Neste artigo, quero falar sobre minha paixão de longa data - estudar e trabalhar com microfone de campos distantes (matriz de microfone) - matrizes de microfone.
O artigo será interessante para quem gosta de construir seus assistentes de voz, responderá a algumas perguntas para pessoas que consideram a engenharia como uma arte e também que desejam se dedicar ao papel de Q ( este é de Bond ). Minha humilde história, espero que possa ajudá-lo a entender por que uma coluna de assistente inteligente feita estritamente de acordo com o tutorial funciona bem apenas se não houver ruído. E tão ruim onde eles estão, por exemplo, na cozinha.
Muitos anos atrás, fiquei interessado em programação, comecei a escrever código simplesmente porque professores sábios me permitiam jogar apenas jogos escritos por mim. Fazia um ano com 87 anos e era um Yamaha MSX. Sobre este assunto, houve também uma primeira inicialização. Tudo é estritamente de acordo com a sabedoria: “Escolha um emprego que você goste e não precisará trabalhar um único dia em sua vida” (Confúcio).
E assim os anos se passaram, e eu ainda estou escrevendo código. Mesmo um hobby com um código - bem, exceto para patinar, para aquecer cérebros e "não esquecerei matan", isso está funcionando com o microfone Far Fields (matriz Mic). Em vão os professores passaram algum tempo comigo.
O que é e onde é aplicado
O assistente de voz que ouve você geralmente possui uma variedade de microfones. Nós os encontramos em sistemas de videoconferência. Na comunicação coletiva, a maior parte da atenção é dada à fala, é claro, não olhamos constantemente para o falante ao nos comunicar, mas falar diretamente no microfone ou no fone de ouvido é constrangedor e inconveniente.
Quase todo mundo, um cliente respeitado, um fabricante de celulares usa de 2 ou mais microfones em suas criações (sim, os microfones ficam atrás desses buracos acima, abaixo e atrás). Por exemplo, no iPhone 3G / 3GS, ele era o único, na quarta geração de iPhones havia dois e na quinta já havia três microfones. Em geral, este também é um conjunto de microfones. E tudo isso para melhor audibilidade do som.
Mas voltando aos nossos assistentes de voz
Como aumentar o alcance da audição?
"precisa de orelhas grandes"
Uma idéia simples: se, para ouvir o próximo, basta apenas um microfone, então para ouvir de longe, você precisa usar um microfone mais caro com um refletor, semelhante aos ouvidos das raposas fenech:

(Wikipedia)


 De fato, isso não faz parte da suíte peluda, mas um dispositivo sério para caçadores e batedores.
De fato, isso não faz parte da suíte peluda, mas um dispositivo sério para caçadores e batedores.

O mesmo, apenas em tubos ressonadores

No habitat.
(Retirado de https://forum.guns.ru )
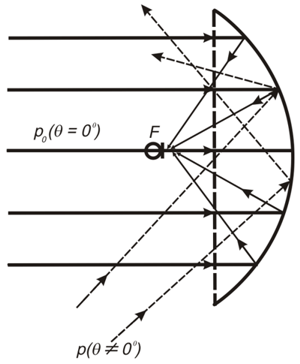
Diâmetro do espelho de 200mm a 1.5m
(mais sobre isso, consulte http://elektronicspy.narod.ru/next.html )
"Precisa de mais microfones"
Ou talvez, se você colocar muitos microfones baratos, a quantidade será de qualidade e tudo funcionará? Zerghrash apenas com microfones.
Estranho, mas funciona na vida real. É verdade com muita matan, mas funciona. E falaremos sobre isso na próxima seção.
E como aprender a ouvir mais sem chifres bonitos?

Um dos problemas dos sistemas de buzinas é que você pode ouvir claramente o que está em foco. Mas se você precisar ouvir algo de uma direção diferente, precisará fazer uma "simulação com os ouvidos" e redirecionar fisicamente o sistema em outra direção.
E sobre a relação sinal / ruído em sistemas com matrizes de microfone, é de alguma forma melhor comparado a um microfone convencional.
Nas matrizes de microfones, bem como em seus parentes mais próximos - PAR (antenas de phased array), você não precisa ativar nada. Leia mais na seção Beamforming. Fácil de ver:

Um microfone fora de foco (imagem à esquerda) grava todos os sons de todas as direções, não apenas o que você precisa.
De onde vem a grande variedade? Na imagem certa, o microfone ouve atentamente apenas uma fonte. Como se estivesse focando, ele recebe um sinal apenas de uma fonte selecionada e não uma confusão de possíveis fontes de ruído, e um sinal puro é simplesmente amplificado (mais alto) sem o uso de técnicas sofisticadas de redução de ruído. Um pouco como um bocal, mas com uma tração fosca.
O que há de errado com a redução de ruído?
Ao aplicar uma redução de ruído complexa, muitas falhas significam que parte do sinal desaparece, juntamente com parte do sinal, o som muda e, de ouvido, parece uma coloração característica do som com redução de ruído e como resultado de ilegibilidade. Essa ilegibilidade é visível para os falantes de russo que desejam ouvir esses sibilos do interlocutor. Bem, e além disso - como resultado do cancelamento de ruído, o ouvinte não ouve nenhum sinal de identificação que o conecte ao interlocutor (respiração, fungadela e outros ruídos que acompanham a fala ao vivo). Isso cria alguns problemas, porque no discurso coloquial tudo isso é ouvido e ajuda a avaliar o estado e a atitude do interlocutor em relação a você. A ausência deles (barulho) enquanto ouvimos a voz causa sensações desagradáveis e reduz o nível de percepção, entendimento e identificação. Bem, se um assistente de voz o escuta, a redução de ruído dificulta o reconhecimento da frase-chave e do discurso posterior. É verdade que existe um problema de vida - você precisa treinar o reconhecedor em uma amostra gravada, levando em consideração as distorções da redução de ruído usada.
Aqueles que estão familiarizados com as palavras problema de coquetel ainda podem tomar um café ou um coquetel e realizar um experimento de campo, com vontade de ler, continuam.

Brevemente sobre o matan em que trabalha:
DOA (determinação da direção e, se possível, localização da fonte):
Serei breve, porque o tópico é muito extenso, isso é feito com a ajuda de magia branca, cinza ou escura (dependendo do tópico preferido no IDE) e matan. o principal Uma maneira frequente de tocar DOA é analisar correlações e outras coisas entre pares de microfones (geralmente com diâmetro oposto).
Life hack: para pesquisas, é melhor escolher um array com um arranjo circular de microfones. O benefício é que é fácil coletar estatísticas de pares com diferentes distâncias entre microfones - com diâmetro máximo e mínimo entre microfones - se você usar pares em acordes e com diferentes azimutes (direções) para a fonte.
Formação de vigas - A maneira mais simples e fácil de entender é -day e soma (DAS e FDAS) - formação de vigas com base no atraso e na soma.
Para recursos visuais:
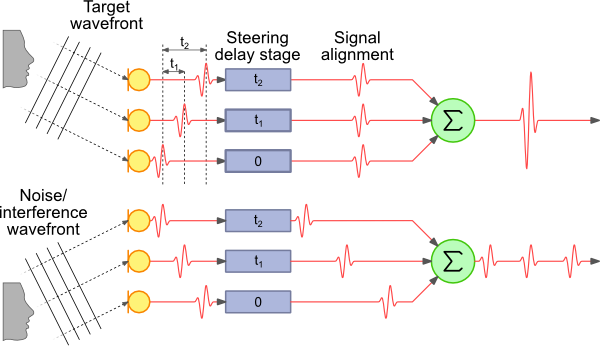
(Retirado de http://www.labbookpages.co.uk/audio/beamforming/delaySum.html )
Life hack: Não se esqueça dos diferentes comprimentos de onda e para cada frequência calculamos nossa diferença de fase tn
Um padrão de radiação aproximado será mais ou menos assim
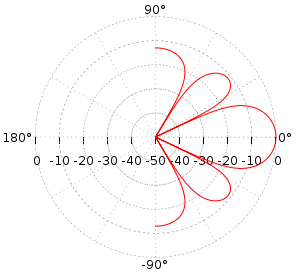
Detalhes e com fórmulas
Aqueles que não se esqueceram de como fumar um matan podem participar do JIO-RLS (mínimos quadrados de classificação reduzida adaptativa do subespaço iterativo conjunto). Muito parecido com o sabor da descida gradiente, você sabe.

Então, resumimos: usando métodos convencionais, é difícil obter qualidade comparável a um microfone de matriz. Depois de aplicar a definição da direção à fonte e, como resultado, apenas ouvimos a fonte necessária, nos livramos do ruído e da reverberação do meio, mesmo que seja pouco audível (efeito Haas).
Voice Assistant - Como fica por dentro
Então, como é o esquema de processamento de som de um assistente de voz experiente:

O sinal do conjunto de microfones é alimentado a um dispositivo no qual formamos um feixe para uma fonte de som (formação de feixe), removendo, assim, a interferência. Em seguida, começamos a reconhecer o som desse raio, geralmente não é suficiente para o reconhecimento de alta qualidade dos recursos do dispositivo e, na maioria das vezes, o sinal vai para a nuvem para reconhecimento (Microsoft, Google, Amazon o escolhe).
O leitor atento notará: E na figura com a descrição existe algum tipo de quadrado da palavra Não, e por que não reconhecimento imediato, como prometido?
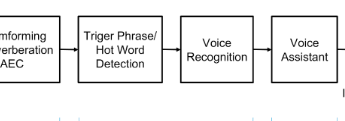
Por que esse quadrado provavelmente extra é desenhado no diagrama?
E porque você transmite constantemente um sinal de todas as fontes de ruído para a Internet para ouvindo o reconhecimento de quaisquer recursos não é suficiente. Portanto, começamos a reconhecer apenas quando eles perceberam que definitivamente o desejam de nós - e por isso disseram um feitiço especial - ok Google, Siri ou Alex, ou me chamaram de cortan. E o classificador de palavras do Notificador geralmente é um neurônio e funciona diretamente no dispositivo. Na construção do classificador, há também muitas coisas interessantes, mas hoje não é sobre isso.
E, de fato, o diagrama se parece com isso:
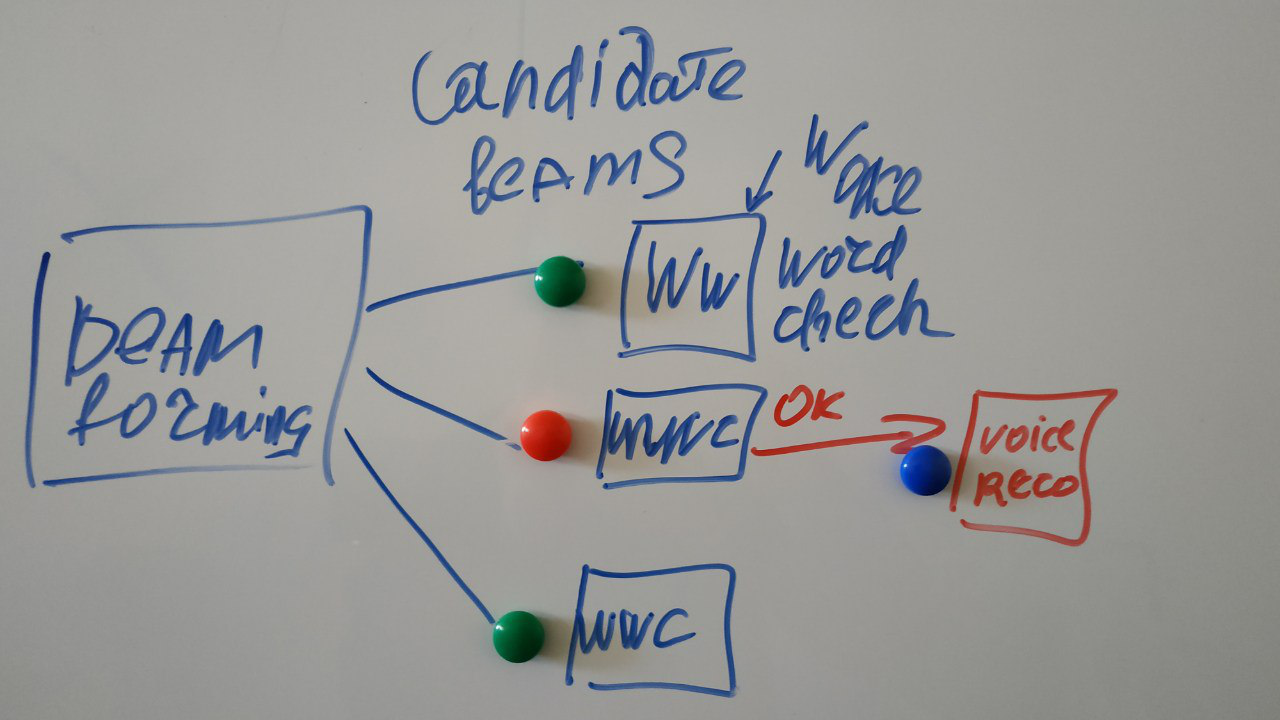
(meus rabiscos)
Vários raios podem ser formados em diferentes fontes de sinal, e estamos procurando uma palavra especial em cada um deles. Mais adiante, processaremos quem disse a palavra certa.
O próximo passo é o reconhecimento na nuvem, coberto repetidamente na Internet, e existem muitos tutoriais.
Como você pode participar deste feriado matana
A maneira mais fácil de comprar uma placa de desenvolvimento. Visão geral dos devboards existentes: um dos mais completos - por referência .
O mais amigável para iniciantes:
https://www.seeedstudio.com/ReSpeaker-4-Mic-Array-for-Raspberry-Pi-p-2941.html
https://www.seeedstudio.com/ReSpeaker-Mic-Array-v2-0-p-3053.html
baseado no XMOS XVF-3000.
Eu mesmo aplico
Feito como eu gosto - o FPGA com uma interface aberta controla os microfones da matriz, comunicando-se com ele via SDA.
Meus feitos para cruzar o Android Things e o Mic Array:
Certamente existem muitos exemplos neste fórum (Voice), mas é conveniente para mim usá-lo em Things.
Argumentos para as coisas:
Você pode criar uma ferramenta flexível e poderosa:
- conveniente que você possa usar a tela como um dispositivo separado
- pode ser usado como um dispositivo sem cabeça, ou seja, fazer uma transferência pela rede (criar uma API para transferência para outro dispositivo)
- depuração conveniente
- muitas bibliotecas, inclusive para transmissão pela rede;
- ferramentas de análise - muito.
- e se pareceu um pouco, é possível conectar bibliotecas Sishnoy
Por exemplo, eu uso:
- análise de arquivos de som
- HRTF,
- Formação \ construção de classificadores.
E então, se você precisar portar / reescrever o código em algum tipo de incorporação, é mais fácil fazer isso com o código Java.
Infelizmente, o exemplo dos autores do quadro do Things foi um pouco inoperante, então fiz meu projeto de demonstração (naturalmente - eu posso).
Em resumo, o que existe - toda a magia negra dos microfones de pesquisa rápida, fazemos FFT em C ++ e visualização, análise, interação de rede - em Java.
Planos de desenvolvimento futuro
Fonte de planos e inspiração ao mesmo tempo: ODAS .
Então, eu quero fazer o mesmo, apenas no Things e sem falhas.
- Porque o ODAS é um pouco inconveniente de usar.
- Eu preciso de uma ferramenta normal para trabalhar
- Porque eu posso e gosto deste tópico
- As ferramentas de hardware usadas atendem à complexidade da tarefa.
Meus planos são baseados neste (meu próprio) repositório .
E lembre
"Se você tem algo para complementar ou criticar, não hesite em escrever sobre isso nos comentários, porque uma cabeça é pior que duas, duas são piores que três e n-1 é pior que n" nikitasius