Exemplos de reconstrução de um fragmento de vídeo compactado por diferentes codecs com aproximadamente o mesmo valor BPP (bits por pixel). Resultados comparativos dos testes, veja em catPesquisadores da WaveOne
afirmam estar perto de uma revolução na compactação de vídeo. Ao processar vídeo em alta definição 1080p, o
novo codec de aprendizado de máquina compacta o vídeo cerca de 20% melhor do que os codecs de vídeo tradicionais mais modernos, como o H.265 e o VP9. E em um vídeo de "definição padrão" (SD / VGA, 640 × 480), a diferença chega a 60%.
Os desenvolvedores chamam os métodos atuais de compactação de vídeo, implementados no H.265 e VP9, de "antigos" de acordo com os padrões das tecnologias modernas: "Nos últimos 20 anos, os fundamentos dos algoritmos de compactação de vídeo existentes não mudaram significativamente", escrevem os autores do artigo científico na introdução de seu artigo. "Embora sejam muito bem projetados e ajustados com cuidado, eles permanecem codificados e, como tal, não podem se adaptar à demanda crescente e a uma gama cada vez mais versátil de aplicativos para materiais de vídeo, que incluem compartilhamento de mídia social, detecção de objetos, streaming de realidade virtual e assim por diante".
O uso do aprendizado de máquina deve finalmente trazer a tecnologia de compressão de vídeo para o século XXI. O novo algoritmo de compactação é significativamente superior aos codecs de vídeo existentes. "Até onde sabemos, este é o primeiro método de aprendizado de máquina que mostrou esse resultado", dizem eles.
A idéia principal da compactação de vídeo é remover dados redundantes e substituí-los por uma descrição mais curta que permita reproduzir o vídeo posteriormente. A maior parte da compactação de vídeo ocorre em dois estágios.
O primeiro estágio é a compactação de movimento, quando o codec procura objetos em movimento e tenta prever onde eles estarão no próximo quadro. Em seguida, em vez de registrar os pixels associados a esse objeto em movimento, em cada quadro, o algoritmo codifica apenas a forma do objeto e a direção do movimento. De fato, alguns algoritmos analisam os quadros futuros para determinar o movimento com mais precisão, embora isso obviamente não funcione para transmissões ao vivo.
A segunda etapa de compactação remove outras redundâncias entre um quadro e o próximo. Portanto, em vez de registrar a cor de cada pixel no céu azul, o algoritmo de compactação pode determinar a área dessa cor e indicar que ela não muda nos próximos quadros. Assim, esses pixels permanecem da mesma cor até que sejam solicitados a mudar. Isso é chamado de compressão residual.
A nova abordagem que os cientistas introduziram usa o aprendizado de máquina pela primeira vez para melhorar esses dois métodos de compressão. Portanto, ao comprimir o movimento, os métodos de aprendizado de máquina da equipe encontraram novas redundâncias com base no movimento, que os codecs convencionais nunca foram capazes de detectar e muito menos uso. Por exemplo, virar a cabeça de uma pessoa de uma vista frontal para um perfil sempre dá um resultado semelhante: "Os codecs tradicionais não podem prever o perfil de uma pessoa com base em uma vista frontal", escrevem os autores do artigo científico. Pelo contrário, o novo codec estuda esses tipos de padrões espaço-temporais e os utiliza para prever quadros futuros.
Outro problema é a alocação de largura de banda disponível entre movimento e compactação residual. Em algumas cenas, a compressão de movimento é mais importante, enquanto em outras, a compressão residual fornece o maior ganho. O compromisso ideal entre eles difere de quadro para quadro.
Os algoritmos tradicionais processam os dois processos separadamente um do outro. Isso significa que não há uma maneira fácil de dar vantagem a uma ou a outra e encontrar um compromisso.
Os autores contornam isso compactando os dois sinais ao mesmo tempo e, com base na complexidade do quadro, determinam como distribuir a largura de banda entre os dois sinais da maneira mais eficiente.
Essas e outras melhorias permitiram que os pesquisadores criassem um algoritmo de compactação que ultrapassasse em muito os codecs tradicionais (consulte os benchmarks abaixo).
 Exemplos de reconstrução de um fragmento compactado por diferentes codecs com aproximadamente o mesmo valor de BPP mostram uma vantagem significativa do codec WaveOne
Exemplos de reconstrução de um fragmento compactado por diferentes codecs com aproximadamente o mesmo valor de BPP mostram uma vantagem significativa do codec WaveOne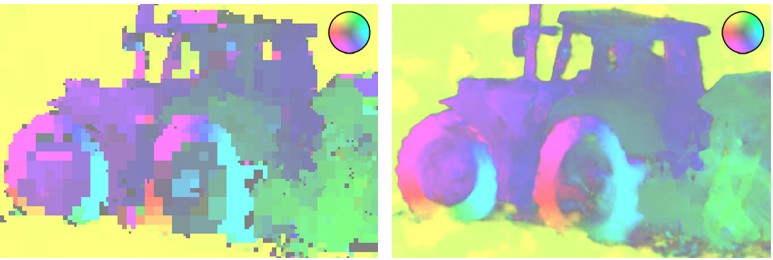 Cartões de fluxo óptico H.265 (à esquerda) e codec WaveOne (à direita) com a mesma taxa de bits
Cartões de fluxo óptico H.265 (à esquerda) e codec WaveOne (à direita) com a mesma taxa de bitsNo entanto, a nova abordagem não deixa de ter algumas desvantagens,
observa a MIT Technology Review . Talvez a principal desvantagem seja a baixa eficiência computacional, ou seja, o tempo necessário para codificar e decodificar o vídeo. Na plataforma Nvidia Tesla V100 e em vídeo do tamanho VGA, o novo decodificador trabalha a uma velocidade média de cerca de 10 quadros por segundo, e o codificador a uma velocidade de cerca de 2 quadros por segundo. Essas velocidades são simplesmente impossíveis de usar nas transmissões de vídeo ao vivo e, com a codificação offline de materiais, o novo codificador terá um escopo muito limitado.
Além disso, a velocidade do decodificador não é suficiente para
assistir a um vídeo compactado com esse codec em um computador pessoal comum. Ou seja, para assistir a esses vídeos, mesmo com qualidade SD mínima, é necessário um cluster de computação inteiro com vários aceleradores gráficos. E para assistir vídeo em qualidade HD (1080p), você precisa de um conjunto completo de computadores.
Só podemos esperar um aumento no poder dos processadores gráficos no futuro e melhorar a tecnologia: "A velocidade atual não é suficiente para implantação em tempo real, mas deve ser significativamente aprimorada em trabalhos futuros", escrevem eles.
Benchmarks
HEVC/H.265, AVC/H.264, VP9 HEVC HM 16.0 . Ffmpeg, — . , . , B- H.264/5
bframes=0,
-auto-alt-ref 0 -lag-in-frames 0 . MS-SSIM, ,
-ssim.
SD HD, . SD- VGA e Consumer Digital Video Library (CDVL). 34 15 650 . HD Xiph 1080p: 22 11 680 . 1080p 1024 ( , 32 ).
:
- MS-SSIM ;
- MS-SSIM ;
- WaveOne ( ).
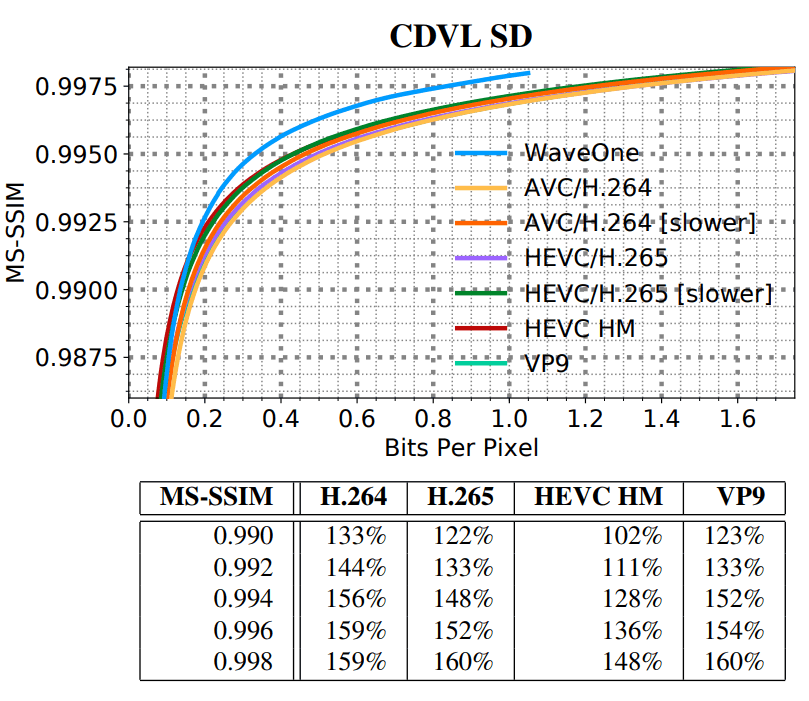 (SD)
(SD)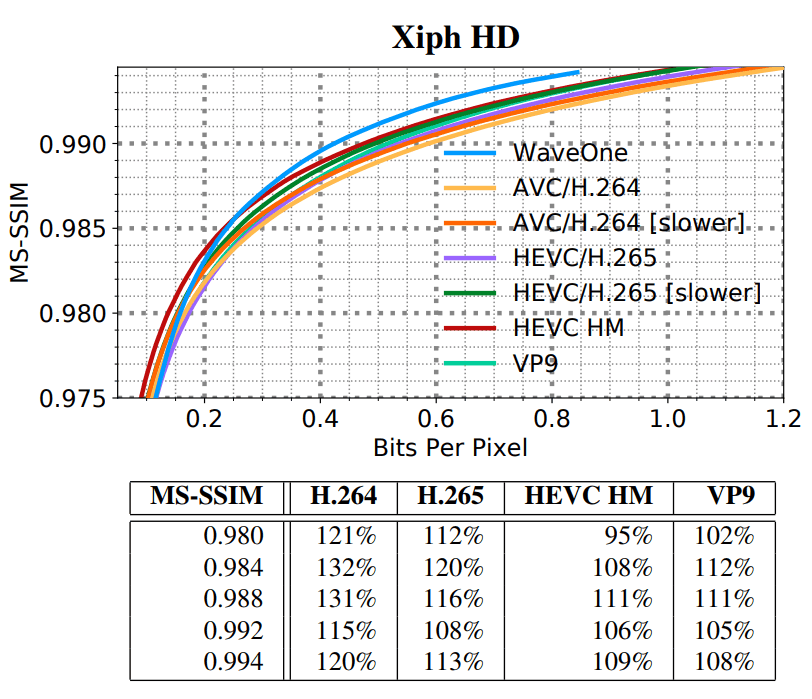 (HD)
(HD)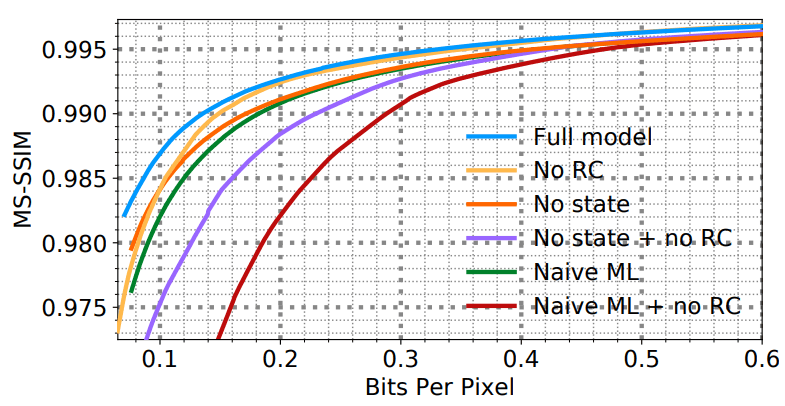 WaveOne
WaveOne. , . . , . G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar.
Variable rate image compression with recurrent neural networks, 2015; G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, M. Covell.
Full resolution image compression with recurrent neural networks, 2016; J. Balle, V. Laparra, E. P. Simoncelli.
End-to-end optimized image compression, 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, G. Toderici.
Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks, 2017 . , , .
ML- , . . . C.-Y. Wu, N. Singhal, and P. Krahenbuhl.
Video compression through image interpolation, ECCV (2018). , . AVC/H.264. , .
« » 16 2018 arXiv.org (arXiv:1811.06981). — (Oren Rippel), (Sanjay Nair), (Carissa Lew), (Steve Branson), (Alexander G. Anderson), (Lubomir Bourdev).
Stas911:
Altaisky: . ?
Stas911: . .