



Este artigo discute as conversões mais interessantes que uma cadeia de dois
transpilers realiza (o primeiro traduz código Python em código na
nova linguagem de programação 11l e o segundo traduz código em 11l em C ++) e também compara o desempenho com outras ferramentas de aceleração / Execução de código Python (PyPy, Cython, Nuitka).
Substituindo fatias \ fatias por intervalos
A indicação explícita para indexação do final da matriz
s[(len)-2] vez de apenas
s[-2] necessária para eliminar os seguintes erros:
- Quando, por exemplo, é necessário obter o caractere anterior por
s[i-1] , mas para i = 0, esse registro / em vez de um erro retornará silenciosamente o último caractere da string [ e, na prática, encontrei esse erro - confirmação ] . - A expressão
s[i:] após i = s.find(":") funcionará incorretamente quando o caractere não for encontrado na string [em vez de '' parte da string iniciando no primeiro caractere : e depois '' o último caractere da string será utilizado ]] (e geralmente , Acho que retornar -1 com a função find() em Python também está incorreto [ deve retornar null / None [ e se -1 for necessário, ele deve ser escrito explicitamente: i = s.find(":") ?? -1 ] ] ) - Escrever
s[-n:] para obter os últimos n caracteres de uma string não funcionará corretamente quando n = 0.
Cadeias de operadores de comparação
À primeira vista, é um recurso excelente da linguagem Python, mas na prática pode ser facilmente abandonado / dispensado usando o operador
in e os intervalos:
Compreensão da lista
Da mesma forma, como se viu, você pode recusar outro recurso interessante das compreensões da lista em Python.
Enquanto alguns
glorificam a compreensão da lista e até sugerem o abandono de `filter ()` e `map ()` , eu descobri que:
Em todos os lugares onde eu vi a compreensão da lista do Python, você pode facilmente conviver com as funções `filter ()` e `map ()`. dirs[:] = [d for d in dirs if d[0] != '.' and d != exclude_dir] dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) '[' + ', '.join(python_types_to_11l[ty] for ty in self.type_args) + ']' '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']'
`filter ()` e `map ()` no 11l parecem mais bonitos que no Python dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) dirs = dirs.filter(d -> d[0] != '.' & d != @exclude_dir) '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']' '['(.type_args.map(ty -> :python_types_to_11l[ty]).join(', '))']' outfile.write("\n".join(x[1] for x in fileslist if x[0])) outfile.write("\n".join(map(lambda x: x[1], filter(lambda x: x[0], fileslist)))) outfile.write(fileslist.filter(x -> x[0]).map(x -> x[1]).join("\n"))
e conseqüentemente, a necessidade de compreensão de lista em 11l realmente desaparece [a substituição da compreensão de lista por filter() e / ou map() é realizada durante a conversão do código Python em 11l automaticamente ] .
Converta a cadeia if-elif-else para alternar
Embora o Python não contenha uma instrução switch, essa é uma das construções mais bonitas do 11l, então decidi inserir o switch automaticamente:
Para completar, aqui está o código C ++ gerado switch (instr[i]) { case u'[': nesting_level++; break; case u']': if (--nesting_level == 0) goto break_; break; case u''': ending_tags.append(u"'"_S); break; // '' case u''': assert(ending_tags.pop() == u'''); break; }
Converta pequenos dicionários em código nativo
Considere esta linha de código Python:
tag = {'*':'b', '_':'u', '-':'s', '~':'i'}[prev_char()]
Provavelmente, essa forma de gravação não é muito eficaz
[ em termos de desempenho ] , mas é muito conveniente.
Em 11l, a entrada correspondente a esta linha
[ e obtida pelo transportador Python → 11l ] não
é apenas conveniente
[ no entanto, não é tão elegante quanto em Python ] , mas também é rápida:
var tag = switch prev_char() {'*' {'b'}; '_' {'u'}; '-' {'s'}; '~' {'i'}}
A linha acima é traduzida em:
auto tag = [&](const auto &a){return a == u'*' ? u'b'_C : a == u'_' ? u'u'_C : a == u'-' ? u's'_C : a == u'~' ? u'i'_C : throw KeyError(a);}(prev_char());
[ A chamada de função lambda será compilada pelo compilador C ++ \ inline durante o processo de otimização e apenas a cadeia de operadores permanecerá ?/: ]No caso em que uma variável é atribuída, o dicionário é deixado como está:
Capture \ Cature variáveis externas
No Python, para indicar que a variável não é local, mas deve ser usada fora
[ da função atual ] , a palavra-chave não-local é usada
[ caso contrário, por exemplo, found = True será tratada como a criação de uma nova variável local found , em vez de atribuir um valor já variável externa existente ] .
Em 11l, o prefixo @ é usado para isso:
C ++:
auto writepos = 0; auto write_to_pos = [..., &outfile, &writepos](const auto &pos, const auto &npos) { outfile.write(...); writepos = npos; };
Variáveis globais
Semelhante às variáveis externas, se você esquecer de declarar uma variável global em Python
[ usando a palavra-chave global ] , receberá um erro invisível:
O código 11l
[ direita ] , diferentemente do Python
[ esquerda ], break_label_index erro 'variável não declarada
break_label_index ' no
break_label_index compilação.
Índice / número do item atual do contêiner
Eu continuo esquecendo a ordem das variáveis que a função Python
enumerate retorna {o valor vem primeiro, depois o índice ou vice-versa}. O comportamento analógico no Ruby -
each.with_index - é muito mais fácil de lembrar: com index significa que o índice vem após o valor, não antes. Mas em 11l, a lógica é ainda mais fácil de lembrar:
Desempenho
O
programa para converter a marcação de PC em HTML é usado como um
programa de teste e o código-fonte do
artigo sobre marcação de PC é usado como dados de origem
[ já que este artigo é atualmente o maior dos escritos na marcação de PC ] e é repetido 10 vezes, ou seja, obtido a partir de 48,8 KB de tamanho de arquivo de artigo 488Kb.
Aqui está um diagrama mostrando quantas vezes a maneira correspondente de executar o código Python é mais rápida que a implementação original
[ CPython ] :
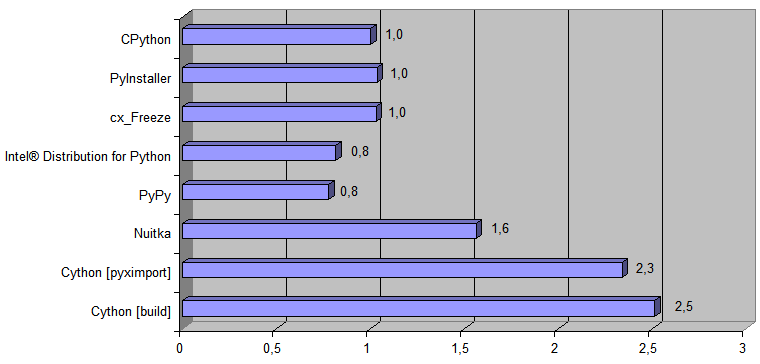
E agora adicione ao diagrama a implementação gerada pelo transpilador Python → 11l → C ++: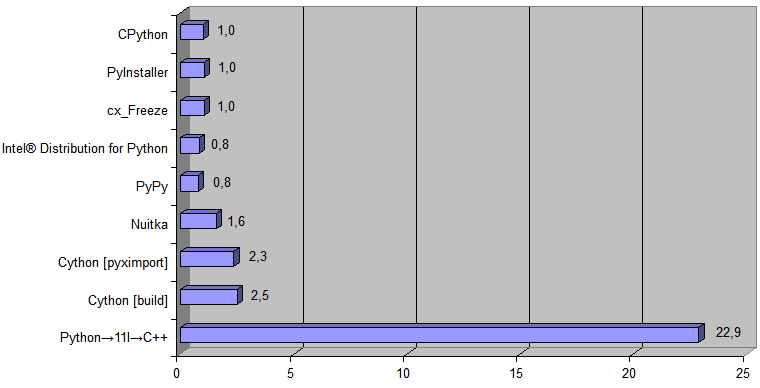
O tempo de execução
[ tempo de conversão do arquivo de 488Kb ] foi de 868 ms para o CPython e 38 ms para o código C ++ gerado
[ desta vez inclui o pleno direito [ isto é não apenas trabalhando com dados na RAM ] executando o programa pelo sistema operacional e todas as entradas / saídas [ lendo o arquivo de origem [ .pq ] e salvando o novo arquivo [ .html ] no disco ] ] .
Eu também queria experimentar o
Shed Skin , mas ele não suporta funções locais.
O Numba também não pôde ser usado (gera um erro 'Uso de código de operação desconhecido LOAD_BUILD_CLASS').
Aqui está o arquivo com o programa usado para comparar o desempenho
[ no Windows ] (requer Python 3.6 ou superior e os seguintes pacotes Python: pywin32, cython).
Código-fonte em Python e saída de transpilers de Python -> 11l e 11l -> C ++: