Olá pessoal! Trabalho na Veeam no projeto Veeam Agent for Linux. Com este produto, você pode fazer backup de uma máquina Linux. "Agente" no nome significa que o programa permite fazer backup de máquinas físicas. O Virtualalkans também faz backup, mas está localizado no SO convidado.
A inspiração para este artigo foi o meu relatório na conferência
Linux Piter , que decidi publicar como artigo para todos os habragiteli interessados.
No artigo, vou revelar o tópico de criação de um instantâneo que permite fazer backup e falar sobre os problemas que encontramos ao criar nosso próprio mecanismo para criar instantâneos de dispositivos de bloco.
Todos os interessados pedem um corte!

Um pouco de teoria no começo
Historicamente, existem duas abordagens para a criação de backups: backup de arquivo e backup de volume. No primeiro caso, copiamos cada arquivo como um objeto separado, no segundo, copiamos todo o conteúdo do volume como um tipo de imagem.
Ambos os métodos têm muitas vantagens e desvantagens, mas os consideraremos através do prisma da recuperação de falhas:
- No caso de backup de arquivos, para recuperar completamente o servidor inteiro, precisamos primeiro instalar o sistema operacional, depois os serviços necessários e somente depois restaurar os arquivos do backup.
- No caso do backup de volume, para uma recuperação completa, basta restaurar todos os volumes de uma máquina sem esforços desnecessários por parte de uma pessoa.
Obviamente, no caso de backup de volume, você pode restaurar o sistema mais rapidamente, e essa é uma
característica importante
do sistema . Portanto, para nós mesmos, observamos o backup de volume como a opção preferida.
Como captamos e salvamos o volume inteiro? Obviamente, simplesmente copiando, não conseguiremos nada de bom. Durante a cópia, alguma atividade com dados ocorrerá no volume; como resultado, os dados inconsistentes aparecerão no backup. A estrutura do sistema de arquivos será violada, os arquivos do banco de dados serão corrompidos e outros arquivos com os quais as operações serão executadas durante a cópia.
Para evitar todos esses problemas, a humanidade progressiva criou uma tecnologia de instantâneo - instantâneo. Em teoria, tudo é simples: criamos uma cópia inalterada - um instantâneo - e fazemos backup dos dados. Quando o backup termina, destruímos o instantâneo. Parece simples, mas, como sempre, existem nuances.
Por causa deles, muitas implementações dessa tecnologia nasceram. Por exemplo, soluções baseadas no
mapeador de dispositivos , como o provisionamento LVM e Thin, fornecem instantâneos de volume total, mas exigem layout de disco especial no estágio de instalação do sistema, o que significa que, em geral, eles não são adequados.
O BTRFS e o ZFS possibilitam a criação de instantâneos das subestruturas do sistema de arquivos, o que é muito legal, mas no momento a participação deles nos servidores é pequena e estamos tentando criar uma solução universal.
Suponha que exista uma EXT banal em nosso dispositivo de bloqueio. Nesse caso, podemos usar o
dm-snap (a propósito, o
dm-bow está sendo desenvolvido agora), mas aqui está sua própria nuance. Você precisa ter um dispositivo de bloco livre pronto para poder soltar os dados da captura instantânea onde.
Prestando atenção às soluções alternativas de backup, percebemos que, em regra, eles usam seu módulo do kernel para criar instantâneos de dispositivos de bloco. Decidimos seguir esse caminho, escrevendo nosso módulo. Foi decidido distribuí-lo sob a licença GPL, para que esteja disponível publicamente no
github .
Como funciona - em teoria
Instantâneo do microscópio
Portanto, agora consideraremos o princípio geral de operação do módulo e abordaremos as principais questões com mais detalhes.
De fato, o veeamsnap (como chamamos de módulo do kernel) é um filtro de driver de dispositivo de bloco.

Seu trabalho é interceptar solicitações para um driver de dispositivo de bloco.
Após interceptar uma solicitação de gravação, o módulo copia dados do dispositivo de bloco original para a área de dados da captura instantânea. Chamamos essa área de snapstore.
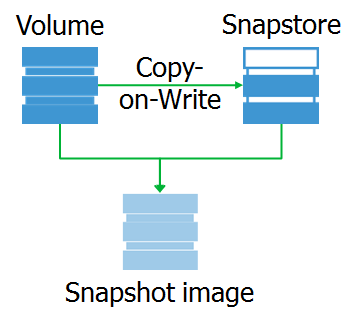
E qual é o instantâneo em si? Este é um dispositivo de bloco virtual, uma cópia do dispositivo original em um determinado momento. Ao acessar os blocos de dados neste dispositivo, eles podem ser lidos no snap-in ou no dispositivo original.
Quero observar que o instantâneo é exatamente o dispositivo de bloco que é completamente idêntico ao original no momento em que o instantâneo foi removido. Graças a isso, podemos montar o sistema de arquivos em um instantâneo e executar o pré-processamento necessário.
Por exemplo, podemos obter um mapa dos blocos ocupados no sistema de arquivos. A maneira mais fácil de fazer isso é usar o ioctl
GETFSMAP .
Dados em blocos ocupados permitem que você leia apenas os dados mais recentes de uma captura instantânea.
Você também pode excluir alguns arquivos. Bem, uma ação completamente opcional: indexe os arquivos que caem no backup, para a possibilidade de um restaurante granular no futuro.
CoW vs RoW
Vamos nos concentrar um pouco na escolha do algoritmo de captura instantânea. A escolha aqui não é muito extensa:
Copiar na gravação ou Redirecionar na gravação .
O redirecionamento na gravação ao interceptar uma solicitação de gravação a redirecionará para o snap, após o qual todas as solicitações para ler este bloco também serão acessadas. Um ótimo algoritmo para sistemas de armazenamento criados com base em árvores B +, como BTRFS, ZFS e Thin Provisioning. A tecnologia é tão antiga quanto o mundo, mas se manifesta especialmente bem em hipervisores, onde é possível criar um novo arquivo e gravar novos blocos lá durante o instantâneo. O desempenho é excelente em comparação com o CoW. Mas há um excesso de gordura - a estrutura do dispositivo original muda e, ao remover o instantâneo, você precisa copiar todos os blocos do snap para o local original.
A cópia na gravação, ao interceptar uma solicitação, copia os dados para o snapstore que devem sofrer uma alteração, após o que permite que eles sejam substituídos no local original. Usado para criar capturas instantâneas para volumes LVM e cópias de sombra do VSS. Obviamente, é mais adequado para criar instantâneos de dispositivos de bloco, porque não altera a estrutura do dispositivo original e, quando você exclui (ou falha), o instantâneo pode ser simplesmente descartado sem arriscar dados. A desvantagem dessa abordagem é a degradação do desempenho, pois algumas operações de leitura / gravação são adicionadas a cada operação de gravação.
Como a segurança dos dados é nossa principal prioridade, nos concentramos em CoW.
Até agora, tudo parece simples, então vamos abordar os problemas da vida real.
Como funciona - na prática
Condição Consistente
Por ele, tudo foi concebido.
Por exemplo, se no momento da criação de um instantâneo (em uma primeira aproximação, podemos assumir que ele foi criado instantaneamente) um registro será gravado em algum arquivo, em um instantâneo o arquivo ficará incompleto, o que significa que será danificado e sem sentido. A situação é semelhante aos arquivos de banco de dados e ao próprio sistema de arquivos.
Mas vivemos no século 21! Existem mecanismos de registro que protegem contra esses problemas! É verdade que existe um “mas” importante: essa proteção não é do fracasso, mas de suas consequências. Ao restaurar para um estado consistente de acordo com o log, operações incompletas serão descartadas, o que significa que elas serão perdidas. Portanto, é importante mudar a prioridade da proteção contra a causa, em vez de tratar as consequências.
O sistema pode ser avisado de que um instantâneo será criado. Para isso, o kernel possui as funções
freeze_bdev e
thaw_bdev . Eles puxam as funções do sistema de arquivos freeze_fs e unfreeze_fs. Quando você chama o primeiro, o sistema deve redefinir o cache, suspender a criação de novas solicitações para o dispositivo de bloco e aguardar a conclusão de todas as solicitações geradas anteriormente. E quando unfreeze_fs é chamado, o sistema de arquivos restaura seu funcionamento normal.
Acontece que podemos avisar o sistema de arquivos. E os aplicativos? Aqui, infelizmente, tudo está ruim. Enquanto no Windows existe um mecanismo
VSS que, com a ajuda do Writers, fornece interação com outros produtos, cada um no Linux segue seu próprio caminho. No momento, isso levou à situação em que a tarefa do administrador do sistema de escrever (copiar,
roubar , comprar, etc.) os scripts de pré-congelamento e pós-descongelamento por conta própria, preparará o aplicativo para o instantâneo. De nossa parte, no próximo lançamento, apresentaremos o suporte ao Oracle Application Processing, como o recurso mais frequentemente solicitado por nossos clientes. Em seguida, outros aplicativos podem ser suportados, mas no geral a situação é bastante triste.
Onde colocar o snap?
Este é o segundo problema que está no nosso caminho. À primeira vista, o problema não é óbvio, mas depois de um pouco de compreensão, vemos que isso ainda é uma lasca.
Obviamente, a solução mais fácil é colocar o snap na RAM. Para o desenvolvedor, a opção é ótima! Tudo é rápido, muito conveniente para a depuração, mas há um batente: a RAM é um recurso valioso e ninguém nos dará uma grande ajuda por lá.
OK, vamos fazer do snap-file um arquivo regular. Mas surge outro problema - você não pode fazer backup do volume no qual o snapstop está localizado. O motivo é simples: interceptamos solicitações de gravação, o que significa que interceptaremos nossas próprias solicitações de gravação no snap-in. Os cavalos corriam de uma maneira científica - impasse. Depois, há um forte desejo de usar um disco separado para isso, mas ninguém adicionará discos ao nosso servidor por nossa causa. Você deve poder trabalhar no que é.
Posicionar remotamente o snap-in é uma excelente idéia, mas pode ser implementado em círculos muito estreitos de redes com alta largura de banda e latens microscópicos. Caso contrário, enquanto mantém o instantâneo na máquina, haverá uma estratégia baseada em turnos.
Portanto, você precisa, de alguma maneira, colocar o snap no disco local. Mas, como regra, todo o espaço nos discos locais já está distribuído entre os sistemas de arquivos e, ao mesmo tempo, você precisa pensar muito sobre como contornar o problema do impasse.
A direção da reflexão, em princípio, é uma: você precisa, de alguma forma, alocar espaço no sistema de arquivos, mas trabalhar diretamente com o dispositivo de bloco. A solução para esse problema foi implementada no código do espaço do usuário, no serviço.
Há uma chamada do sistema
fallocate que permite criar um arquivo vazio do tamanho desejado. No entanto, de fato, apenas os metadados são criados no sistema de arquivos que descreve o local do arquivo no volume. E o ioctl
FIEMAP nos permite obter um mapa da localização dos blocos de arquivos.
E pronto: criamos um arquivo sob snap usando fallocate, o FIEMAP fornece um mapa da localização dos blocos desse arquivo, que podemos transferir para trabalhar em nosso módulo veeamsnap. Além disso, ao acessar o snapstor, o módulo faz solicitações diretamente ao dispositivo de bloco em blocos conhecidos por nós, e sem conflitos.
Mas há uma nuance. A chamada do sistema fallocate é suportada apenas por XFS, EXT4 e BTRFS. Para outros sistemas de arquivos como o EXT3, é necessário gravá-lo completamente para alocar o arquivo. A funcionalidade é afetada por um aumento no tempo para preparar snappads, mas não há escolha. Novamente, você precisa ser capaz de trabalhar no que é.
E se o ioctl FIEMAP também não for suportado? Essa é a realidade do NTFS e do FAT32, onde nem sequer há suporte para o antigo FIBMAP. Eu tive que implementar um certo algoritmo genérico, cuja operação não depende dos recursos do sistema de arquivos. Em poucas palavras, o algoritmo é:
- O serviço cria um arquivo e começa a gravar um padrão específico nele.
- O módulo intercepta solicitações de gravação, verifica os dados que estão sendo gravados.
- Se os dados do bloco corresponderem ao padrão especificado, o bloco será marcado como pertencente ao snapstop.
Sim, difícil, sim, devagar, mas melhor que nada. É usado em casos raros para sistemas de arquivos sem suporte a FIEMAP e FIBMAP.
Estouro de instantâneo
Em vez disso, o local que alocamos no snapstore termina. A essência do problema é que não há lugar para descartar novos dados, o que significa que o instantâneo se torna inutilizável.
O que fazer
Obviamente, você precisa aumentar o tamanho dos snappants. Quanto? A maneira mais fácil de definir o tamanho dos snappants é determinar a porcentagem de espaço livre no volume (como feito no VSS). Para um volume de 20 TB, 10% será de 2 TB - o que é muito para um servidor descarregado. Para um volume de 200 GB, 10% são 20 GB, o que pode ser muito pouco para um servidor que está atualizando intensivamente seus dados. E ainda há volumes finos ...
Em geral, apenas o administrador do sistema do servidor pode descobrir o tamanho ideal do snap-in necessário, ou seja, você deve fazer a pessoa pensar e dar sua opinião de especialista. Isso não está de acordo com o princípio de "Simplesmente funciona".
Para resolver esse problema, desenvolvemos o algoritmo de snapshot stretch. A idéia é dividir o snap em porções. Ao mesmo tempo, novas partes são criadas após a criação de um instantâneo, conforme necessário.

Novamente, brevemente o algoritmo:
- Antes de criar um instantâneo, a primeira parte do instantâneo é criada e fornecida ao módulo.
- Quando o instantâneo é criado, a parte começará a ser preenchida.
- Assim que metade da parte estiver cheia, uma solicitação é enviada ao serviço para criar uma nova.
- O serviço cria, fornece os dados para o módulo.
- O módulo começa a preencher o próximo lote.
- O algoritmo é repetido até que o backup seja concluído ou até que cheguemos ao limite do uso de espaço livre em disco.
É importante observar que o módulo deve ter tempo para criar novas partes de snapposts conforme necessário, caso contrário - exceda, redefina as capturas instantâneas e nenhum backup. Portanto, a operação de um algoritmo desse tipo é possível apenas em sistemas de arquivos com suporte a fallocate, onde é possível criar rapidamente um arquivo vazio.
O que fazer em outros casos? Estamos tentando adivinhar o tamanho necessário e criar todo o snappast inteiro. Mas, de acordo com nossas estatísticas, a grande maioria dos servidores Linux agora usa EXT4 e XFS. EXT3 é encontrado em máquinas mais antigas. Mas no SLES / openSUSE, você pode encontrar o BTRFS.
CBT (Change Block Tracking)
Backup incremental ou diferencial (a propósito, rabanete de rabanete é mais doce ou não, sugiro que leia
aqui ) - sem ele, você não pode imaginar nenhum produto de backup adulto. E para que isso funcione, você precisa do CBT. Se alguém perdeu: o CBT permite rastrear alterações e gravar no backup apenas os dados alterados no último backup.

Muitos têm sua própria experiência nesta área. Por exemplo, no VMware vSphere, esse recurso está disponível desde a versão 4 em 2009. No Hyper-V, o suporte foi introduzido no Windows Server 2016 e, para oferecer suporte a versões anteriores, seu próprio driver VeeamFCT foi desenvolvido em 2012. Portanto, para o nosso módulo, não nos tornamos originais e usamos algoritmos que já estão funcionando.
Sobre como isso funciona.
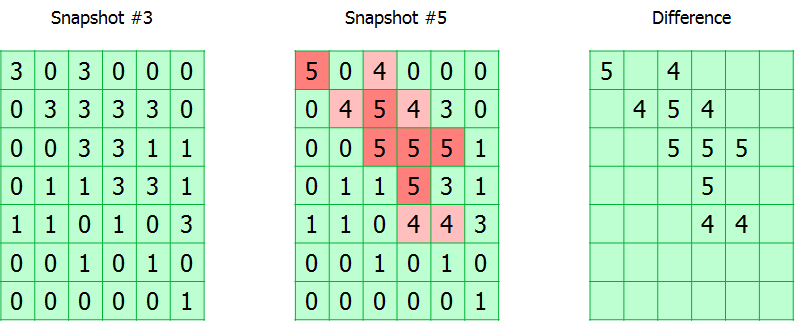
Todo o volume rastreado é dividido em blocos. O módulo simplesmente acompanha todas as solicitações de gravação, marcando os blocos alterados na tabela. De fato, a tabela CBT é uma matriz de bytes, em que cada byte corresponde a um bloco e contém o número do instantâneo no qual foi alterado.
Durante o backup, o número da captura instantânea é registrado nos metadados do backup. Assim, conhecendo os números do instantâneo atual e aquele a partir do qual o backup anterior bem-sucedido foi feito, é possível calcular o mapa da localização dos blocos alterados.
Existem duas nuances.
Como eu disse, um byte é alocado para o número da captura instantânea na tabela CBT, o que significa que o comprimento máximo da cadeia incremental não pode ser maior que 255. Quando esse limite é atingido, a tabela é redefinida e ocorre um backup completo. Pode parecer inconveniente, mas, na verdade, uma cadeia de 255 incrementos está longe de ser a melhor solução ao criar um plano de backup.
O segundo recurso é o armazenamento da tabela CBT apenas na RAM. Portanto, quando você reinicia a máquina de destino ou descarrega o módulo, ele será redefinido e, novamente, você precisará criar um backup completo. Essa solução permite não resolver o problema de inicialização do módulo na inicialização do sistema. Além disso, não há necessidade de salvar as tabelas CBT quando você desliga o sistema.
Problema de desempenho
O backup é sempre uma carga tão boa nas E / S do seu equipamento. Se já houver tarefas ativas suficientes nele, o processo de backup poderá transformar seu sistema em uma espécie de
preguiça .
Vamos ver o porquê.
Imagine que o servidor simplesmente escreva linearmente alguns dados. A velocidade de gravação, neste caso, é máxima, todos os atrasos são minimizados, o desempenho tende ao máximo. Agora, adicionamos aqui o processo de backup, que a cada gravação ainda precisa concluir o algoritmo Copy-on-Write, e essa é uma operação de leitura adicional com gravação subsequente. E não esqueça que, para backup, você ainda precisa ler dados do mesmo volume. Em uma palavra, seu belo acesso linear se transforma em um acesso aleatório sem piedade, com todas as consequências.
Obviamente, precisamos fazer algo com isso e implementamos um pipeline para processar solicitações não uma de cada vez, mas em pacotes inteiros. Funciona assim.
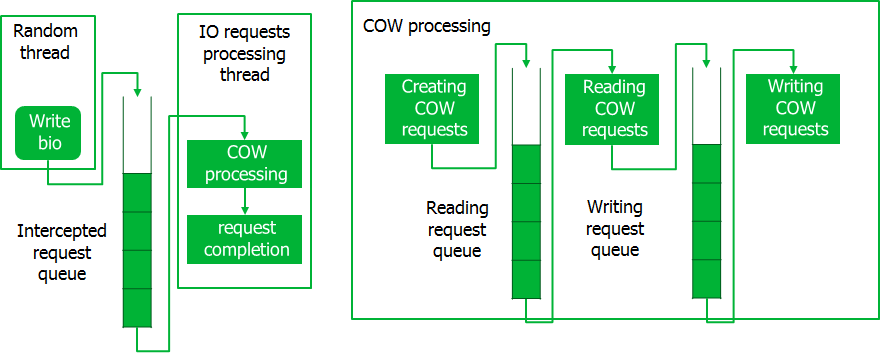
Ao interceptar solicitações, elas são colocadas em uma fila, onde um fluxo especial as leva em partes. No momento, são criadas solicitações de COW, que também são processadas em lotes. Ao processar solicitações de CoW, primeiro todas as operações de leitura são executadas para a parte inteira, após o que as operações de gravação são executadas. Somente após o processamento de toda a parte das solicitações de CoW, as solicitações interceptadas são executadas. Esse transportador fornece acesso ao disco em grandes pedaços de dados, o que minimiza as perdas de tempo.
Limitação
Já no estágio de depuração, outra nuance apareceu. Durante o backup, o sistema ficou sem resposta, ou seja, as solicitações de E / S do sistema começaram a ser executadas com longos atrasos. Porém, os pedidos de leitura de dados de um instantâneo foram executados a uma velocidade próxima do máximo.
Eu tive que estrangular um pouco o processo de backup implementando o mecanismo de limitação. Para fazer isso, o processo de leitura da imagem da captura instantânea é colocado em um estado de espera se a fila de solicitações interceptadas não estiver vazia. Espera-se que o sistema ganhe vida.
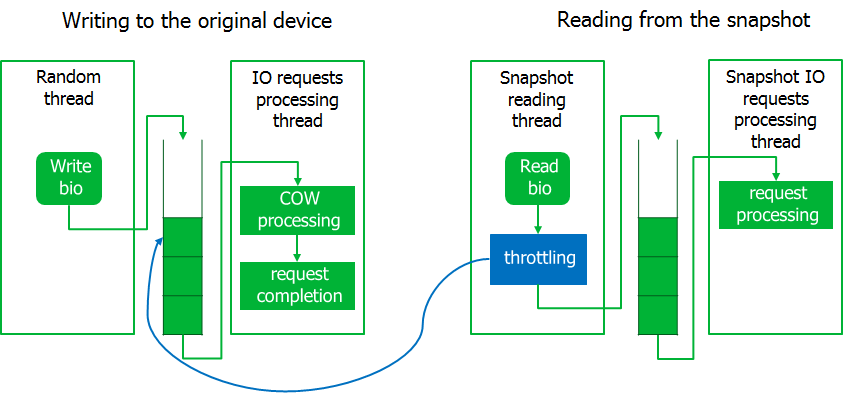
Como resultado, se a carga no sistema de E / S aumentar bastante, o processo de leitura do instantâneo aguardará. Aqui decidimos ser guiados pelo princípio de que é melhor encerrar o backup com um erro do que interromper o servidor.
Impasse
Acho que precisamos explicar com mais detalhes o que é.
Já na fase de teste, começamos a encontrar situações de paralisação completa do sistema com o diagnóstico de sete problemas - um reset.
Eles começaram a entender. Aconteceu que essa situação pode ser observada se, por exemplo, você criar uma captura instantânea do dispositivo de bloco no qual o volume LVM está localizado e colocar a captura instantânea no mesmo volume LVM. Deixe-me lembrá-lo de que o LVM usa o módulo do kernel do mapeador de dispositivos.

Nessa situação, ao interceptar uma solicitação de gravação, o módulo, copiando os dados para o snap-in, enviará a solicitação de gravação para o volume LVM. O mapeador de dispositivos redirecionará essa solicitação para o dispositivo de bloco. Uma solicitação do mapeador de dispositivos será novamente interceptada pelo módulo. Mas uma nova solicitação não pode ser processada até que a anterior tenha sido processada. Como resultado, o processamento da solicitação é bloqueado, você é recebido por um conflito.
Para evitar essa situação, o próprio módulo do kernel fornece um tempo limite para a operação de cópia de dados no snap-in. Isso permite que você detecte o deadlock e o backup de falhas. A lógica aqui é a mesma: é melhor não fazer backup do que suspender o servidor.
Banco de dados round robin
Este já é um problema gerado pelos usuários após o lançamento da primeira versão.
Descobriu-se que existem esses serviços que estão envolvidos apenas na substituição constante dos mesmos blocos.
Um exemplo impressionante é o monitoramento de serviços, que constantemente geram dados sobre o estado do sistema e os sobrescrevem em um círculo. Para tais tarefas, use bancos de dados cíclicos especializados ( RRD ).Aconteceu que, com um backup dessas bases, o instantâneo é garantido para transbordar. Em um estudo detalhado do problema, encontramos uma falha na implementação do algoritmo CoW. Se o mesmo bloco foi substituído, os dados foram copiados para o snap-in sempre. Resultado: duplicação de dados no snap.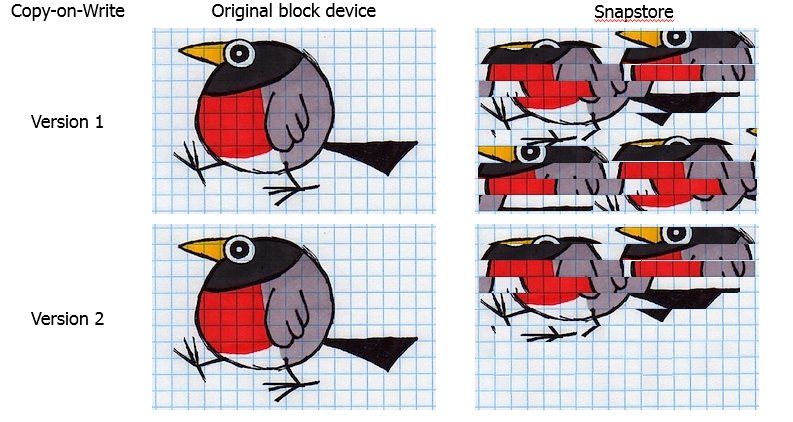 Naturalmente, mudamos o algoritmo. Agora, o volume é dividido em blocos e os dados são copiados no bloco de snap. Se o bloco já tiver sido copiado uma vez, esse processo não será repetido.
Naturalmente, mudamos o algoritmo. Agora, o volume é dividido em blocos e os dados são copiados no bloco de snap. Se o bloco já tiver sido copiado uma vez, esse processo não será repetido.Seleção de tamanho de bloco
Agora, quando o snapstrap é dividido em blocos, surge a pergunta: qual é, de fato, o tamanho dos blocos para quebrar os snapplugs?O problema é duplo. Se o bloco for grande, é mais fácil para eles operarem, mas se pelo menos um setor mudar, será necessário enviar o bloco inteiro para a sonda e, como resultado, as chances de transbordar serão aumentadas. Obviamente, quanto menor o tamanho do bloco, maior a porcentagem de dados úteis enviados para o snapstore, mas como isso afetará o desempenho?Eles procuraram a verdade empiricamente e criaram 16KiB. Observe também que o Windows VSS também usa 16 blocos KiB.
Obviamente, quanto menor o tamanho do bloco, maior a porcentagem de dados úteis enviados para o snapstore, mas como isso afetará o desempenho?Eles procuraram a verdade empiricamente e criaram 16KiB. Observe também que o Windows VSS também usa 16 blocos KiB.Em vez de uma conclusão
Por enquanto é tudo. Deixarei muitos outros problemas não menos interessantes, como dependência de versões do kernel, escolha de opções de distribuição de módulos, compatibilidade com kABI, trabalho em condições de backport etc. O artigo acabou sendo volumoso, então decidi me concentrar nos problemas mais interessantes.Agora estamos nos preparando para a versão 3.0, o código do módulo está no github e qualquer pessoa pode usá-lo sob a licença GPL.