-FPMAgregador XHProf e XHProf
XHProf é uma extensão para PHP que coloca temporizadores em torno de todas as chamadas para funções / métodos e também contém ferramentas para visualizar os resultados assim obtidos. Diferentemente do perf, ele permite que você opere com termos de código PHP (ao mesmo tempo, o que está acontecendo nas extensões não é visível).
As desvantagens incluem duas coisas:
- todas as medições são coletadas no âmbito de uma única solicitação, portanto, não fornecem informações sobre a imagem como um todo;
- a sobrecarga, embora não seja tão grande quanto, por exemplo, ao usar o Xdebug, mas é, e em alguns casos, os resultados são bastante distorcidos (quanto mais vezes uma função é chamada e quanto mais simples é, maior a distorção).
Aqui está um exemplo que ilustra o último ponto:
function child1() { return 1; } function child2() { return 2; } function parent1() { child1(); child2(); return; } for ($i = 0; $i < 1000000; $i++) { parent1(); }
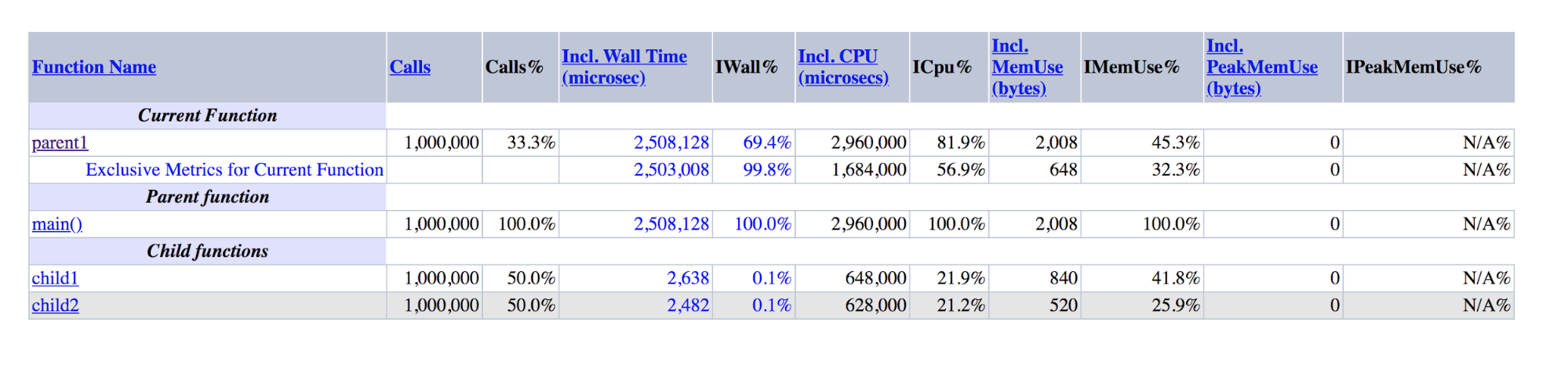 Saída XHProf para demos: parent1 é ordens de magnitude maiores que a soma de child1 e child2
Saída XHProf para demos: parent1 é ordens de magnitude maiores que a soma de child1 e child2Pode-se observar que parent1 () foi executado ~ 500 vezes mais que child1 () + child2 (), embora, na realidade, esses números devam ser aproximadamente iguais, assim como main () e parent1 ().
Se a última desvantagem é difícil de combater, para combater a primeira, criamos um complemento para o XHProf, que agrega os perfis de diferentes solicitações e visualiza os dados agregados.
Além do XHProf, existem muitos outros criadores de perfil menos conhecidos trabalhando com um princípio semelhante. Eles têm vantagens e desvantagens semelhantes.
Pinba
O Pinba permite
monitorar o desempenho por scripts (ações) e por temporizadores predefinidos. Todas as medidas no contexto dos scripts são feitas prontamente, para isso, nenhuma etapa adicional é necessária. Para cada script e cronômetro, a
getrusage é
executada , para que saibamos exatamente quanto tempo do processador foi gasto em uma parte específica do código (diferente dos criadores de perfil de amostragem, onde esse tempo pode se transformar em rede, disco etc.). O Pinba é ótimo para salvar dados históricos e obter uma imagem em geral e dentro de tipos específicos de consultas.
 A confusão geral de todos os scripts obtidos de Pinba
A confusão geral de todos os scripts obtidos de PinbaAs desvantagens incluem o fato de que os cronômetros que perfilam seções específicas do código, e não os scripts inteiros, devem ser organizados com antecedência no código, bem como a presença de uma sobrecarga que (como no XHProf) pode distorcer os dados.
phpspy
O phpspy é um projeto relativamente novo (o primeiro commit no GitHub foi há meio ano), que parece promissor, por isso estamos monitorando de perto.
Do ponto de vista do usuário, o phpspy é semelhante ao perf: um processo paralelo é iniciado, que copia periodicamente as partes da memória do processo PHP, analisa-as e recebe rastreamentos de pilha e outros dados a partir daí. Isso é feito de uma maneira bastante específica. Para minimizar a sobrecarga, o phpspy não interrompe o processo PHP e copia a memória diretamente enquanto está em execução. Isso leva ao fato de que o criador de perfil pode obter um estado inconsistente, rastreamentos de pilha podem ser quebrados. Mas o phpspy pode detectar isso e descartar esses dados.
No futuro, usando esta ferramenta, será possível coletar dados da imagem como um todo e perfis de tipos específicos de consultas.
Tabela de comparação
Para estruturar as diferenças entre as ferramentas, vamos criar uma tabela dinâmica:
 Comparação dos principais recursos dos criadores de perfilGráficos de chama
Comparação dos principais recursos dos criadores de perfilGráficos de chamaOtimização e abordagens
Com essas ferramentas, monitoramos constantemente o desempenho e o uso de nossos recursos. Quando eles são usados injustificadamente ou estamos nos aproximando do limite (para a CPU, escolhemos empiricamente um valor de 55% para ter uma margem de tempo em caso de crescimento), como escrevi acima, uma das soluções para o problema é a otimização.
Bem, se a otimização já foi feita por outra pessoa, como foi o caso do PHP 7.0, quando esta versão se mostrou muito mais produtiva do que as anteriores. Geralmente tentamos usar tecnologias e ferramentas modernas, incluindo atualizações oportunas para as versões mais recentes do PHP. De acordo com
benchmarks públicos , o PHP 7.2 é 5-12% mais rápido que o PHP 7.1. Mas essa transição, infelizmente, nos deu muito menos.
Durante todo o tempo, implementamos um grande número de otimizações. Infelizmente, a maioria deles está fortemente relacionada à nossa lógica de negócios. Vou falar sobre aqueles que podem ser relevantes não apenas para nós, ou sobre idéias e abordagens que podem ser usadas fora do nosso código.
Compactação Zlib => zstd
Usamos compactação para grandes chaves de memkey. Isso nos permite gastar três a quatro vezes menos memória para armazenamento devido aos custos adicionais da CPU para compactação / descompactação. Usamos o zlib para isso (nossa extensão para trabalhar com memekes é diferente daquela que vem com o PHP, mas os oficiais
também usam o zlib).
Em perf, a produção era algo assim:
+ 4.03% 0.22% php-cgi libz.so.1.2.11 [.] inflate
+ 3.38% 0.00% php-cgi libz.so.1.2.11 [.] deflate7-8% do tempo foi gasto em compressão / descompressão.
Decidimos testar diferentes níveis e algoritmos de compactação. Verificou-se que o zstd roda nossos dados quase dez vezes mais rápido, perdendo 1,1 vezes. Uma mudança bastante simples no algoritmo nos salvou ~ 7,5% da CPU (isso, lembro-me, em nossos volumes é equivalente a ~ 45 servidores).
É importante entender que a proporção do desempenho de diferentes algoritmos de compactação pode variar bastante, dependendo dos dados de entrada. Existem várias
comparações , mas com mais precisão isso só pode ser estimado usando exemplos do mundo real.
IS_ARRAY_IMMUTABLE como repositório de dados raramente modificados
Ao trabalhar com tarefas reais, é necessário lidar com esses dados que você precisa frequentemente e ao mesmo tempo raramente mudam e têm um tamanho limitado. Temos muitos dados semelhantes, um bom exemplo é a configuração de
testes divididos . Verificamos se o usuário se enquadra nas condições de um teste específico e, dependendo disso, mostramos a ele a funcionalidade experimental ou normal (isso acontece quase durante cada solicitação). Em outros projetos, configurações e vários diretórios podem ser um exemplo: países, cidades, idiomas, categorias, marcas, etc.
Como esses dados costumam ser solicitados, o recebimento deles pode criar uma carga adicional perceptível tanto no próprio aplicativo quanto no serviço no qual esses dados são armazenados. O último problema pode ser resolvido, por exemplo, usando o APCu, que usa a memória da mesma máquina executando o PHP-FPM como armazenamento. Mas mesmo assim:
- haverá custos de serialização / desserialização;
- você precisa de alguma forma invalidar os dados ao alterar;
- Há alguma sobrecarga em comparação ao acesso a apenas uma variável no PHP.
O PHP 7.0 apresenta a otimização
IS_ARRAY_IMMUTABLE . Se você declarar uma matriz, cujos elementos são conhecidos no momento da compilação, ela será processada e colocada na memória OPCache uma vez, os funcionários do PHP-FPM se referirão a essa memória compartilhada sem gastar seu tempo antes de tentar mudar. Da mesma forma, a inclusão de uma matriz levará tempo constante, independentemente do tamanho (geralmente ~ 1 microssegundo).
Para comparação: um exemplo do tempo para obter uma matriz de 10.000 elementos através de include e apcu_fetch:
$t0 = microtime(true); $a = include 'test-incl-1.php'; $t1 = microtime(true); printf("include (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6); $t0 = microtime(true); $a = apcu_fetch('a'); $t1 = microtime(true); printf("apcu_fetch (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6);
Verificar se essa otimização foi aplicada pode ser muito simples se você observar os códigos de operação gerados:
$ cat immutable.php <?php return [ 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3', ]; $ cat mutable.php <?php return [ 'key1' => \SomeClass::CONST_1, 'key2' => 'val2', 'key3' => 'val3', ]; $ php -d opcache.enable=1 -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 immutable.php $_main: ; (lines=1, args=0, vars=0, tmps=0) ; (after optimizer) ; /home/ubuntu/immutable.php:1-8 L0 (4): RETURN array(...) $ php -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 mutable.php $_main: ; (lines=5, args=0, vars=0, tmps=2) ; (after optimizer) ; /home/ubuntu/mutable.php:1-8 L0 (4): T1 = FETCH_CLASS_CONSTANT string("SomeClass") string("CONST_1") L1 (4): T0 = INIT_ARRAY 3 T1 string("key1") L2 (5): T0 = ADD_ARRAY_ELEMENT string("val2") string("key2") L3 (6): T0 = ADD_ARRAY_ELEMENT string("val3") string("key3") L4 (6): RETURN T0
No primeiro caso, pode-se ver que há apenas um código de operação no arquivo - o retorno da matriz finalizada. No segundo caso, sua formação elemento a elemento ocorre sempre que esse arquivo é executado.
Assim, é possível gerar estruturas de uma forma que não exija mais transformação no tempo de execução. Por exemplo, em vez de desmontar os nomes das classes pelos sinais “_” e “\” a cada vez para o carregamento automático, você pode pré-gerar o mapa de correspondência “Class => Path”. Nesse caso, a função de conversão será reduzida para uma única chamada de tabela de hash. O Composer faz esse tipo de otimização se você ativar a
opção optimize-autoloader .
Para invalidar esses dados, você não precisa fazer nada específico - o próprio PHP recompilará o arquivo ao alterar, da mesma forma que faria com uma implantação normal de código. A única desvantagem que você não deve esquecer: se o arquivo for muito grande, a primeira solicitação após a alteração causará uma recompilação, o que pode levar um tempo tangível.
O desempenho inclui / requer
Ao contrário do exemplo de matriz estática, anexar arquivos com declarações de classe e função não é tão rápido. Apesar da presença do OPCache, o mecanismo PHP deve copiá-los na memória do processo, conectando dependências recursivamente, o que pode levar centenas de microssegundos ou mesmo milissegundos por arquivo.
Se você criar um novo projeto vazio no
Symfony 4.1 e colocar
get_included_files () como a primeira linha da ação, poderá ver que 310 arquivos já estão conectados. Em um projeto real, esse número pode atingir milhares por solicitação. Vale a pena prestar atenção nas seguintes coisas.
Falta de recursos de carregamento automáticoExiste a
função Autoloading RFC , mas nenhum desenvolvimento foi visto por vários anos. Portanto, se uma dependência no Composer define funções fora da classe e essas funções devem estar acessíveis ao usuário, isso é feito
obrigatoriamente conectando um arquivo com essas funções a cada inicialização do carregador automático.
Por exemplo, removendo uma das dependências do composer.json, que declara muitas funções e é facilmente substituída por cem linhas de código, conquistamos alguns por cento da CPU.
O carregador automático é chamado com mais frequência do que parece.Para demonstrar a ideia, crie um arquivo com uma classe:
<?php class A extends B implements C { use D; const AC1 = \E::E1; const AC2 = \F::F1; private static $as3 = \G::G1; private static $as4 = \H::H1; private $a5 = \I::I1; private $a6 = \J::J1; public function __construct(\K $k = null) {} public static function asf1(\L $l = null) :? LR { return null; } public static function asf2(\M $m = null) :? MR { return null; } public function af3(\N $n = null) :? NR { return null; } public function af4(\P $p = null) :? PR { return null; } }
Registre o carregador automático: spl_autoload_register(function ($name) { echo "Including $name...\n"; include "$name.php"; });
E faremos vários casos de uso para esta classe: include 'A.php' Including B... Including D... Including C... \A::AC1 Including A... Including B... Including D... Including C... Including E... new A() Including A... Including B... Including D... Including C... Including E... Including F... Including G... Including H... Including I... Including J...
Você pode perceber que, quando de alguma forma conectamos a classe, mas não criamos sua instância, o pai, as interfaces e os traços serão conectados. Isso é feito recursivamente para todos os arquivos conectados conforme resolvidos.
Ao criar uma instância, a resolução de todas as constantes e campos é adicionada a isso, o que leva à conexão de todos os arquivos necessários para isso, o que, por sua vez, também causará a conexão recursiva de características, pais e interfaces das classes recém-conectadas.
 Conectando Classes Relacionadas para o Processo de Criação da Instância e Outros Casos
Conectando Classes Relacionadas para o Processo de Criação da Instância e Outros CasosNão existe uma solução universal para esse problema, basta manter isso em mente e monitorar as conexões entre as classes: uma linha pode gerar a conexão de centenas de arquivos.
Configurações do OPCacheSe você usar o método
atomic deploy alterando o link simbólico proposto por Rasmus Lerdorf, o criador do PHP, para
resolver o problema de "colar" o link simbólico na versão antiga, inclua opcache.revalidate_path, como recomendado, por exemplo, neste
artigo sobre OPCache traduzido por Mail .Ru Group.
O problema é que esta opção significativamente (em média, uma vez e meia a duas vezes) aumenta o tempo de inclusão de cada arquivo. No total, isso pode consumir uma quantidade significativa de recursos (no nosso caso, desabilitar essa opção deu um ganho de 7 a 9%).
Para desativá-lo, você precisa fazer duas coisas:
- faça o servidor da web resolver links simbólicos;
- pare de conectar arquivos dentro do script PHP ao longo dos caminhos que contêm links simbólicos ou force-os através de readlink () ou realpath ().
Se todos os arquivos estiverem conectados ao carregador automático do Composer, o segundo item será executado automaticamente após a conclusão do primeiro: O compositor usa a constante __DIR__, que será resolvida corretamente.
O OPCache tem mais algumas opções que podem aumentar o desempenho em troca de flexibilidade. Você pode ler mais sobre isso no
artigo que mencionei acima.
Apesar de todas essas otimizações, a inclusão ainda não será gratuita. Para combater isso, o PHP 7.4 planeja adicionar
pré-carregamento .
APCu Lock
Embora não falemos de bancos de dados e serviços aqui, vários tipos de bloqueios também podem ocorrer no código, o que aumenta o tempo de execução do script.
À medida que as solicitações aumentavam, notamos uma desaceleração acentuada da resposta nos horários de pico. Depois de descobrir os motivos, descobriu-se que, embora o APCu seja a maneira mais rápida de obter dados (em comparação com Memcache, Redis e outro armazenamento externo), ele também pode trabalhar lentamente com a substituição freqüente das mesmas chaves.
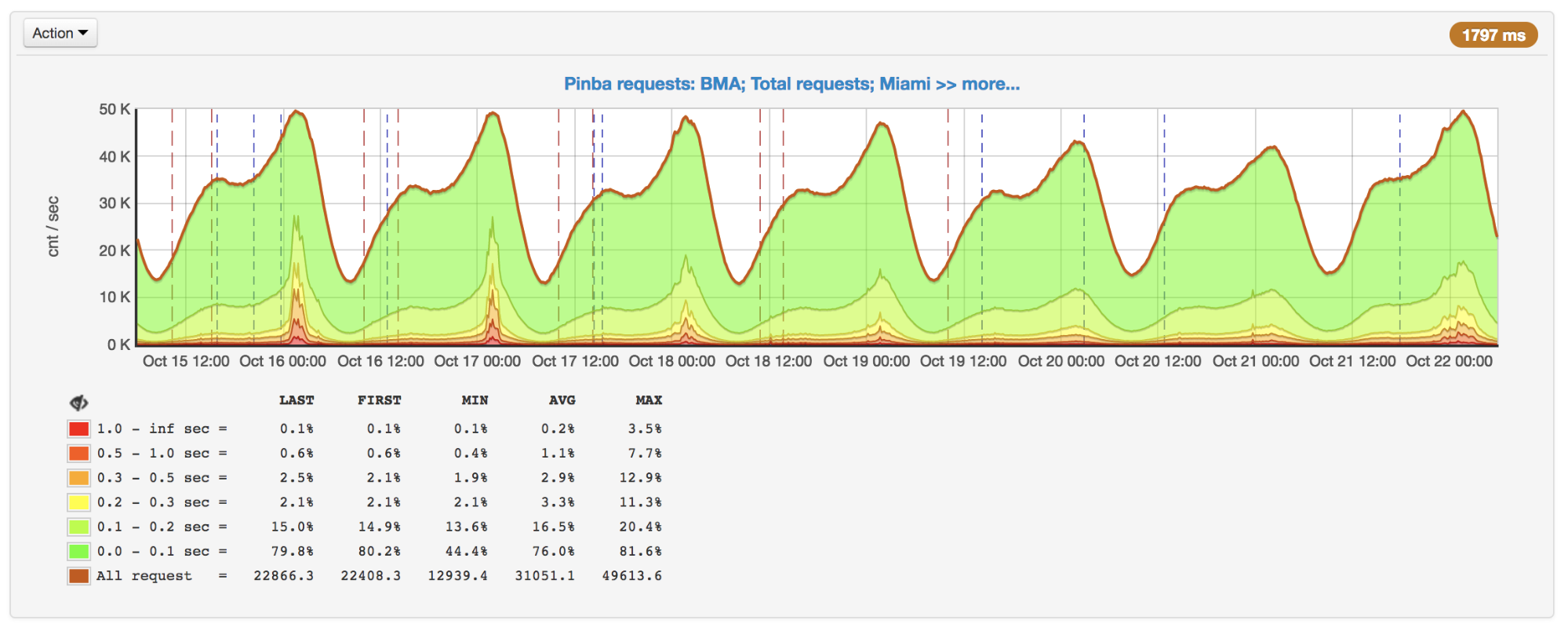 Número de solicitações por segundo e tempo de execução: picos em 16 e 17 de outubro
Número de solicitações por segundo e tempo de execução: picos em 16 e 17 de outubroAo usar o APCu como cache, esse problema não é tão relevante, porque o cache geralmente envolve gravação rara e leitura frequente. Mas algumas tarefas e algoritmos (por exemplo,
Disjuntor (
implementação em PHP )) também envolvem gravação frequente, o que causa bloqueios.
Não existe uma solução universal para esse problema, mas no caso do disjuntor, ele pode ser resolvido, por exemplo, colocando-o em um
serviço separado instalado em máquinas com PHP.
Processamento em lote
Mesmo que você não leve em consideração a inclusão, normalmente, uma parte significativa do tempo de execução da consulta é gasta na inicialização: uma estrutura (por exemplo, construindo um contêiner de DI e inicializando todas as suas dependências, roteamento, execução de todos os ouvintes), aumentando a sessão, Usuário e assim por diante. mais adiante.
Se o seu back-end é uma API interna para alguma coisa, algumas solicitações de clientes podem ser agrupadas e enviadas como uma única solicitação. Nesse caso, a inicialização será realizada uma vez para várias solicitações.
, , . - , . .
Badoo , . PHP-FPM, CPU, , , : IO, CPU .
PHP-FPM — , PHP.
(CPU, IO), . , , , , - , . , . , , .
Conclusão
. PHP .
:
- ;
- ;
- - , : , ;
- : (, , );
- : ;
- , OPCache PHP, , , ;
- : (, , PHP 7.2 , );
- : , .
?
Obrigado pela atenção!