O surgimento de idéias
Recentemente eu estava visitando amigos e escolhemos um filme, e eu, como fã de filmes queimados (na verdade, não tanto quanto queimados), rejeitei tudo como visto. E eles me fizeram uma pergunta lógica, mas por que você não olhou? Ao qual eu disse que estou conduzindo uma pesquisa de filme e assisto a todos os filmes que assisti, por classificação ou apenas por um sinal de visto que a exibição ocorreu. E então surgiu uma pergunta na minha cabeça, mas quanto tempo eu gastei em filmes? O Steam possui estatísticas convenientes para o jogo, mas nada para filmes. Então eu decidi enfrentar essa idéia.
O que há com a implementação?
Estou desenvolvendo o ASP.NET há vários anos e estou acostumado ao C #, no começo eu queria escrever esse utilitário nele, mas havia um problema com um ambiente pesado e, como eu sou um pouco familiarizado com o Python, recorri a ele.
E onde conseguir os dados?
E aqui estou diante do primeiro problema. Ingenuamente, assumi que a pesquisa de filmes tem uma API pública oficial e algum tipo de versão gratuita. Mas não encontrei nada parecido. Há uma oportunidade de solicitar por meio de suporte técnico, mas mesmo lá eles são distribuídos apenas pela enésima quantia, e eu escrevi isso para mim e não quis pagar de forma alguma.
Naturalmente, tive que considerar a opção de analisar páginas, e foi nela que parei.
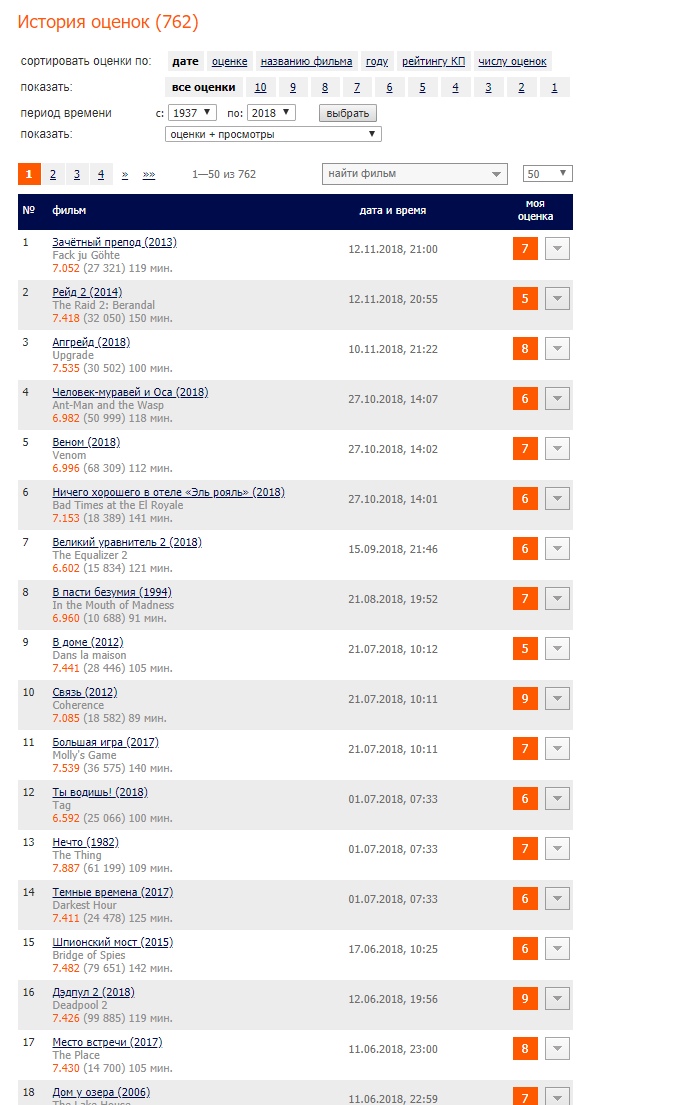
Todos no perfil têm uma lista de filmes assistidos com uma pequena descrição que inclui a duração da imagem. Dessa forma, consigo apenas algumas páginas (tenho 762 filmes e era necessário obter apenas 17 páginas) e calculo o tempo gasto.
Mal disse o que fez.
class KinopoiskParser: def __init__(self, user_id, current_page=1): self._user_id = user_id self._current_page = current_page self._wasted_time_in_minutes = 0 def calculate_wasted_time(self): while True: film_list_url = f'https://www.kinopoisk.ru/user/{self._user_id}' \ f'/votes/list/ord/date/genre/films/page/{self._current_page}/#list' try: film_response = requests.get(film_list_url).text except BaseException: proxy_manager.update_proxy() continue user_page = BeautifulSoup(film_response, "html.parser") is_end = kinopoisk_parser._check_that_is_end_of_film_list(user_page) if is_end: break wasted_time = self._get_film_duration_on_page(user_page) self._wasted_time_in_minutes += wasted_time print(f'Page {self._current_page}, wasted time {self._wasted_time_in_minutes}') self._move_next_page() def get_wasted_time(self): return self._wasted_time_in_minutes def _move_next_page(self): self._current_page += 1 @staticmethod def _get_film_duration_on_page(user_page): try: wasted_time = 0 film_list = user_page.findAll("div", {"class": "profileFilmsList"})[0].findAll("div", {"class": "item"}) for film in film_list: film_description = film.findAll("span") if len(film_description) <= 1: continue film_duration_in_minutes = int(film_description[1].string.split(" ")[0]) wasted_time = wasted_time + film_duration_in_minutes return wasted_time except BaseException: print("Something went wrong.") return 0 @staticmethod def _check_that_is_captcha(html): captcha_element = html.find_all("a", {"href": "//yandex.ru/support/captcha/"}) return len(captcha_element) > 0 @staticmethod def _check_that_is_end_of_film_list(html): error_element = html.find_all("div", {"class": "error-page__container-left"}) return len(error_element) > 0
Mas já no estágio de depuração, encontrei um problema que a pesquisa de cinema bloqueia solicitações (cerca de 4 iterações) e as considera suspeitas. E ele está certo! Mas eu também sugeri essa opção e segui para o plano B.
Plano B - alterar proxies como luvas
Pegar o primeiro servidor que fornece uma API para obter o proxy IP (não anuncio nenhum serviço, peguei os dois primeiros links do Google), estraguei tudo e continuou a escrever o código principal. E uma hora depois, quando eu estava quase completo, fui bloqueado pelo servidor que a API fornece! Eu tive que mudar para outra, que produz uma lista fixa, a cada meia hora, para minha tarefa é suficiente. Mas se a lista terminar repentinamente, você poderá retornar à opção anterior (eles emitem de 10 a 24 proxies a cada 24 horas).
class ProxyManager: def __init__(self): self._current_proxy = "" self._current_proxy_index = -1 self._proxy_list = [] self._get_proxy_list() def get_proxies(self): proxies = { "http": self._current_proxy, "https": self._current_proxy } return proxies def update_proxy(self): self._current_proxy_index += 1 if self._current_proxy_index == len(self._proxy_list): print("Proxies are ended") print("Try get alternative proxy") proxy_ip_with_port = self._get_another_proxy() print("Proxy updated to " + proxy_ip_with_port) self._current_proxy = f'http://{proxy_ip_with_port}' return self._current_proxy proxy_ip_with_port = self._proxy_list[self._current_proxy_index] print("Proxy updated to " + proxy_ip_with_port) self._current_proxy = f'http://{proxy_ip_with_port}' return self._current_proxy @staticmethod def _get_another_proxy(): proxy_response = requests.get("https://api.getproxylist.com/proxy?protocol[]=http", headers={ 'Content-Type': 'application/json' }).json() ip = proxy_response['ip'] port = proxy_response['port'] proxy = f'{ip}:{port}' return proxy def _get_proxy_list(self): proxy_response = requests.get("http://www.freeproxy-list.ru/api/proxy?anonymity=false&token=demo") self._proxy_list = proxy_response.text.split("\n")
Combinando tudo isso (no final, darei um link para o github com a versão final), consegui uma excelente coisa por contar o tempo gasto nos filmes. E ele recebeu o número estimado, tadam: "Você desperdiçou 84542 minutos ou 1409,03 horas ou 58,71 dia".
Em vão gastou tempo para contar em vão gastou tempo
De fato, não em vão. A tarefa era interessante, embora dificilmente necessária, para pelo menos alguém.
E agora posso dizer a todos que durante quase dois meses da minha vida eu estava assistindo um filme!
Se alguém também estiver interessado em obter essas estatísticas "importantes", copie o ID do seu perfil e inicie o projeto com esse parâmetro. Se você puder descartar facilmente o resultado no comentário, estou interessado em um "fã de cinema" ou iniciante.
Link do código fontePS: Ficarei feliz em ouvir dicas sobre como melhorar o código, já que escrevi muito pouco sobre python e ainda não entendo completamente a sintaxe.