
Recentemente, um cliente nos pediu para implementar um sistema de contabilidade de capacidade em disco. A tarefa era combinar informações de mais de setenta matrizes de disco de diferentes fornecedores, de switches SAN e hosts VMware ESX. Em seguida, os dados precisavam ser sistematizados, analisados e capazes de serem exibidos em um painel e em vários relatórios, por exemplo, sobre o volume livre e ocupado de espaço em disco em todas as matrizes ou tomadas separadamente.
Decidimos implementar o projeto usando o sistema de análise operacional - Splunk.
Por que splunk?
O Splunk é poderoso na visualização dos dados que coleta. Permite criar relatórios interativos - painéis - atualizados em tempo real. Exibimos informações sobre o espaço total em disco nelas, exibimos imediatamente todas as matrizes com a capacidade de classificar por filtros diferentes, por exemplo, por capacidade. Ao clicar na matriz, obtemos imediatamente informações sobre todas as conexões. Em um painel separado, é possível inserir o nome da máquina virtual e ver em qual host ESX ele vive, a partir de quais matrizes recebe dados e outros parâmetros.
Na minha opinião, até agora o Splunk não tem análogos que funcionariam com qualquer sistema de armazenamento pronto para uso. Há alguns anos, o CommandCentral pago apareceu, mas não possui a flexibilidade necessária, não sabe como gerar relatórios arbitrários (nas primeiras versões dos relatórios não havia nenhum) e com visualização esfarrapada. Em geral, isso não é uma ferramenta para inventário, mas para monitorar e controlar o status dos sistemas. Para cumprir a tarefa definida pelo cliente, ela teria que ser refinada por um longo tempo e cara.
Ao mesmo tempo, o Splunk possui recursos impressionantes de exibição de informações: os gráficos podem ser organizados livremente entre si, monitorar o status de todos os sistemas em um modo de janela única e, assim, simplificar sua manutenção. Para todo o resto - para a nossa tarefa, usamos a versão gratuita.

O que você fez?
Até o momento, nossa equipe não possuía experiência com o Splunk. Felizmente, o sistema acabou sendo amigável e intuitivo, e as soluções para problemas emergentes foram facilmente encontradas usando uma ajuda regular ou em um mecanismo de busca.
O Splunk criou várias ferramentas que precisamos. Por exemplo, o sistema permite combinar dados de diferentes fontes para qualquer campo por meio das chamadas pesquisas (diretórios). Portanto, em uma tabela, os hosts ESX foram exibidos como IP, em outra - como nomes DNS. Inicialmente, queríamos criar uma pesquisa caseira e usar o utilitário nslookup para selecionar registros DNS e coletar tabelas, mas o Splunk possui um diretório que compara DNS sobre IP e vice-versa. Essa pesquisa interna não precisa ser configurada, ela própria extrai dados sobre servidores DNS das configurações do sistema e não importa se é Windows ou Linux, e os dados nos registros DNS estão sempre atualizados.

Um dos cenários interessantes implementados com o Splunk é o controle de alterações (RFC) no sistema. Por exemplo, um gerente de RFC recebe uma solicitação de um engenheiro para atender a um dos comutadores SAN. Ele digita o nome do comutador no Splunk e vê quais armazenamentos estão conectados a ele e quais servidores recebem dados desses armazenamentos. Ao mesmo tempo, o gerente vê o plano de trabalho que o engenheiro escreveu e pode avaliar como a desativação dessa opção durante a manutenção afetará o desempenho de matrizes e servidores.
Configuramos o carregamento diário de informações sobre como conectar todos os switches e matrizes ao Splunk. O cliente está satisfeito com esta taxa de atualização. Ele já tinha uma ferramenta de monitoramento Stor2RRD, mas não sabe como combinar dados de diferentes fontes e visualizá-los. Portanto, configuramos o sistema de aquisição de dados no Splunk da seguinte maneira:
- Nós recebemos informações sobre armazenamentos do Stor2RRD;
- Dos switches, recebemos informações sobre SAN;
- Por meio do vCenter usando scripts PowerCLI, coletamos dados de hosts ESX.
Os dados recebidos são automaticamente trazidos para um único formulário, processados e exibidos na forma de quaisquer relatórios necessários.
Com o que você teve que lutar?
O Splunk é um sistema poderoso, mas existem tarefas que não podem ser resolvidas imediatamente e, para resolver alguns problemas, precisamos de um conhecimento profundo do VMware.
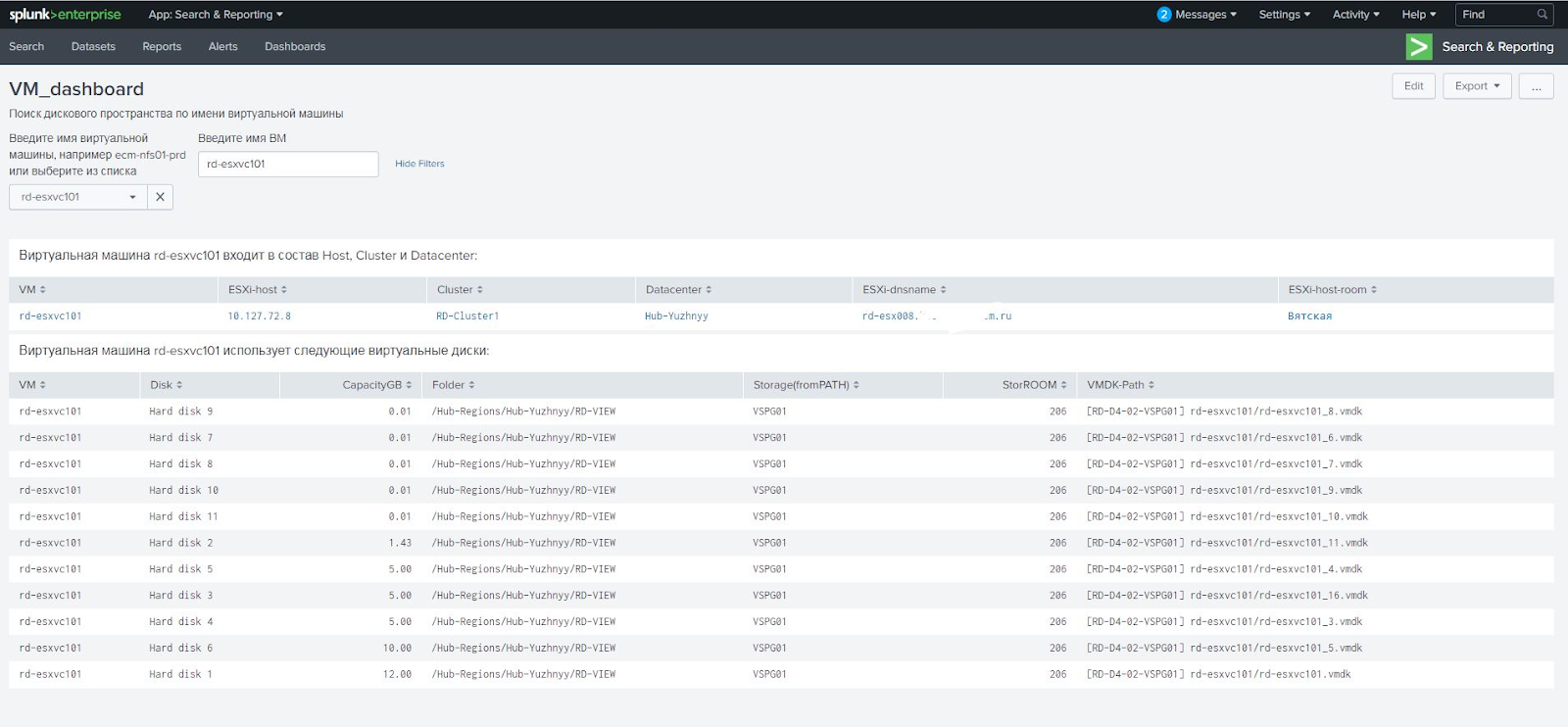
Por exemplo, um cliente usa discos RDM alocados diretamente e datastores virtuais virtuais para máquinas virtuais. Esses dois tipos de unidades precisam ser manipulados de maneira diferente. Inicialmente, resolvemos o problema por conta própria, mas depois enfrentamos uma situação em que a máquina virtual recebia discos RAW e virtuais. Verificou-se que estávamos obtendo o campo Caminho errado no relatório do vCenter e o link errado para a matriz de discos RAW. O esquema funciona com datastores comuns, mas não funciona com discos RAW. Para eles, você precisa usar a propriedade do disco RAW Disk ID, que contém o atributo do disco. Eu tive que recorrer a especialistas da VMware que refizeram o script para calcular a matriz correta por meio do ID de disco RAW.
Além disso, não aprendemos imediatamente como trabalhar da melhor maneira com os scripts do PowerCLI; posteriormente, os algoritmos tiveram que ser mais desenvolvidos. Inicialmente, os scripts processavam dados de vários milhares de máquinas virtuais por até três horas! Após o refinamento, a duração dos scripts foi reduzida para quarenta minutos.
Qual é o resultado?
Como não possuímos experiência com o Splunk, rapidamente implementamos em sua base um sistema de capacidade de disco contábil, que recebe informações de várias fontes, consolida-as e fornece uma ampla variedade de gráficos convenientes e intuitivos. Se você nunca teve que escolher ou criar esse sistema antes, o Splunk é um bom candidato para essa função. Funciona rapidamente, é fácil e flexível e não requer nenhum conhecimento especializado para resolver a grande maioria das tarefas.
Vladislav Semenov, Chefe do Grupo de Arquitetura de Sistemas, Centro de Design de Complexos de Computação, Jet Infosystems