
Um projeto típico de integração de sistemas para nós se parece com isso: o cliente possui um transporte de sistemas para clientes de contabilidade, a tarefa é coletar cartões de clientes em um único banco de dados. E não apenas para coletar, mas também para limpar duplicatas e lixo. Para obter cartões de cliente limpos, estruturados e completos.
Para iniciantes, explicarei que a migração ocorre de acordo com este esquema:
fontes → conversão de dados (respostas ETL ou bus ) → receptor .
Em um projeto, perdemos três meses simplesmente porque uma equipe de integradores de terceiros não estudou os dados nos sistemas de origem. A coisa mais irritante era que isso poderia ter sido evitado.
Eles trabalharam assim:
- Os integradores de sistemas personalizam o processo ETL.
- O ETL transforma os dados de origem e os fornece para mim.
- Estudo descarga e envio erros aos integradores.
- Os integradores corrigem ETLs e iniciam a migração novamente.
No artigo, mostrarei como analisar dados durante a integração do sistema. Estudei uploads de ETL, foi muito útil. Mas nos dados de origem, as mesmas técnicas acelerariam o trabalho duas vezes.
As dicas serão úteis para testadores, implementadores de produtos corporativos, integradores de sistemas e analistas. As recepções são universais para bancos de dados relacionais e são totalmente divulgadas em volumes de um milhão de clientes.
Mas primeiro, sobre um dos principais mitos da integração de sistemas.
A documentação e o arquiteto ajudarão (na verdade não)
Os integradores geralmente não estudam dados antes da migração - eles economizam tempo. Eles leem a documentação, examinam a estrutura, conversam com o arquiteto - e isso é o suficiente. Depois disso, eles já estão planejando a integração.
Acontece ruim. Somente a análise mostrará o que realmente está acontecendo no banco de dados. Se você não acessar os dados com mangas arregaçadas e uma lupa, a migração será incorreta.
A documentação está mentindo. Um sistema corporativo típico dura de 5 a 20 anos. Todos esses anos, as mudanças foram documentadas por vários departamentos e contratados. Cada um com sua própria torre sineira. Portanto, não há integridade na documentação, ninguém entende completamente a lógica e a estrutura do armazenamento de dados. Sem mencionar que os prazos estão sempre ativos e não há tempo suficiente para a documentação.
Uma história comum: na tabela de clientes, há um campo "SNILS", no papel é muito importante. Mas quando olho para os dados, vejo - o campo está vazio. Como resultado, o cliente concorda que a base de destino ficará sem um campo para SNILS, pois ainda não há dados.
Um caso especial de documentação são regulamentos e descrições de processos de negócios: como os dados entram no banco de dados, sob quais circunstâncias e em que formato. Tudo isso também não ajudará.
Os processos de negócios são perfeitos apenas no papel. De manhã cedo, a sonolenta operadora Anatoly entra no escritório do banco nos arredores de Vyksa. Debaixo da janela, eles gritaram a noite toda, e pela manhã Anatoly brigou com a garota. Ele odeia o mundo inteiro.
Os nervos ainda não foram colocados em ordem e o Anatoly direciona inteiramente o nome do novo cliente para o campo de sobrenome. Ele se esquece completamente de seu aniversário - o padrão "01.01.1900 g" permanece no formulário. Eu não dou a mínima para as regras quando tudo ao redor é tão enfurecedor !!!
O caos conquista processos de negócios, muito bem proporcionados no papel.
Um arquiteto de sistema não sabe tudo. Trata-se novamente da venerável vida útil dos sistemas corporativos. Ao longo dos anos em que trabalham, os arquitetos mudaram. Mesmo se você conversar com o atual, as decisões das anteriores serão surpreendentes durante o projeto.
E lembre-se: mesmo um arquiteto agradável, em todos os aspectos, manterá em segredo suas fraudes e muletas do sistema.
A integração "por instrumentos" sem análise de dados é um erro. Mostrarei como nós da HFLabs aprendemos os dados através da integração do sistema. No último projeto, analisei apenas os uploads de ETL. Mas quando o cliente dá acesso aos dados de origem, eu definitivamente os verifico de acordo com os mesmos princípios.
Campos preenchidos e valores nulos
As verificações mais simples estão na integridade das tabelas como um todo e na integridade de campos individuais. Estou começando com eles.
Quantas linhas totais estão na tabela. A solicitação mais simples possível.
SELECT COUNT(*) FROM <table_name>;
Eu recebo o primeiro resultado.
Aqui eu olho para a adequação dos dados. Se apenas dois milhões de clientes chegaram à descarga de um grande banco, então algo está claramente errado. Mas enquanto tudo parece como o esperado, seguindo em frente.
Quantas linhas são preenchidas para cada campo separadamente. Verifico todas as colunas da tabela.
SELECT <column_name>, COUNT(*) AS <column_name> cnt FROM <table_name> WHERE <column_name> IS NOT NULL;
O primeiro se deparou com um campo de feliz aniversário e imediatamente curioso: por algum motivo, os dados não chegaram a todos.
Se todos os valores no campo são "NULL" no upload, a primeira coisa que vejo é o sistema de origem. Talvez os dados sejam armazenados lá corretamente, mas eles foram perdidos durante a migração.
Vejo que no sistema de origem existem aniversários. Eu vou para os integradores: pessoal, erro. Verificou-se que, no processo ETL, a função de decodificação funcionava incorretamente. O código foi corrigido. No próximo upload, verificaremos as alterações.
Eu vou mais longe no campo com o TIN.
Existem 100 milhões de pessoas no banco de dados e apenas 65 mil são preenchidas com NIFs - ou seja, 0,07%. Uma ocupação tão fraca é um sinal de que o campo na base do receptor pode não ser necessário.
Verifico o sistema de origem, está tudo correto: os NIFs são semelhantes aos atuais, mas quase não existem. Portanto, não se trata de migração. Resta descobrir se o cliente precisa de um campo quase vazio sob o NIF no banco de dados de destino.
Cheguei ao sinalizador de remoção do cliente.
Os sinalizadores estão vazios. Mas o que, a empresa não remove clientes? Eu olho para o sistema de origem, converso com o cliente. Acontece que sim: a bandeira é formal, em vez de excluir clientes, suas contas são excluídas. Nenhuma conta - como se o cliente tivesse sido excluído.
No sistema de destino, é necessário o sinalizador de cliente remoto, esse é um recurso da arquitetura. Portanto, se o cliente tiver zero contas no sistema receptor, ele precisará ser fechado por meio de lógica adicional ou nem importado. Então, como o cliente decide.
Em seguida é a placa de endereço. Geralmente, algo está errado com essas tabelas, porque os endereços são complicados, eles são inseridos de maneiras diferentes.
Verifico a integridade dos componentes do endereço.
Os endereços não são preenchidos de maneira uniforme, mas é muito cedo para tirar conclusões: primeiro perguntarei ao cliente para que ele serve. Se a segmentação por país estiver correta, há dados suficientes. Se para listas de discussão, o problema é: as casas estão quase vazias, não há apartamentos.
Como resultado, o cliente viu que o ETL estava recebendo endereços de um tablet antigo e irrelevante. Ela está na base como um monumento. Mas há outra tabela, nova e boa, os dados devem ser retirados dela.
Durante a análise, preencheu os campos vinculados aos diretórios com particularidade. A condição "IS NOT NULL" não funciona com eles: em vez de "NULL", a célula geralmente é "0". Portanto, verifique os campos de referência separadamente.
Mudanças no preenchimento de campos. Portanto, verifiquei a ocupação geral e a ocupação de cada campo. Problemas encontrados, integradores corrigiram o processo ETL e iniciaram a migração novamente.
Executo o segundo descarregamento para todas as etapas listadas acima. Eu escrevo estatísticas no mesmo arquivo para ver as alterações.
Completude de todos os campos.
Entre os envios, 5 milhões de registros desapareceram. Vou aos integradores, faço perguntas típicas:
- “Por que os registros foram perdidos?”;
- "Quais dados foram rastreados?";
- "Quais dados você deixou?"
Acontece que não há problema: eles simplesmente removeram os clientes "técnicos" da nova descarga. Eles estão no banco de dados para testes, não são pessoas vivas. Mas com a mesma probabilidade, os dados podem ser perdidos por engano, isso acontece.
Mas os aniversários da nova descarga apareceram, como eu esperava.
Mas! Não é necessariamente bom quando dados ausentes anteriormente apareceram repentinamente em um novo upload. Por exemplo, os aniversários podem ser preenchidos com datas padrão - não há nada para se alegrar. Portanto, eu sempre verifico quais dados vieram.
O que verificar, em poucas palavras.
- O número total de entradas nas tabelas. Essa quantidade é adequada às expectativas?
- O número de linhas preenchidas em cada campo.
- A proporção do número de linhas preenchidas em cada campo para o número de linhas na tabela. Se for muito pequeno, é uma ocasião para pensar em arrastar o campo para a base de destino.
Repita as três primeiras etapas para cada upload. Siga a dinâmica: onde e por que aumentou ou diminuiu.Comprimento dos valores nos campos de sequência
Sigo uma das regras básicas de teste - verifico os valores dos limites.
Quais valores são muito curtos. Entre os valores mais curtos está o lixo, por isso é interessante cavar aqui.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) < 3;
Dessa forma, verifico o nome, número de telefone, TIN, OKVED, endereços de sites. Um absurdo aparece como "A * 1", "0", "11", "-" e "...".
Está tudo bem com os valores máximos. O campo Fechar é um marcador do fato de que os dados não se ajustaram durante a transferência e foram cortados automaticamente. O MySQL resolve isso de maneira famosa sem aviso prévio. Ao mesmo tempo, parece que a migração ocorreu sem problemas.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) = 65;
Dessa forma, encontrei no campo com o tipo de documento a linha "Certificado de registro do pedido de reconhecimento do imigrante". Ela disse aos integradores que o comprimento do campo foi corrigido.
Como os valores são distribuídos ao longo do comprimento. Nos HFLabs, chamamos a tabela de distribuição de comprimento para as linhas.
SELECT LENGTH(<column_name>), COUNT(<column_name>) FROM <table_name> GROUP BY LENGTH(<column_name>);
Aqui, procuro anomalias na distribuição ao longo do comprimento. Por exemplo, aqui está uma frequência para uma tabela com endereços para correspondência.
Valores com um comprimento de 125 são muitos. Olho para o banco de dados de origem e acho que, por algum motivo, alguns dos endereços foram cortados para 125 caracteres há três anos. Em outros anos, está tudo bem. Eu vou com esse problema para o cliente e integradores, entendemos.
O que verificar, em poucas palavras.
- Os valores mais curtos nos campos de sequência. Muitas vezes, linhas com menos de três caracteres são lixo.
- Valores que se limitam ao longo da largura do campo. Muitas vezes eles são circuncidados.
- Anomalias na distribuição de linhas ao longo do comprimento.
Valores Populares
Divido em três categorias os valores que se enquadram no top popular:
- muito comum , como o nome "Tatyana" ou o nome do meio "Vladimirovich". Aqui deve ser lembrado que, no caso geral, Tatyana não deve ser 100 vezes mais popular que Anna e Ismail dificilmente pode ser mais popular que Egor;
- lixo , como ".", "1", "-" e similares;
- Padrão no formulário de entrada, como "01/01/1900" para datas.
Dois em cada três casos são marcadores do problema, é útil procurá-los.
Eu procuro valores populares em três tipos de campos:
- Campos de string comuns.
- Campos da string de referência. Esses são campos de string comuns, mas é claro que o número de valores diferentes neles é regulado. Esses campos armazenam países, cidades, meses, tipos de telefone.
- Campos do classificador - eles contêm um link para uma entrada em uma tabela do classificador de terceiros.
Estudo os campos de cada um desses tipos de maneira um pouco diferente.
Para campos de sequência - quais são os 100 principais valores populares. Se você quiser, pode pegar mais, mas nos primeiros cem valores todas as anomalias são geralmente colocadas.
SELECT * FROM (SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC) WHERE ROWNUM <= 100;
Verifico os campos desta maneira:
- Nome completo, bem como sobrenomes, nomes e patronímicos separados;
- datas de nascimento e geralmente quaisquer datas;
- endereços O endereço completo e seus componentes individuais, se eles estiverem armazenados no banco de dados;
- Telefones
- série, número, tipo, local de emissão dos documentos.
Quase sempre entre os populares - valores padrão e de teste, alguns stubs.

Acontece que o problema encontrado não é um problema. Certa vez, encontrei um número de telefone suspeito e popular no banco de dados. Os clientes indicaram esse número como trabalhador e, no banco de dados, havia simplesmente muitos funcionários de uma organização.
Ao longo do caminho, essa análise mostrará campos de referência ocultos. Logicamente, esses campos não devem ser diretórios, mas na verdade eles estão no banco de dados. Por exemplo, seleciono valores populares no campo "Posição" e existem apenas cinco deles.
Talvez a empresa atenda apenas cinco profissões. Não é muito verdade, certo? Em vez disso, no formulário para os operadores, em vez de uma linha, eles criaram um diretório e esqueceram de despejar valores. A questão importante aqui é: é aconselhável preencher posts através do diretório? Assim, através da análise de dados, resolvo possíveis problemas com o software do operador.
Para campos de referência e classificadores, verifico a popularidade de todos os valores. Para começar, descubro quais campos são diretórios. Você não pode se dar bem com scripts, eu pego a documentação e finjo que sou. Normalmente, os diretórios são criados para valores, cujo número é claro e relativamente pequeno:
- países
- línguas
- moedas
- meses
- a cidade
Em um mundo ideal, o conteúdo dos campos de referência é claro e consistente. Mas nosso mundo não é assim, então eu verifico com um pedido.
SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC;
Geralmente, nos campos de string dos diretórios, fica isso.
Problemas comuns:
- erros de digitação;
- espaços
- caso diferente.
Tendo encontrado uma bagunça, vou aos integradores com exemplos à mão. Deixe-os deixar lixo na fonte e elimine as discrepâncias. Então, no banco de dados de destino, por rigor, será possível transformar as linhas de referência em classificadores.
Verifico os valores populares nos campos do classificador para detectar a falta de opções. Diante de tais casos.
Esses classificadores parecem muito estranhos, devem ser mostrados ao cliente. Toda vez que havia um erro por trás desses casos: algo estava errado no banco de dados ou os dados foram baixados do local errado.
O que verificar, em poucas palavras.
- Quais campos de sequência são referência e quais não são.
- Para campos de sequência simples, os principais valores populares. Geralmente no lixo superior e nos dados padrão.
- Para campos de referência de cadeia, a distribuição de todos os valores por popularidade. A seleção mostrará discrepâncias nos valores de referência.
- Para classificadores - existem opções suficientes no banco de dados.
Consistência e reconciliação cruzada
A partir da análise de dados dentro de tabelas, recorro à análise de relacionamentos.
Se os dados devem estar relacionados. Chamamos esse parâmetro de "consistência". Pego a mesa subordinada, por exemplo, com telefones. Para ele em um par - a tabela pai de clientes. E vejo quantos clientes na tabela subordinada são identificadores que não estão no pai.
SELECT COUNT(*) FROM ((SELECT <ID1> FROM <table_name_1>) MINUS (SELECT <ID2> FROM <table_name_2>));
Se a solicitação deu um delta, isso significa que não há sorte - há dados não relacionados no upload. Então eu checo as tabelas com telefones, contratos, endereços, contas e assim por diante. Uma vez, durante um projeto, ela encontrou 23 milhões de números que simplesmente pairavam no ar.
Também funciona na direção oposta - procuro clientes que, por algum motivo, não tenham um único contrato, endereço e número de telefone. Às vezes, tudo bem - bem, o cliente não tem um endereço. Aqui você precisa descobrir com o cliente, a documentação enganará facilmente.
Existem duplicações de chaves primárias em tabelas diferentes. Às vezes, entidades idênticas são armazenadas em tabelas diferentes. Por exemplo, clientes heterossexuais. (Ninguém sabe o motivo, porque Brezhnev ainda reivindicou a estrutura.) Mas a tabela no receptor é única e, ao migrar, os identificadores de clientes entram em conflito.
Viro a cabeça e olho para a estrutura da base: onde é possível a fragmentação de entidades semelhantes. Pode ser tabelas de clientes, telefones de contato, passaportes e assim por diante.
Se houver várias tabelas com entidades semelhantes, faço uma verificação cruzada: verifico a interseção de identificadores. Interseção - cole um adesivo. Por exemplo, coletamos identificadores para uma única tabela de acordo com o esquema "nome da tabela de origem + ID".
O que verificar, em poucas palavras.
- Quantos dados não relacionados existem em tabelas vinculadas.
- Existem possíveis conflitos de chave primária?
O que mais para verificar
Existem caracteres latinos nos quais eles não pertencem. Por exemplo, sobrenomes.
SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[AZ]', 'i');
Então eu pego a maravilhosa letra latina "C", que coincide com a cirílica. O erro é desagradável, porque de acordo com o nome com o latim "C" o operador nunca encontrará um cliente.
Existem caracteres estranhos nos campos de string destinados a números? SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[^0-9]');
Os problemas aparecem nos campos com o número do passaporte da Federação Russa ou TIN. Os telefones são os mesmos, mas eu permito mais, colchetes e hífens. A solicitação também revelará a letra "O", que foi definida em vez de zero.
Quão adequados são os dados. Você nunca sabe onde o problema surgirá, por isso estou sempre em guarda. Eu conheci esses casos:
- Sofya Vladimirovna é um cliente com 50.000 telefones - isso é normal? Resposta: não normal. O cliente é técnico, eles colocam números de telefone "sem dono" nele para enviar mensagens sms. Não é necessário puxar o cliente para uma nova base;
- O número de identificação do contribuinte é preenchido; na verdade, a coluna contém "79853617764", "89109462345", "4956780966" e assim por diante. Que tipo de telefone, okuda? Cadê a pousada? Resposta: que tipo de números - não se sabe quem os colocou - não é claro. Ninguém os usa. O TIN atual é armazenado em outro campo de outra tabela, retirado de lá;
- o campo "endereço em uma linha" não corresponde aos campos em que o endereço está armazenado em partes. Por que os endereços são diferentes? Resposta: quando os operadores preencherem os endereços com uma linha e o sistema externo classificar os endereços em campos separados. Para segmentação. Com o passar do tempo, as pessoas mudaram de endereço. Os operadores os atualizavam regularmente, mas apenas como uma sequência: o endereço permanecia antigo em partes.
Tudo que você precisa é SQL e Excel
Para analisar dados, não é necessário um software caro. Excel suficiente e antigo e conhecimento de SQL.
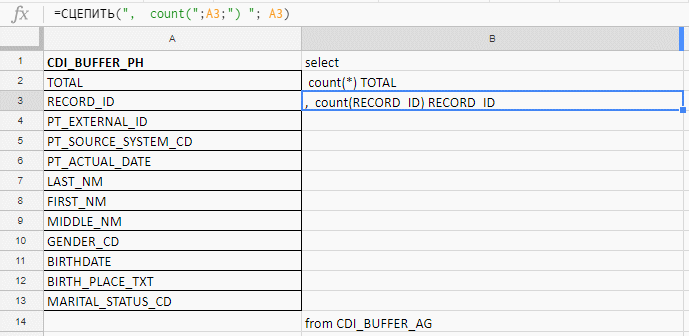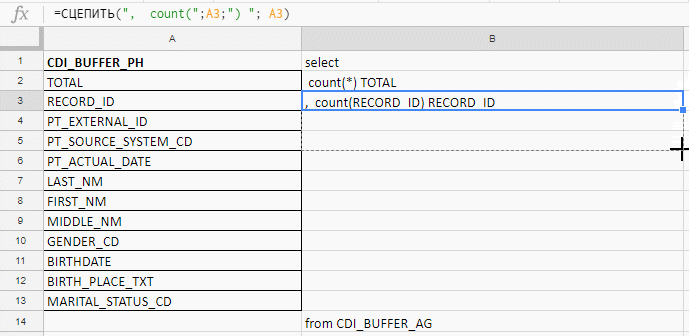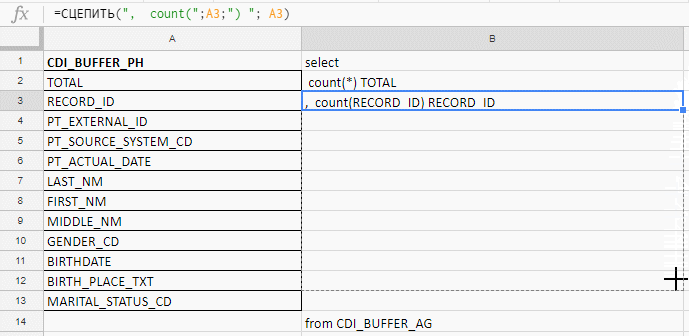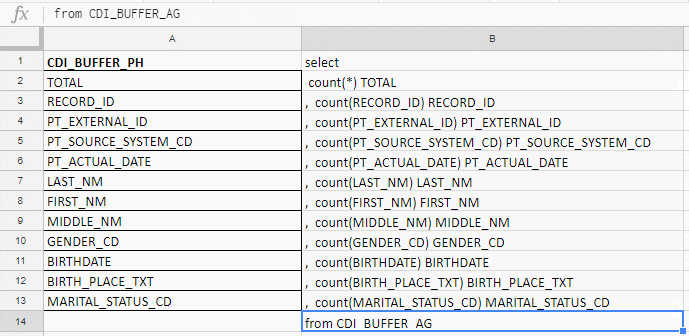
Excel que eu uso para compilar uma consulta longa. Por exemplo, verifico se os campos estão completos e há 140. Na tabela, escreverei com as mãos antes da conspiração da cenoura, para coletar a solicitação com as fórmulas no excel-plate.
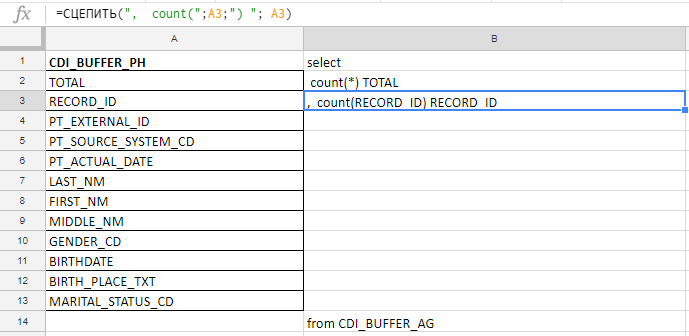 Na coluna “A”, insiro os nomes dos campos, os levo na documentação ou nas tabelas de serviço. Na coluna "B" - uma fórmula para colar uma solicitação
Na coluna “A”, insiro os nomes dos campos, os levo na documentação ou nas tabelas de serviço. Na coluna "B" - uma fórmula para colar uma solicitaçãoEu insiro os nomes dos campos, escrevo a primeira fórmula na coluna "B", puxo a esquina - e pronto.
 Funciona no Excel, no Google Docs e no Excel Online (disponível no Yandex.Disk)
Funciona no Excel, no Google Docs e no Excel Online (disponível no Yandex.Disk)A análise de dados economiza o tempo e os nervos dos gerentes. Com isso, é mais fácil cumprir o prazo. Se o projeto for grande, a análise economizará milhões de rublos e uma reputação.
Não números, mas conclusões
Ela formulou uma regra para si mesma: para não mostrar números simples para o cliente, você ainda não terá o efeito. Minha tarefa é analisar os dados e tirar conclusões e anexar os números como evidência. As conclusões são primárias, os números são secundários.
O que eu coleciono para o relatório:
- a redação dos problemas na forma de uma hipótese ou pergunta : “O NTI é preenchido em 0,07%. Como você usa esses dados, qual é a relevância, como interpretá-los? Existe apenas um DCI em uma tabela? ” Você não pode culpar: "O seu NIF não está cheio." Em resposta, você receberá apenas agressão;
- exemplos de problemas. Essas são as tábuas das quais existem tantas no artigo;
- Opções de como fazê-lo: "Pode valer a pena remover o NIF da base de destino para não produzir campos vazios".
Não tenho o direito de decidir o que exatamente escolher no banco de dados de origem e como alterar os dados durante a migração. Portanto, com o relatório, vou ao cliente ou aos integradores e descobrimos como proceder.
Às vezes, o cliente, vendo o problema, responde: “Não se preocupe, não preste atenção. Compraremos um terabyte extra de memória, só isso. É mais barato do que otimizar. " Você não pode concordar com isso: se você pegar tudo em sequência, não haverá qualidade no receptor. Todos os mesmos dados redundantes de lixo estão sendo migrados.
Portanto, pedimos gentilmente, mas com firmeza: "Diga-nos como você usará esses dados específicos no sistema de destino". Não "por que você precisa", ou seja, "como você usará". As respostas "então apresentaremos" ou "apenas no caso" não são adequadas. Cedo ou tarde, o cliente entende quais dados podem ser dispensados.
O principal é encontrar e resolver todos os problemas até que o sistema seja lançado no prod. Para mudar a arquitetura e o modelo de dados em tempo real, você ficará louco.
Isso é tudo com verificações básicas, estude os dados!