 datacenterknowledge.com
datacenterknowledge.comNo ano passado, a maior instalação de armazenamento baseada em RAIDIX no momento foi implementada. Um sistema de 11 clusters de failover foi implantado no Instituto de Ciências da Computação RIKEN (Japão). O principal objetivo do sistema é o armazenamento da infraestrutura HPC (HPCI), que é implementada como parte do intercâmbio acadêmico em larga escala de informações acadêmicas Academic Cloud (com base na rede SINET).
Uma característica significativa deste projeto é o seu volume total de 65 PB, dos quais o volume utilizável do sistema é 51,4 PB. Para entender melhor esse valor, adicionamos que são 6512 discos de 10 TB cada (o mais moderno no momento da instalação). Isso é muito.
O trabalho no projeto continuou ao longo do ano, após o qual o monitoramento da estabilidade do sistema continuou por cerca de um ano. Os indicadores obtidos atendem aos requisitos estabelecidos e agora podemos falar sobre o sucesso desse registro e um projeto significativo para nós.
Supercomputador no RIKEN Institute Computing Center
Para a indústria de TIC, o Instituto RIKEN é conhecido principalmente por seu lendário “K-computer” (do japonês “kei”, que significa 10 quatrilhões), que na época do lançamento (junho de 2011) era considerado o supercomputador mais poderoso do mundo.
O supercomputador ajuda o Centro de Ciências Computacionais na implementação de pesquisas complexas em larga escala: permite modelar clima, condições climáticas e comportamento molecular, calcular e analisar reações na física nuclear, previsão de terremotos e muito mais. As capacidades de supercomputadores também são usadas para pesquisas mais "cotidianas" e aplicadas - para procurar campos de petróleo e prever tendências nos mercados de ações.
Tais cálculos e experimentos geram uma enorme quantidade de dados, cujo valor e significância não podem ser superestimados. Para tirar o máximo proveito disso, os cientistas japoneses desenvolveram um conceito para um único espaço de informações no qual profissionais de HPC de diferentes centros de pesquisa terão acesso aos recursos recebidos de HPC.
Infraestrutura de computação de alto desempenho (HPCI)
O HPCI opera com base no SINET (The Science Information Network), uma rede principal para o intercâmbio de dados científicos entre universidades japonesas e centros de pesquisa. Atualmente, o SINET reúne cerca de 850 institutos e universidades, criando enormes oportunidades para o intercâmbio de informações em pesquisas que afetam a física nuclear, astronomia, geodésia, sismologia e ciência da computação.
O HPCI é um projeto de infraestrutura exclusivo que forma um sistema unificado de troca de informações no campo da computação de alto desempenho entre universidades e centros de pesquisa no Japão.
Ao combinar os recursos do supercomputador “K” e de outros centros de pesquisa de forma acessível, a comunidade científica recebe benefícios óbvios por trabalhar com dados valiosos criados pela computação de supercomputadores.
Para fornecer acesso conjunto eficaz ao usuário ao ambiente HPCI, foram impostos altos requisitos de armazenamento à velocidade de acesso. E, graças à "hiperprodutividade" do computador K, o cluster de armazenamento no Centro de Ciências da Computação do Instituto RIKEN foi calculado para ser criado com um volume de trabalho de pelo menos 50 PB.
A infraestrutura do projeto HPCI foi construída sobre o sistema de arquivos Gfarm, que permitiu um alto nível de desempenho e combinou clusters de armazenamento diferentes em um único espaço compartilhado.
Sistema de arquivos Gfarm
Gfarm é um sistema de arquivos distribuídos de código aberto desenvolvido por engenheiros japoneses. Gfarm é o fruto do desenvolvimento do Instituto de Ciência e Tecnologia Industrial Avançada (AIST), e o nome do sistema refere-se à arquitetura usada pelo Grid Data Farm.
Este sistema de arquivos combina várias propriedades aparentemente incompatíveis:
- Alta escalabilidade em volume e desempenho
- Distribuição de rede de longa distância com suporte para um único espaço de nome para diversos centros de pesquisa
- Suporte à API POSIX
- Alto desempenho necessário para computação paralela
- Segurança de armazenamento de dados
O Gfarm cria um sistema de arquivos virtual usando recursos de armazenamento de vários servidores. Os dados são distribuídos pelo servidor de metadados e o próprio esquema de distribuição é oculto aos usuários. Devo dizer que o Gfarm consiste não apenas em um cluster de armazenamento, mas também em uma grade computacional que utiliza os recursos dos mesmos servidores. O princípio de operação do sistema se assemelha ao Hadoop: o trabalho enviado é "reduzido" para o nó em que os dados estão.
A arquitetura do sistema de arquivos é assimétrica. As funções estão claramente alocadas: Servidor de Armazenamento, Servidor de Metadados, Cliente. Mas, ao mesmo tempo, todas as três funções podem ser executadas pela mesma máquina. Os servidores de armazenamento armazenam muitas cópias de arquivos e os servidores de metadados operam no modo mestre-escravo.
Trabalho de projeto
A Core Micro Systems, um parceiro estratégico e fornecedor exclusivo da RAIDIX no Japão, implementou a implementação no Instituto de Ciências da Computação RIKEN. Para implementar o projeto, foram necessários 12 meses de trabalho minucioso, nos quais participaram não apenas os funcionários da Core Micro Systems, mas também os especialistas técnicos da equipe da Reydix.
Ao mesmo tempo, a transição para outro sistema de armazenamento parecia improvável: o sistema existente tinha muitas ligações técnicas, o que complicou a transição para qualquer nova marca.
Durante longos testes, verificações e melhorias, o RAIDIX demonstrou consistentemente alto desempenho e eficiência ao trabalhar com uma quantidade impressionante de dados.
Sobre as melhorias, vale a pena contar um pouco mais. Era necessário não apenas criar a integração dos sistemas de armazenamento com o sistema de arquivos Gfarm, mas expandir algumas características funcionais do software. Por exemplo, para atender aos requisitos estabelecidos das especificações técnicas, era necessário desenvolver e implementar a tecnologia de Gravação Automática o mais rápido possível.
A implantação do próprio sistema foi sistemática. Os engenheiros da Core Micro Systems conduziram com cuidado e precisão cada etapa do teste, aumentando gradualmente a escala do sistema.
Em agosto de 2017, a primeira fase de implantação foi concluída quando o volume do sistema atingiu 18 PB. Em outubro do mesmo ano, foi implementada a segunda fase, na qual o volume atingiu o recorde de 51 PB.
Arquitetura da solução
A solução foi criada através da integração dos sistemas de armazenamento RAIDIX e o sistema de arquivos distribuídos Gfarm. Em conjunto com o Gfarm, a capacidade de criar armazenamento escalável usando 11 sistemas RAIDIX de controlador duplo.
A conexão com os servidores Gfarm é feita através de 8 x SAS 12G.
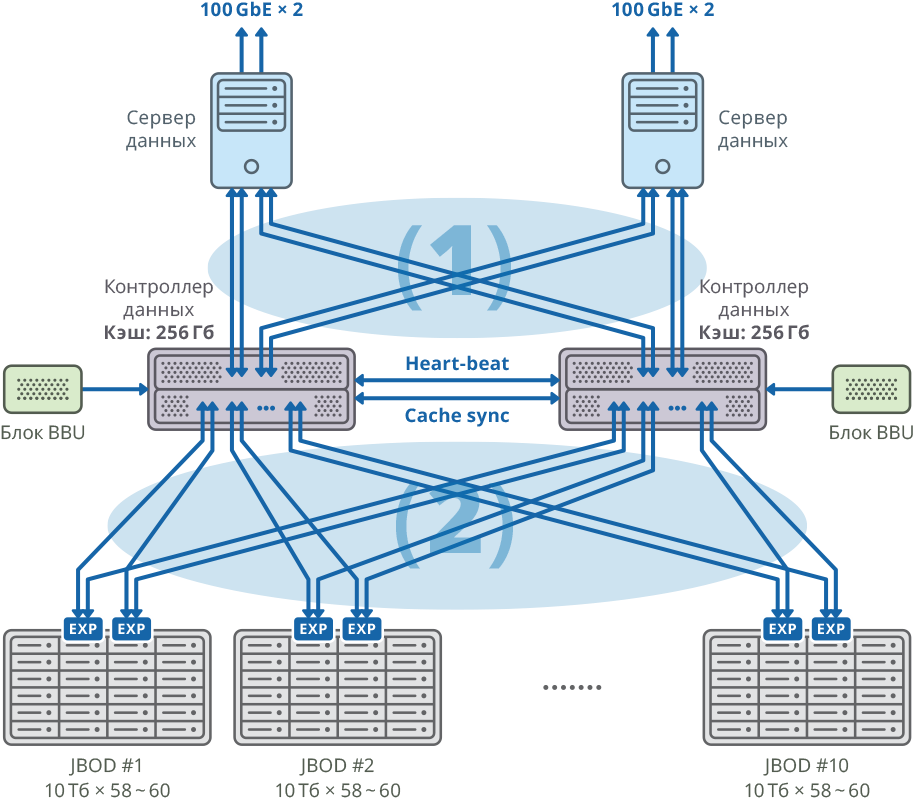 Fig. 1. Imagem de um cluster com um servidor de dados separado para cada nó
Fig. 1. Imagem de um cluster com um servidor de dados separado para cada nó(1) conexões SAN Mesh de 48 Gbps × 8; largura de banda: 384Gbps
(2) conexões de malha de 48 Gbps × 40; largura de banda: 1920Gbps
Configuração da plataforma de controlador duplo
| CPU | Intel Xeon E5-2637 - 4pcs |
| Placa-mãe | Compatível com o modelo de processador compatível com PCI Express 3.0 x8 / x16 |
| Cache interno | 256 GB para cada nó |
| Chassis | 2U |
| Controladores SAS para conectar prateleiras de disco, servidores e sincronização de cache de gravação | Broadcom 9305 16e, 9300 8e |
| HDD | HDD HGST Hélio 10TB SAS |
| Sincronização de pulsação | Ethernet 1 GbE |
| Sincronização CacheSync | 6 x SAS 12G |
Os dois nós do cluster de failover são conectados a 10 JBODs (60 discos de 10 TB cada) por meio de 20 portas SAS 12G para cada nó. Nestas prateleiras de disco, foram criadas 58 matrizes RAID6 de 10 TB (8 discos de dados (D) + 2 discos de paridade (P)) e 12 discos foram alocados para “hot swap”.
10 JBOD => 58 × RAID6 (8 discos de dados (D) + 2 discos de paridade (P)), LUN de 580 HDD + 12 HDD para “hot swap” (2,06% do volume total)
592 HDD (10TB SAS / 7.2k HDD) por cluster * HDD: HGST (MTBF: 2 500 000 horas)
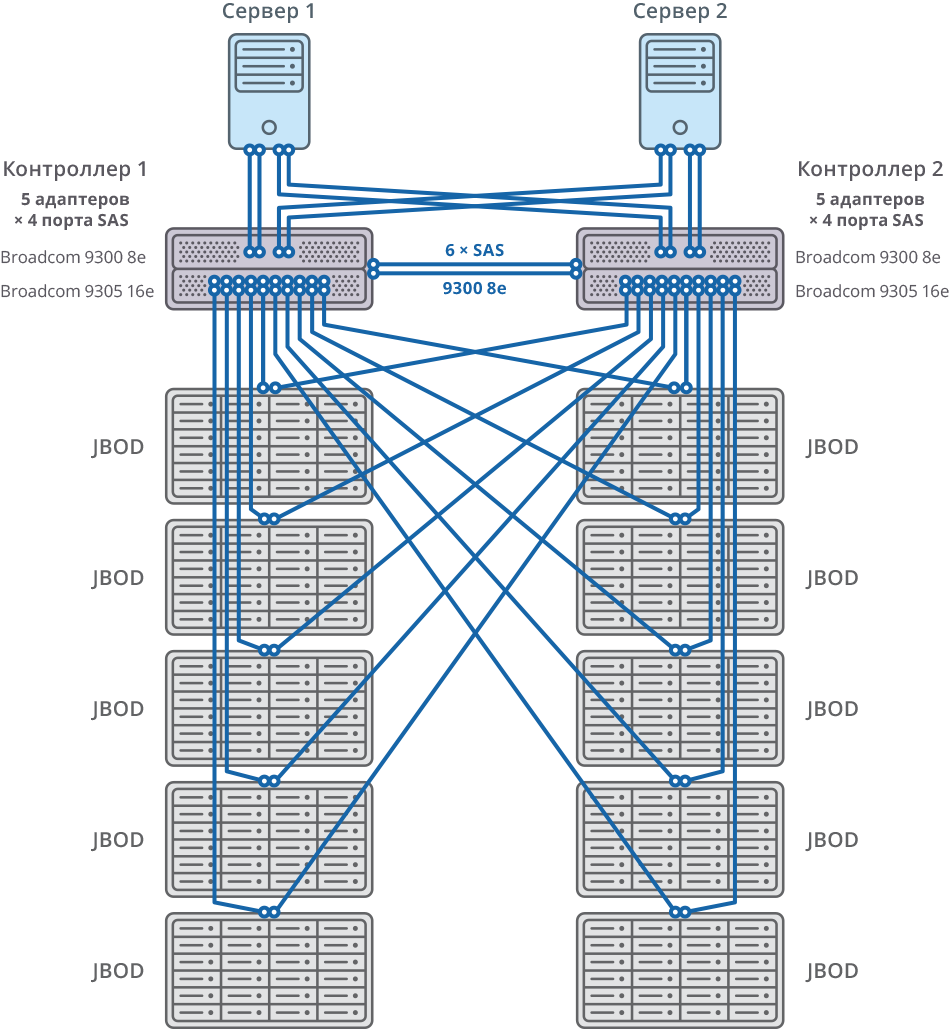 Fig. 2. Cluster de failover com diagrama de conexão 10 JBOD
Fig. 2. Cluster de failover com diagrama de conexão 10 JBODSistema geral e diagrama de conexão
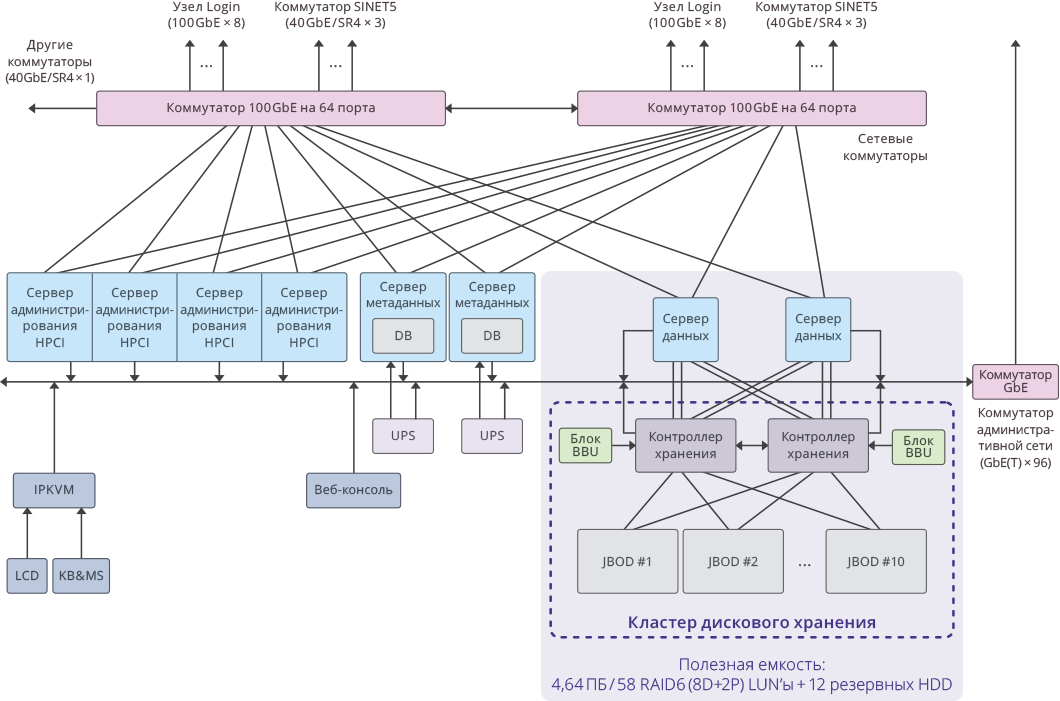 Fig. 3. Imagem de um único cluster no sistema HPCI
Fig. 3. Imagem de um único cluster no sistema HPCIPrincipais indicadores do projeto
Capacidade útil por cluster: 4,64 PB ((RAID6 / 8D + 2P) LUN × 58)
A capacidade útil total de todo o sistema: 51,04 PB (4,64 PB × 11 clusters).
Capacidade total do sistema: 65 PB .
O desempenho do sistema foi: 17 GB / s para gravação, 22 GB / s para leitura.
O desempenho total do subsistema de disco do cluster em 11 sistemas de armazenamento RAIDIX: 250 GB / s .