Para aqueles que gostaram do meu
artigo anterior , continuo compartilhando minhas impressões da ferramenta de teste de estresse Locust.
Tentarei demonstrar claramente as vantagens de escrever um python de teste de carga com código no qual você pode preparar convenientemente quaisquer dados para o teste e processar os resultados.
Processamento de resposta do servidor
Às vezes, no teste de carga, não basta obter 200 OK do servidor HTTP. Acontece, é necessário verificar o conteúdo da resposta para garantir que, sob carga, o servidor emita os dados corretos ou faça cálculos precisos. Apenas nesses casos, a Locust adicionou a capacidade de substituir os parâmetros de sucesso da resposta do servidor. Considere o seguinte exemplo:
from locust import HttpLocust, TaskSet, task import random as rnd class UserBehavior(TaskSet): @task(1) def check_albums(self): photo_id = rnd.randint(1, 5000) with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response: if response.status_code == 200: album_id = response.json().get('albumId') if album_id % 10 != 0: response.success() else: response.failure(f'album id cannot be {album_id}') else: response.failure(f'status code is {response.status_code}') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Ele possui apenas uma solicitação, que criará uma carga no seguinte cenário:
No servidor, solicitamos objetos de fotos com ID aleatório no intervalo de 1 a 5000 e verificamos o ID do álbum nesse objeto, assumindo que ele não pode ser múltiplo de 10.
Aqui você pode dar imediatamente algumas explicações:
- a construção impressionante com request () como resposta: você pode substituí-lo com sucesso por response = request () e trabalhar silenciosamente com o objeto de resposta
- A URL é formada usando a sintaxe de formato de string adicionada no python 3.6, se não me engano - f '/ photos / {photo_id}' . Nas versões anteriores, esse design não funcionaria!
- um novo argumento que não tínhamos usado antes, catch_response = True , diz ao Locust que nós mesmos determinaremos o sucesso da resposta do servidor. Se você não o especificar, receberemos o objeto de resposta da mesma maneira e poderemos processar seus dados, mas não redefiniremos o resultado. Abaixo está um exemplo detalhado.
- Outro nome de argumento = '/ photos / [id]' . É necessário agrupar solicitações nas estatísticas. O nome pode ser qualquer texto, não é necessário repetir o URL. Sem ele, cada solicitação com um endereço ou parâmetros exclusivos será gravada separadamente. Veja como funciona:
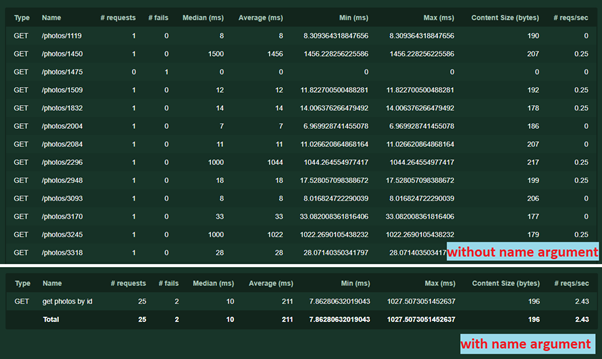
Usando o mesmo argumento, você pode executar outro truque - às vezes acontece que um serviço com parâmetros diferentes (por exemplo, conteúdos diferentes de solicitações POST) executa uma lógica diferente. Para que os resultados do teste não se confundam, você pode escrever várias tarefas separadas, especificando para cada um o seu próprio
nome de argumento.
Em seguida, fazemos as verificações. Eu tenho 2. Primeiro, verificamos que o servidor retornou uma resposta se
response.status_code == 200 :
Se sim, verifique se o ID do álbum é múltiplo de 10. Se não for múltiplo, marque esta resposta como uma
resposta bem-sucedida.success
()Em outros casos, indicamos por que a resposta falhou
response.failure ('error text') . Este texto será exibido na página Falhas durante o teste.
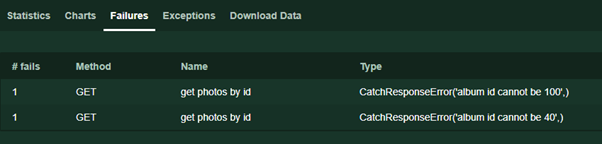
Além disso, leitores atentos podem perceber a ausência de exceções, características do código que funciona com interfaces de rede. De fato, no caso de tempo limite, erro de conexão e outros incidentes imprevistos, a Locust tratará os erros e ainda retornará uma resposta, indicando, no entanto, o status do código de resposta é 0.
Se o código ainda gerar uma exceção, ele será gravado na guia Exceções em tempo de execução, para que possamos lidar com isso. A situação mais típica é que o json'e da resposta não retornou o valor que estávamos procurando, mas já estamos realizando as seguintes operações nele.
Antes de fechar o tópico - no exemplo, uso o servidor json para maior clareza, pois é mais fácil processar as respostas. Mas você pode trabalhar com o mesmo sucesso com HTML, XML, FormData, anexos de arquivo e outros dados usados por protocolos baseados em HTTP.
Trabalhar com cenários complexos
Quase toda vez que a tarefa é realizar testes de carga de um aplicativo da Web, rapidamente fica claro que é impossível fornecer uma cobertura decente apenas com os serviços GET - que simplesmente retornam dados.
Exemplo clássico: para testar uma loja online, é desejável que o usuário
- Abriu a loja principal
- Eu estava procurando por mercadorias
- Detalhes do item aberto
- Item adicionado ao carrinho
- Pago
A partir do exemplo, podemos assumir que a chamada de serviços em ordem aleatória não funcionará, apenas sequencialmente. Além disso, mercadorias, cestas e formas de pagamento podem ter identificadores exclusivos para cada usuário.
Usando o exemplo anterior, com pequenas modificações, você pode implementar facilmente o teste desse cenário. Nós adaptamos o exemplo para o nosso servidor de teste:
- O usuário está escrevendo uma nova postagem.
- O usuário escreve um comentário na nova postagem
- O usuário lê o comentário
from locust import HttpLocust, TaskSet, task class FlowException(Exception): pass class UserBehavior(TaskSet): @task(1) def check_flow(self):
Neste exemplo, adicionei uma nova classe
FlowException . Após cada etapa, se não correu como o esperado, lancei essa classe de exceção para interromper o script - se a postagem não funcionou, não haveria nada para comentar, etc. Se desejado, a construção pode ser substituída pelo
retorno usual, mas, neste caso, em tempo de execução e ao analisar os resultados, não ficará tão claro onde o script executado se encaixa na guia Exceções. Pelo mesmo motivo, não uso a
tentativa ... exceto a construção.
Tornando a carga realista
Agora posso ser criticado - no caso da loja, tudo é realmente linear, mas o exemplo com postagens e comentários é muito exagerado - eles lêem postagens 10 vezes mais frequentemente do que criam. Razoavelmente, vamos tornar o exemplo mais viável. E há pelo menos 2 abordagens:
- Você pode "codificar" a lista de postagens que os usuários leem e simplificar o código de teste se houver essa possibilidade e a funcionalidade do back-end não depender de postagens específicas
- Salve as postagens criadas e leia-as, se não for possível predefinir a lista de postagens ou a carga realista depende de quais postagens são lidas (removi a criação de comentários do exemplo para tornar seu código menor e mais visual)
from locust import HttpLocust, TaskSet, task import random as r class UserBehavior(TaskSet): created_posts = [] @task(1) def create_post(self): new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'} post_response = self.client.post('/posts', json=new_post) if post_response.status_code != 201: return post_id = post_response.json().get('id') self.created_posts.append(post_id) @task(10) def read_post(self): if len(self.created_posts) == 0: return post_id = r.choice(self.created_posts) self.client.get(f'/posts/{post_id}', name='read post') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Na classe
UserBehavior, criei uma lista
created_posts . Preste atenção especial - este é um objeto e não foi criado no construtor da classe
__init __ (), portanto, diferentemente da sessão do cliente, essa lista é comum a todos os usuários. A primeira tarefa cria uma postagem e grava seu ID na lista. O segundo - 10 vezes mais frequentemente, lê um post selecionado aleatoriamente da lista. Uma condição adicional da segunda tarefa é verificar se há alguma postagem criada.
Se queremos que cada usuário opere apenas com seus próprios dados, podemos declará-los no construtor da seguinte maneira:
class UserBehavior(TaskSet): def __init__(self, parent): super(UserBehavior, self).__init__(parent) self.created_posts = list()
Mais alguns recursos
Para o lançamento sequencial de tarefas, a documentação oficial sugere que também utilizemos a anotação de tarefa @seq_task (1), especificando o número de série da tarefa no argumento
class MyTaskSequence(TaskSequence): @seq_task(1) def first_task(self): pass @seq_task(2) def second_task(self): pass @seq_task(3) @task(10) def third_task(self): pass
Neste exemplo, cada usuário executará primeiro a primeira
tarefa , depois a
segunda tarefa e , em seguida, 10 vezes a
terceira tarefa .
Francamente, a disponibilidade dessa oportunidade agrada, mas, diferentemente dos exemplos anteriores, não está claro como transferir os resultados da primeira tarefa para a segunda, se necessário.
Além disso, para cenários particularmente complexos, é possível criar conjuntos de tarefas aninhados, de fato, criando várias classes TaskSet e se conectando.
from locust import HttpLocust, TaskSet, task class Todo(TaskSet): @task(3) def index(self): self.client.get("/todos") @task(1) def stop(self): self.interrupt() class UserBehavior(TaskSet): tasks = {Todo: 1} @task(3) def index(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
No exemplo acima, com uma probabilidade de 1 a 6, o script
Todo será iniciado e será executado até que, com uma probabilidade de 1 a 4, retorne ao script
UserBehavior . É muito importante que você tenha uma chamada para
self.interrupt () - sem ela, o teste se concentrará na subtarefa.
Obrigado pela leitura. No artigo final, escreverei sobre testes distribuídos e testes sem uma interface do usuário, bem como sobre as dificuldades que encontrei durante os testes com a Locust e como contorná-las.