Sobre o jogo Revenge de Montezuma em Habré, não foi escrito muito. Este é um jogo clássico complexo que antes era muito popular, mas agora é jogado por aqueles com quem evoca sentimentos nostálgicos ou por pesquisadores que desenvolvem IA.
Neste verão, foi
relatado que o DeepMind foi capaz de ensinar sua IA a jogar pela Atari, incluindo a Revenge de Montezuma. Usando o exemplo do mesmo jogo, os criadores do OpenAI também
ensinaram seu desenvolvimento. Agora, o Uber assumiu um projeto semelhante.
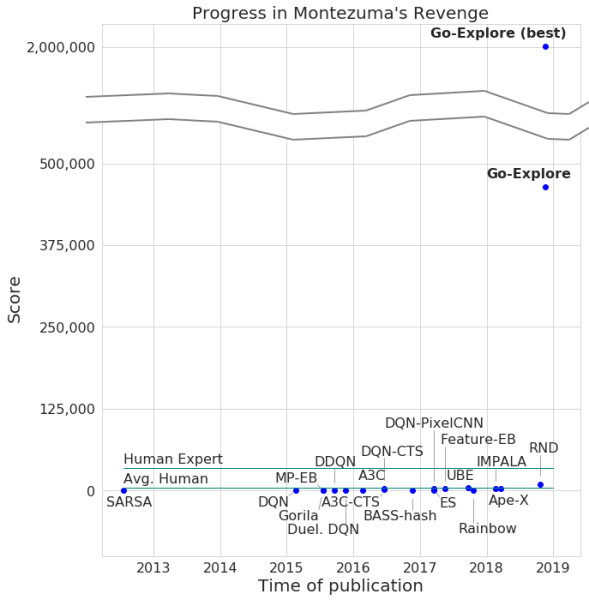
Os desenvolvedores anunciaram a passagem do jogo por sua rede neural, com um número máximo de pontos de 2 milhões.Realmente, em média, o sistema ganhou não mais que 400.000 por cada tentativa. Quanto à passagem, o computador atingiu o nível 159.
Além disso, o Go-Explore aprendeu como passar pelo Pitfall, com um excelente resultado que é superior ao jogador médio, sem mencionar outros agentes de IA. O número de pontos marcados pelo Go-Explore neste jogo é 21.000.
A diferença entre o Go-Explore e seus "colegas" é que as redes neurais não precisam demonstrar a passagem de diferentes níveis de treinamento. O sistema aprende tudo sozinho durante o jogo, mostrando resultados muito superiores aos demonstrados pelas redes neurais que requerem treinamento visual. De acordo com os desenvolvedores do Go-Explore, a tecnologia é significativamente diferente de todas as outras, e seus recursos permitem o uso de uma rede neural em várias áreas, incluindo a robótica.
A maioria dos algoritmos acha difícil lidar com a Vingança de Montezuma porque o jogo não tem feedback muito explícito. Por exemplo, uma rede neural que é "afiada" para receber recompensas no processo de passar de nível prefere lutar contra o inimigo do que pular em uma escada que leva à saída e permite avançar mais rapidamente. Outros sistemas de IA preferem receber uma recompensa aqui e agora, e não avançar na "esperança" de obter mais.
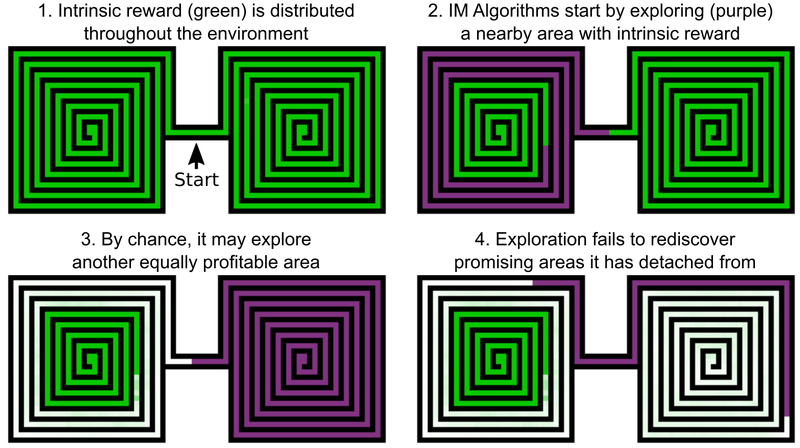
Uma das decisões dos engenheiros da Uber é adicionar bônus por explorar o mundo do jogo, isso pode ser chamado de motivação interna da IA. Mas mesmo os elementos de IA com motivação intrínseca adicional não se dão bem com Revenge and Pitfall, de Montezuma. O problema é que a IA "esquece" sobre locais promissores depois de passar por eles. Como resultado, o agente de IA fica preso em um nível em que tudo parece ter sido investigado.
Um exemplo é o agente de IA, que precisa estudar dois labirintos - leste e oeste. Ele começa a passar por um deles, mas de repente decide que seria possível passar pelo segundo. O primeiro permanece estudado em 50%, o segundo em 100%. E o agente não retorna ao primeiro labirinto - simplesmente porque ele "esqueceu" que ele não foi concluído até o fim. E já que a passagem entre o labirinto oriental e ocidental já foi estudada, a IA não tem motivação para retornar.
A solução para esse problema, de acordo com desenvolvedores do Uber, inclui duas etapas: pesquisa e amplificação. Quanto à primeira parte, aqui a IA cria um arquivo de vários estados do jogo - células (células) - e várias trajetórias que levam a eles. A AI escolhe a oportunidade de obter o número máximo de pontos ao detectar a trajetória ideal.
As células são quadros de jogo simplificados - 11 por 8 imagens em tons de cinza com intensidade de 8 pixels, com quadros que diferem o suficiente - para não impedir a passagem do jogo.

Como resultado, a AI lembra locais promissores e retorna a eles depois de examinar outras partes do mundo do jogo. O "desejo" de explorar o mundo do jogo e locais promissores no Go-Explore é mais forte do que o desejo de receber um prêmio aqui e agora. O Go-Explore também usa informações sobre as células nas quais o agente de IA é treinado. Para a Vingança de Montezuma, são dados de pixel, como as coordenadas X e Y, a sala atual e o número de chaves encontradas.
O estágio de amplificação funciona como uma proteção contra "ruído". Se as soluções de IA são instáveis ao "ruído", a IA as fortalece com a ajuda de uma rede neural de vários níveis, operando no exemplo de neurônios do cérebro humano.

Nos testes, o Go-Explore tem um desempenho muito bom - em média, a IA estuda 37 salas e resolve 65% dos quebra-cabeças de primeiro nível. Isso é muito melhor do que as tentativas anteriores de conquistar o jogo - então a IA estudou, em média, 22 salas do primeiro nível.

Ao adicionar ganho ao algoritmo existente, a IA começou a concluir com êxito em média 29 níveis (não salas) com uma pontuação média de 469,209.
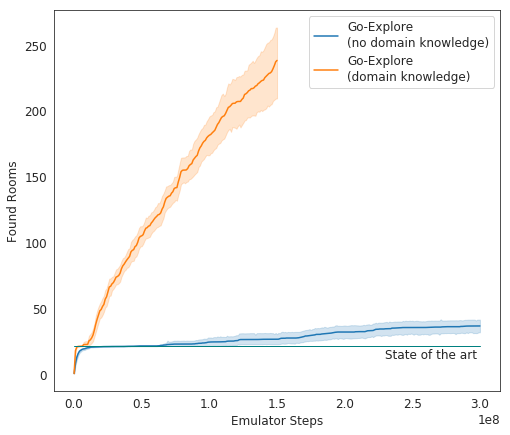
A encarnação final da IA do Uber começou a rodar o jogo muito melhor do que outros agentes da IA e melhor que os humanos. Agora, os desenvolvedores estão melhorando seu sistema para que ele mostre um resultado ainda mais impressionante.