Em um dos artigos anteriores, falei sobre como você pode criar um executor de programa para uma máquina de pilha virtual usando abordagens de programação funcional e orientada a linguagem. A estrutura matemática da linguagem sugeriu a estrutura básica para a implementação de seu tradutor, com base no conceito de semigrupos e monoides. Essa abordagem me permitiu criar uma implementação bonita e expansível e quebrar os aplausos, mas a primeira pergunta da platéia me fez sair da tribuna e entrar no Emacs novamente.
Realizei um teste simples e certifiquei-me de que, em tarefas simples que usam apenas a pilha, a máquina virtual funcione de maneira inteligente e, ao usar a "memória" - uma matriz com acesso aleatório - grandes problemas começam. Sobre como conseguimos resolvê-los sem alterar os princípios básicos da arquitetura do programa e alcançar uma aceleração mil vezes maior do programa, e será discutido neste artigo.
Haskell é uma linguagem peculiar com um nicho especial. O principal objetivo de sua criação e desenvolvimento foi a necessidade da lingua franca expressar e testar idéias de programação funcional. Isso justifica suas características mais marcantes: preguiça, extrema pureza, ênfase nos tipos e manipulações com eles. Não foi projetado para o desenvolvimento cotidiano, nem para programação industrial, nem para uso generalizado. O fato de ser realmente usado para criar projetos de larga escala no setor de redes e no processamento de dados é a boa vontade dos desenvolvedores, prova de conceito, se você preferir. Mas até agora, o produto mais importante, amplamente utilizado e surpreendentemente poderoso escrito em Haskell é ... o compilador ghc. E isso é completamente justificado do ponto de vista de seu objetivo - ser uma ferramenta para pesquisas no campo da ciência da computação. O princípio proclamado por Simon Payton-Johnson: "Evite o sucesso a todo custo" é necessário para que o idioma continue sendo um instrumento. Haskell é como uma câmara estéril no laboratório de um centro de pesquisa que desenvolve tecnologias semicondutoras ou nanomateriais. É terrivelmente inconveniente trabalhar, e para a prática cotidiana também restringe a liberdade de ação, mas sem esses inconvenientes, sem aderência intransigente às restrições, não será possível observar e estudar os efeitos sutis que mais tarde se tornarão a base dos desenvolvimentos industriais. Ao mesmo tempo, na indústria, a esterilidade será necessária apenas no volume mais necessário, e os resultados dessas experiências aparecerão em nossos bolsos na forma de gadgets. Estudamos estrelas e galáxias não porque esperamos receber benefícios diretos deles, mas porque, na escala desses objetos impraticáveis, efeitos quânticos e relativísticos se tornam observáveis e estudados, tanto que, mais tarde, podemos usar esse conhecimento para desenvolver algo muito utilitário. Portanto, Haskell, com suas linhas "erradas", preguiça impraticável de cálculos, rigidez de alguns algoritmos de inferência de tipos, com uma curva de entrada extremamente íngreme, finalmente não permite que você crie facilmente um aplicativo inteligente no joelho ou em um sistema operacional. No entanto, lentes, mônadas, análise combinatória, uso generalizado de monóides, métodos de comprovação automática de teoremas, gerenciadores de pacotes funcionais declarativos, tipos lineares e dependentes estão se aproximando do mundo prático. Ele encontra aplicação em condições menos estéreis nos idiomas Python, Scala, Kotlin, F #, Rust e muitos outros. Mas eu não usaria nenhuma dessas linguagens maravilhosas para ensinar os princípios da programação funcional: levaria o aluno ao laboratório, mostraria como ele funciona em exemplos claros e claros e, então, você poderá ver esses princípios em ação na fábrica. uma máquina grande e incompreensível, mas muito rápida. Evitar o sucesso a todo custo é proteção contra tentativas de colocar uma cafeteira em um microscópio eletrônico, a fim de popularizá-lo. E nas competições cujo idioma é mais legal, Haskell estará sempre fora das indicações usuais.
No entanto, a pessoa é fraca e um demônio também vive em mim, o que me faz querer comparar, avaliar e defender "minha língua favorita" na frente dos outros. Então, depois de escrever uma implementação elegante de uma máquina empilhada, com base em uma composição monoidal, com o único objetivo de verificar se essa ideia funciona para mim, fiquei imediatamente chateado por perceber que a implementação funcionava de maneira brilhante, mas terrivelmente ineficiente! É como se eu realmente fosse usá-lo para tarefas sérias ou vender minha máquina empilhada no mesmo mercado em que as máquinas virtuais Python ou Java são oferecidas. Mas, caramba, o artigo sobre o leitão com o qual toda essa conversa começou deu números tão saborosos: centenas de milissegundos para o leitão, segundos para Python ... e meu lindo monóide não consegue lidar com a mesma tarefa em uma hora! Eu tenho que ter sucesso! Meu microscópio preparará café expresso como uma máquina de café no corredor do instituto! O Palácio de Cristal pode ser disperso e lançado no espaço!
Mas o que você está pronto para desistir, o anjo matemático me pergunta? A pureza e transparência da arquitetura do palácio? A flexibilidade e extensibilidade que os homomorfismos dos programas para outras soluções oferecem? O demônio e o anjo são teimosos, e o sábio taoísta, a quem eu também me permito viver, propôs seguir o caminho que combina com ambos e segui-lo o maior tempo possível. No entanto, não com o objetivo de identificar o vencedor, mas de conhecer o caminho em si, descobrir até onde ele leva e ganhar novas experiências. E então eu conhecia a triste tristeza e a alegria da otimização.
Antes de começarmos, acrescentamos que as comparações de idiomas em termos de eficácia são inúteis. Você precisa comparar tradutores (intérpretes ou compiladores) ou o desempenho de um programador que usa o idioma. No final, é fácil refutar a afirmação de que os programas C são os mais rápidos escrevendo um intérprete C completo no BASIC, por exemplo. Portanto, não estamos comparando Haskell e javascript, mas o desempenho de programas executados por um tradutor compilado pelo ghc e programas executados, digamos, em um navegador específico. Toda terminologia suína vem de um artigo inspirador sobre máquinas empilhadas. Todo o código Haskell que acompanha o artigo pode ser estudado no repositório .
Saímos da zona de conforto
A posição inicial será a implementação de uma máquina de empilhamento monoidal na forma de EDSL - uma pequena linguagem simples que permite combinar duas dúzias de primitivas para renderizar programas para uma máquina de empilhamento virtual. Assim que ele entrou no segundo artigo, damos a ele o nome monopig . É baseado no fato de que os idiomas para máquinas empilhadas formam um monóide com uma operação de concatenação e uma operação vazia como uma unidade. Consequentemente, ele próprio foi construído na forma de uma transformação monóide do estado da máquina. O estado inclui uma pilha, memória na forma de um vetor (uma estrutura que fornece acesso aleatório a elementos), um sinalizador de parada de emergência e uma bateria monoidal para acumular informações de depuração. Toda essa estrutura é transmitida ao longo de uma cadeia de endomorfismos de operação para operação, realizando um processo computacional. Uma estrutura isomórfica de códigos de programa foi construída a partir da estrutura que os programas formam e, a partir dele, homomorfismos em outras estruturas úteis que representam os requisitos do programa em termos de número de argumentos e memória. O estágio final da construção foi a criação de monoides de transformação na categoria Claysley, que permitem imergir os cálculos em uma mônada arbitrária. Portanto, a máquina obteve os recursos de entrada-saída e cálculos ambíguos. Vamos começar com esta implementação. O código dela pode ser encontrado aqui .
Testaremos a eficácia do programa na implementação ingênua da peneira de Eratóstenes, que enche a memória (matriz) de zeros e uns, denotando números primos por zero. Fornecemos o código processual do algoritmo em javascript :
var memSize = 65536; var arr = []; for (var i = 0; i < memSize; i++) arr.push(0); function sieve() { var n = 2; while (n*n < memSize) { if (!arr[n]) { var k = n; while (k < memSize) { k+=n; arr[k] = 1; } } n++; } }
O algoritmo é imediatamente ligeiramente otimizado. Elimina a má caminhada através das células de memória já preenchidas. Meu anjo matemático não concordou com uma versão realmente ingênua de um exemplo no projeto PorosenokVM , pois essa otimização custa apenas cinco instruções da linguagem da pilha. Veja como o algoritmo se traduz em monopig :
sieve = push 2 <> while (dup <> dup <> mul <> push memSize <> lt) (dup <> get <> branch mempty fill <> inc) <> pop fill = dup <> dup <> add <> while (dup <> push memSize <> lt) (dup <> push 1 <> swap <> put <> exch <> add) <> pop
E aqui está como você pode escrever uma implementação equivalente desse algoritmo no Haskell idiomático, usando os mesmos tipos que no monopig :
sieve' :: Int -> Vector Int -> Vector Int sieve' km | k*k < memSize = sieve' (k+1) $ if m ! k == 0 then fill' k (2*k) m else m | otherwise = m fill' :: Int -> Int -> Vector Int -> Vector Int fill' knm | n < memSize = fill' k (n+k) $ m // [(n,1)] | otherwise = m
Ele usa o tipo Data.Vector e ferramentas para trabalhar com ele, que não são muito comuns para o trabalho diário em Haskell. Expressão m ! k m ! k retorna o k ésimo elemento do vetor me m // [(n,1)] - define o elemento com o número n como 1. Estou escrevendo isso aqui porque precisei pedir ajuda a eles, mesmo trabalhando em Haskell quase todo dia. O fato é que estruturas com acesso aleatório em uma implementação funcional são ineficientes e, por esse motivo, não são amadas.
De acordo com as condições de competição especificadas no artigo sobre o leitão, o algoritmo é executado 100 vezes. E, para se livrar de um computador específico, vamos comparar as velocidades de execução desses três programas, referindo-os ao desempenho do programa javascript que foi executado no Chrome.
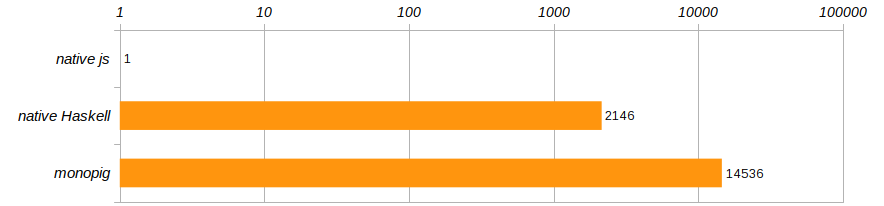
Horror horror !!! O monopig não apenas monopig velocidade de Deus, como também a versão nativa não é muito melhor! Haskell, é claro, é legal, mas não tanto quanto inferior a um programa em execução em um navegador ?! Como os treinadores nos ensinam, você não pode viver assim, é hora de sair da zona de conforto que Haskell nos fornece!
Superar a preguiça
Vamos acertar. Para fazer isso, compile um programa no monopig com o sinalizador -rtsopts para -rtsopts estatísticas -rtsopts e ver o que precisamos para executar a peneira de Eratóstenes uma vez:
$ ghc -O -rtsopts ./Monopig4.hs [1 of 1] Compiling Main ( Monopig4.hs, Monopig4.o ) Linking Monopig4 ... $ ./Monopig4 -RTS -sstderr "Ok" 68,243,040,608 bytes allocated in the heap 6,471,530,040 bytes copied during GC 2,950,952 bytes maximum residency (30667 sample(s)) 42,264 bytes maximum slop 15 MB total memory in use (7 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 99408 colls, 0 par 2.758s 2.718s 0.0000s 0.0015s Gen 1 30667 colls, 0 par 57.654s 57.777s 0.0019s 0.0133s INIT time 0.000s ( 0.000s elapsed) MUT time 29.008s ( 29.111s elapsed) GC time 60.411s ( 60.495s elapsed) <-- ! EXIT time 0.000s ( 0.000s elapsed) Total time 89.423s ( 89.607s elapsed) %GC time 67.6% (67.5% elapsed) Alloc rate 2,352,591,525 bytes per MUT second Productivity 32.4% of total user, 32.4% of total elapsed
A última linha nos diz que o programa estava envolvido em computação produtiva apenas um terço do tempo. Durante o resto do tempo, o coletor de lixo ficou sem memória e foi limpo para cálculos preguiçosos. Quantas vezes nos disseram na infância que a preguiça não é boa! Aqui, a principal característica de Haskell fez um desserviço, tentando criar vários bilhões de vetores adiados e transformações de pilha.
Um anjo matemático, neste momento, levanta o dedo e fala alegremente sobre o fato de que, desde os tempos da Igreja de Alonzo, há um teorema que afirma que a estratégia de cálculo não afeta o resultado, o que significa que somos livres para escolhê-lo por razões de eficiência. Alterar os cálculos para estrito não é nada difícil - coloque um sinal ! na declaração do tipo de pilha e memória e, assim, tornar esses campos estritos.
data VM a = VM { stack :: !Stack , status :: Maybe String , memory :: !Memory , journal :: !a }
Não alteraremos mais nada e verificaremos imediatamente o resultado:
$ ./Monopig41 +RTS -sstderr "Ok" 68,244,819,008 bytes allocated in the heap 7,386,896 bytes copied during GC 528,088 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 16 MB total memory in use (14 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 129923 colls, 0 par 0.666s 0.654s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.001s 0.001s 0.0006s 0.0007s INIT time 0.000s ( 0.000s elapsed) MUT time 13.029s ( 13.048s elapsed) GC time 0.667s ( 0.655s elapsed) EXIT time 0.001s ( 0.001s elapsed) Total time 13.700s ( 13.704s elapsed) %GC time 4.9% (4.8% elapsed) Alloc rate 5,238,049,412 bytes per MUT second Productivity 95.1% of total user, 95.1% of total elapsed
A produtividade cresceu significativamente. Os custos totais de memória ainda permaneceram impressionantes devido à imutabilidade dos dados, mas o mais importante é que agora que limitamos a preguiça dos dados, o coletor de lixo tem a oportunidade de ser preguiçoso, apenas 5% do trabalho permanece nele. Digite uma nova entrada na classificação.

Bem, cálculos rigorosos nos aproximaram da velocidade do código Haskell nativo, que vergonhosamente diminui sem nenhuma máquina virtual. Isso significa que a sobrecarga do uso de um vetor imutável excede significativamente o custo de manutenção de uma máquina empilhada. E isso significa que é hora de dizer adeus à imutabilidade da memória.
Deixar Mudanças na Vida
O tipo Data.Vector bom, mas, usando-o, passamos muito tempo copiando, em nome da preservação da pureza do processo de computação. Substituindo-o Data.Vector.Unpacked tipo Data.Vector.Unpacked pelo menos economizamos no empacotamento da estrutura, mas isso não altera fundamentalmente a imagem. A solução correta seria remover a memória do estado da máquina e fornecer acesso ao vetor externo usando a categoria Kleisley. Ao mesmo tempo, junto com vetores puros, você pode usar os chamados vetores mutáveis (mutáveis) Data.Vector.Mutable .
Vamos conectar os módulos apropriados e pensar em como lidar com dados mutáveis em um programa funcional limpo.
import Control.Monad.Primitive import qualified Data.Vector.Unboxed as V import qualified Data.Vector.Unboxed.Mutable as M
Esses tipos sujos devem ser isolados do público puro. Eles estão contidos nas mônadas da classe PrimMonad (elas incluem ST ou IO ), onde programas limpos inserem cuidadosamente instruções para ações escritas em uma linguagem funcional cristalina em pergaminho precioso. Assim, o comportamento desses animais impuros é determinado por cenários estritamente ortodoxos e não é perigoso. Nem todos os programas de nossa máquina usam memória; portanto, não há necessidade de condenar toda a arquitetura à imersão na mônada de IO S. Juntamente com um subconjunto limpo da linguagem monopig criaremos quatro instruções que fornecem acesso à memória, e somente elas terão acesso ao território perigoso.
O tipo de máquina limpa está ficando mais curto:
data VM a = VM { stack :: !Stack , status :: Maybe String , journal :: !a }
Os projetistas de programas e os próprios programas dificilmente perceberão essa alteração, mas seus tipos mudarão. Além disso, faz sentido definir vários tipos de sinônimos para simplificar as assinaturas.
type Memory m = M.MVector (PrimState m) Int type Logger ma = Memory m -> Code -> VM a -> m (VM a) type Program' ma = Logger ma -> Memory m -> Program ma
Os construtores terão outro argumento representando o acesso à memória. Os executores mudarão significativamente, especialmente aqueles que mantêm um log de cálculo, porque agora precisam solicitar o estado do vetor variável. O código completo pode ser visto e estudado no repositório, mas aqui darei o mais interessante: a implementação dos componentes básicos para trabalhar com a memória para mostrar como isso é feito.
geti :: PrimMonad m => Int -> Program' ma geti i = programM (GETI i) $ \mem -> \s -> if (0 <= i && i < memSize) then \vm -> do x <- M.unsafeRead mem i setStack (x:s) vm else err "index out of range" puti :: PrimMonad m => Int -> Program' ma puti i = programM (PUTI i) $ \mem -> \case (x:s) -> if (0 <= i && i < memSize) then \vm -> do M.unsafeWrite mem ix setStack s vm else err "index out of range" _ -> err "expected an element" get :: PrimMonad m => Program' ma get = programM (GET) $ \m -> \case (i:s) -> \vm -> do x <- M.read mi setStack (x:s) vm _ -> err "expected an element" put :: PrimMonad m => Program' ma put = programM (PUT) $ \m -> \case (i:x:s) -> \vm -> M.write mix >> setStack s vm _ -> err "expected two elemets"
O daemon otimizador imediatamente se ofereceu para economizar um pouco mais na verificação dos valores de índice permitidos na memória, porque para os geti puti e geti índices são conhecidos no estágio de criação do programa e os valores incorretos podem ser eliminados antecipadamente. Os índices definidos dinamicamente para comandos put e get não garantem segurança, e o anjo matemático não permitiu que chamadas perigosas fossem feitas a eles.
Todo esse barulho de colocar a memória em um argumento separado parece complicado. Mas mostra muito claramente os dados a serem alterados por seu local - eles devem estar fora . Lembro que estamos tentando levar um entregador de pizza a um laboratório estéril. As funções puras sabem o que fazer com elas, mas esses objetos nunca se tornarão cidadãos de primeira classe, e não vale a pena preparar pizza no laboratório.
Vamos verificar o que compramos com essas alterações:
$ ./Monopig5 +RTS -sstderr "Ok" 9,169,192,928 bytes allocated in the heap 2,006,680 bytes copied during GC 529,608 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 2 MB total memory in use (0 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 17693 colls, 0 par 0.094s 0.093s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.000s 0.000s 0.0002s 0.0003s INIT time 0.000s ( 0.000s elapsed) MUT time 7.228s ( 7.232s elapsed) GC time 0.094s ( 0.093s elapsed) EXIT time 0.000s ( 0.000s elapsed) Total time 7.325s ( 7.326s elapsed) %GC time 1.3% (1.3% elapsed) Alloc rate 1,268,570,828 bytes per MUT second Productivity 98.7% of total user, 98.7% of total elapsed
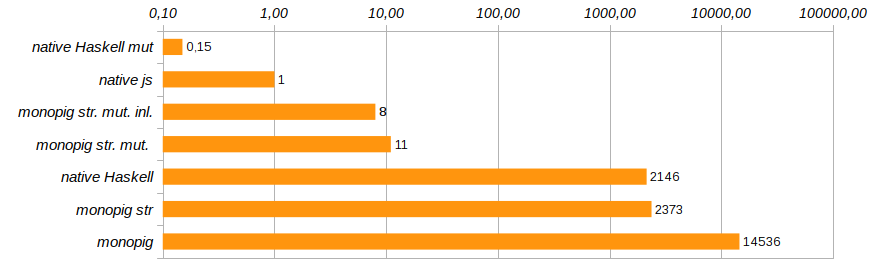
Isso já é progresso! O uso da memória foi reduzido oito vezes, a velocidade de execução do programa aumentou 180 vezes e o coletor de lixo permaneceu quase completamente sem trabalho.

A solução apareceu monopig st. mut. , que é dez vezes mais lento que a solução nativa em js , mas, além disso, a solução nativa em Haskell, usando vetores mutáveis. Aqui está o código dele:
fill' :: Int -> Int -> Memory IO -> IO (Memory IO) fill' knm | n > memSize-k = return m | otherwise = M.unsafeWrite mn 1 >> fill' k (n+k) m sieve' :: Int -> Memory IO -> IO (Memory IO) sieve' km | k*k < memSize = do x <- M.unsafeRead mk if x == 0 then fill' k (2*k) m >>= sieve' (k+1) else sieve' (k+1) m | otherwise = return m
Começa da seguinte maneira
main = do m <- M.replicate memSize 0 stimes 100 (sieve' 2 m >> return ()) print "Ok"
E agora Haskell finalmente mostra que ele não é uma linguagem de brinquedo. Você só precisa usá-lo com sabedoria. A propósito, o código acima usa o fato de que o tipo IO () forma um semigrupo com a operação de execução sequencial de programas (>>) e, com a ajuda de stimes , repetimos 100 vezes o cálculo do problema de teste.
Agora está claro por que existe uma antipatia por matrizes funcionais e por que ninguém se lembra de como trabalhar com elas: assim que um programador Haskell realmente precisa de estruturas de acesso aleatório, ele se concentra em dados mutáveis e trabalha em mônadas ST ou IO.
Colocar parte de comandos em uma zona especial questiona a legalidade do código de isomorfismo o programa . Afinal, não podemos transformar o código simultaneamente em programas puros e monádicos, isso não permite que o sistema de tipos faça isso. No entanto, as classes de tipo são flexíveis o suficiente para que esse isomorfismo exista. Código do homomorfismo o programa agora está dividido em vários homomorfismos para diferentes subconjuntos do idioma. Como exatamente isso é feito pode ser visto no [código] () completo do programa.
Não pare por aí
Eliminar chamadas de função desnecessárias e incorporar seu código diretamente usando o pragma {-# INLINE #-} ajudará a alterar levemente a produtividade do programa. Este método não é adequado para funções recursivas, mas é ótimo para componentes básicos e funções de configuração. Reduz o tempo de execução do programa de teste em outros 25% (consulte Monopig51.hs ).
O próximo passo razoável será livrar-se das ferramentas de registro quando elas não forem necessárias. No estágio de formação do endomorfismo que representa o programa, usamos um argumento externo, que determinamos na inicialização. program construtores inteligentes e programM podem ser avisados de que não pode haver nenhum argumento-logger. Nesse caso, o código do conversor não contém nada de supérfluo: apenas a funcionalidade e a verificação do status da máquina.
program code f = programM code (const f) programM code f (Just logger) mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> logger mem code =<< f mem (stack vm) vm _ -> return vm programM code f _ mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> f mem (stack vm) vm _ -> return vm
Agora, as funções de execução devem indicar explicitamente a presença ou ausência de log não usando o stub none , mas usando o tipo Maybe (Logger ma) . Por que isso funcionaria, porque se houver registro ou não, os componentes do programa descobrirão "no último momento", antes da execução? O código desnecessário não seria costurado no estágio de composição da composição do programa? Haskell é uma linguagem preguiçosa e aqui ela toca em nossas mãos. É antes da execução que o código final é otimizado para uma tarefa específica. Essa otimização reduziu o tempo de execução do programa em outros 40% (consulte Monopig52.hs ).
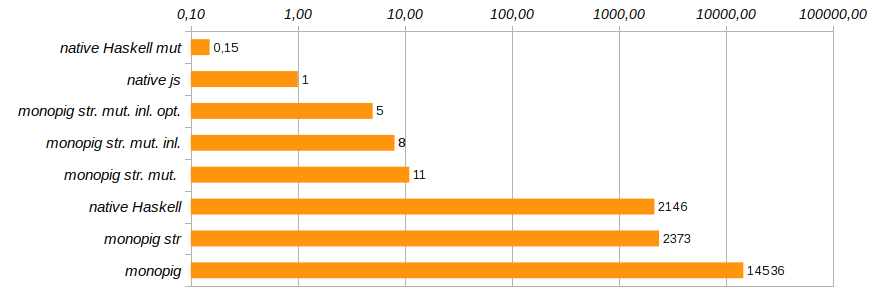
Com isso, concluiremos o trabalho de aceleração do leitão monoidal. Ele já está correndo rápido o suficiente para que tanto o anjo quanto o demônio possam se acalmar. Obviamente, isso não é C, ainda usamos uma lista limpa como uma pilha, mas substituí-la por uma matriz levará a uma escavação completa do código e à recusa de usar modelos elegantes nas definições de comandos básicos. Eu queria passar com mudanças mínimas, e principalmente no nível dos tipos.
Alguns problemas permanecem com o log. Uma simples contagem do número de etapas ou o uso da pilha funciona bem (tornamos o campo de registro estrito), mas combiná-las já começa a consumir memória, você precisa se preocupar com chutes usando seq , o que já é bastante irritante. Mas diga-me, quem registrará os 14 bilhões de etapas, se você puder depurar a tarefa nas primeiras centenas? Portanto, não vou gastar meu tempo acelerando para acelerar.
Resta apenas acrescentar que, no artigo sobre o leitão, como um dos métodos para otimizar cálculos, o rastreamento é dado: a alocação de seções lineares do código, rastreamentos nos quais os cálculos podem ser realizados ignorando o ciclo principal de despacho de comando (bloco de switch ). No nosso caso, a composição monoidal dos componentes do programa cria esses traços durante a formação do programa a partir dos componentes EDSL ou durante a operação do homomorfismo fromCode . Esse método de otimização nos chega de graça, por assim dizer, por construção.
Existem muitas soluções Conduits e rápidas no ecossistema Haskell, como fluxos de Conduits ou Pipes , existem excelentes substituições de String e criadores de XML ágeis como blaze-html, e o analisador attoparsec é um padrão para análise combinatória para gramáticas LL (∞). Tudo isso é necessário para a operação normal. Mas ainda mais necessária é a pesquisa que leva a essas decisões. Haskell tem sido e continua sendo uma ferramenta de pesquisa que atende a requisitos específicos não necessários ao público em geral. Vi em Kamchatka como os ases de um helicóptero Mi-4 fechavam as caixas de fósforos em uma discussão, empurrando o trem de pouso com uma roda enquanto pairavam no ar. Isso pode ser feito e é legal, mas não é necessário.
Mas, no entanto, isso é legal !!