
Habr, este é um relatório do engenheiro de software Alexei Starkov na conferência Moscow Python Conf ++ 2018 em Moscou. Vídeo no final da postagem.
Olá pessoal! Meu nome é Alexei Starkov - sou eu, nos meus melhores anos, trabalho em uma fábrica.
Agora eu trabalho no Qrator Labs. Basicamente, durante toda a minha vida, estudei C e C ++ - adoro Alexandrescu, The Gang of Four, os princípios do SOLID - é tudo. O que me torna um astronauta arquitetônico. Eu tenho escrito Python nos últimos dois anos, porque eu gosto.
Na verdade, quem são os "cosmonautas da arquitetura"? A primeira vez que conheci esse termo com Joel Spolsky, você provavelmente o leu. Ele descreve os "astronautas" como pessoas que desejam construir uma arquitetura ideal que se baseia na abstração, na abstração, na abstração, que está se tornando cada vez mais geral. No final, esses níveis são tão altos que descrevem todos os programas possíveis, mas não resolvem problemas práticos. Neste momento, o "astronauta" (esta é a última vez que este termo é cercado por aspas) fica sem ar e ele morre.
Também tenho tendências para a exploração do espaço arquitetônico, mas neste relatório falarei um pouco sobre como isso me afetou e não me permitiu construir um sistema com o desempenho necessário. O principal é como eu superei isso.
Resumo do meu relatório: foi / foi.

Um aumento de milhares e milhões de vezes. Quando eu fiz este slide, o único pensamento que eu tinha era "Como?"

Onde eu poderia estragar tanto? Se você não quer estragar como eu - continue a ler.

Vou falar sobre o sistema de configuração. O sistema de configuração é uma ferramenta interna do Qrator Labs que armazena configurações para a Rede Definida por Software (SDN) - nossa rede de filtragem. Ele está comprometido em sincronizar a configuração entre componentes e monitorar seu status.

Em que consiste, em suma,? Temos um banco de dados que armazena um instantâneo de nossa configuração para toda a rede e temos um servidor que processa os comandos que chegam a ele e de alguma forma altera a configuração.
Nossos administradores e clientes técnicos chegam a esse servidor e por meio do console, pelas APIs de terminal, APIs REST, JSON RPC e outras coisas que emitem comandos para o servidor, como resultado do qual ele altera nossa configuração.
As equipes podem ser muito simples ou mais complicadas. Então, temos um certo conjunto de receptores que compõem nosso SDN e o servidor envia a configuração a esses receptores. Isso parece bem simples. Basicamente, vou falar sobre essa parte.
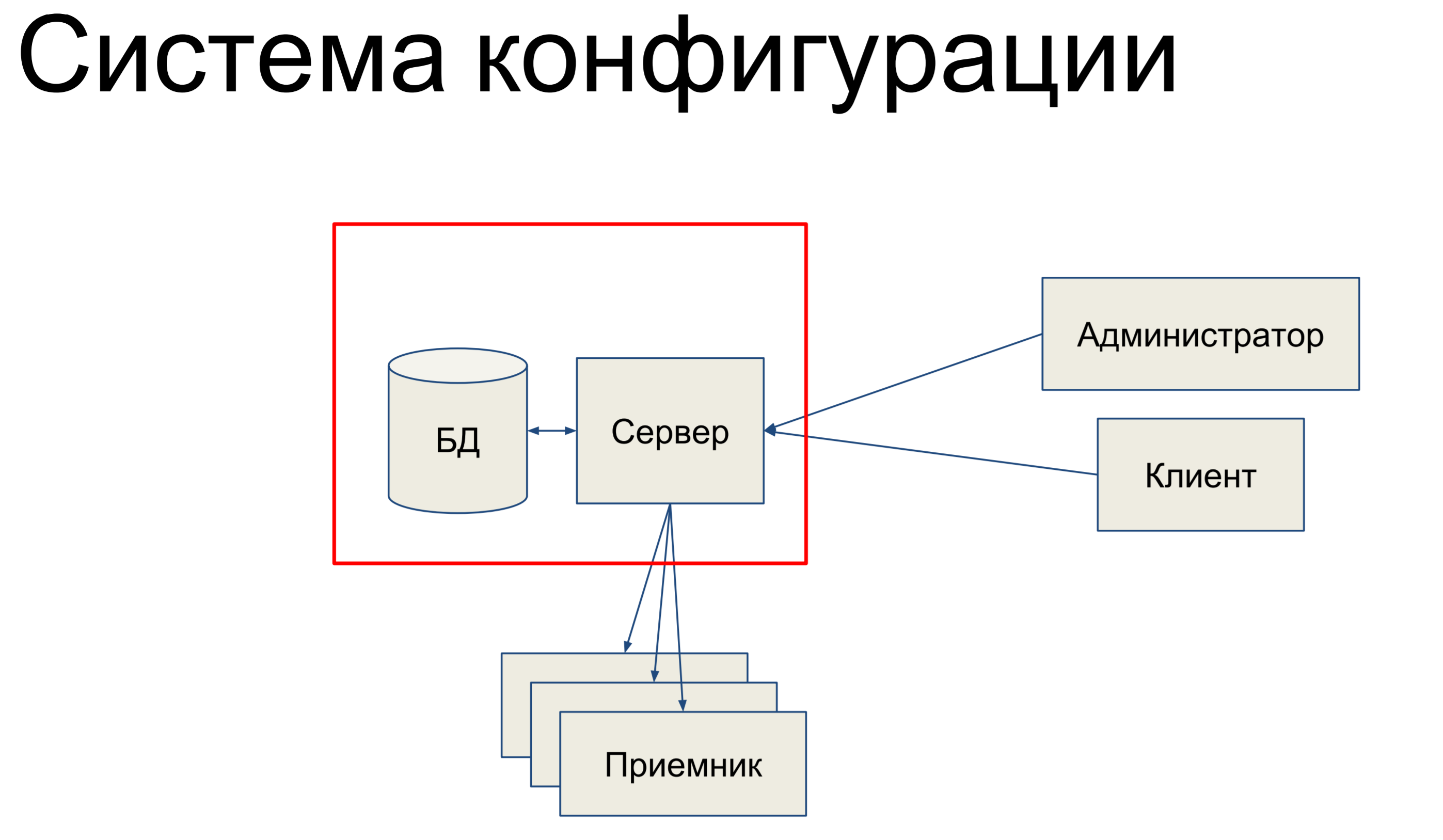
Como é ela quem está relacionada ao banco de dados e à alquimia.

Qual é a peculiaridade deste sistema? É bem pequeno - medíocre. Centenas de milhares, até milhões, de entidades são armazenadas neste banco de dados. A peculiaridade é que o gráfico das relações entre entidades é bastante complexo. Existem várias hierarquias de herança entre entidades, existem inclusões, existem simplesmente dependências entre elas. Todas essas restrições são determinadas pela lógica de negócios e devemos cumpri-las.
A proporção de solicitações de gravação para solicitações de leitura é de aproximadamente 15: 1. Aqui está claro: existem muitos comandos para alterar a configuração e, uma vez em um determinado período de tempo, enviamos a configuração para os pontos finais.
O MySQL é usado internamente - também está disponível em outros produtos da nossa empresa, temos uma experiência bastante séria nesse banco de dados, existem pessoas que podem trabalhar com ele: criar um esquema de dados, criar consultas e tudo mais. Portanto, tomamos o MySQL como um banco de dados relacional universal.

Qual foi o problema depois que projetamos esse sistema? A execução de um comando levou de um a trinta segundos, dependendo da complexidade da equipe. Consequentemente, o atraso na execução chegou a cinco minutos. Uma equipe chegou - 30 segundos, o segundo e assim por diante, uma pilha de acumulados - um atraso de 5 minutos.
O atraso na aplicação da configuração é de até dez minutos. Foi decidido que isso não era suficiente para nós e que a otimização era necessária.

Primeiro, antes de realizar qualquer otimização, é necessário realizar uma investigação e descobrir qual é realmente o problema.

Como se viu, não tínhamos o componente mais importante para a investigação - não tínhamos telemetria. Portanto, se você estiver projetando algum tipo de sistema, primeiro, no estágio de design, coloque telemetria nele. Mesmo que o sistema seja inicialmente pequeno, um pouco mais e mais - no final, todo mundo chega a uma situação em que você precisa assistir a trilhas, mas não há telemetria.
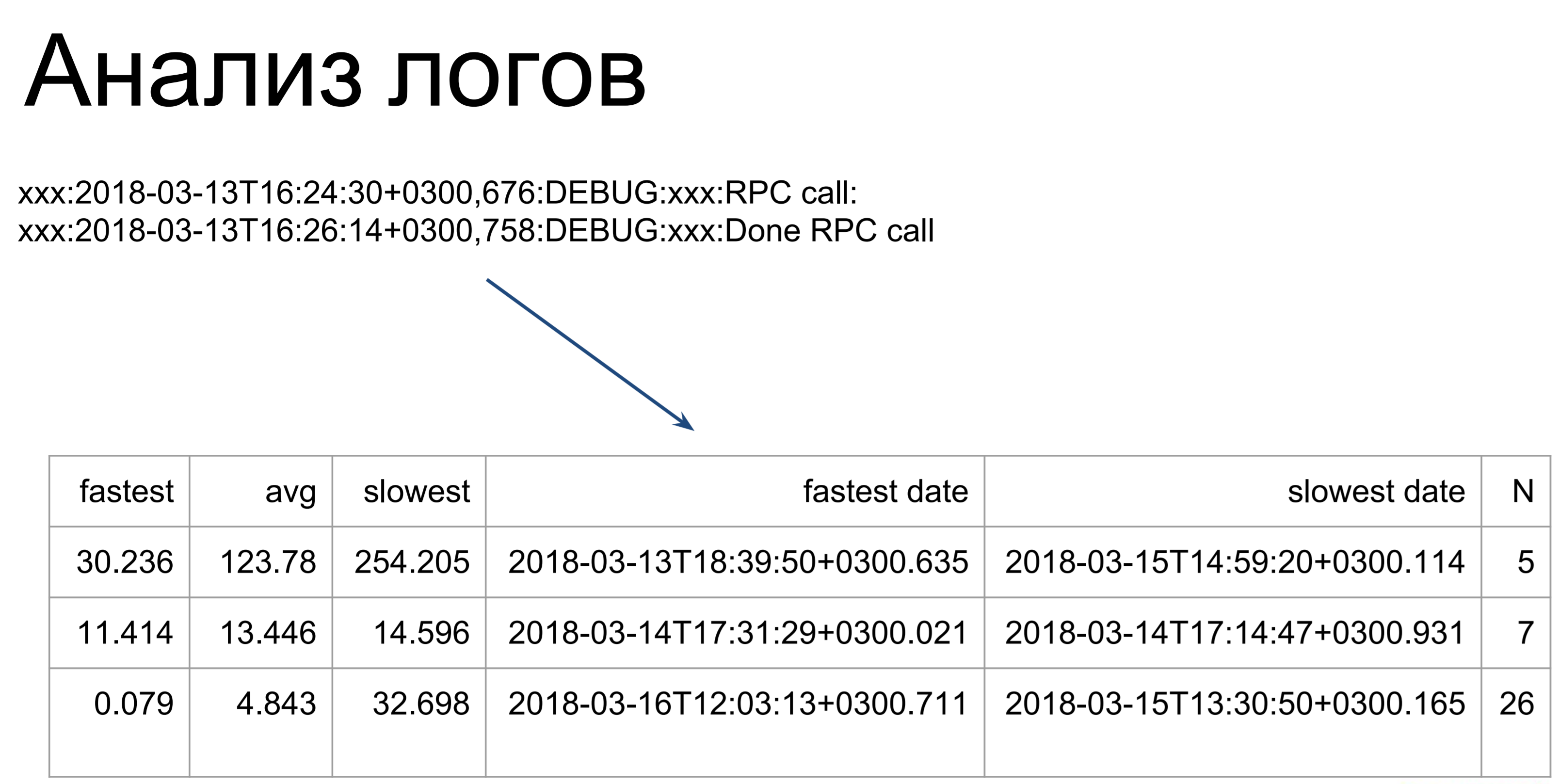
O que pode ser feito a seguir se você não tiver telemetria? Você pode analisar os logs. Aqui, scripts bastante simples passam por nossos logs e os transformam em uma tabela, ilustrando os tempos de execução de comando mais rápidos, lentos e médios. A partir daqui, já podemos ver em quais lugares temos piadas: quais equipes demoram mais para serem executadas e quais são mais rápidas.

A única coisa a observar é que, ao analisar os logs, consideramos apenas o tempo de execução desses comandos no servidor. Este é o primeiro estágio - o marcado como t2. t1 - é assim que o cliente verá o tempo de execução de nossa equipe: entrando na fila, aguardando, execução no servidor. Como esse tempo será mais longo, otimizamos o tempo t2 e, em seguida, usamos o tempo t1 para determinar se atingimos a meta.
t1 é a métrica da qualidade do nosso desempenho.

Dessa forma, é assim que criamos o perfil de todas as equipes - ou seja, pegamos o log do servidor, conduzimos por nossos scripts, analisamos e identificamos os componentes que funcionavam mais lentamente. O servidor é construído de forma bastante modular, um componente separado é responsável por cada comando e podemos criar um perfil individual dos componentes - e fazer benchmarks para eles. Então, aqui tivemos uma classe - para cada componente problemático que escrevemos, no qual em code_under_test () realizamos alguma atividade representando o uso de combate do componente. E havia dois métodos: profile () e bench (). A primeira chama cProfile, mostrando quantas vezes o que foi chamado, onde estão os gargalos.
bench () foi executado várias vezes e considerou métricas diferentes para nós - foi assim que avaliamos o desempenho.
Mas acabou que este não é o problema!

O principal problema foi o número de consultas ao banco de dados. Havia muitos pedidos e, para entender por que havia tantos, vejamos como tudo foi organizado.
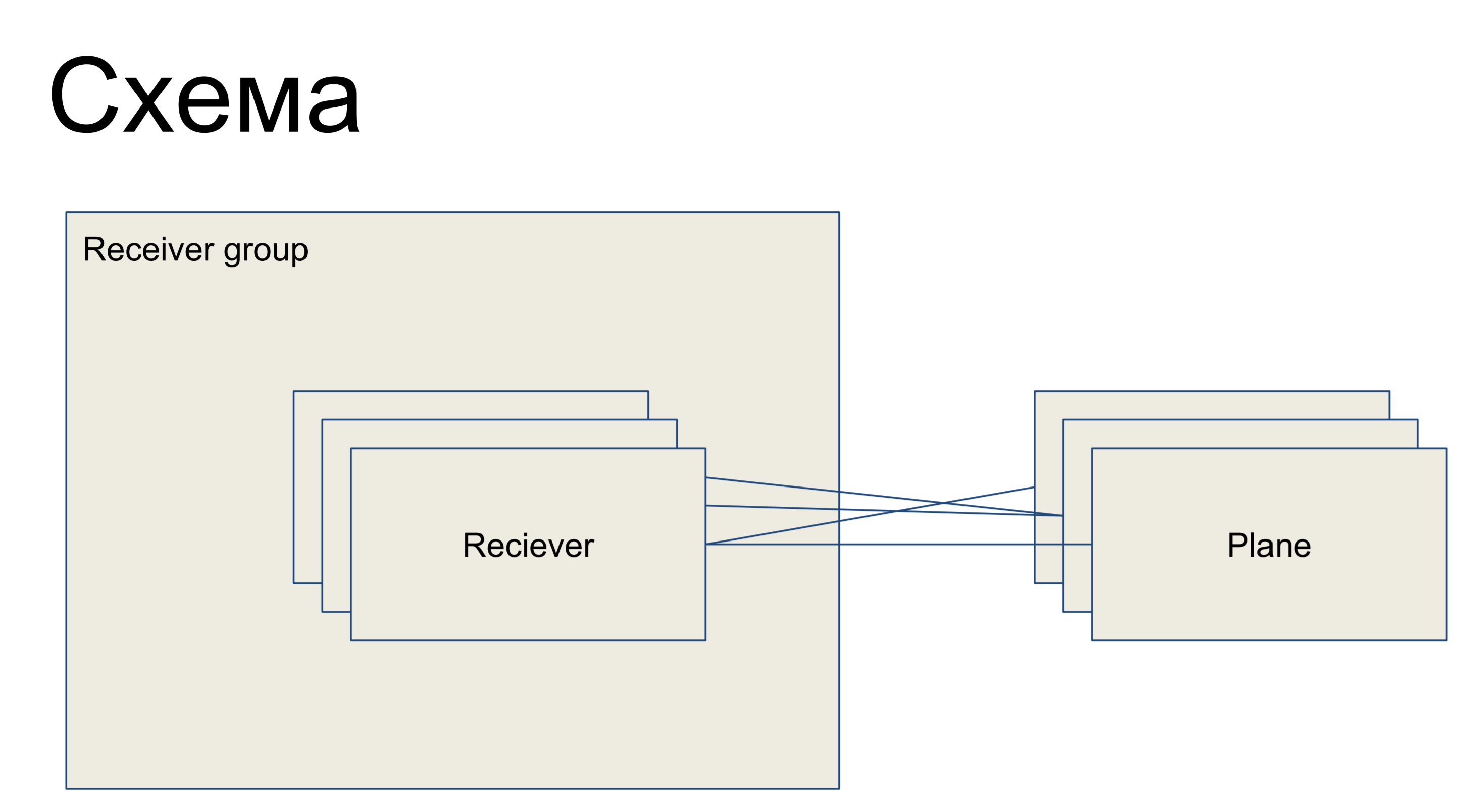
À nossa frente está um pedaço de um circuito simples que representa nossos receptores, apresentado na forma da classe Receptor. Eles estão unidos em algum grupo receptor - grupo. E, consequentemente, existem alguns planos de configuração - fatias da configuração, que são um subconjunto das configurações que são responsáveis por uma "função" desse receptor. Por exemplo, para roteamento - plano de roteamento. As planícies com receptores podem ser conectadas em qualquer ordem - ou seja, esse é um relacionamento de muitos para muitos.
Este é um pedaço do grande esboço que estou apresentando aqui para que os exemplos possam ser melhor compreendidos.
O que todo cosmonauta de arquitetura quer fazer quando vê a API de outra pessoa? Ele quer ocultá-lo, abstrair e escrever sua interface para poder remover esta API, ou melhor, ocultá-la.
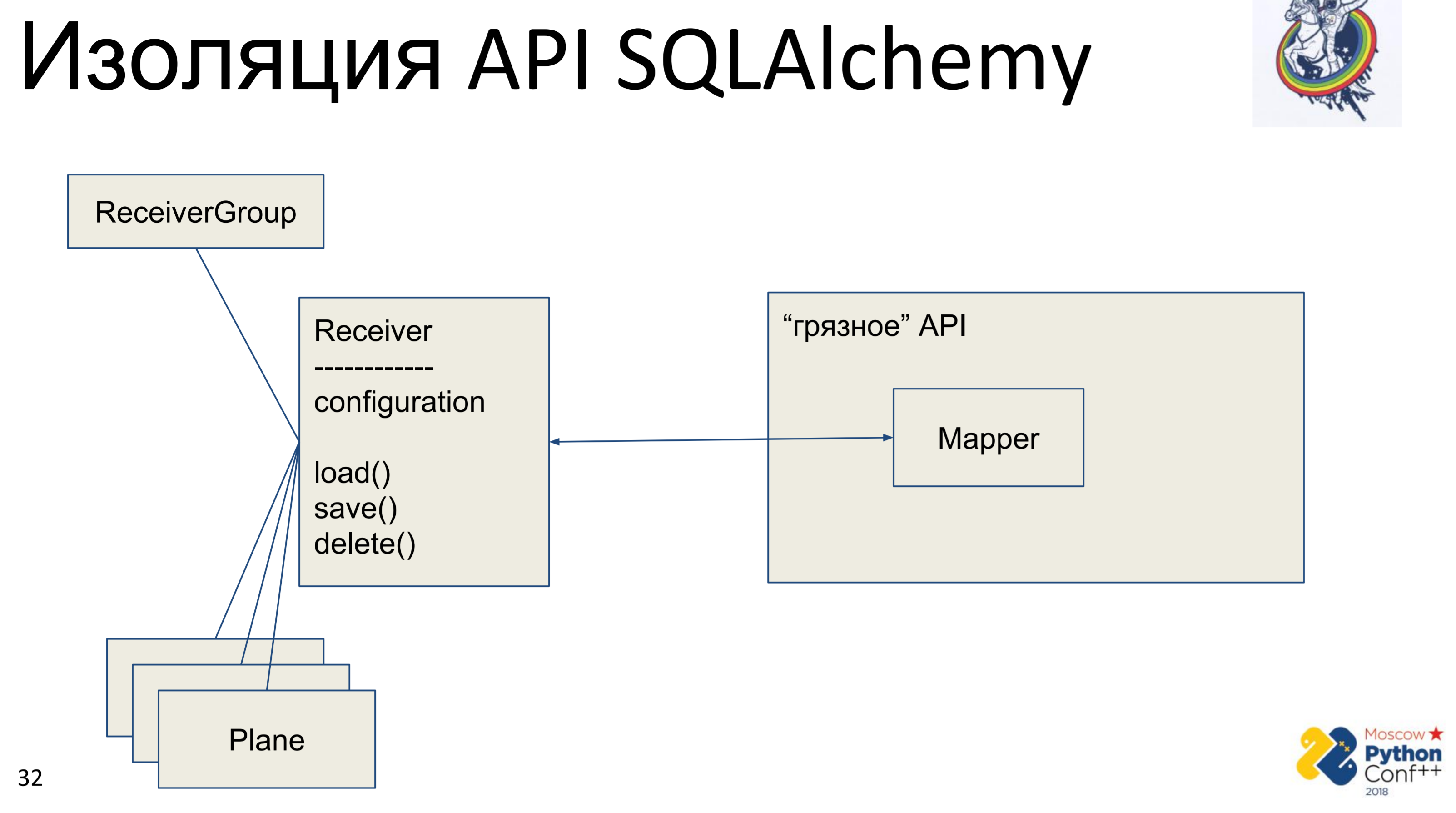
Assim, existe uma API "suja" da alquimia, na qual existem, de fato, mapeadores e nossa classe "pura" - Receiver, na qual algumas configurações são armazenadas e existem métodos: load (), save (), delete (). E todas as outras classes associadas a ele. Nós obtemos um gráfico de objetos Python, de alguma forma conectados entre si - cada um deles possui um método load (), save (), delete (), que se refere ao mapeador de alquimia, que, por sua vez, chama a API.

A implementação aqui é muito simples. Temos um método de carregamento que faz uma consulta ao banco de dados e, para cada objeto recebido, cria seu próprio objeto Python. Existe um método de salvamento que faz a operação oposta - parece que existe um objeto no banco de dados usando a chave primária, caso contrário - ele cria, adiciona e, em seguida, salvamos o estado desse objeto. excluir na chave primária recebe e exclui o objeto do banco de dados.

O principal problema é imediatamente visível - este é o mapeamento. Primeiro, fazemos isso uma vez do objeto Python para o mapeador, depois o mapeador para a base. O mapeamento adicional é uma ou duas chamadas, o que pode não ser tão assustador ainda. O principal problema foi a sincronização manual. Temos dois objetos de nossa interface "limpa" e um deles altera o atributo - como vemos que o atributo mudou no outro? De jeito nenhum. É necessário mesclar as alterações no banco de dados e obter o atributo em outro objeto. Obviamente, se sabemos que os objetos estão presentes no mesmo contexto, podemos rastrear isso. Mas se tivermos duas sessões em lugares diferentes - apenas através da base ou bloquear a base na memória, o que não fizemos.
Esse carregamento / salvamento / exclusão é outro mapeador que duplica completamente o interior da alquimia, que é bem escrito e testado. Essa ferramenta tem muitos anos, existe muita ajuda na Internet e a duplicação também não é muito boa.
Veja o ícone no canto superior direito? Marcarei os slides nos quais algo é feito para "pureza", para aumentar o nível de abstração, para a astronáutica arquitetônica. Ou seja, slides sem esse ícone são pragmáticos e chatos, desinteressantes e não podem ser lidos.
O que fazer se muitas consultas forem lentas. Quantos? Na verdade muito. Imagine uma cadeia de herança: um objeto, ele tem um pai, que um tem outro pai. Sincronizamos o objeto filho - para fazer isso, primeiro você precisa sincronizar os pais. Para sincronizar um pai, você precisa sincronizar seu pai. Bem, todo mundo estava sincronizado. De fato, dependendo de como construímos o gráfico, podemos caminhar e sincronizar todos esses objetos centenas de vezes - daí um grande número de solicitações.
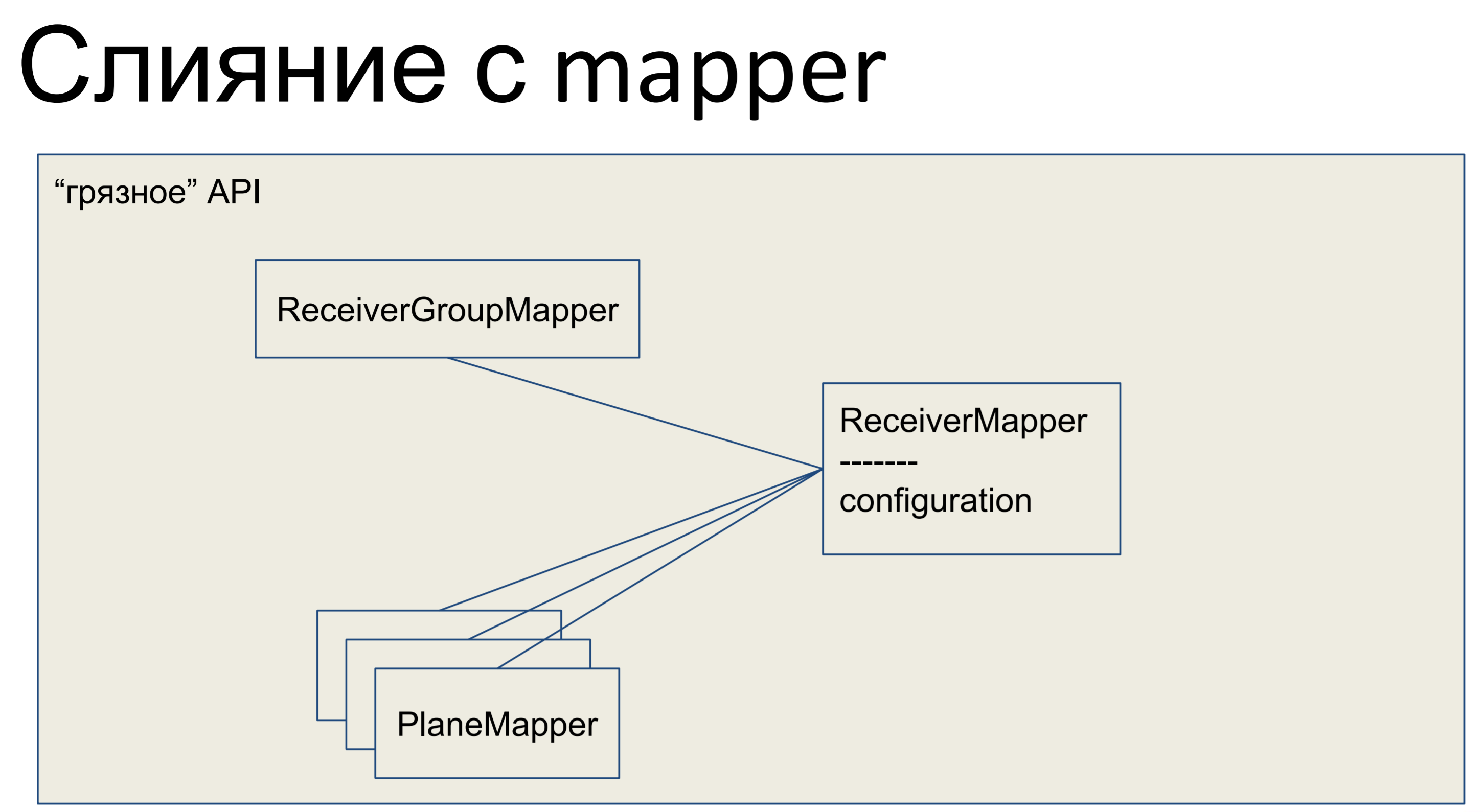
O que fizemos? Pegamos toda a nossa lógica de negócios e a colocamos no mapeador. Todos os outros objetos aqui também se fundiram com os mapeadores, e toda a nossa API, toda a camada de abstração de dados, ficou suja.

É assim que fica em Python - nosso mapeador possui algum tipo de lógica de negócios, há uma descrição declarativa dessa placa ali. Colunas são listadas, relacionamentos. Aqui nós temos essa classe.

Obviamente, do ponto de vista de qualquer astronauta, uma API suja é uma desvantagem. Lógica comercial em uma descrição declarativa da base. Os esquemas são misturados à lógica de negócios. Ufa. Feio.
A descrição do circuito está confusa. Na verdade, isso é um problema - se a lógica de negócios não tiver duas linhas, mas um volume maior, nessa classe, precisamos rolar ou procurar por um período muito longo para obter descrições específicas. Antes disso, tudo era bonito: em um lugar a descrição da base, declarativa, descrição dos esquemas, em outro lugar, a lógica de negócios. E então o circuito está confuso.
Mas, por outro lado, obtemos imediatamente os mecanismos da alquimia: unidade de trabalho, que permite rastrear quais objetos estão sujos e quais relés precisam ser atualizados; obtemos um relacionamento que nos permite eliminar perguntas adicionais no banco de dados, sem garantir que as coleções relevantes sejam preenchidas; e o mapa de identidade que mais nos ajudou. O mapa de identidade garante que dois objetos Python serão o mesmo objeto Python se eles tiverem a mesma chave primária.
Consequentemente, reduzimos imediatamente a complexidade para linear.

Estes são resultados intermediários. O desempenho aumentou imediatamente 10 vezes, o número de consultas ao banco de dados caiu cerca de 40-80 vezes e o RPS aumentou para 1-5. Bem bom. Mas a API está suja. O que fazer
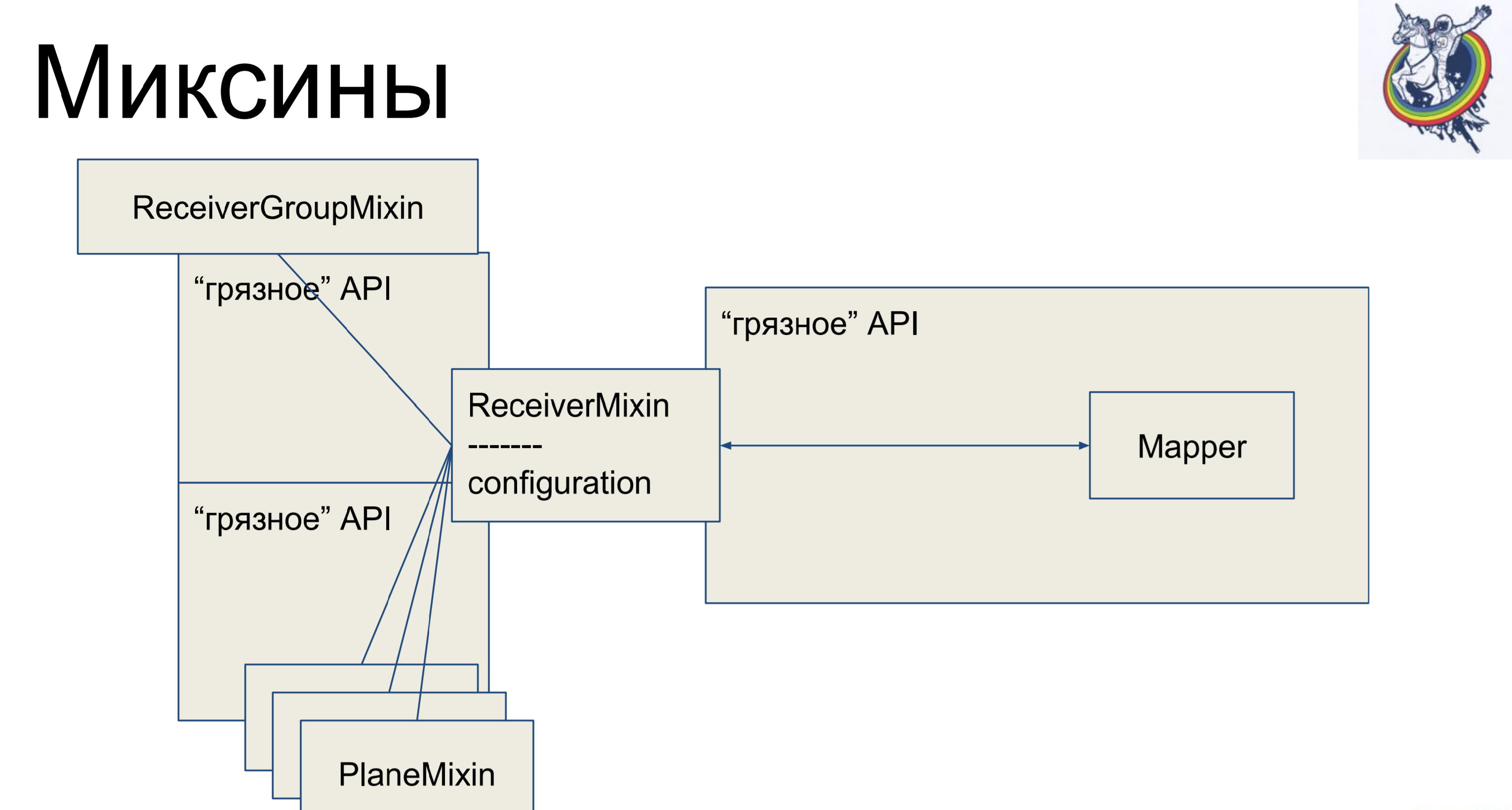
Mixins. Adotamos a lógica de negócios, novamente a removemos do nosso mapeador, mas, para que não haja mais mapeamento, herdaremos nosso mapeador dentro da alquimia da nossa combinação. Por que não o contrário? Isso não funcionará na alquimia, ela jurará e dirá: "Você tem duas classes diferentes referentes a um tablet, não há poliformismo - vá daqui". E assim - é possível.
Portanto, temos uma descrição declarativa no mapeador, que é herdada do mixin e recebe toda a lógica de negócios. Muito confortável E o resto das aulas são exatamente iguais. Parece - legal, tudo está limpo. Mas há uma ressalva - as conexões e os relés permanecem dentro da alquimia e, quando, digamos, nos unimos através de uma tabela secundária de placas intermediárias, o mapeador dessa placa estará presente no código do cliente, o que não é muito bonito.
A alquimia não teria sido uma estrutura tão boa e famosa se não tivesse me dado a oportunidade de lutar contra isso.

Como é o mixin. Ele tem lógica de negócios, mapeadores separadamente, uma descrição declarativa do prato. As conexões permanecem dentro da alquimia, mas a lógica de negócios é separada.
Como é o esquema geral?
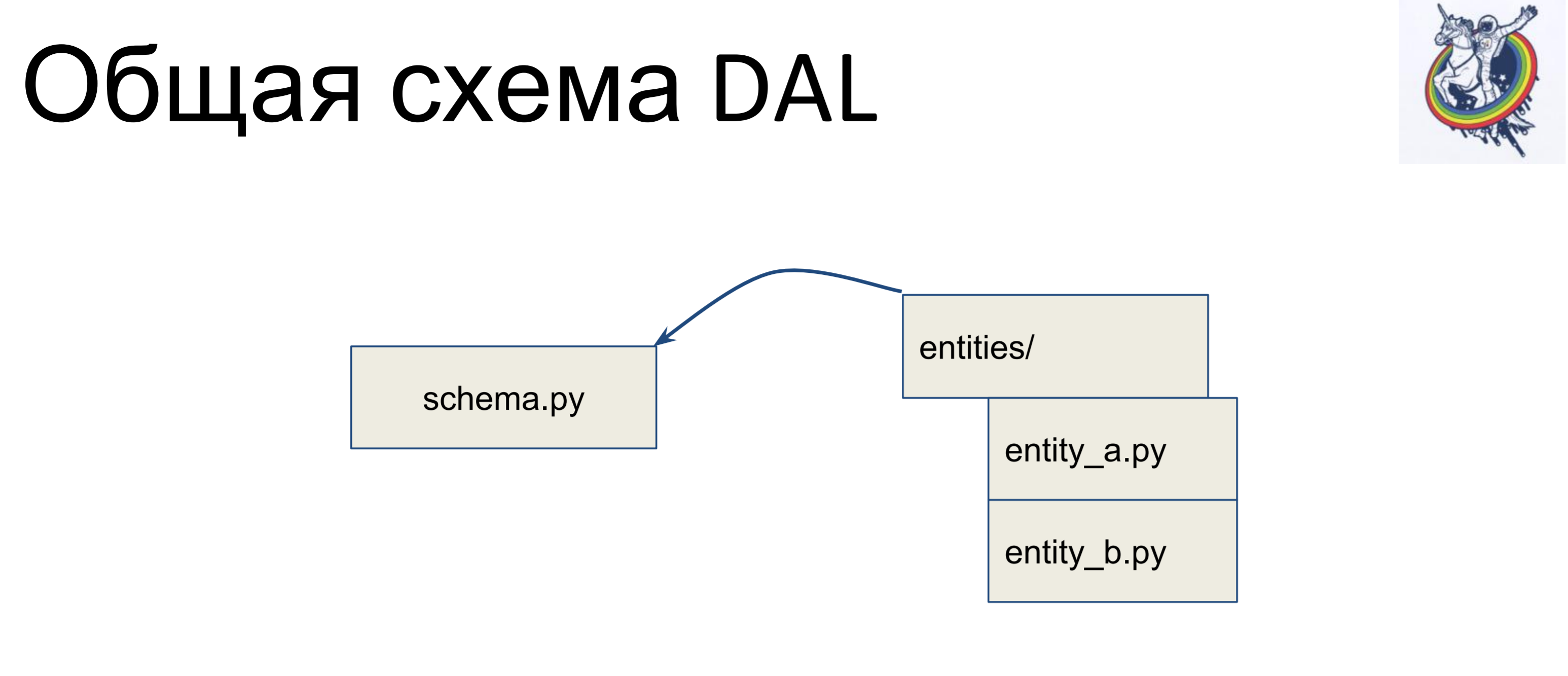
Temos um arquivo com um esquema no qual todas as nossas classes declarativas são coletadas - vamos chamá-lo de schema.py. E temos entidades na lógica de negócios, separadamente. E essas entidades são herdadas dentro do arquivo do esquema - escrevemos uma classe separada para cada entidade e a herdamos no esquema. Assim, a lógica de negócios está em uma pilha, o esquema em outra e elas podem ser alteradas independentemente.
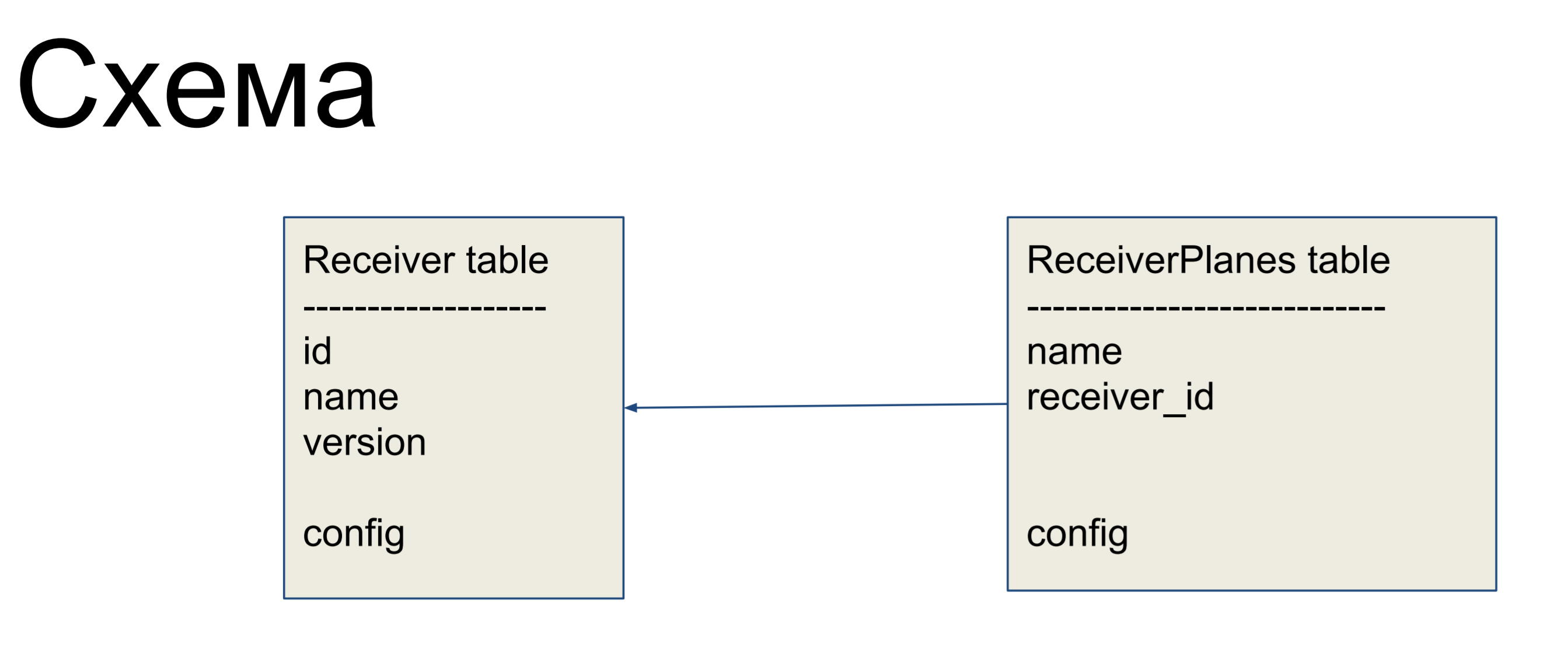
Como exemplo de aprimoramento, consideraremos um esquema simples de dois rótulos: receptores (tabela Receiver) e fatias da configuração (tabela ReceiverPlanes). Fatias de configuração muitos para um são associadas ao rótulo do receptor. Não há nada particularmente complicado.
Para ocultar relacionamentos dentro da interface "suja" da alquimia, usamos relacionamentos e coleções.

Eles nos permitem ocultar nossos mapeadores do código do cliente.

Em particular, duas coleções muito úteis são association_proxy e attribute_mapped_collection. Nós os usamos juntos. Como a relação clássica funciona na alquimia: temos uma relação - essa é uma certa coleção, lista, mapeadores. Mapeadores são objetos de relacionamento de ponta remota. Attribute_mapped_collection permite substituir esta lista por um ditado, as chaves nas quais serão alguns dos atributos dos mapeadores e os valores são os próprios mapeadores.
Este é o primeiro passo.
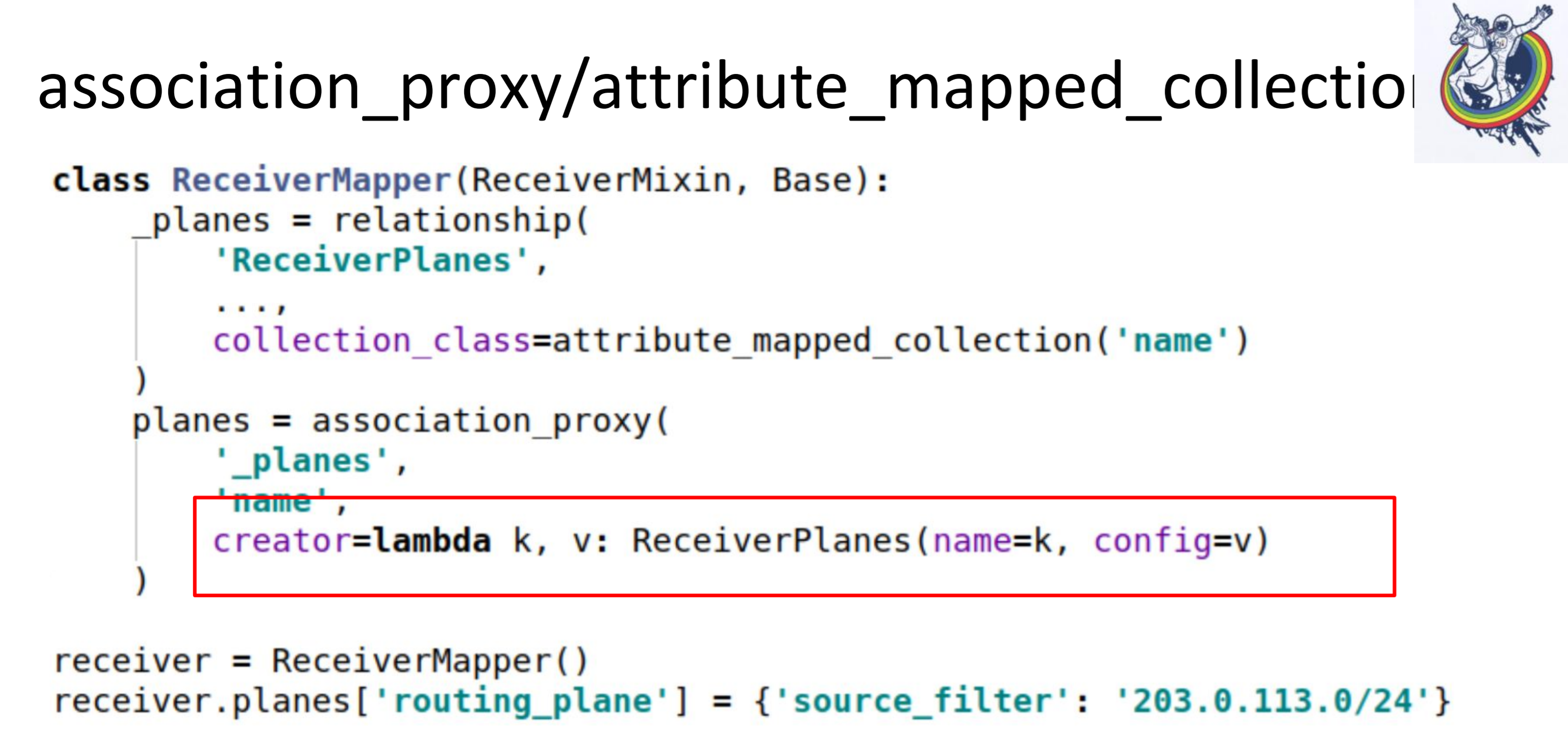
O segundo passo, fazemos associação_proxy sobre esse relacionamento. Ele nos permite não passar o mapeador para a coleção, mas passar algum valor que posteriormente será usado para inicializar nosso mapeador, ReceiverPlanes.
Aqui temos lambda, na qual passamos a chave e o valor. A chave se transforma no nome da fatia de configuração e o valor no valor da fatia de configuração. Como resultado, no código do cliente, tudo se parece com isso.

Apenas colocamos algum tipo de ditado em algum tipo de dicionário. Tudo funciona: sem mapeadores, sem alquimia, sem bancos de dados.
É verdade que existem armadilhas.

Se atribuirmos valores diferentes, ou mesmo um, à mesma chave duas vezes - lambda é chamado para cada item definido, um objeto é criado - um mapeador. E, dependendo de como o esquema está estruturado, isso pode levar a várias consequências, de “apenas violações das constantes” a conseqüências imprevisíveis. Por exemplo, você meio que excluiu um objeto da coleção, mas ele ainda permaneceu lá: você excluiu apenas um. Quando comecei, matei muito tempo com essas coisas.
E um pouco de sincronização implícita. Association_proxy e attribute_mapped_collection podem demorar um pouco: quando criamos um objeto mapeador, ele é adicionado ao banco de dados, mas ainda não está presente no atributo collection. Aparecerá apenas quando o atributo expirar nesta sessão. Quando expirar, uma nova sincronização com o banco de dados ocorrerá e chegará lá.
Para superar isso, usamos nossas próprias coleções auto-escritas. Isso nem é alquimia - você pode simplesmente criar sua própria coleção para superar tudo isso.
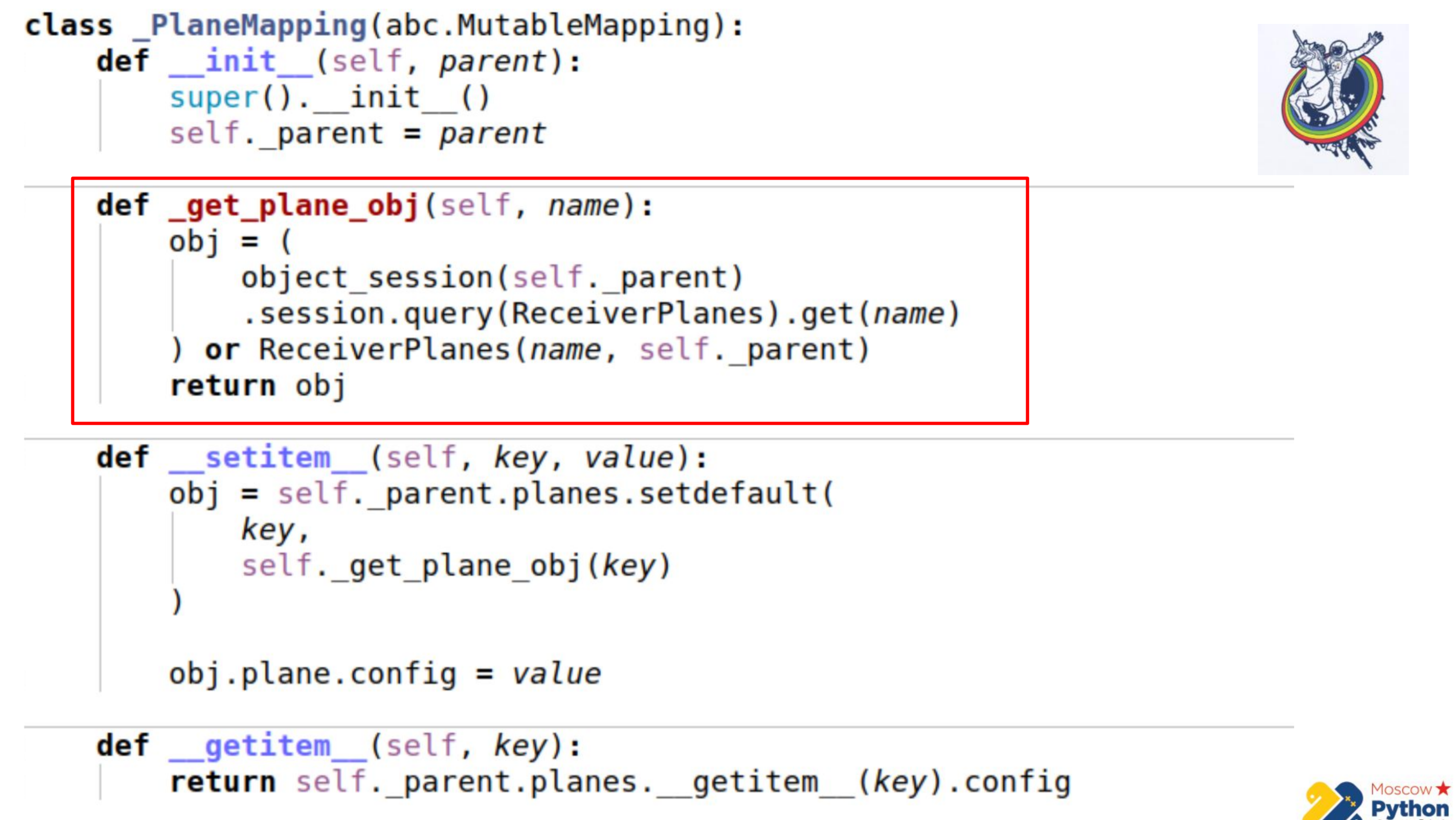
Há mais código e a parte mais importante é destacada. Temos uma certa coleção que herda de mapeamento mutável - este é um ditado, nas chaves das quais você pode alterar os valores. E existe um método _get_plane_obj - para obter o objeto de fatia de configuração.
Aqui fazemos coisas simples - tentamos obtê-lo pelo nome, por alguma chave primária e, se não for, criamos e retornamos esse objeto.
Em seguida, redefinimos apenas dois métodos: __setitem__ e __getitem__
No __setitem__, colocamos esses objetos em nossa coleção, em um relacionamento. A única coisa é que atribuímos valor no final. Assim, implementamos o mesmo mecanismo que o association_proxy - transmite o valor, dite para ele e ele é atribuído ao atributo correspondente.
__getitem__ faz a manipulação inversa. Ele recebe por chave algum objeto do relé e retorna seu atributo. Há também uma pequena armadilha aqui - se você armazenar em cache a coleção dentro do nosso mapeamento, é possível sair um pouco da sincronização. Como quando o atributo da coleção expira na alquimia, a coleção é substituída por outra, após a expiração. Portanto, podemos manter a referência à coleção antiga e não saber que a antiga expirou e que uma nova já apareceu. Portanto, na última parte, vamos diretamente para a instância da alquimia, novamente obtemos a coleção através de __getattr__ e fazemos __getitem__ com ela. Ou seja, não podemos armazenar em cache a coleção Planes aqui.
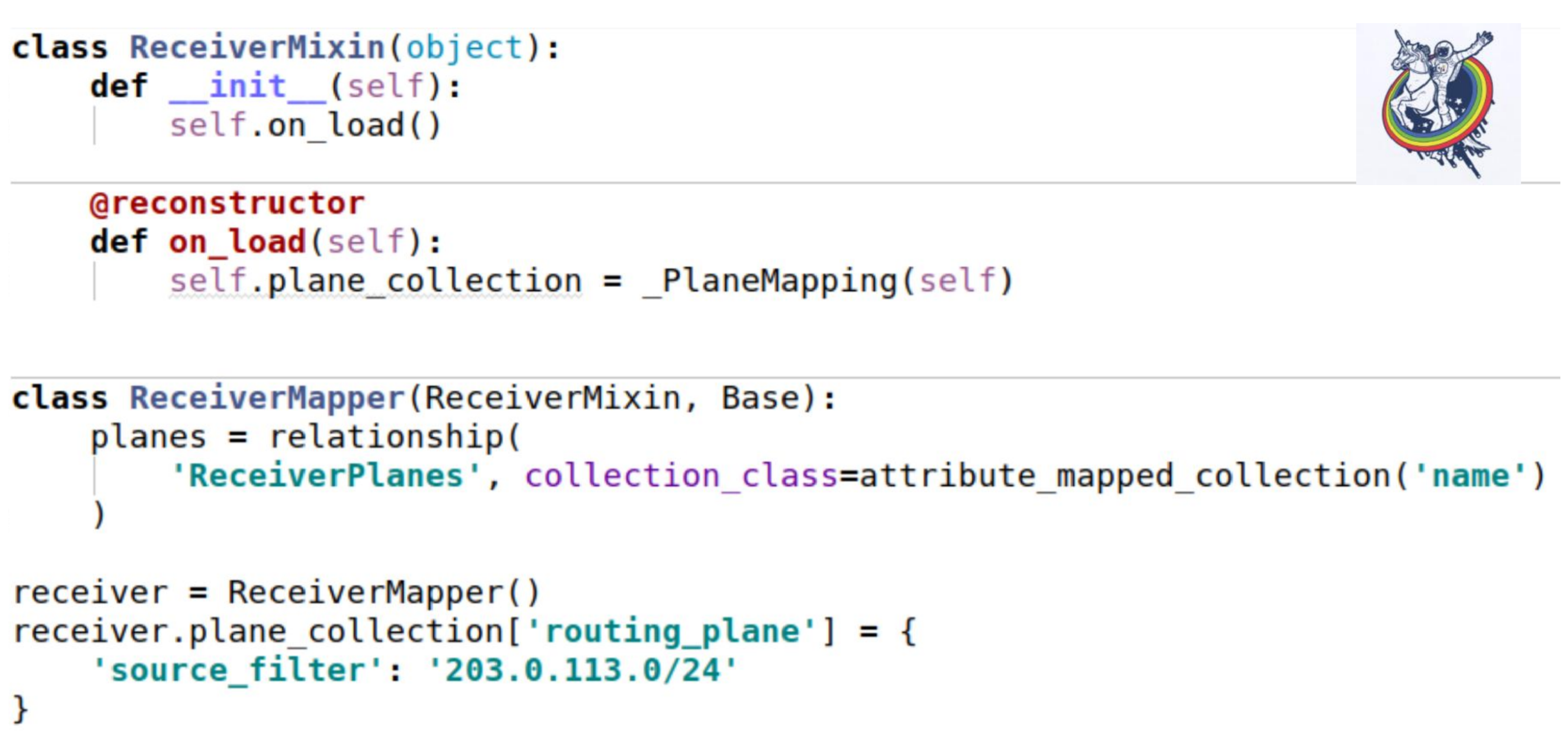
Como essa coleção afeta nossos mixins? Como sempre - configure um atributo de coleção. O único lugar interessante é que, quando carregamos uma instância do banco de dados, o método __init__ não é chamado. Todos os atributos são substituídos ex post.
A alquimia fornece um decorador de reconstrutor padrão, que permite marcar algum método como sendo chamado após o carregamento de um objeto do banco de dados. E apenas no momento da inicialização, precisamos inicializar nossa coleção. O eu é apenas essa instância. O uso é exatamente o mesmo que no exemplo anterior.
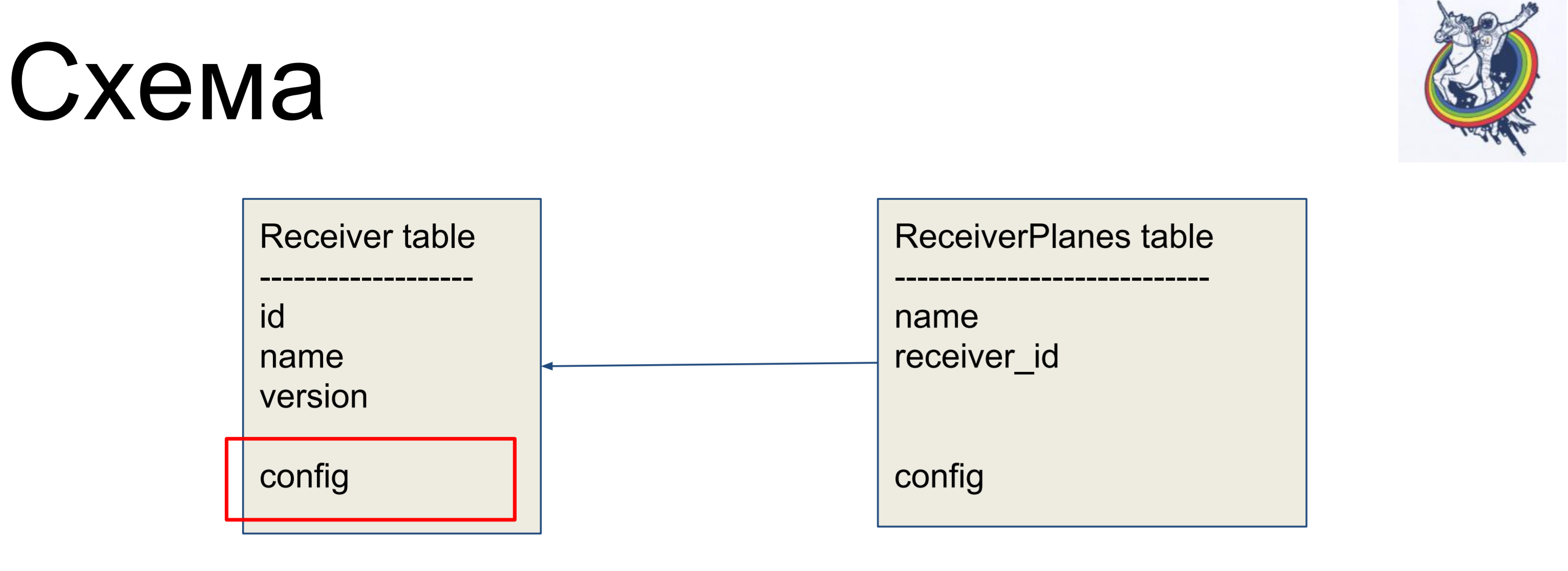
Mas em nosso esquema, os ouvidos do banco de dados ainda estão visíveis - essa é a configuração. Que tipo de configuração? É varchar ou é blob? De fato, o cliente não está interessado.
Ele deve trabalhar com entidades abstratas de seu nível. Para isso, a alquimia fornece decoração tipo. Um exemplo simples. Nosso banco de dados armazena o endereço IP como um varchar. Utilizamos a classe TypeDecorator, que faz parte da alquimia, que permite, primeiro, indicar qual tipo de banco de dados subjacente será usado para esse tipo e, em segundo lugar, definir dois parâmetros: process_bind_param convertendo o valor para o tipo de banco de dados e process_result_value quando valorizamos do tipo de banco de dados, converta para um objeto Python.O atributo do endereço assume o tipo python IPAddress. E podemos chamar métodos desse tipo e atribuir objetos desse tipo a ele, e tudo funciona para nós. E está armazenado no banco de dados ... não sei o que está armazenado, varchar (45), mas podemos substituir essa linha e o blob será armazenado. Ou, se algum tipo nativo suportar endereços IP, você poderá usá-lo.O código do cliente não depende disso, não precisa ser reescrito.
Um exemplo simples. Nosso banco de dados armazena o endereço IP como um varchar. Utilizamos a classe TypeDecorator, que faz parte da alquimia, que permite, primeiro, indicar qual tipo de banco de dados subjacente será usado para esse tipo e, em segundo lugar, definir dois parâmetros: process_bind_param convertendo o valor para o tipo de banco de dados e process_result_value quando valorizamos do tipo de banco de dados, converta para um objeto Python.O atributo do endereço assume o tipo python IPAddress. E podemos chamar métodos desse tipo e atribuir objetos desse tipo a ele, e tudo funciona para nós. E está armazenado no banco de dados ... não sei o que está armazenado, varchar (45), mas podemos substituir essa linha e o blob será armazenado. Ou, se algum tipo nativo suportar endereços IP, você poderá usá-lo.O código do cliente não depende disso, não precisa ser reescrito.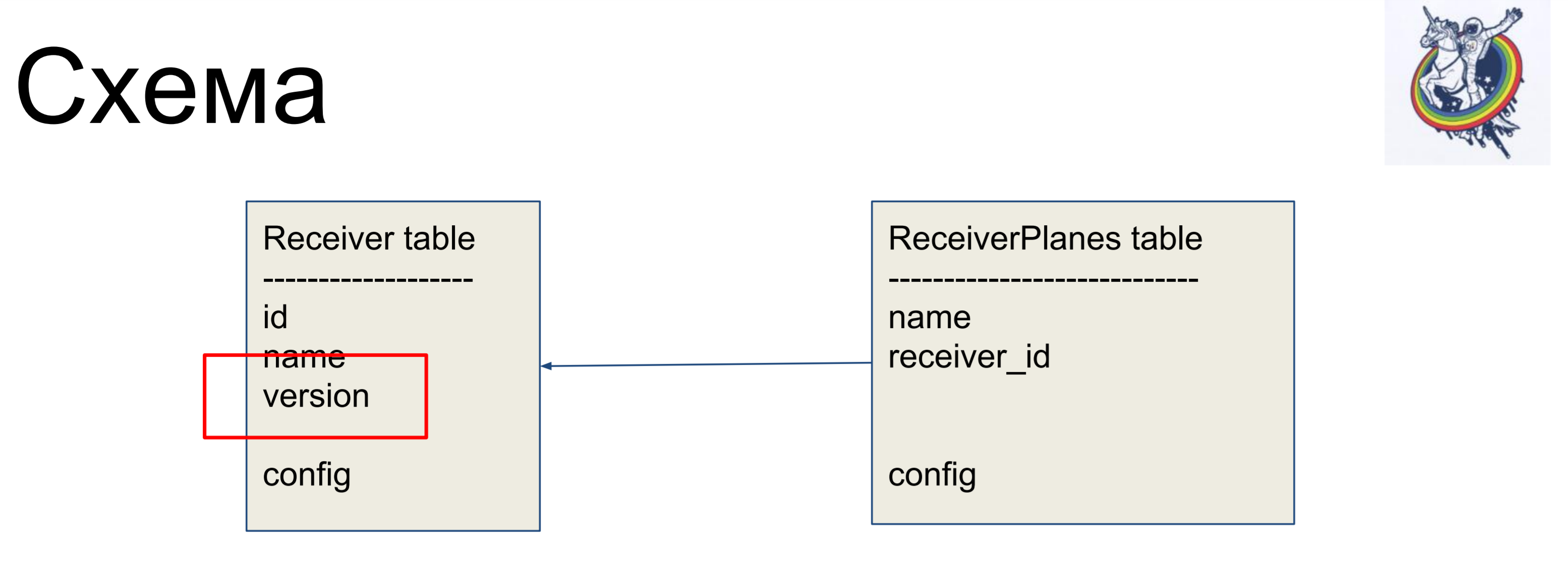 Outra coisa interessante é que temos uma versão. Queremos que assim que mudarmos nosso objeto, a versão aumente imediatamente. Temos algum contador de versão, alteramos o objeto - ele mudou, a versão aumentou. Fazemos isso automaticamente para não esquecer.
Outra coisa interessante é que temos uma versão. Queremos que assim que mudarmos nosso objeto, a versão aumente imediatamente. Temos algum contador de versão, alteramos o objeto - ele mudou, a versão aumentou. Fazemos isso automaticamente para não esquecer. Para isso, usamos eventos. Eventos são eventos que ocorrem em diferentes estágios da vida de um mapeador e podem ser acionados quando os atributos mudam, quando uma entidade muda de um estado para outro, por exemplo, "criado", "salvo no banco de dados", "carregado a partir do banco de dados", "excluído"; e também - em eventos no nível da sessão, antes que o código sql seja emitido no banco de dados, antes da confirmação, após a confirmação e também após a reversão.A alquimia nos permite atribuir manipuladores para todos esses eventos, mas a ordem na qual os manipuladores são executados para o mesmo evento não é garantida. Ou seja, é específico, mas não se sabe qual. Portanto, se a ordem de execução for importante para você, será necessário executar um mecanismo de registro.
Para isso, usamos eventos. Eventos são eventos que ocorrem em diferentes estágios da vida de um mapeador e podem ser acionados quando os atributos mudam, quando uma entidade muda de um estado para outro, por exemplo, "criado", "salvo no banco de dados", "carregado a partir do banco de dados", "excluído"; e também - em eventos no nível da sessão, antes que o código sql seja emitido no banco de dados, antes da confirmação, após a confirmação e também após a reversão.A alquimia nos permite atribuir manipuladores para todos esses eventos, mas a ordem na qual os manipuladores são executados para o mesmo evento não é garantida. Ou seja, é específico, mas não se sabe qual. Portanto, se a ordem de execução for importante para você, será necessário executar um mecanismo de registro.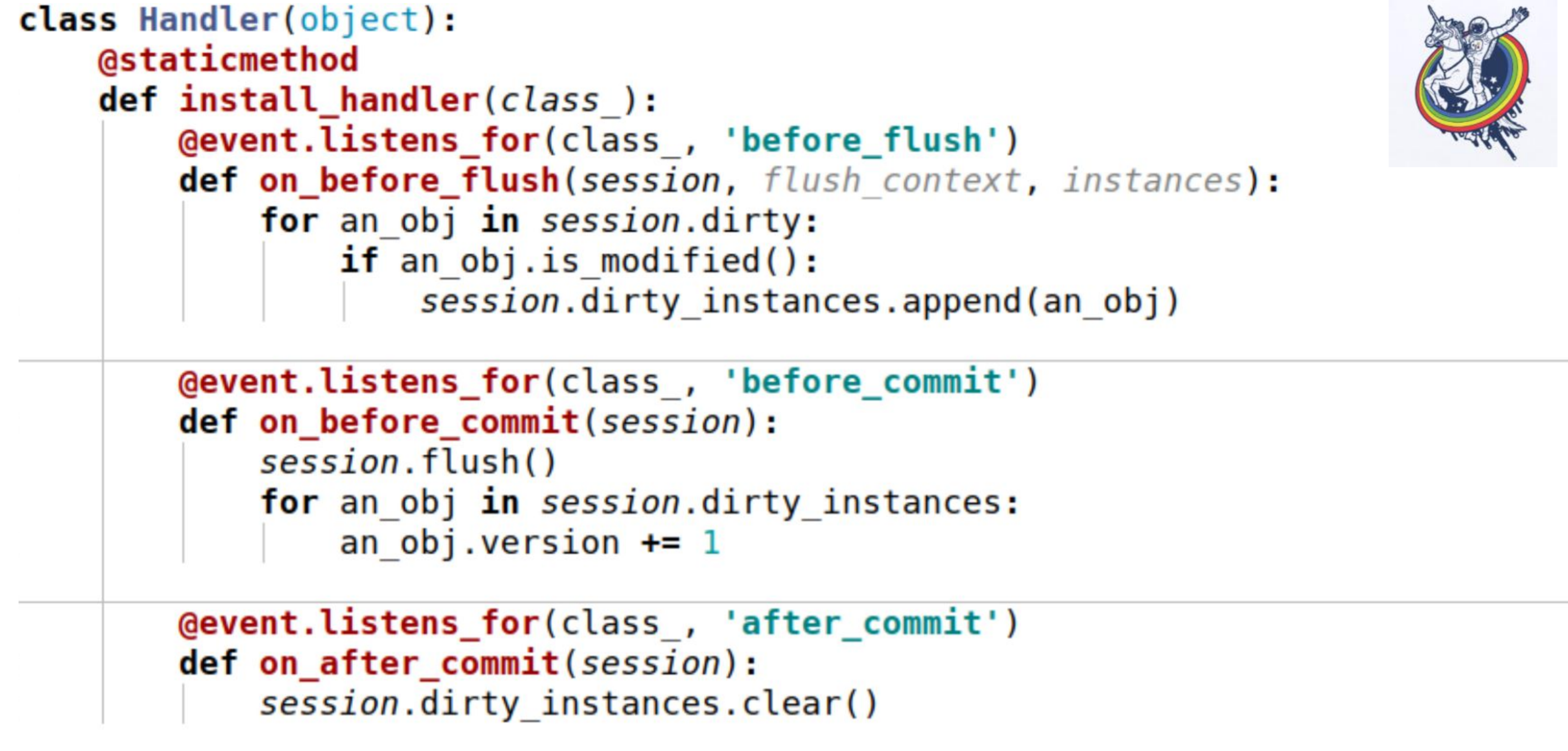 Aqui está um exemplo. Três eventos são usados aqui:on_before_flush - antes que o código sql seja emitido para o banco de dados, examinamos todos os objetos que a alquimia marcou como sujos nesta sessão e verificamos se esse objeto foi modificado ou não. Por que isso é necessário se a alquimia já marcou tudo? A alquimia marca um objeto como sujo assim que algum atributo é alterado. Se atribuirmos o mesmo valor a esse atributo que ele possuía, ele será marcado como sujo. Existe um método de sessão is_modified para isso - ele é usado internamente, não o desenhei. Além disso, do ponto de vista de nossa semântica, do ponto de vista de nossa lógica de negócios, mesmo que o atributo tenha sido alterado, o objeto ainda pode permanecer inalterado. Por exemplo, há uma certa lista na qual dois elementos são trocados - do ponto de vista da alquimia, o atributo foi alterado, mas isso não importa para a lógica de negócios se, por exemplo,algum tipo.E, no final, chamamos outro método específico para cada objeto para entender se o objeto é ou não modificado. E nós os adicionamos a uma determinada variável associada à sessão que criamos - esta é a nossa variável dirty_instances, na qual adicionamos esse objeto.O seguinte evento ocorre antes do commit - before_commit. Há também uma pequena armadilha: se não tivermos um único flush para toda a transação, o flush será chamado antes do commit - no meu caso, o manipulador foi chamado antes do commit antes do flush.Como você pode ver, o que fizemos no parágrafo anterior pode não nos ajudar e o session.dirty_instances estará vazio. Portanto, dentro do manipulador, fazemos novamente o flush para que todos os manipuladores sejam chamados antes do flush e simplesmente incrementamos a versão em um.after_commit, after_soft_rollback - após o commit, apenas o limpamos para que não haja excessos na próxima vez.Assim, você vê - este método install_handler instala manipuladores para três eventos ao mesmo tempo. Como classe, passamos a sessão aqui, pois esse é um evento do seu nível.
Aqui está um exemplo. Três eventos são usados aqui:on_before_flush - antes que o código sql seja emitido para o banco de dados, examinamos todos os objetos que a alquimia marcou como sujos nesta sessão e verificamos se esse objeto foi modificado ou não. Por que isso é necessário se a alquimia já marcou tudo? A alquimia marca um objeto como sujo assim que algum atributo é alterado. Se atribuirmos o mesmo valor a esse atributo que ele possuía, ele será marcado como sujo. Existe um método de sessão is_modified para isso - ele é usado internamente, não o desenhei. Além disso, do ponto de vista de nossa semântica, do ponto de vista de nossa lógica de negócios, mesmo que o atributo tenha sido alterado, o objeto ainda pode permanecer inalterado. Por exemplo, há uma certa lista na qual dois elementos são trocados - do ponto de vista da alquimia, o atributo foi alterado, mas isso não importa para a lógica de negócios se, por exemplo,algum tipo.E, no final, chamamos outro método específico para cada objeto para entender se o objeto é ou não modificado. E nós os adicionamos a uma determinada variável associada à sessão que criamos - esta é a nossa variável dirty_instances, na qual adicionamos esse objeto.O seguinte evento ocorre antes do commit - before_commit. Há também uma pequena armadilha: se não tivermos um único flush para toda a transação, o flush será chamado antes do commit - no meu caso, o manipulador foi chamado antes do commit antes do flush.Como você pode ver, o que fizemos no parágrafo anterior pode não nos ajudar e o session.dirty_instances estará vazio. Portanto, dentro do manipulador, fazemos novamente o flush para que todos os manipuladores sejam chamados antes do flush e simplesmente incrementamos a versão em um.after_commit, after_soft_rollback - após o commit, apenas o limpamos para que não haja excessos na próxima vez.Assim, você vê - este método install_handler instala manipuladores para três eventos ao mesmo tempo. Como classe, passamos a sessão aqui, pois esse é um evento do seu nível. Bem aqui. Lembrarei o que alcançamos - velocidade de 30 a 40 segundos para equipes complexas e grandes. De maneira alguma, algumas foram concluídas em um segundo, outras em 200 milissegundos, como você pode ver no RPS. As consultas ao banco de dados começaram a ser contadas em centenas.
Bem aqui. Lembrarei o que alcançamos - velocidade de 30 a 40 segundos para equipes complexas e grandes. De maneira alguma, algumas foram concluídas em um segundo, outras em 200 milissegundos, como você pode ver no RPS. As consultas ao banco de dados começaram a ser contadas em centenas. O resultado é um sistema bastante equilibrado. Havia, no entanto, uma ressalva. Alguns pedidos vêm de nós em lotes, emissões. Ou seja, cerca de 30 pedidos chegam e cada um deles é assim! (o orador mostra o polegar)Se os processarmos um segundo de cada vez, a última solicitação na fila funcionará por 30 segundos. O primeiro, o segundo dois e assim por diante.
O resultado é um sistema bastante equilibrado. Havia, no entanto, uma ressalva. Alguns pedidos vêm de nós em lotes, emissões. Ou seja, cerca de 30 pedidos chegam e cada um deles é assim! (o orador mostra o polegar)Se os processarmos um segundo de cada vez, a última solicitação na fila funcionará por 30 segundos. O primeiro, o segundo dois e assim por diante. Portanto, ainda precisamos acelerar. O que vamos fazer?De fato, a alquimia tem duas partes. A primeira é uma abstração em um banco de dados sql chamado SQLAlchemy Core. O segundo é ORM, o mapeamento real entre o banco de dados relacional e a representação do objeto. Consequentemente, o núcleo da alquimia é de um a um coincide com o sql - se você conhece o último, não terá problemas com o núcleo. Se você não conhece o sql - aprenda o sql.Além disso, o núcleo representa a menor sobrecarga. Praticamente não há bombeamento - as consultas são geradas usando o gerador de consultas e, em seguida, executadas. A sobrecarga sobre o dbapi é mínima.Podemos criar solicitações de qualquer complexidade, de qualquer tipo, podemos otimizá-las para a tarefa. Ou seja, se, no caso geral, o ORM não se importa com a forma como o esquema do banco de dados é construído - há alguma descrição das tabelas, ele gera algumas consultas, sem saber que, neste caso, por exemplo, será ideal selecionar daqui, em outro - a partir daí, como aplicar o filtro, e lá - outro, então aqui podemos fazer solicitações para a tarefa.A desvantagem é que chegamos novamente à sincronização manual. Todos os eventos, relés - tudo isso no núcleo não funciona. Fizemos uma seleção, objetos vieram até nós, fizemos algo com eles, em seguida, atualizamos, inserimos ... você precisa incrementar a versão com as mãos, verifique você mesmo as constantes. O Core não permite que tudo isso seja feito de maneira conveniente, em alto nível.Bem, não vivemos o primeiro dia.
Portanto, ainda precisamos acelerar. O que vamos fazer?De fato, a alquimia tem duas partes. A primeira é uma abstração em um banco de dados sql chamado SQLAlchemy Core. O segundo é ORM, o mapeamento real entre o banco de dados relacional e a representação do objeto. Consequentemente, o núcleo da alquimia é de um a um coincide com o sql - se você conhece o último, não terá problemas com o núcleo. Se você não conhece o sql - aprenda o sql.Além disso, o núcleo representa a menor sobrecarga. Praticamente não há bombeamento - as consultas são geradas usando o gerador de consultas e, em seguida, executadas. A sobrecarga sobre o dbapi é mínima.Podemos criar solicitações de qualquer complexidade, de qualquer tipo, podemos otimizá-las para a tarefa. Ou seja, se, no caso geral, o ORM não se importa com a forma como o esquema do banco de dados é construído - há alguma descrição das tabelas, ele gera algumas consultas, sem saber que, neste caso, por exemplo, será ideal selecionar daqui, em outro - a partir daí, como aplicar o filtro, e lá - outro, então aqui podemos fazer solicitações para a tarefa.A desvantagem é que chegamos novamente à sincronização manual. Todos os eventos, relés - tudo isso no núcleo não funciona. Fizemos uma seleção, objetos vieram até nós, fizemos algo com eles, em seguida, atualizamos, inserimos ... você precisa incrementar a versão com as mãos, verifique você mesmo as constantes. O Core não permite que tudo isso seja feito de maneira conveniente, em alto nível.Bem, não vivemos o primeiro dia. Um caso de uso simples. Cada mapeador contém internamente um objeto __table__, que é usado no núcleo. A seguir, veja - nós selecionamos o habitual, listamos as colunas, juntamos duas placas, indicamos a esquerda e a direita, indicamos por que condição a unimos, bem, para o gosto adicionamos uma ordem de compra. Além disso, alimentamos essa solicitação gerada na sessão e ela retorna iterável para nós, na qual os objetos semelhantes ao toque são indexados pelo nome da coluna e pelo número. O número corresponde à ordem em que estão listados na seleção.
Um caso de uso simples. Cada mapeador contém internamente um objeto __table__, que é usado no núcleo. A seguir, veja - nós selecionamos o habitual, listamos as colunas, juntamos duas placas, indicamos a esquerda e a direita, indicamos por que condição a unimos, bem, para o gosto adicionamos uma ordem de compra. Além disso, alimentamos essa solicitação gerada na sessão e ela retorna iterável para nós, na qual os objetos semelhantes ao toque são indexados pelo nome da coluna e pelo número. O número corresponde à ordem em que estão listados na seleção. Tornou-se muito melhor. No pior dos casos, o desempenho caiu para 2-4 segundos, a solicitação mais complexa e mais longa continha 14 comandos e o RPS 10-15. É sólido.
Tornou-se muito melhor. No pior dos casos, o desempenho caiu para 2-4 segundos, a solicitação mais complexa e mais longa continha 14 comandos e o RPS 10-15. É sólido. O que eu gostaria de dizer em conclusão.Não produza entidades onde elas não são necessárias - não estrague a sua onde estiver pronta.Use SQLA ORM - esta é uma ferramenta muito conveniente que permite rastrear eventos em alto nível, responder a vários eventos associados ao banco de dados, esconder todos os ouvidos da alquimia.Se tudo mais falhar, o desempenho não é suficiente - use o SQLA Core. Isso ainda é melhor do que usar SQL puro, porque fornece uma abstração relacional no banco de dados. Escapa automaticamente parâmetros, vincula corretamente, não importa qual banco de dados está nele - ele pode ser alterado e o Core suporta diferentes dialetos.
O que eu gostaria de dizer em conclusão.Não produza entidades onde elas não são necessárias - não estrague a sua onde estiver pronta.Use SQLA ORM - esta é uma ferramenta muito conveniente que permite rastrear eventos em alto nível, responder a vários eventos associados ao banco de dados, esconder todos os ouvidos da alquimia.Se tudo mais falhar, o desempenho não é suficiente - use o SQLA Core. Isso ainda é melhor do que usar SQL puro, porque fornece uma abstração relacional no banco de dados. Escapa automaticamente parâmetros, vincula corretamente, não importa qual banco de dados está nele - ele pode ser alterado e o Core suporta diferentes dialetos. É muito conveniente
É tudo o que eu queria lhe contar hoje.