Os sistemas distribuídos são usados quando há necessidade de dimensionamento horizontal para fornecer indicadores de desempenho aprimorados que um sistema dimensionado verticalmente não é capaz de fornecer dinheiro adequado.
Assim como a transição de um paradigma de thread único para multi-thread, a migração para um sistema distribuído requer um tipo de imersão e compreensão de como ele funciona no interior, no que você precisa prestar atenção.
Um dos problemas enfrentados por uma pessoa que deseja migrar um projeto para um sistema distribuído ou iniciar um projeto nele é qual produto escolher.
Nós, como uma empresa que “comeu um cachorro” no desenvolvimento de tais sistemas, ajudamos nossos clientes a tomar decisões equilibradas em relação aos sistemas de armazenamento distribuído. Também estamos lançando uma
série de seminários on-
line para um público mais amplo, focado em princípios básicos em um idioma simples, e quaisquer preferências alimentares específicas ajudam a mapear recursos significativos para facilitar a escolha.
Este artigo é baseado em nossos materiais sobre consistência e garantias ACID em sistemas distribuídos.
O que é e por que é necessário?
"
Consistência de dados (às vezes
consistência de dados ) é
consistência de dados entre si, integridade de dados e consistência interna." (
Wikipedia )
A consistência implica que, a qualquer momento, os aplicativos possam ter certeza de que estão trabalhando com a versão correta e tecnicamente relevante dos dados, e poderão confiar neles para tomar decisões.
Em sistemas distribuídos, garantir a consistência está se tornando mais difícil e mais caro, porque surgem uma série de novos desafios relacionados à troca de rede entre nós diferentes, à possibilidade de falha de nós individuais e - frequentemente - à falta de uma única memória que pode servir para verificação.
Por exemplo, se eu tiver um sistema de 4 nós: A, B, C e D, que serve transações bancárias, e os nós C e D estiverem separados de A e B (por exemplo, devido a problemas de rede), é bem possível que agora não esteja Eu tenho acesso a parte da transação. Como eu ajo nesta situação? Sistemas diferentes adotam abordagens diferentes.
No nível superior, existem duas direções principais que são expressas no teorema da PAC.
“
O teorema da CAP (também conhecido como
teorema de Brewer ) é uma afirmação heurística de que em qualquer implementação da computação distribuída é possível fornecer não mais que duas das três propriedades a seguir:
- consistência dos dados (consistência Eng.) - em todos os nós de computação em um determinado momento, os dados não se contradizem;
- disponibilidade (disponibilidade do Eng.) - qualquer solicitação para um sistema distribuído termina com uma resposta correta, mas sem garantia de que as respostas de todos os nós do sistema correspondam;
- tolerância de partição - dividir um sistema distribuído em várias seções isoladas não leva a uma resposta incorreta de cada seção. ”
(
Wikipedia )
Quando o teorema da CAP fala de consistência, implica uma definição bastante rigorosa, incluindo linearização de registros e leituras, e estipula apenas consistência ao escrever valores individuais. (
Martin Kleppman )
O teorema da CAP diz que, se queremos resistir a problemas de rede, em geral devemos escolher se devemos sacrificar: consistência ou acessibilidade. Existe também uma versão estendida desse teorema - PACELC (
Wikipedia ), que também fala sobre o fato de que, mesmo na ausência de problemas de rede, devemos escolher entre velocidade de resposta e consistência.
E, embora, à primeira vista, um nativo do mundo dos DBMSs clássicos, parece que a escolha é óbvia e a consistência é a coisa mais importante que temos, isso está longe de ser sempre o caso, que ilustra claramente o crescimento explosivo de vários DBMSs NoSQL que fizeram uma escolha diferente e Apesar disso, eles têm uma enorme base de usuários. O Apache Cassandra, com sua famosa consistência eventual, é um bom exemplo.
Tudo isso se deve ao fato de ser uma
escolha que implica sacrificar alguma coisa e nem sempre estamos prontos para sacrificá-la.
Freqüentemente, o problema de consistência em sistemas distribuídos é resolvido simplesmente abandonando essa consistência.
Mas é necessário e importante entender quando a rejeição dessa consistência é aceitável e quando é um requisito comercial crítico.
Por exemplo, se eu projetar um componente responsável por armazenar sessões do usuário, aqui, provavelmente, a consistência não é tão importante para mim e a perda de dados não será crítica se ocorrer apenas em casos problemáticos - muito raramente. O pior que acontecerá é que o usuário precisará fazer login e, para muitas empresas, isso terá pouco efeito no desempenho financeiro.
Se eu fizer análises no fluxo de dados a partir de sensores, em muitos casos, é totalmente não-crítico para mim perder alguns dados e obter uma redução de amostragem por um curto período de tempo, especialmente se finalmente os ver.
Mas se eu criar um sistema bancário, a consistência das transações em dinheiro é fundamental para os meus negócios. Se eu acumulei uma penalidade no empréstimo de um cliente devido ao fato de simplesmente não ver o pagamento pontual, embora ele estivesse no sistema, isso é muito, muito ruim. Assim como se o cliente pudesse retirar todo o dinheiro do meu cartão de crédito várias vezes, porque eu tinha problemas de rede no momento da transação e as informações de retirada não atingiram parte do meu cluster.
Se você fizer uma compra cara em uma loja on-line, não deseja que seu pedido seja esquecido, apesar do relatório de sucesso na página da web.
Mas se você optar pela consistência, sacrifica a acessibilidade. E muitas vezes isso é esperado, provavelmente você já se deparou com isso mais de uma vez.
É melhor que a cesta da loja online diga "tente mais tarde, o DBMS distribuído não está disponível" do que se relatar o sucesso e esquecer o pedido. É melhor obter uma recusa em uma transação devido à indisponibilidade dos serviços do banco do que uma batida no sucesso e depois nos procedimentos com o banco porque se esqueceu de que você pagou o empréstimo.
Finalmente, se observarmos o teorema do PACELC estendido, entendemos que, mesmo no caso de operação regular do sistema, escolhendo a consistência, podemos sacrificar latências baixas, obtendo um nível potencialmente mais baixo de desempenho máximo.
Portanto, respondendo à pergunta “por que isso é necessário?”: É necessário que seja essencial para sua tarefa ter dados atualizados e consistentes, e a alternativa trará a você perdas significativas maiores que a indisponibilidade temporária do serviço durante o período do incidente ou seu desempenho inferior.
Como fornecer isso?
Consequentemente, a primeira decisão que você precisa tomar é onde está no teorema da PAC, deseja consistência ou disponibilidade em caso de incidente.
Em seguida, você precisa entender em que nível deseja fazer alterações. Talvez você tenha registros atômicos suficientes que afetam um único objeto, pois o MongoDB era capaz e capaz (agora o amplia adicionalmente com suporte para transações completas). Deixe-me lembrá-lo de que o teorema do CAP não diz nada sobre a consistência das operações de gravação envolvendo vários objetos: o sistema pode muito bem ser CP (ou seja, preferir a consistência da acessibilidade) e, ao mesmo tempo, fornecer apenas registros únicos atômicos.
Se isso não for suficiente para você, começaremos a abordar o conceito de transações ACID distribuídas de pleno direito.
Observo que, mesmo quando entramos no admirável mundo novo de transações ACID distribuídas, muitas vezes precisamos sacrificar algo. Por exemplo, vários sistemas de armazenamento distribuído têm transações distribuídas, mas apenas dentro de uma única partição. Ou, por exemplo, o sistema pode não suportar a parte “I” no nível que você precisa, sem isolamento ou com um número insuficiente de níveis de isolamento.
Essas restrições costumavam ser feitas por algum motivo: para simplificar a implementação ou, por exemplo, para melhorar o desempenho ou para outra coisa. Eles são suficientes para um grande número de casos, portanto, você não deve considerá-los como contras por conta própria.
Você precisa entender se essas restrições são um problema para o seu cenário específico. Caso contrário, você tem mais opções e pode dar mais peso, por exemplo, aos indicadores de desempenho ou à capacidade do sistema de fornecer tolerância a desastres, etc. Finalmente, não devemos esquecer que em vários sistemas esses parâmetros podem ser ajustados até o ponto em que o sistema pode ser CP ou AP, dependendo da configuração.
Se nosso produto pretende ser CP, geralmente ele possui uma abordagem de quorum para seleção de dados ou nós dedicados que são os principais proprietários dos registros, todas as alterações de dados passam por eles e, no caso de problemas de rede, se esses nós principais não puderem fornecer dados. resposta, acredita-se que os dados, em princípio, não possam ser obtidos, ou arbitragem, quando um componente externo altamente acessível (por exemplo, o cluster ZooKeeper) pode dizer qual dos segmentos de cluster é o principal, contém a versão atual dos dados e pode atender com eficiência à solicitação s.
Por fim, se estivermos interessados não apenas no CP, mas no suporte a transações ACID distribuídas completas, geralmente uma única fonte de verdade é frequentemente usada, por exemplo, armazenamento em disco centralizado, onde nossos nós, de fato, atuam apenas como caches para ele, que podem ser desativados em tempo de confirmação ou o protocolo de confirmação multifásico é aplicado.
A primeira abordagem de disco único também simplifica a implementação, fornece baixas latências nas transações distribuídas, mas troca em troca de escalabilidade muito limitada em cargas com grandes volumes de gravação.
A segunda abordagem oferece muito mais liberdade no dimensionamento e, por sua vez, é dividida em protocolos de confirmação de duas fases (
Wikipedia ) e trifásicas (
Wikipedia ).
Considere uma confirmação em duas fases que use, por exemplo, Apache Ignite.
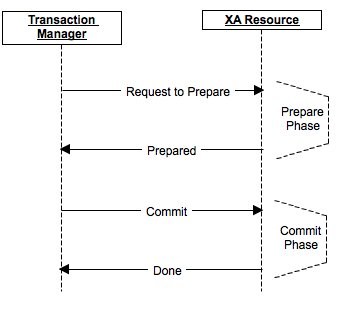

O procedimento de confirmação é dividido em 2 fases: preparar e confirmar.
Na fase de preparação, uma mensagem é preparada sobre a preparação para a confirmação, e cada participante, se necessário, bloqueia, executa todas as operações até e inclusive a confirmação real e envia a preparação para suas réplicas, se isso for assumido pelo produto. Se pelo menos um dos participantes respondeu com uma recusa por algum motivo ou se mostrou indisponível - os dados realmente não foram alterados, não houve confirmação. Os participantes revertem as alterações, liberam bloqueios e retornam ao seu estado original.
Na fase de consolidação, a execução real da consolidação é enviada aos nós do cluster. Se por algum motivo alguns dos nós estavam indisponíveis ou responderam com um erro, então os dados foram inseridos em seu redo-log (desde que a preparação foi bem-sucedida) e a confirmação, em qualquer caso, pode ser concluída pelo menos em um estado pendente.
Por fim, se o coordenador falhar, no estágio de preparação, o commit será cancelado, no estágio de commit, um novo coordenador poderá ser selecionado e, se todos os nós tiverem concluído o preparo, ele poderá verificar e garantir que o estágio de commit seja concluído.
Diferentes produtos têm seus próprios recursos de implementação e otimização. Assim, por exemplo, alguns produtos conseguem, em alguns casos, reduzir um commit de duas fases para um de 1 fase, ganhando significativamente em desempenho.
Conclusões
Conclusão chave: os sistemas de armazenamento distribuído são um mercado bastante desenvolvido e os produtos nele podem fornecer alta consistência dos dados.
Além disso, os produtos dessa categoria estão localizados em diferentes pontos da escala de consistência, desde produtos totalmente em AP sem nenhuma transacionalidade até produtos em CP que fornecem adicionalmente transações ACID de pleno direito. Alguns produtos podem ser configurados de uma maneira ou de outra.
Quando você escolhe o que precisa, precisa levar em conta as necessidades do seu caso e entender bem quais sacrifícios e compromissos está disposto a fazer, porque nada acontece de graça e, ao escolher um, você provavelmente recusará outra coisa.
Ao avaliar produtos desse lado, vale a pena prestar atenção ao seguinte:
- onde eles estão no teorema da PAC;
- Eles suportam transações ACID distribuídas?
- que restrições eles impõem às transações distribuídas (por exemplo, apenas dentro de uma única partição, etc.);
- Conveniência e eficiência do uso de transações distribuídas, sua integração com outros componentes do produto.