Em 8 de novembro, no salão principal da conferência
HighLoad ++ 2018 , no âmbito da seção DevOps and Operations, foi elaborado um relatório intitulado Databases and Kubernetes. Ele fala sobre a alta disponibilidade de bancos de dados e abordagens para tolerância a falhas no Kubernetes e com ele, além de opções práticas para colocar o DBMS em clusters do Kubernetes e soluções existentes para isso (incluindo Stolon para PostgreSQL).

Por tradição, temos o prazer de apresentar um
vídeo com um relatório (cerca de uma hora,
muito mais informativo
que o artigo) e o aperto principal em forma de texto. Vamos lá!
Teoria
Este relatório apareceu como resposta a uma das perguntas mais populares que nos últimos anos nos foram feitas incansavelmente em diferentes lugares: comentários no hub ou no YouTube, redes sociais etc. Parece simples: “É possível executar o banco de dados no Kubernetes?”, E se geralmente respondemos “geralmente sim, mas ...”, claramente não havia explicação suficiente para esses “em geral” e “mas”, mas para ajustá-los em uma mensagem curta não teve sucesso.
No entanto, para começar, eu resumi o problema do "banco de dados [dados]" para o estado como um todo. Um DBMS é apenas um caso especial de decisões com estado, cuja lista mais completa pode ser representada da seguinte maneira:
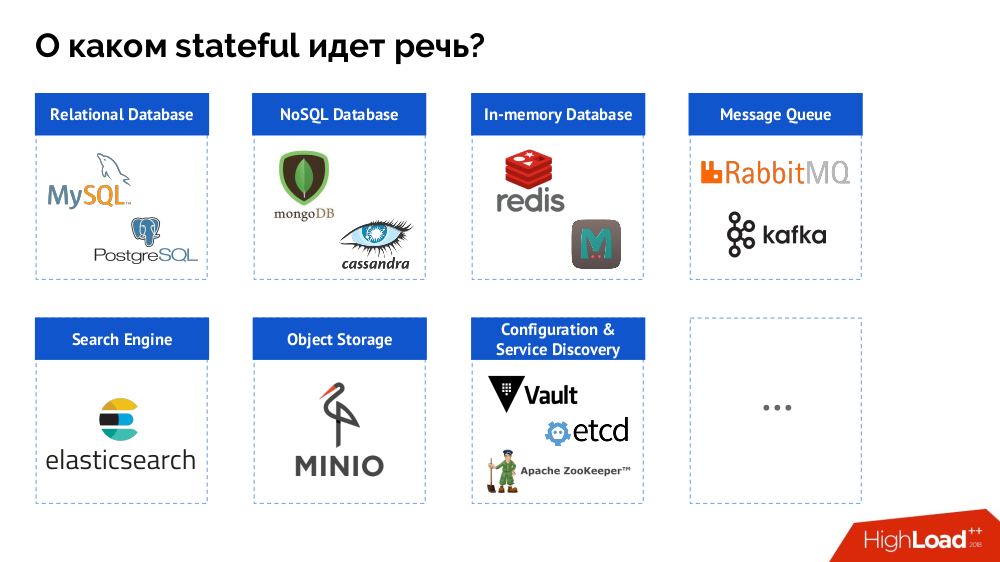
Antes de analisar casos específicos, falarei sobre três características importantes do trabalho / uso do Kubernetes.
1. Filosofia de Alta Disponibilidade Kubernetes
Todo mundo conhece a analogia "animais de estimação
versus gado " e entende que, se Kubernetes é uma história do mundo dos rebanhos, os DBMSs clássicos são apenas animais de estimação.
E como era a arquitetura dos “animais de estimação” na versão “tradicional”? Um exemplo clássico de instalação do MySQL é a replicação em dois servidores de ferro com energia redundante, um disco, uma rede ... e tudo o mais (incluindo um engenheiro e várias ferramentas auxiliares), que nos ajudarão a ter certeza de que o processo do MySQL não falhará e se houver algum problema crítico. para seus componentes, a tolerância a falhas será respeitada:
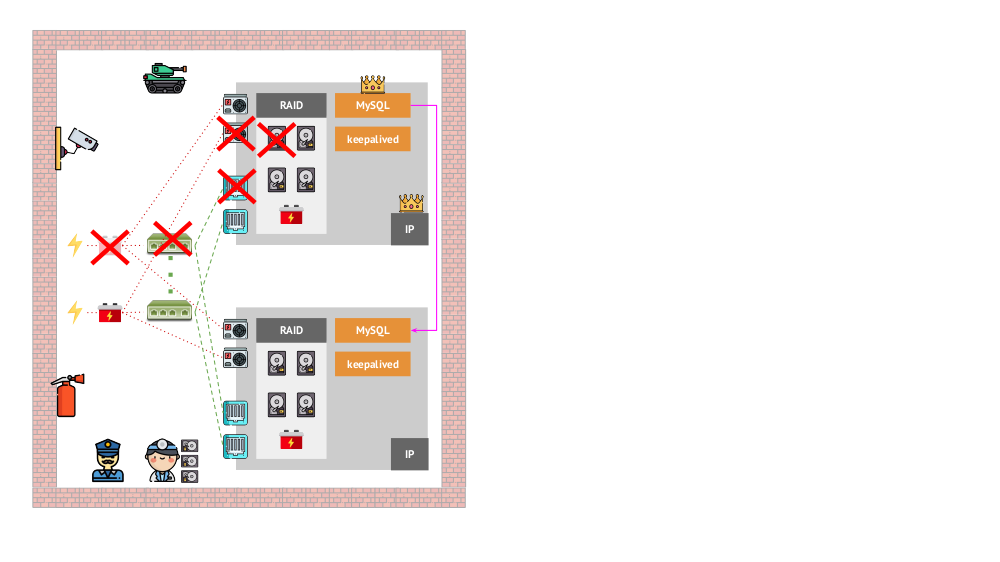
Como será a mesma aparência no Kubernetes? Aqui, geralmente há muito mais servidores de ferro, eles são mais simples e não possuem energia e rede redundantes (no sentido de que a perda de uma máquina não afeta nada) - tudo isso é combinado em um cluster. Sua tolerância a falhas é fornecida pelo software: se algo acontecer com o nó, o Kubernetes detecta e inicia as instâncias necessárias no outro nó.
Quais são os mecanismos de alta disponibilidade nos K8s?
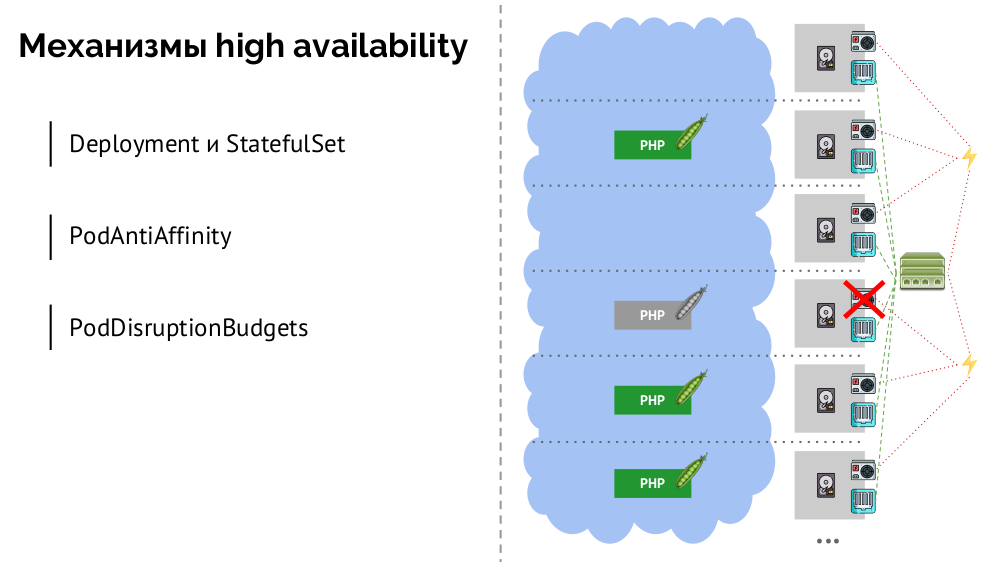
- Controladores Existem muitos, mas dois principais:
Deployment (para aplicativos sem estado) e StatefulSet (para aplicativos com estado). Eles armazenam toda a lógica das ações executadas no caso de uma falha no nó (inacessibilidade do pod). PodAntiAffinity - a capacidade de especificar pods específicos para que não fiquem no mesmo nó.PodDisruptionBudgets - limite no número de instâncias de pod que podem ser desativadas ao mesmo tempo em caso de trabalho agendado.
2. Garantias de consistência do Kubernetes
Como o esquema familiar de tolerância a falhas de mestre único funciona? Dois servidores (mestre e em espera), um dos quais é constantemente acessado pelo aplicativo, que por sua vez é usado através do balanceador de carga. O que acontece no caso de um problema de rede?
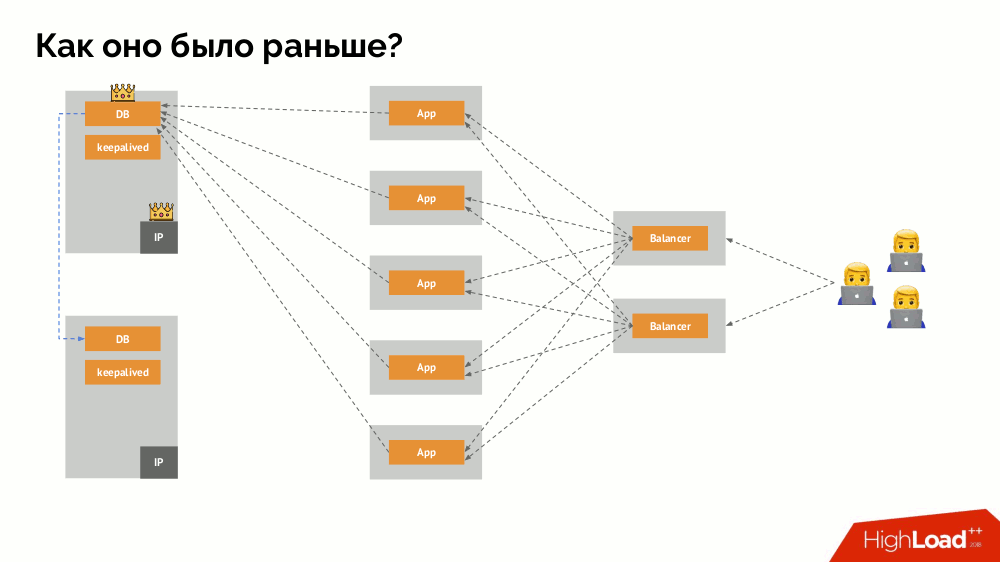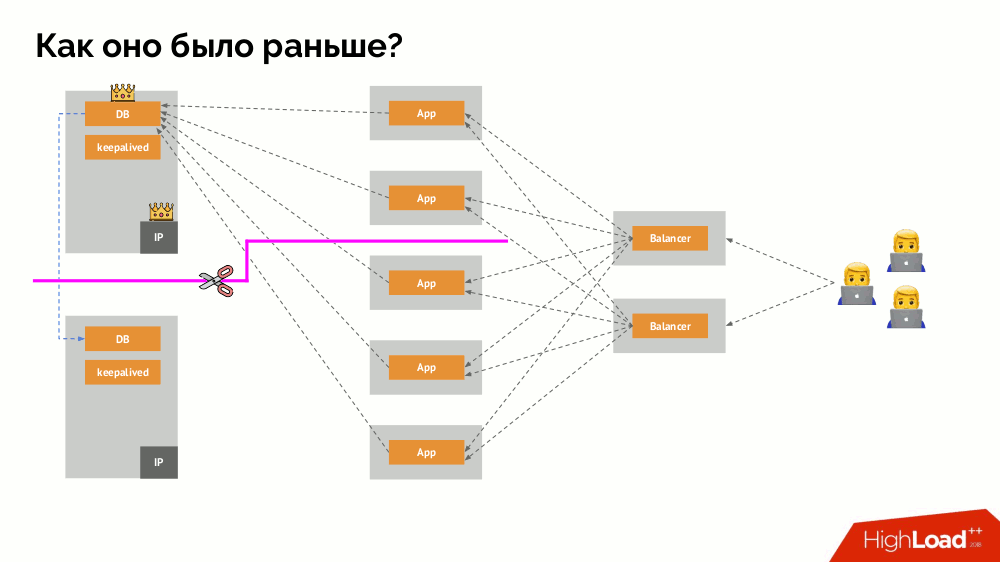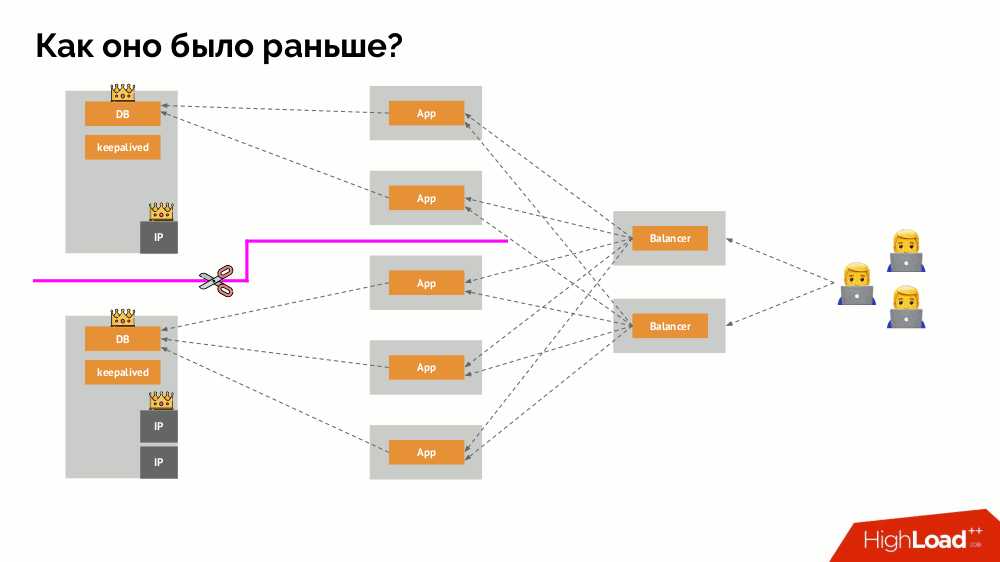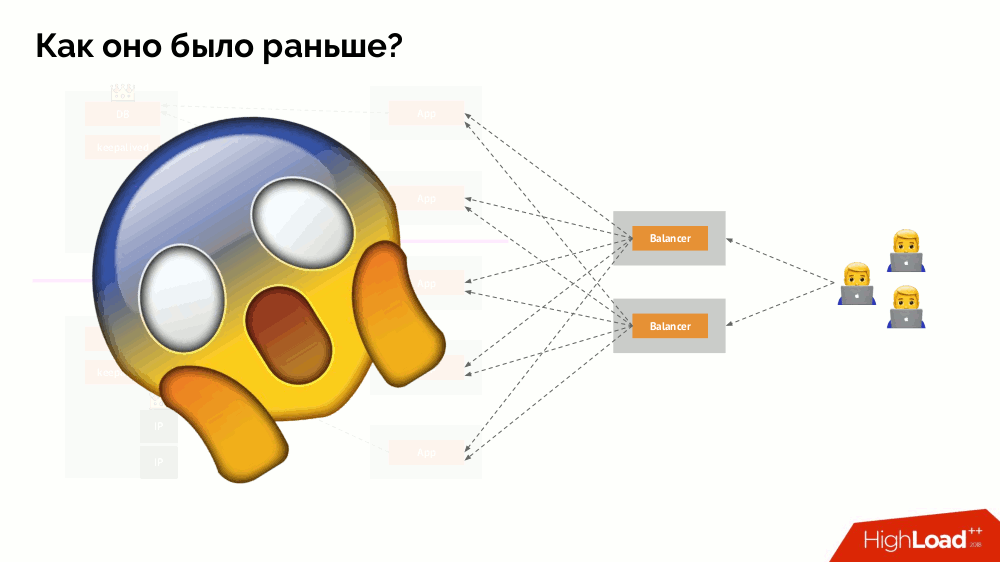 Cérebro dividido
Cérebro dividido clássico: o aplicativo começa a acessar as duas instâncias do DBMS, cada uma das quais se considera a principal. Para evitar isso, keepalived foi substituído por corosync por três instâncias para obter um quorum ao votar no mestre. No entanto, mesmo neste caso, há problemas: se uma instância do DBMS caída tentar "se matar" de todas as formas possíveis (remover o endereço IP, converter o banco de dados em somente leitura ...), a outra parte do cluster não saberá o que aconteceu com o mestre - isso pode acontecer, que esse nó ainda funcione e as solicitações cheguem a ele, o que significa que ainda não podemos mudar o assistente.
Para resolver essa situação, existe um mecanismo para isolar o nó para proteger todo o cluster contra operação incorreta - esse processo é chamado de
cerca . A essência prática se resume ao fato de que estamos tentando, por alguns meios externos, "matar" o carro caído. As abordagens podem ser diferentes: desde desligar a máquina via IPMI e bloquear a porta no comutador até acessar a API do provedor de nuvem, etc. E somente após esta operação você pode mudar o assistente. Isso garante uma garantia
no máximo, que nos garante
consistência .
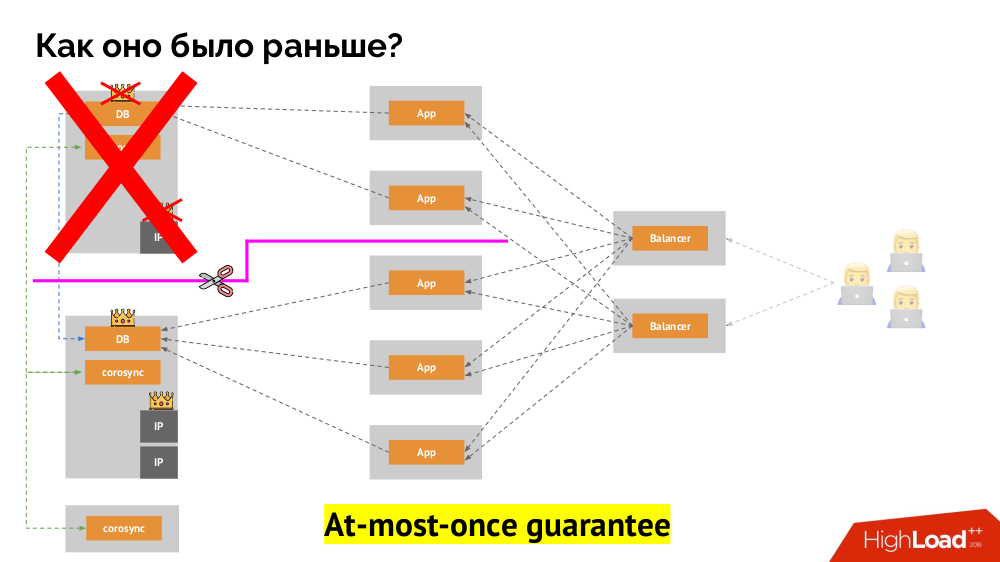
Como conseguir o mesmo no Kubernetes? Para fazer isso, já existem controladores mencionados, cujo comportamento no caso de inacessibilidade de um nó é diferente:
Deployment : "Disseram-me que deveria haver 3 pods e agora existem apenas 2 pods - vou criar um novo";StatefulSet : "Pod foi?" Vou esperar: esse nó retornará ou eles nos dirão para matá-lo " os próprios contêineres (sem ação do operador) não são recriados. É assim que a mesma garantia máxima é alcançada.
No entanto, aqui, no último caso, é necessário cercar: precisamos de um mecanismo que confirme que esse nó definitivamente desapareceu. Torná-lo automático é, em primeiro lugar, muito difícil (muitas implementações são necessárias) e, em segundo lugar, ainda pior, geralmente mata nós lentamente (o acesso ao IPMI pode levar segundos ou dezenas de segundos ou até minutos). Poucas pessoas estão satisfeitas com a espera por minuto para mudar a base para o novo mestre. Mas há outra abordagem que não requer um mecanismo de esgrima ...
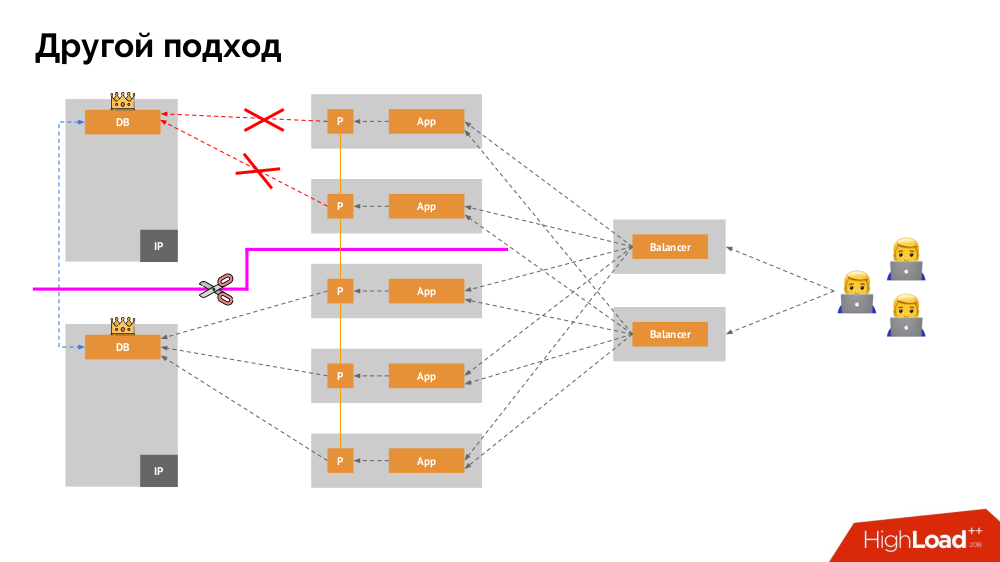
Vou começar a descrição dele fora do Kubernetes. Ele usa um balanceador de carga especial por meio do qual os back-ends acessam o DBMS. Sua especificidade reside no fato de ter a propriedade de consistência, ou seja, proteção contra falhas de rede e cérebro dividido, pois permite remover todas as conexões com o mestre atual, aguardar a sincronização (réplica) em outro nó e alternar para ele. Não encontrei um termo estabelecido para essa abordagem e a chamei de
alternância consistente .
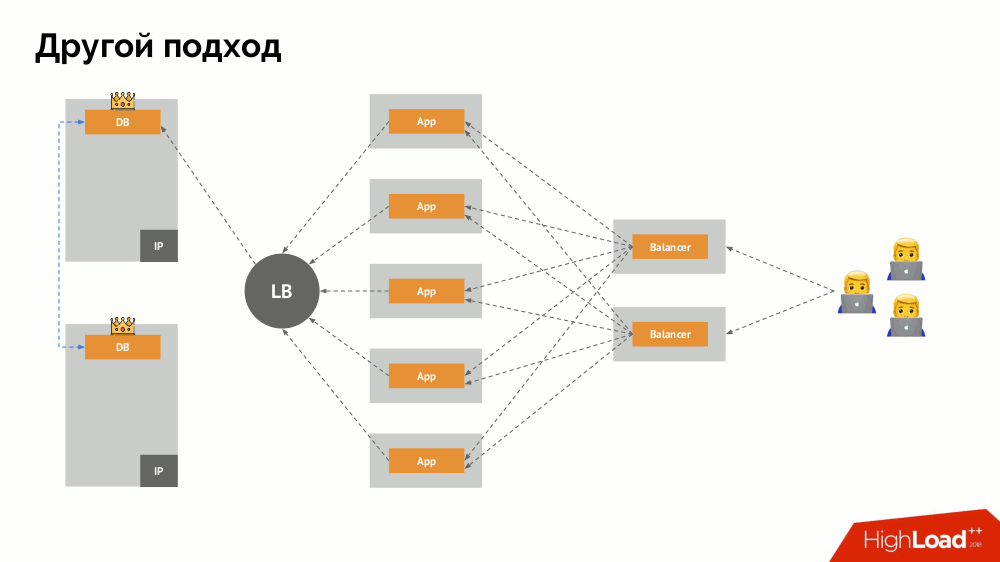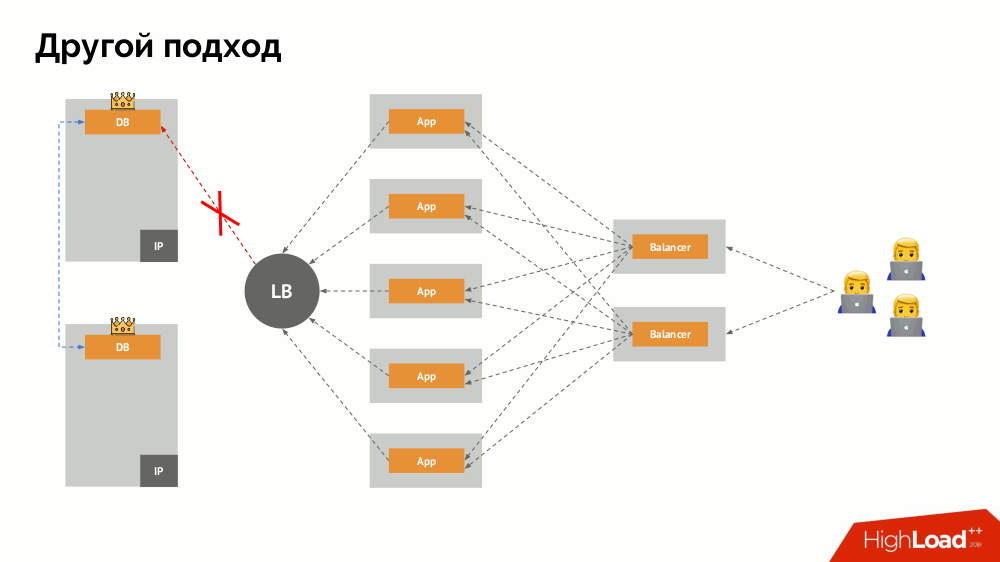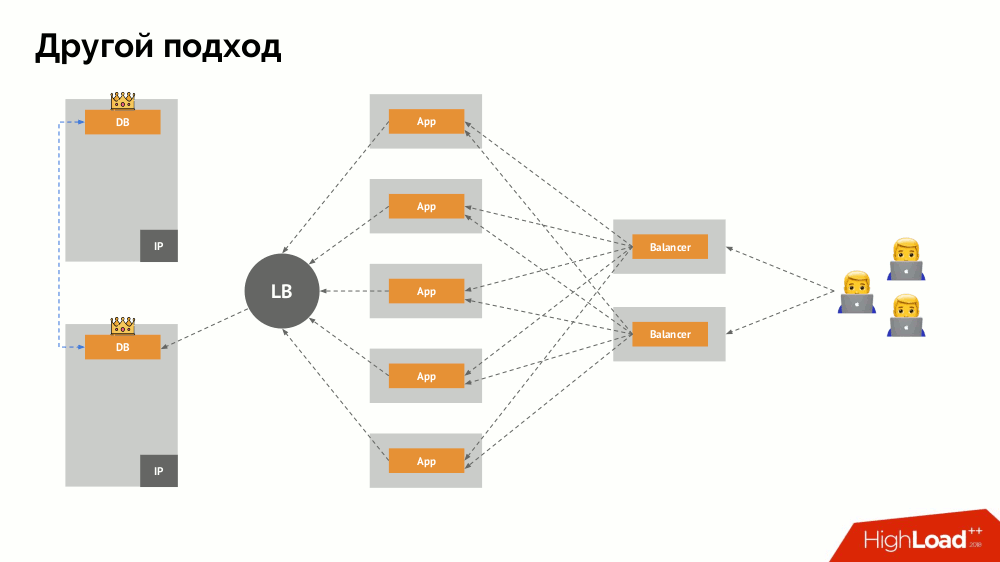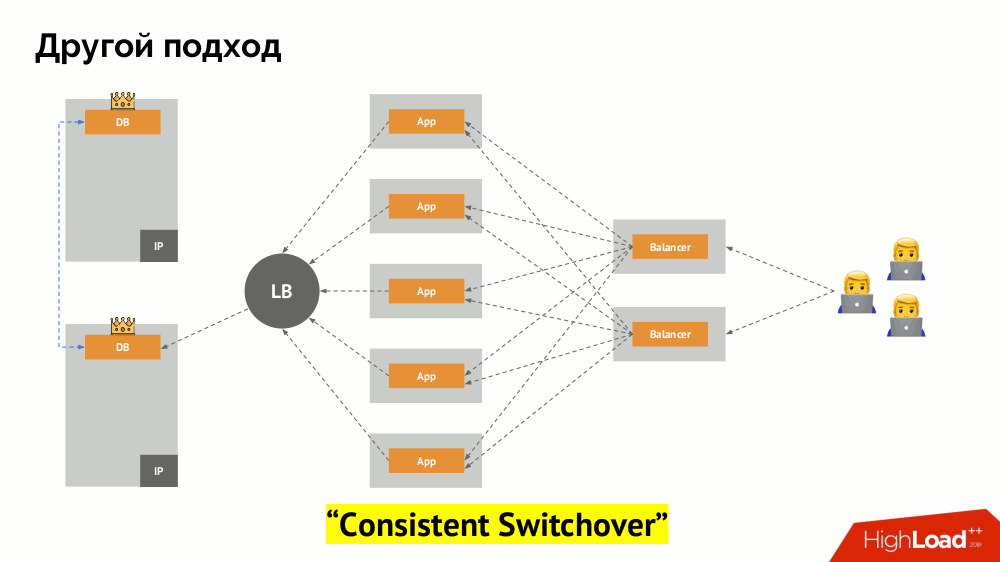
A principal questão com ele é como torná-lo universal, fornecendo suporte para provedores de nuvem e instalações privadas. Para isso, servidores proxy são adicionados aos aplicativos. Cada um deles aceitará solicitações de seu aplicativo (e as encaminhará ao DBMS), e um quorum será coletado de todas elas. Assim que uma parte do cluster falhar, os proxies que perderam o quorum removerão imediatamente suas conexões com o DBMS.
3. Armazenamento de Dados e Kubernetes
O mecanismo principal é a unidade de rede
Dispositivo de Bloco de Rede (aka) em várias implementações para as opções de nuvem desejadas ou bare metal. No entanto, colocar um banco de dados carregado (por exemplo, MySQL, que requer 50 mil IOPS) na nuvem (AWS EBS) não funcionará devido à
latência .
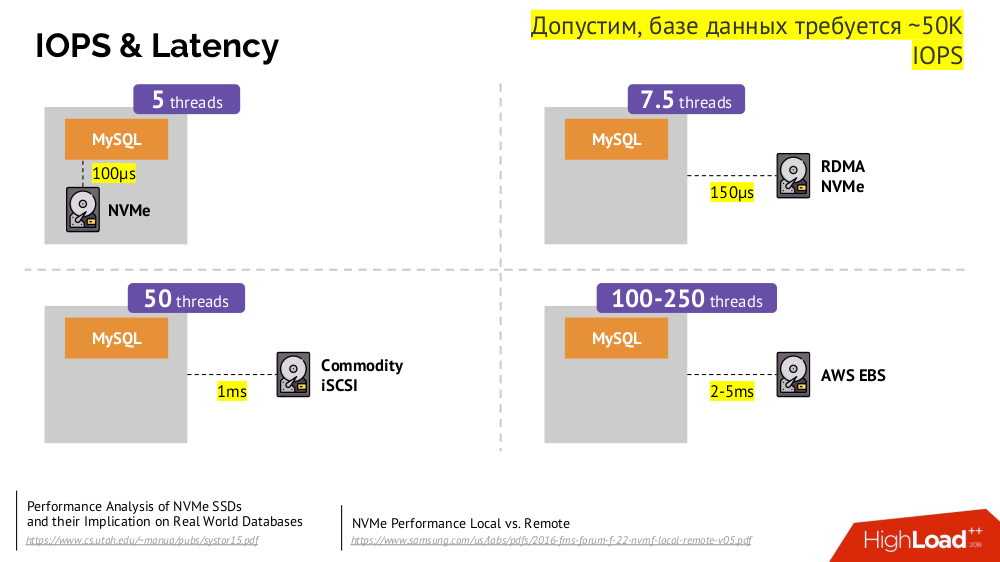
O Kubernetes nesses casos tem a capacidade de conectar um disco rígido
local -
armazenamento local . Se ocorrer uma falha (o disco não está mais disponível no pod), somos forçados a reparar esta máquina - semelhante ao esquema clássico no caso de uma falha de um servidor confiável.
As duas opções (
Dispositivo de Bloco de Rede e
Armazenamento Local ) pertencem à categoria
ReadWriteOnce : o armazenamento não pode ser montado em dois locais (pods) - para esse dimensionamento, você precisará criar um novo disco e conectá-lo a um novo pod (existe um mecanismo K8s interno para isso) e preencha com os dados necessários (já realizados por nossas forças).
Se precisarmos do modo
ReadWriteMany , as implementações do
Network File System (ou NAS) estarão disponíveis: para a nuvem pública, essas são
AzureFile e
AWSElasticFileSystem , e para suas instalações CephFS e Glusterfs para fãs de sistemas distribuídos, bem como NFS.

Prática
1. Independente
Essa opção ocorre quando nada impede que você inicie o DBMS no modo de servidor separado com armazenamento local. Não há dúvida de alta disponibilidade ... embora possa ser até certo ponto (isto é, suficiente para esta aplicação) implementado no nível do ferro. Existem muitos casos para esta aplicação. Antes de tudo, esses são todos os tipos de ambientes de teste e desenvolvimento, mas não apenas: os serviços secundários também caem aqui, desativá-los por 15 minutos não é crítico. No Kubernetes, isso é implementado pelo
StatefulSet com um pod:
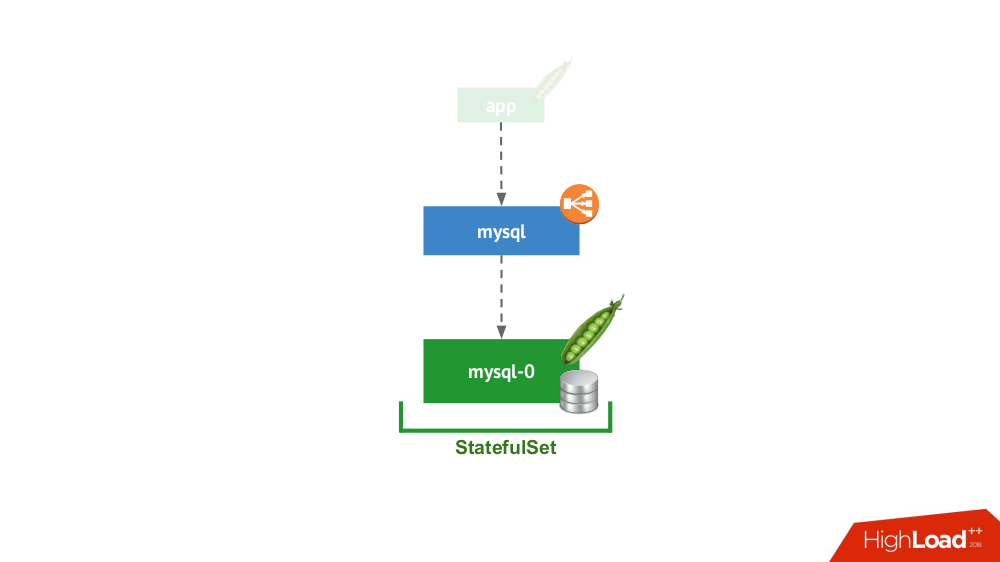
Em geral, essa é uma opção viável, que, do meu ponto de vista, não possui desvantagens em comparação com a instalação de um DBMS em uma máquina virtual separada.
2. Par replicado com comutação manual
StatefulSet usado novamente, mas o esquema geral se parece com isso:
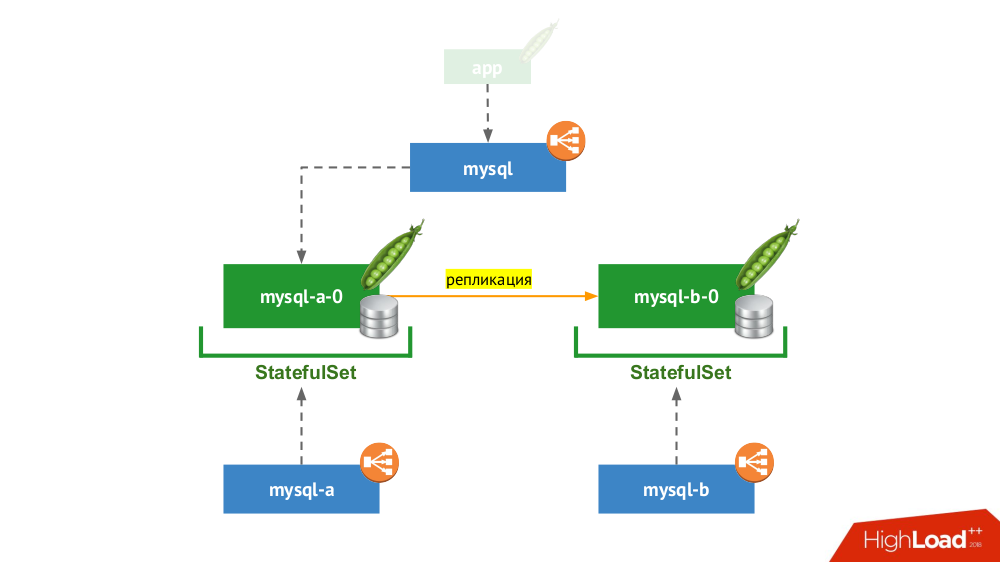
Se um dos nós trava (
mysql-a-0 ), um milagre não ocorre, mas temos uma réplica (
mysql-b-0 ) para a qual podemos mudar o tráfego. Nesse caso, mesmo antes de mudar o tráfego, é importante não apenas esquecer as solicitações de DBMS do serviço
mysql , mas também efetuar login manualmente no DBMS e garantir que todas as conexões sejam concluídas (eliminá-las), além de ir para o segundo nó do DBMS e reconfigurar a réplica. na direção oposta.
Se você está atualmente usando a versão clássica com dois servidores (mestre + espera) sem
failover automático, essa solução é equivalente no Kubernetes. Adequado para MySQL, PostgreSQL, Redis e outros produtos.
3. Escalando a carga de leitura
De fato, este caso não é estável, porque estamos falando apenas de leitura. Aqui, o servidor DBMS principal está fora do esquema considerado e, dentro da estrutura do Kubernetes, é criado um "farm de servidores escravos", que são somente leitura. O mecanismo geral - o uso de contêineres init para preencher dados do DBMS em cada novo pod deste farm (usando um despejo quente ou o usual com ações adicionais etc. - depende do DBMS usado). Para garantir que cada instância não fique muito longe do mestre, você pode usar testes de animação.

4. Cliente Inteligente
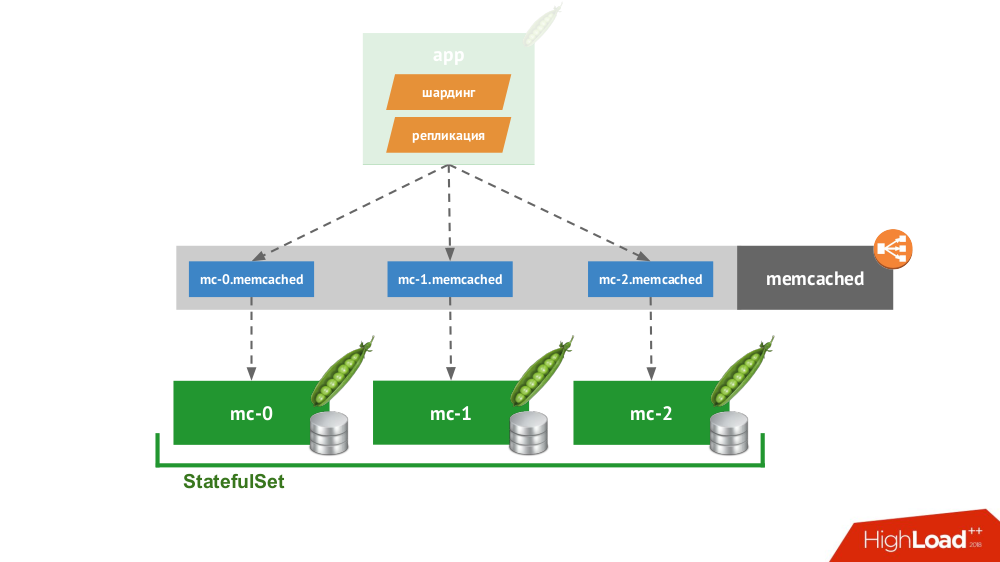
Se você criar um
StatefulSet de três memcached, o Kubernetes terá um serviço especial que não equilibrará solicitações, mas criará cada pod para seu próprio domínio. O cliente poderá trabalhar com eles se ele próprio for capaz de fragmentar e replicar.
Você não precisa ir muito longe por exemplo: é assim que o armazenamento de sessões funciona no PHP imediatamente. Para cada solicitação de sessão, as solicitações são feitas simultaneamente a todos os servidores, após o qual a resposta mais relevante é selecionada a partir deles (da mesma forma que um registro).
5. Soluções nativas em nuvem
Existem muitas soluções inicialmente focadas na falha dos nós, ou seja, eles mesmos podem
executar failover e recuperação de nós, fornecer garantias de
consistência . Esta não é uma lista completa deles, mas apenas parte de exemplos populares:

Todos eles são simplesmente colocados no
StatefulSet , após o qual os nós se encontram e formam um cluster. Os próprios produtos diferem na maneira como implementam três coisas:
- Como os nós aprendem um sobre o outro? Existem métodos como a API do Kubernetes, registros DNS, configuração estática, nós especializados (semente), descoberta de serviços de terceiros ...
- Como o cliente se conecta? Por meio de um balanceador de carga que distribui para hosts, ou o cliente precisa saber sobre todos os hosts e ele decide como proceder.
- Como é feito o dimensionamento horizontal? De jeito nenhum, completo ou difícil / com restrições.
Independentemente das soluções escolhidas para esses problemas, todos esses produtos funcionam bem com o Kubernetes, porque foram originalmente criados como um "rebanho"
(gado) .
6. Stolon PostgreSQL
Stolon realmente permite que você transforme o PostgreSQL, criado como
animal de estimação , em
gado . Como isso é alcançado?
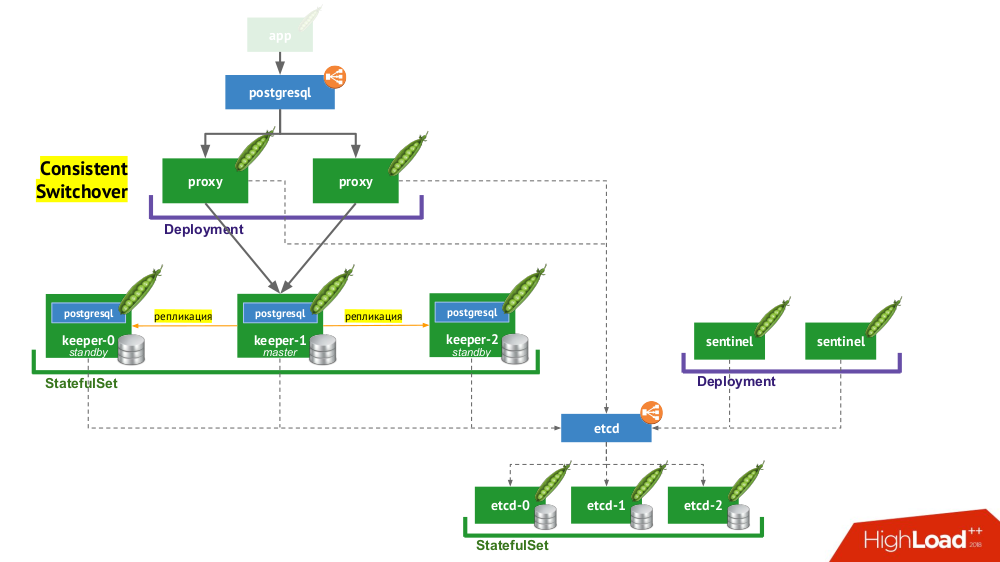
- Primeiramente, precisamos de uma descoberta de serviço, cuja função possa ser etcd (outras opções estão disponíveis) - um cluster delas é colocado em um
StatefulSet . - Outra parte da infraestrutura é
StatefulSet com instâncias do PostgreSQL. Além do DBMS propriamente dito, ao lado de cada instalação também há um componente chamado guardião , que executa a configuração do DBMS. - Outro componente, o sentinel, é implantado como uma
Deployment e monitora a configuração do cluster. É ele quem decide quem será o mestre e o modo de espera, grava essas informações no etcd. E o guardião lê os dados do etcd e executa ações correspondentes ao status atual com uma instância do PostgreSQL. - Outro componente implantado no
Deployment e enfrentando instâncias do PostgreSQL, proxy, é uma implementação do padrão de Alternância Consistente já mencionado. Esses componentes estão conectados ao etcd e, se essa conexão for perdida, o proxy eliminará imediatamente as conexões de saída, porque a partir deste momento ele não sabe o papel do servidor (agora é mestre ou em espera?). - Por fim, as instâncias de proxy enfrentam o habitual
LoadBalancer LoadBalancer.
Conclusões
Então, é possível basear-se no Kubernetes? Sim, é claro, é possível, em alguns casos ... E se for apropriado, é feito assim (consulte o fluxo de trabalho Stolon) ...
Todo mundo sabe que a tecnologia está evoluindo em ondas. Inicialmente, qualquer novo dispositivo pode ser muito difícil de usar, mas com o tempo tudo muda: a tecnologia se torna disponível. Para onde vamos? Sim, permanecerá assim por dentro, mas não saberemos como isso funcionará. Kubernetes está desenvolvendo ativamente
operadores . Até agora, não existem muitos deles e eles não são tão bons, mas há movimento nessa direção.
Vídeos e slides
Vídeo da apresentação (cerca de uma hora):
Apresentação do relatório:
PS Também encontramos na rede um
pequeno aperto textual neste relatório - obrigado por Nikolai Volynkin.
PPS
Outros relatórios em nosso blog:
Você também pode estar interessado nas seguintes publicações: