[parte 2 de 2]
[parte 1 de 2]

Como fizemos
Decidimos mudar para o GCP para melhorar o desempenho do aplicativo - enquanto aumentamos a escala, mas sem custos significativos. Todo o processo levou mais de 2 meses. Para resolver esse problema, formamos um grupo especial de engenheiros.
Nesta publicação, falaremos sobre a abordagem escolhida e sua implementação, bem como sobre como conseguimos alcançar o objetivo principal - realizar esse processo da maneira mais tranquila possível e transferir toda a infraestrutura para o Google Cloud Platform, sem comprometer a qualidade do serviço ao usuário.
Planejamento
- Uma lista de verificação detalhada foi preparada identificando cada etapa possível. Um fluxograma foi criado para descrever a sequência.
- Foi desenvolvido um plano de redefinição que, se houver, poderíamos usar.
Algumas sessões de brainstorming - e identificamos a abordagem mais compreensível e simples para implementar o esquema ativo-ativo. Consiste no fato de que um pequeno conjunto de usuários está hospedado em uma nuvem e o restante em outra. No entanto, essa abordagem causou problemas, especialmente no lado do cliente (relacionados ao gerenciamento de DNS) e levou a atrasos na replicação do banco de dados. Por isso, era quase impossível implementá-lo com segurança. O método óbvio não forneceu a solução necessária e tivemos que desenvolver uma estratégia especializada.
Com base no diagrama de dependência e nos requisitos de segurança operacional, dividimos os serviços de infraestrutura em 9 módulos.
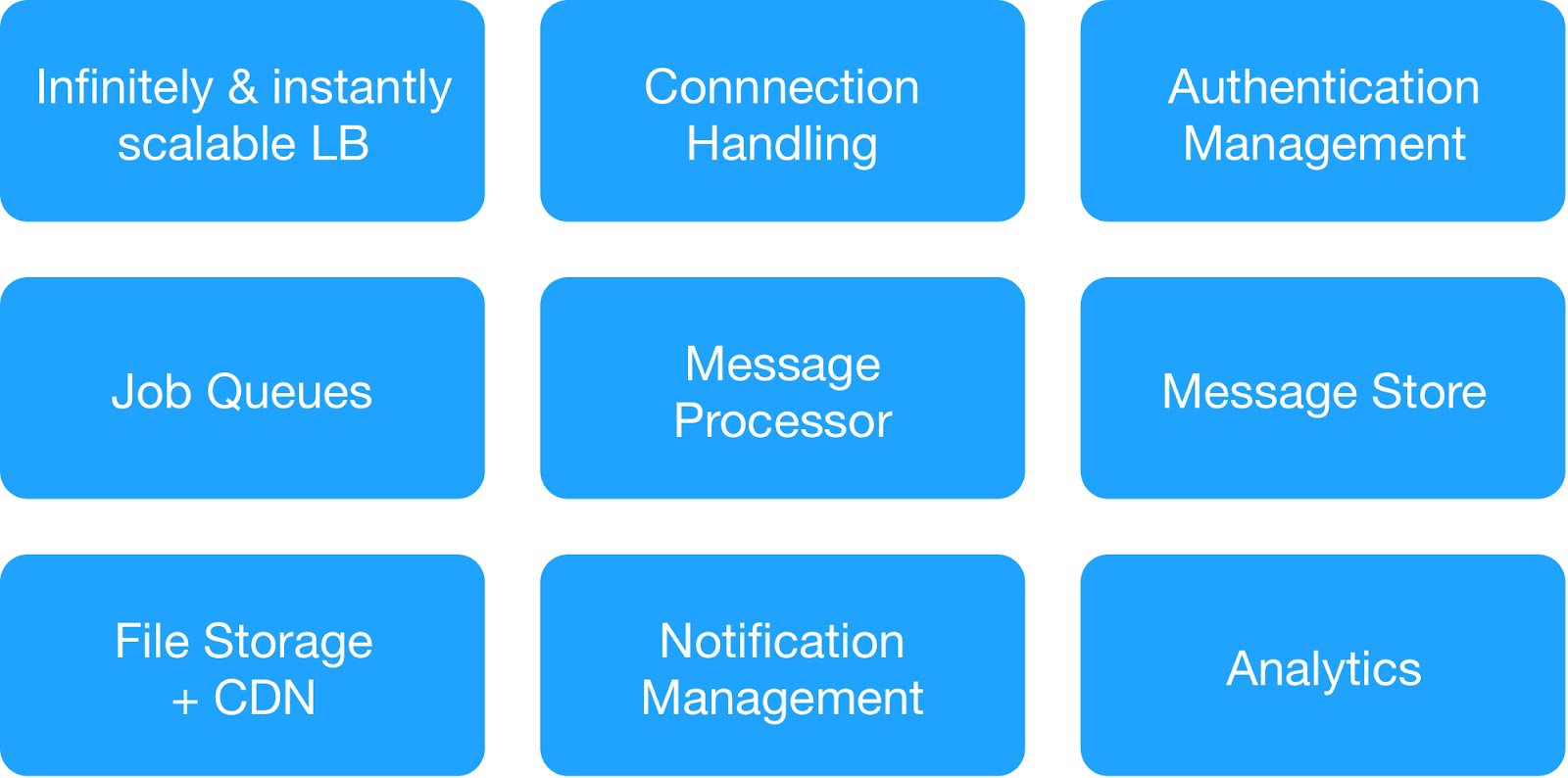
(Módulos básicos para implantação da infraestrutura de hospedagem)
Cada grupo de infraestrutura gerenciava serviços internos e externos comuns.
Service Serviço de mensagens de infraestrutura : MQTT, HTTPs, Thrift, servidor Gunicorn, módulo de fila, cliente Async, servidor Jetty, cluster Kafka.
Warehouse Serviços de Data Warehouse : cluster distribuído MongoDB, Redis, Cassandra, Hbase, MySQL e MongoDB.
Service Serviço de análise de infraestrutura : cluster Kafka, cluster de data warehouse (HDFS, HIVE).
Preparando-se para um dia significativo:
✓ Um plano detalhado para mudar para o GCP para cada serviço: sequência, data warehouse, plano de redefinição.
✓ Interações de rede entre projetos (nuvem privada virtual compartilhada VPC [XPN]) no GCP para isolar diferentes partes da infraestrutura, otimizar o gerenciamento, melhorar a segurança e a conectividade.
✓ Vários túneis VPN entre o GCP e a nuvem virtual privada (VPC) em execução para simplificar a transferência de grandes quantidades de dados pela rede durante a replicação, bem como para a possível implantação subsequente de um sistema paralelo.
✓ Automatize a instalação e configuração de toda a pilha usando o sistema Chef.
✓ Scripts e ferramentas de automação para implantação, monitoramento, registro, etc.
✓ Configure todas as sub-redes necessárias e regras de firewall gerenciado para o fluxo do sistema.
✓ Replicação em vários data centers (Multi-DC) para todos os sistemas de armazenamento.
✓ Configurar balanceadores de carga (GLB / ILB) e grupos de instâncias gerenciadas (MIG).
✓ Scripts e código para transferir o contêiner de armazenamento de objetos para o GCP Cloud Storage com pontos de verificação.
Em breve, atendemos a todos os pré-requisitos necessários e preparamos uma lista de verificação de elementos para mover a infraestrutura para a plataforma GCP. Após inúmeras discussões, além de considerar o número de serviços e seus diagramas de dependência, decidimos transferir a infraestrutura de nuvem para o GCP em três noites para cobrir todos os serviços de armazenamento de dados e do servidor.
Transição
Estratégia de transferência do balanceador de carga:
Substituímos o cluster gerenciado HAProxy usado anteriormente por um balanceador de carga global para processar diariamente dezenas de milhões de conexões de usuários ativos.
⊹ Etapa 1:
- Os MIGs são criados com regras de encaminhamento de pacotes para encaminhar todo o tráfego para os endereços IP do MQTT na nuvem existente.
- Um balanceador SSL e Proxy TCP foi criado com o MIG como parte do servidor.
- Para o MIG, o HAProxy é iniciado com os servidores MQTT como parte do servidor.
- No DNS, uma política de roteamento baseada em peso adicionou um endereço IP GLB externo.
As conexões do usuário são implantadas gradualmente enquanto acompanha o desempenho delas.
2 Etapa 2: transição de marco, comece a implantar serviços no GCP.
⊹ Etapa 3: Na etapa final da transição, todos os serviços são transferidos para o GCP.
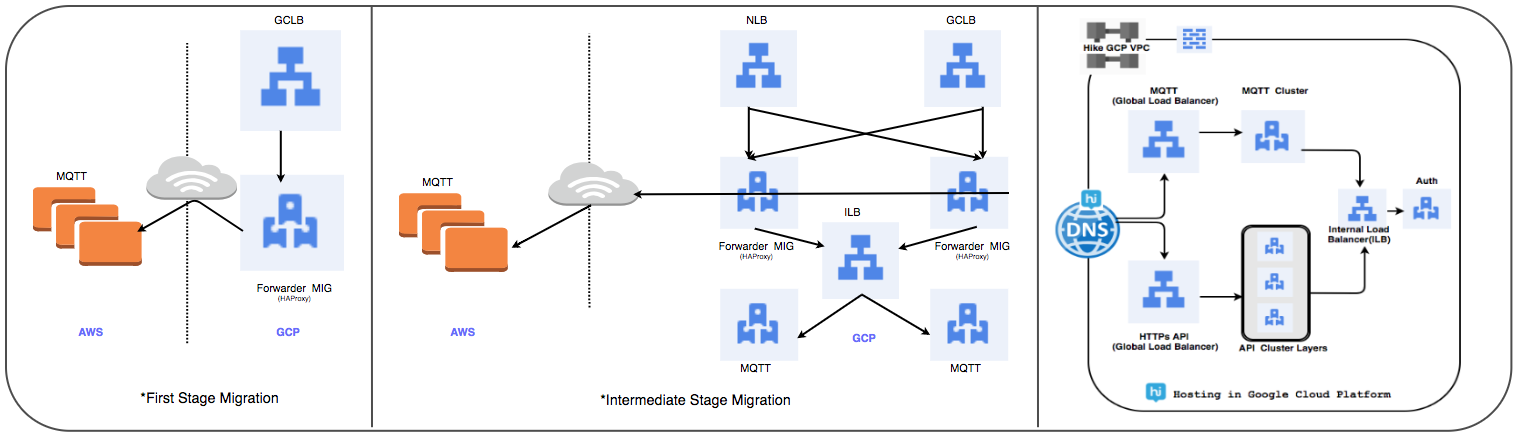
(Estágios de transferência do balanceador de carga)
Nesta fase, tudo funcionou como esperado. Logo, chegou a hora de implantar vários serviços HTTP internos no GCP com roteamento - considerando o peso dos coeficientes. Monitoramos de perto todos os indicadores. Quando começamos a aumentar gradualmente o tráfego, no dia anterior à transição planejada, os atrasos na interação da VPC via VPN (atrasos de 40 ms a 100 ms foram registrados, embora anteriormente fossem inferiores a 10 ms) aumentaram.
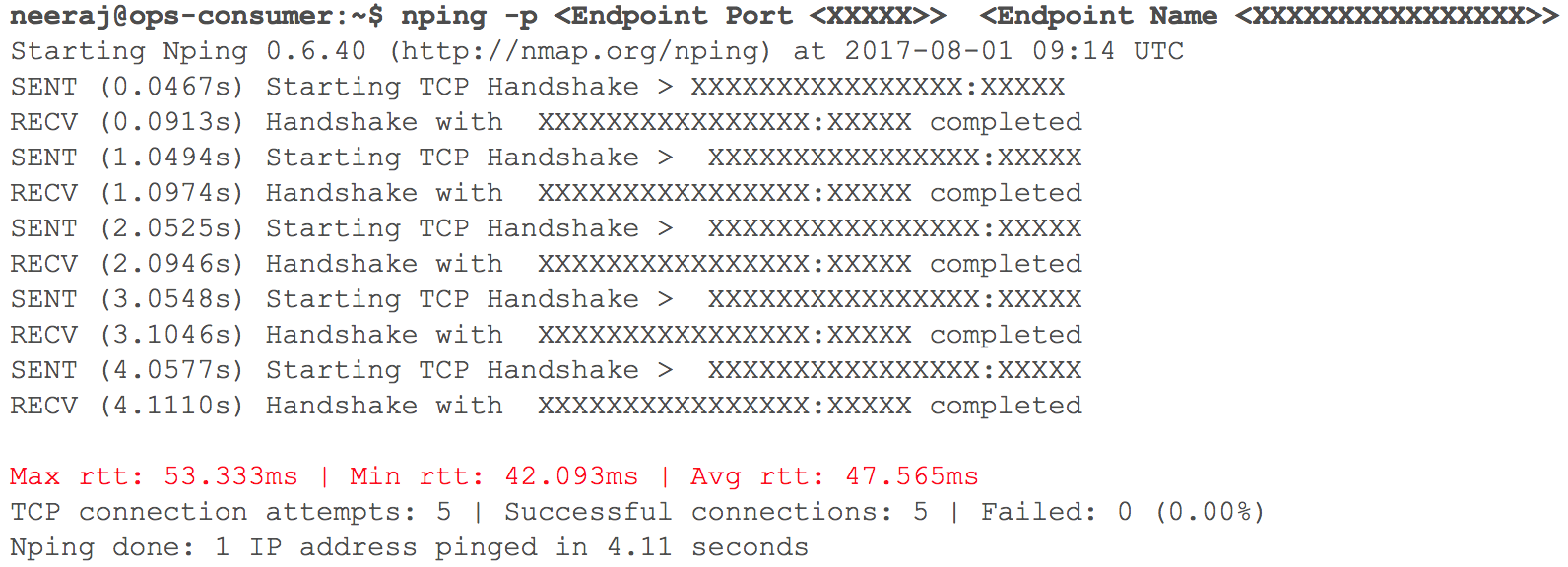
(Instantâneo da verificação do atraso da rede quando duas VPCs interagem)
O monitoramento mostrou claramente: algo estava errado com os dois canais de rede na nuvem usando túneis VPN. Mesmo a taxa de transferência do túnel VPN não atingiu a marca ideal. Essa situação começou a afetar negativamente alguns de nossos serviços de usuário. Retornamos imediatamente todos os serviços HTTP migrados anteriormente para seu estado original. Entramos em contato com as equipes de suporte dos serviços de nuvem e TAM, fornecemos os dados iniciais necessários e começamos a entender por que os atrasos estavam aumentando. Os especialistas em suporte chegaram à conclusão de que foi alcançada a largura de banda máxima da rede no canal em nuvem entre dois provedores de serviços em nuvem. Daí o crescimento de atrasos na rede durante a transferência de sistemas internos.
Este incidente forçado a suspender a transição para a nuvem. Os provedores de serviços em nuvem não conseguiram dobrar a largura de banda com rapidez suficiente. Portanto, voltamos ao estágio de planejamento e revisamos a estratégia. Decidimos transferir a infraestrutura de nuvem para o GCP em uma noite em vez de três e incluímos no plano todos os serviços da parte do servidor e armazenamento de dados. Quando a hora “X” chegou, tudo correu bem: as cargas de trabalho foram transferidas com sucesso para o Google Cloud despercebidas pelos nossos usuários!
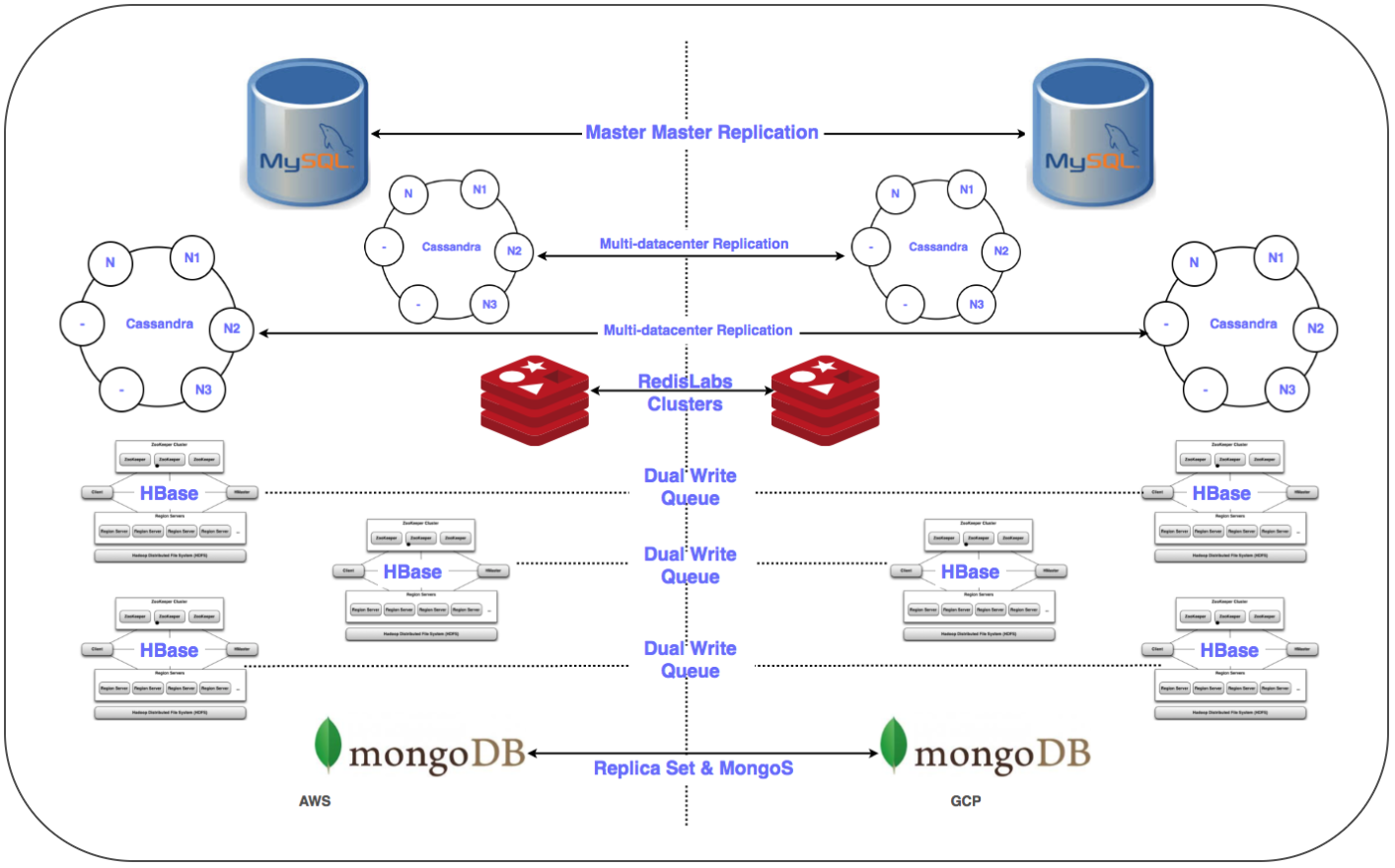
Estratégia de migração de banco de dados:
Era necessário transferir mais de 50 pontos de extremidade do banco de dados para um DBMS relacional, armazenamento na memória, bem como NoSQL e clusters distribuídos e escalonáveis com baixa latência. Colocamos réplicas de todos os bancos de dados no GCP. Isso foi feito para todas as implantações, exceto o HBase.
Replic Replicação mestre-escravo: implementada para clusters MySQL, Redis, MongoDB e MongoS.
Replicação Multi Multi-DC: implementada para clusters Cassandra.
⊹ Clusters duplos: um cluster paralelo foi configurado para Gbase no GCP. Os dados existentes foram migrados, a entrada dupla foi configurada de acordo com a estratégia de manter a consistência dos dados nos dois clusters.
No caso do HBase, o problema estava sendo estabelecido com o Ambari. Encontramos algumas dificuldades ao colocar clusters em vários datacenters, por exemplo, houve problemas com o DNS, um script de reconhecimento de rack etc.
As etapas finais (após mover os servidores) incluíram a movimentação das réplicas para os servidores principais e o desligamento dos bancos de dados antigos. Conforme planejado, determinando a prioridade da transferência do banco de dados, usamos o Zookeeper para a configuração necessária dos clusters de aplicativos.
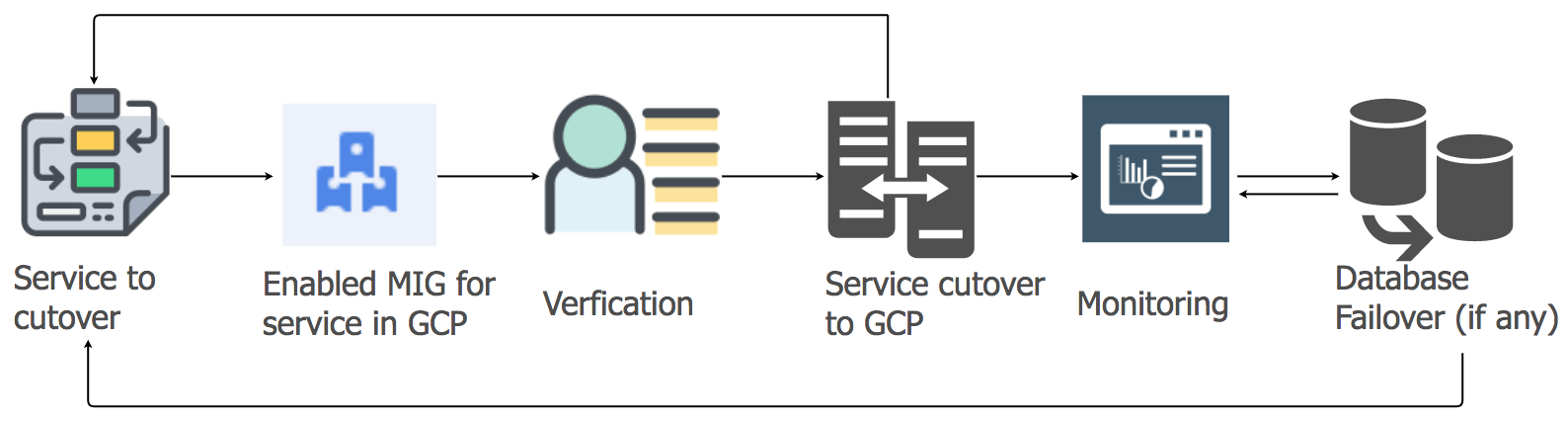
Estratégia de migração de serviços de aplicativos
Para transferir as cargas de trabalho dos serviços de aplicativos da hospedagem atual para a nuvem GCP, usamos a abordagem de elevação e mudança. Para cada serviço de aplicativo, criamos um grupo de instâncias gerenciadas (MIG) com dimensionamento automático.
De acordo com um plano detalhado, começamos a migrar serviços para o GCP, levando em consideração a sequência e as dependências dos data warehouses. Todos os serviços da pilha de mensagens foram migrados para o GCP sem nenhum tempo de inatividade. Sim, houve algumas pequenas falhas, mas lidamos com elas imediatamente.
De manhã, à medida que a atividade do usuário aumentava, seguimos cuidadosamente todos os painéis e indicadores para identificar rapidamente os problemas. Algumas dificuldades realmente surgiram, mas conseguimos eliminá-las rapidamente. Um dos problemas ocorreu devido às limitações do balanceador de carga interno (ILB), que pode lidar com não mais de 20.000 conexões simultâneas. E precisávamos de 8 vezes mais! Portanto, adicionamos ILBs adicionais à nossa camada de gerenciamento de conexões.
Nas primeiras horas de pico de carga após a transição, controlamos todos os parâmetros com cuidado, pois toda a carga da pilha de mensagens foi transferida para o GCP. Houve algumas pequenas falhas com as quais lidamos muito rapidamente. Ao migrar outros serviços, adotamos a mesma abordagem.
Migração de armazenamento de objetos:
Usamos o serviço de armazenamento de objetos principalmente de três maneiras.
⊹ Armazenamento de arquivos de mídia enviados para um bate-papo pessoal ou em grupo. O período de retenção é determinado pela política de gerenciamento do ciclo de vida.
⊹ Armazenamento de imagens e miniaturas do perfil do usuário.
⊹ Armazenamento de arquivos de mídia das seções "Histórico" e "Linha do tempo" e as miniaturas correspondentes.
Usamos a ferramenta de transferência de armazenamento do Google para copiar objetos antigos do S3 para o GCS. Também usamos um MIG personalizado baseado em Kafka para transferir objetos do S3 para o GCS quando uma lógica especial era necessária.
A transição do S3 para o GCS incluiu as seguintes etapas:
● Para o primeiro caso de uso do armazenamento de objetos, começamos a gravar novos dados no S3 e no GCS e, após a expiração, começamos a ler os dados do GCS usando a lógica no lado do aplicativo. A transferência de dados antigos não faz sentido e essa abordagem é econômica.
● No segundo e terceiro casos de uso, começamos a gravar novos objetos no GCS e alteramos o caminho para a leitura de dados, para que a pesquisa seja realizada pela primeira vez no GCS e somente então, se o objeto não for encontrado, no S3.
Demorou meses para planejar, verificar a exatidão do conceito, preparar e prototipar, mas então decidimos a transição e a implementamos muito rapidamente. Avaliamos os riscos e percebemos que a migração rápida é preferível e quase imperceptível.
Esse projeto em larga escala nos ajudou a ganhar uma posição forte e aumentar a produtividade da equipe em muitas áreas, já que a maioria das operações manuais de gerenciamento da infraestrutura em nuvem está no passado.
● Quanto aos usuários, agora recebemos tudo o que é necessário para garantir a mais alta qualidade de seus serviços. O tempo de inatividade quase desapareceu e os novos recursos estão sendo implementados mais rapidamente.
● Nossa equipe gasta menos tempo em tarefas de manutenção e pode se concentrar em projetos de automação e na criação de novas ferramentas.
● Tivemos acesso a um conjunto de ferramentas sem precedentes para trabalhar com big data, além de funcionalidades prontas para aprendizado e análise de máquinas. Veja detalhes aqui.
● O compromisso do Google Cloud em trabalhar com o projeto de código aberto Kubernetes também está alinhado com o nosso plano de desenvolvimento para este ano.