Ceph é um armazenamento de objeto projetado para ajudar a criar um cluster de failover. Ainda assim, falhas acontecem. Todo mundo que trabalha com Ceph conhece a lenda sobre CloudMouse ou Rosreestr. Infelizmente, não é habitual compartilhar experiências negativas conosco, as causas das falhas são mais frequentemente escondidas e não permitem que as gerações futuras aprendam com os erros dos outros.
Bem, vamos configurar um cluster de teste, mas próximo ao real, e analisar o desastre por ossos. Mediremos todos os rebaixamentos de desempenho, encontraremos vazamentos de memória e analisaremos o processo de recuperação de serviços. E tudo isso sob a liderança de Artemy Kapitula, que passou quase um ano estudando as armadilhas, fez com que o desempenho do cluster falhasse em zero e a latência não saltasse para valores indecentes. E eu tenho um gráfico vermelho, que é muito melhor.
A seguir, você encontrará uma versão em vídeo e texto de um dos melhores relatórios do
DevOpsConf Russia 2018.
Sobre o palestrante: Artemy Kapitula, arquiteto de sistemas RCNTEC. A empresa oferece soluções de telefonia IP (colaboração, organização de um escritório remoto, sistemas de armazenamento definidos por software e sistemas de gerenciamento / distribuição de energia). A empresa trabalha principalmente no setor empresarial, portanto, não é muito conhecida no mercado de DevOps. No entanto, alguma experiência foi acumulada com o Ceph, que em muitos projetos é usado como elemento básico da infraestrutura de armazenamento.
O Ceph é um repositório definido por software com muitos componentes de software.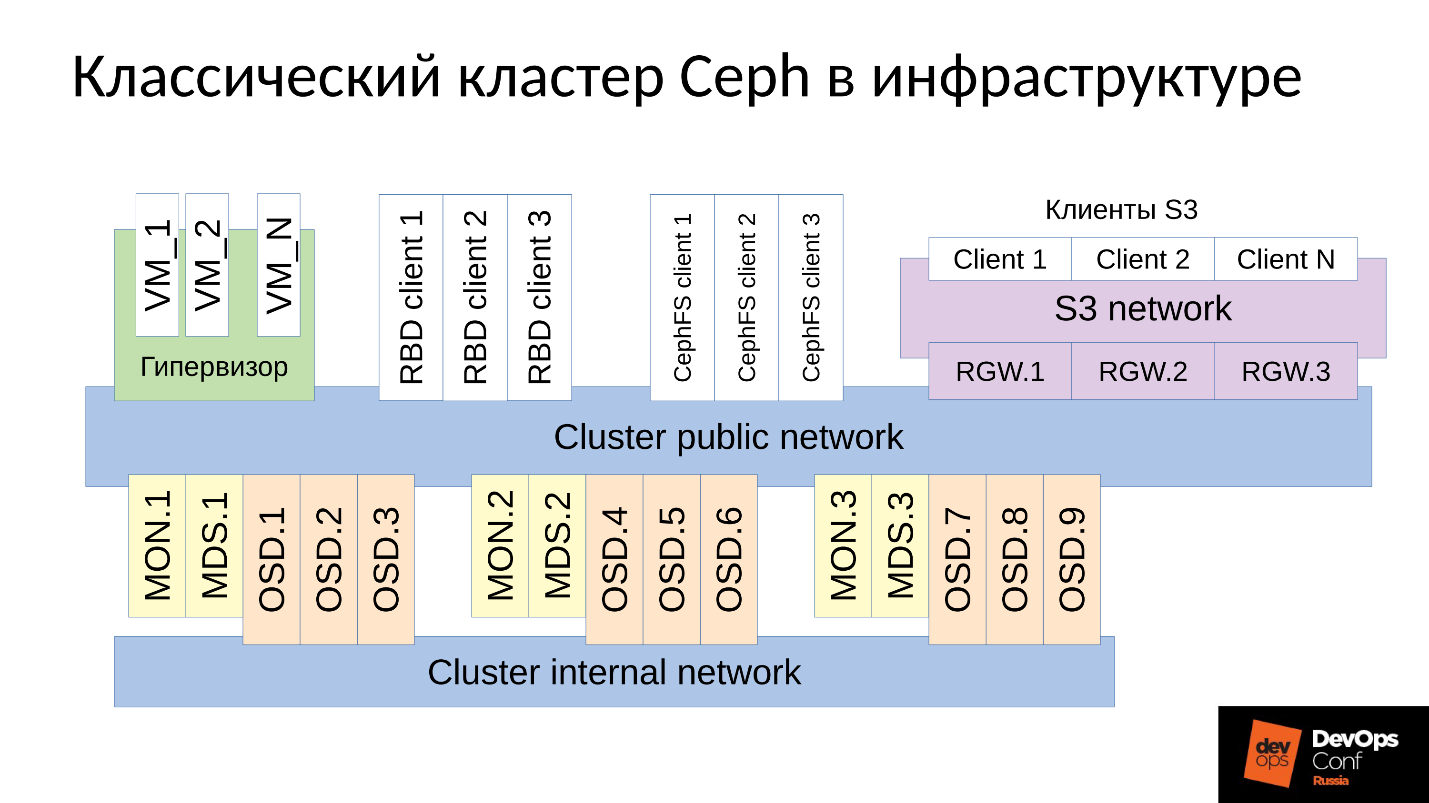
No diagrama:
- O nível superior é a rede interna do cluster através da qual o próprio cluster se comunica;
- O nível mais baixo - atualmente Ceph - é um conjunto de daemons internos do Ceph (MON, MDS e OSD) que armazenam dados.
Como regra, todos os dados são replicados.No diagrama, eu selecionei deliberadamente três grupos, cada um com três OSDs, e cada um desses grupos geralmente contém uma réplica de dados. Como resultado, os dados são armazenados em três cópias.
Uma rede de cluster de nível superior é a rede através da qual os clientes Ceph acessam dados. Por meio dele, os clientes se comunicam com o monitor, com o MDS (quem precisa dele) e com o OSD. Cada cliente trabalha com cada OSD e com cada monitor independentemente. Portanto, o
sistema é desprovido de um único ponto de falha , o que é muito agradável.
Clientes
● clientes S3
S3 é uma API para HTTP. Os clientes S3 trabalham com HTTP e se conectam aos componentes Ceph Rados Gateway (RGW). Eles quase sempre se comunicam com um componente através de uma rede dedicada. Essa rede (eu chamei de rede S3) usa apenas HTTP, as exceções são raras.
● Hipervisor com máquinas virtuais
Esse grupo de clientes é frequentemente usado. Eles trabalham com monitores e com OSD, dos quais recebem informações gerais sobre o status do cluster e a distribuição de dados. Para dados, esses clientes vão diretamente para os daemons OSD por meio da rede pública do cluster.
● clientes RBD
Também existem hosts físicos de metais BR, que geralmente são Linux. Eles são clientes RBD e obtêm acesso às imagens armazenadas em um cluster Ceph (imagens de disco da máquina virtual).
● clientes CephFS
O quarto grupo de clientes, que muitos ainda não têm, mas têm um interesse crescente, são clientes do sistema de arquivos em cluster do CephFS. O sistema de cluster CephFS pode ser montado simultaneamente a partir de muitos nós, e todos os nós obtêm acesso aos mesmos dados, trabalhando com cada OSD. Ou seja, não há Gateways como tal (Samba, NFS e outros). O problema é que esse cliente pode ser apenas Linux e uma versão bastante moderna.

Nossa empresa trabalha no mercado corporativo, e lá a bola é governada por ESXi, HyperV e outros. Por conseguinte, o cluster Ceph, que é de alguma forma usado no setor corporativo, é necessário para apoiar as técnicas apropriadas. Isso não foi suficiente para nós na Ceph, por isso tivemos que refinar e expandir o cluster da Ceph com nossos componentes, construindo algo mais do que a Ceph, nossa própria plataforma para armazenar dados.
Além disso, os clientes do setor corporativo não estão no Linux, mas a maioria deles Windows, ocasionalmente Mac OS, não pode acessar o cluster Ceph. Eles precisam passar por algum tipo de gateways, que nesse caso se tornam gargalos.
Tivemos que adicionar todos esses componentes e obtivemos um cluster um pouco maior.

Temos dois componentes centrais: o
grupo SCSI Gateways , que fornece acesso aos dados em um cluster Ceph por meio do FibreChannel ou iSCSI. Esses componentes são usados para conectar o HyperV e ESXi a um cluster Ceph. Os clientes PROXMOX ainda trabalham à sua maneira - através do RBD.
Não permitimos que os clientes de arquivos entrem diretamente na rede do cluster; vários Gateways tolerantes a falhas são alocados para eles. Cada Gateway fornece acesso ao sistema de cluster de arquivos via NFS, AFP ou SMB. Assim, quase qualquer cliente, seja Linux, FreeBSD ou não apenas um cliente, servidor (OS X, Windows), obtém acesso ao CephFS.
Para gerenciar tudo isso, tivemos que desenvolver nossa própria orquestra Ceph e todos os nossos componentes, que são numerosos lá. Mas falar sobre isso agora não faz sentido, pois esse é o nosso desenvolvimento. A maioria provavelmente estará interessada no próprio Ceph "nu".
O Ceph é usado muito onde, e ocasionalmente ocorrem falhas. Certamente todo mundo que trabalha com Ceph conhece a lenda sobre o CloudMouse. Esta é uma terrível lenda urbana, mas nem tudo é tão ruim quanto parece. Há um novo conto de fadas sobre Rosreestr. Ceph estava girando em todos os lugares, e em todo lugar estava falhando. Em algum lugar que terminou fatalmente, em algum lugar conseguiu eliminar rapidamente as consequências.
Infelizmente, não é habitual compartilharmos experiências negativas, todos estão tentando esconder as informações relevantes. As empresas estrangeiras são um pouco mais abertas, em particular, a DigitalOcean (um conhecido fornecedor que distribui máquinas virtuais) também sofreu uma falha no Ceph por quase um dia, era 1º de abril - um dia maravilhoso! Eles postaram alguns dos relatórios, um pequeno log abaixo.

Os problemas começaram às 7 da manhã, às 11 eles entenderam o que estava acontecendo e começaram a eliminar o fracasso. Para fazer isso, eles alocaram dois comandos: um, por algum motivo, rodou nos servidores e instalou memória nele; o segundo, por algum motivo, iniciou manualmente um servidor após o outro e monitorou cuidadosamente todos os servidores. Porque Estamos todos acostumados a tudo ativado com um clique.
O que basicamente acontece em um sistema distribuído quando ele é efetivamente construído e funciona quase no limite de seus recursos?Para responder a essa pergunta, precisamos examinar como o cluster Ceph funciona e como ocorre a falha.

Cenário de falha do Ceph
No início, o cluster funciona bem, tudo está indo bem. Então, algo acontece, após o qual os daemons OSD, onde os dados são armazenados, perdem contato com os componentes centrais do cluster (monitores). Nesse ponto, ocorre um tempo limite e todo o cluster recebe uma aposta. O cluster permanece por um tempo até perceber que algo está errado com ele e depois corrigir o conhecimento interno. Depois disso, o atendimento ao cliente é restaurado até certo ponto e o cluster está novamente trabalhando em um modo degradado. E o engraçado é que funciona mais rápido do que no modo normal - esse é um fato incrível.
Então eliminamos o fracasso. Suponhamos que perdemos energia, o rack foi completamente cortado. Eletricistas vieram correndo, todos restauraram, forneceram energia, os servidores foram ligados e
a diversão começou .
Todo mundo está acostumado ao fato de que, quando um servidor falha, tudo fica ruim e, quando ligamos o servidor, tudo fica bom. Tudo está completamente errado aqui.
O cluster praticamente para, realiza a sincronização primária e inicia uma recuperação lenta e suave, retornando gradualmente ao modo normal.

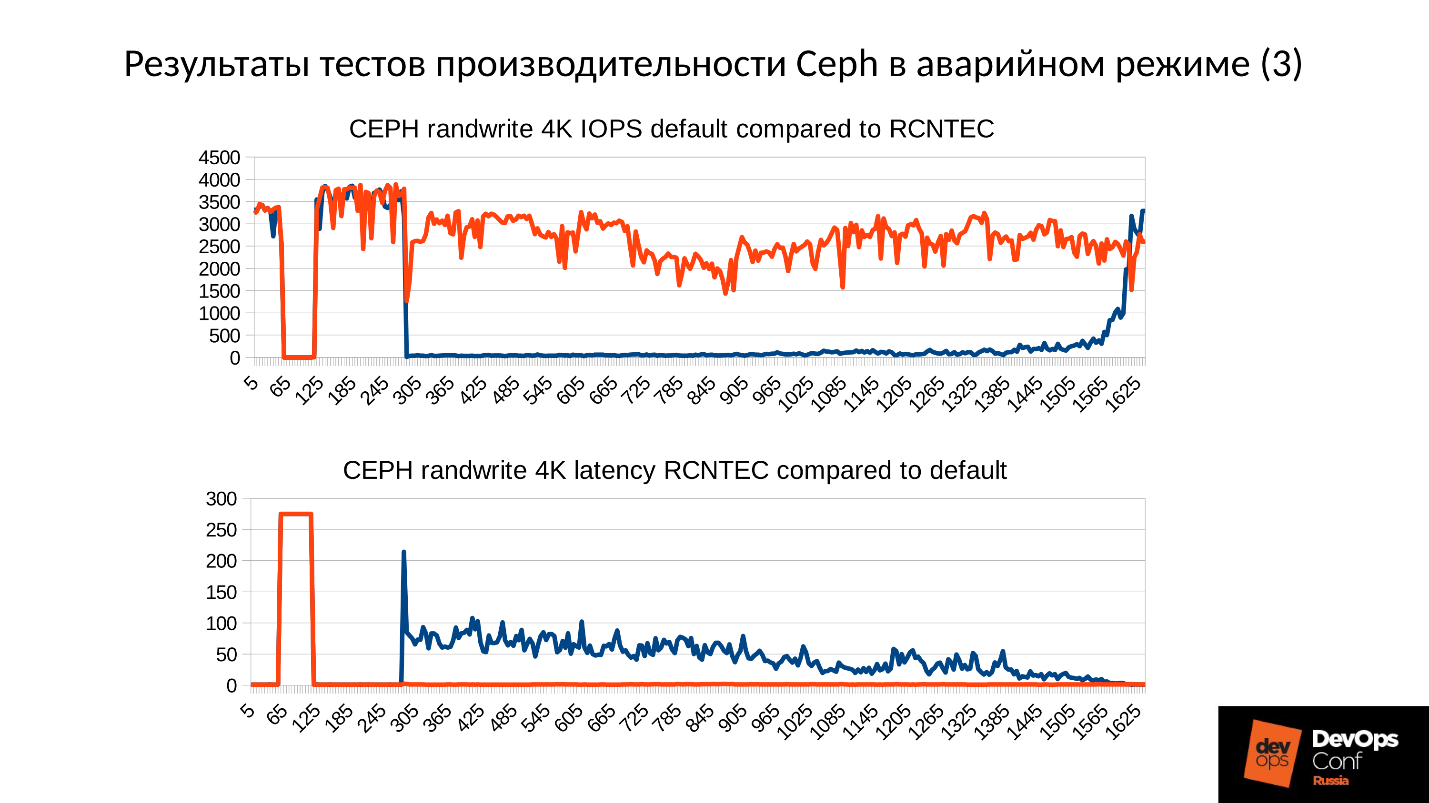
Acima está um gráfico do desempenho do cluster Ceph à medida que uma falha se desenvolve. Observe que aqui os mesmos intervalos de que falamos são muito claramente traçados:
- Operação normal até aproximadamente 70 segundos;
- Falha por um minuto a cerca de 130 segundos;
- Um platô que é notavelmente mais alto que a operação normal é o trabalho de aglomerados degradados;
- Em seguida, ativamos o nó ausente - este é um cluster de treinamento, existem apenas 3 servidores e 15 SSDs. Iniciamos o servidor em torno de 260 segundos.
- O servidor ligado, entrou no cluster - IOPS'y caiu.
Vamos tentar descobrir o que realmente aconteceu lá. A primeira coisa que nos interessa é uma queda no início do gráfico.
Falha no OSD
Considere um exemplo de um cluster com três racks, vários nós em cada um. Se o rack esquerdo falhar, todos os daemons OSD (não os hosts!) Ping-se com mensagens Ceph em um determinado intervalo. Se houver uma perda de várias mensagens, uma mensagem será enviada ao monitor: "Eu, OSD tal e tal, não posso alcançar OSD tal e tal".

Ao mesmo tempo, as mensagens geralmente são agrupadas por host, ou seja, se duas mensagens de OSDs diferentes chegam ao mesmo host, elas são combinadas em uma mensagem. Portanto, se o OSD 11 e o OSD 12 reportarem que não podem alcançar o OSD 1, isso será interpretado como o Host 11 reclamou do OSD 1. Quando o OSD 21 e o OSD 22 foram relatados, ele é interpretado como o Host 21 insatisfeito com o OSD 1. Após o qual o monitor considera que o OSD 1 está no estado inativo e notifica todos os membros do cluster (alterando o mapa OSD), o trabalho continua no modo degradado.
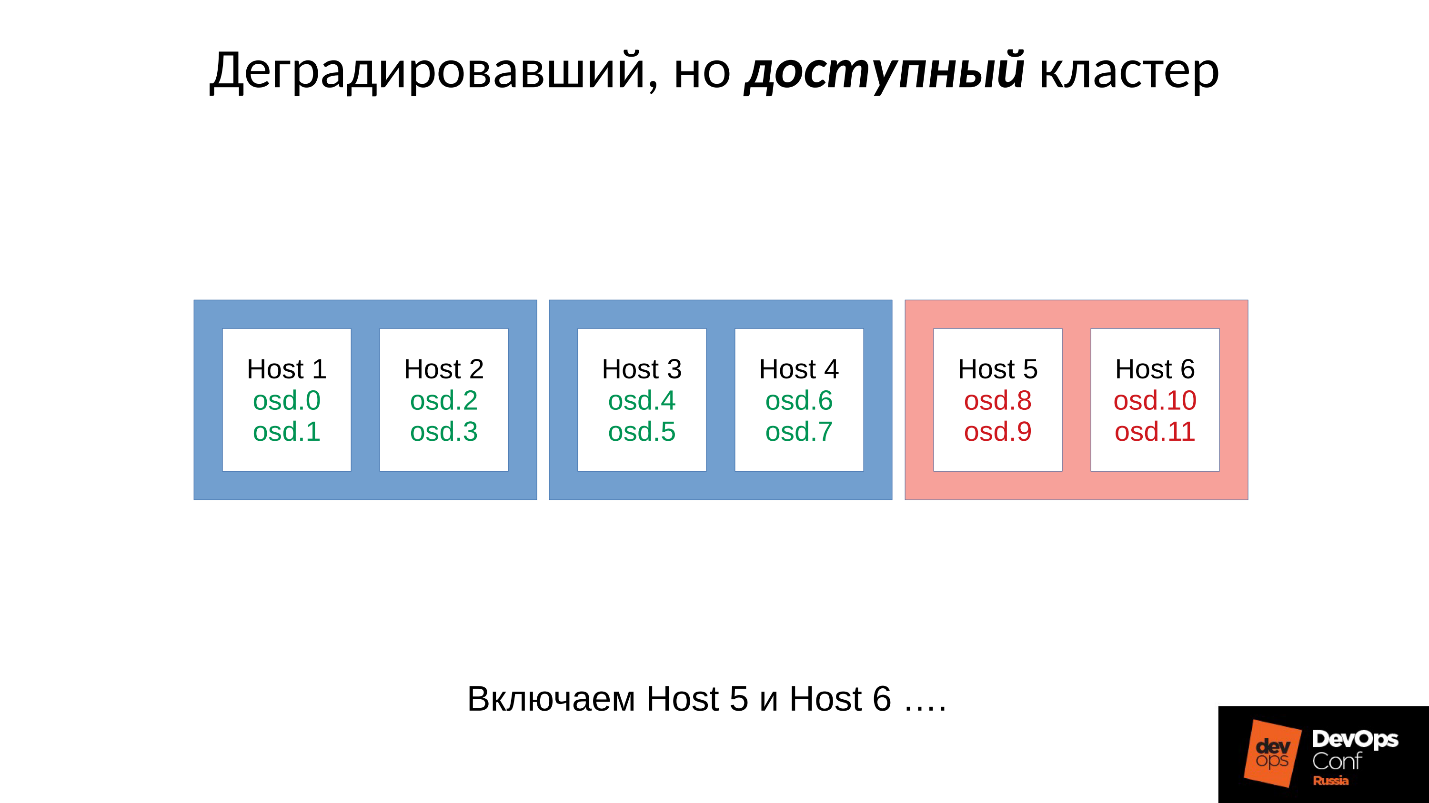
Então, aqui está o nosso cluster e o rack com falha (Host 5 e Host 6). Ativamos o Host 5 e o Host 6, conforme o poder apareceu, e ...
Comportamento interno do Ceph
E agora a parte mais interessante é que estamos iniciando a
sincronização de dados inicial . Como existem muitas réplicas, elas devem ser síncronas e estar na mesma versão. No processo de iniciar o OSD, inicie:
- O OSD lê as versões disponíveis, o histórico disponível (pg_log - para determinar as versões atuais dos objetos).
- Depois disso, ele determina em qual OSD estão as versões mais recentes de objetos degradados (missing_loc) e quais estão atrasadas.
- Onde as versões anteriores são armazenadas, a sincronização é necessária e novas versões podem ser usadas como referência para leitura e gravação de dados.
É usada uma história que é coletada de todos os OSDs, e essa história pode ser bastante; é determinada a localização real do conjunto de objetos no cluster em que as versões correspondentes estão localizadas. Quantos objetos estão no cluster, quantos registros são obtidos, se o cluster permaneceu por muito tempo no modo degradado, a história é longa.
Para comparação: o tamanho típico de um objeto quando trabalhamos com uma imagem RBD é de 4 MB. Quando trabalhamos no apagamento codificado - 1MB. Se tivermos um disco de 10 TB, obteremos um milhão de objetos de megabyte no disco. Se tivermos 10 discos no servidor, já existem 10 milhões de objetos, se 32 discos (estamos construindo um cluster eficaz, temos uma alocação restrita), então 32 milhões de objetos devem ser mantidos na memória. Além disso, de fato, as informações sobre cada objeto são armazenadas em várias cópias, porque cada cópia indica que, neste local, está nesta versão e nesta - nesta.
Acontece uma enorme quantidade de dados, localizada na RAM:
- quanto mais objetos, maior o histórico de missing_loc;
- quanto mais PG - mais pg_log e mapa OSD;
além disso:
- quanto maior o tamanho do disco;
- quanto maior a densidade (o número de discos em cada servidor);
- quanto maior a carga no cluster e mais rápido o cluster;
- quanto mais o OSD estiver inativo (no estado Off-line);
em outras palavras, quanto
mais íngreme o cluster que construímos, e quanto mais a parte do cluster não respondeu, mais RAM seria necessária na inicialização .
Otimizações extremas são a raiz de todo mal
"... e o OOM preto chega aos meninos e meninas maus à noite e mata todos os processos, à esquerda e à direita"
Cidade sysadmin legend
Portanto, a RAM exige muito, o consumo de memória está aumentando (começamos imediatamente em um terço do cluster) e o sistema, em teoria, pode entrar no SWAP, se você o criou naturalmente. Acho que muitas pessoas pensam que o SWAP é ruim e não o criam: "Por que? Temos muita memória! Mas esta é a abordagem errada.
Se o arquivo SWAP não tiver sido criado com antecedência, uma vez que foi decidido que o Linux funcionaria com mais eficiência, mais cedo ou mais tarde ocorrerá com falta de memória (OOM-killer), e não com o fato de matar quem comeu toda a memória, aquele que teve primeiro azar. Sabemos o que é uma localização otimista - pedimos uma memória, eles prometem isso para nós, dizemos: “Agora nos dê uma”, em resposta: “Mas não!” - e sem memória.
Este é um trabalho normal do Linux, a menos que configurado na área de memória virtual.
O processo fica sem memória e cai de forma rápida e implacável. Além disso, nenhum outro processo que ele morreu não conhece. Ele não teve tempo de notificar ninguém de nada, eles simplesmente o demitiram.
Então o processo, é claro, será reiniciado - nós temos systemd, e também lança, se necessário, OSDs que caíram. OSDs caídos começam e ... uma reação em cadeia começa.
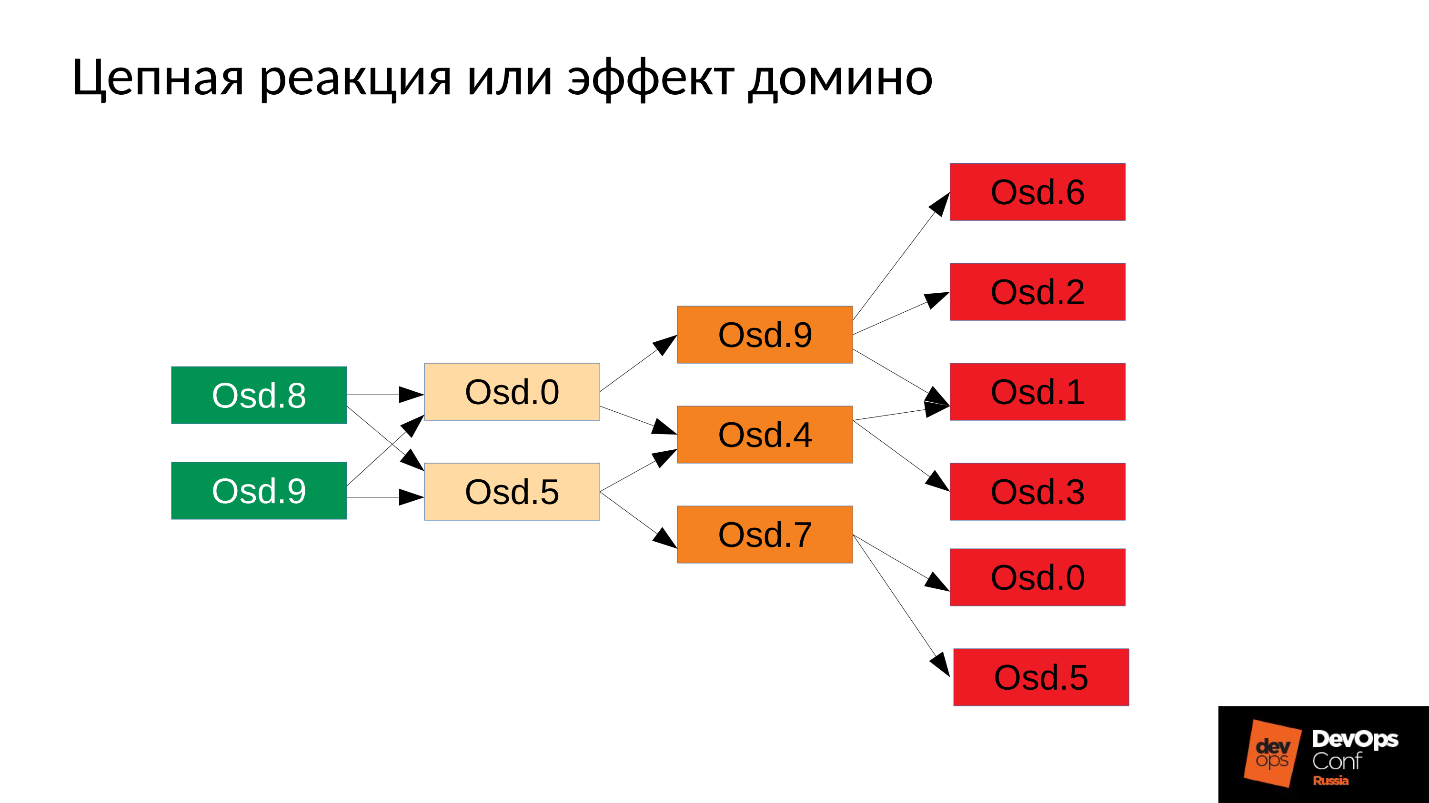
No nosso caso, começamos o OSD 8 e o OSD 9, eles começaram a esmagar tudo, mas sem sorte OSD 0 e OSD 5. Um assassino sem memória voou para eles e os encerrou. Eles recomeçaram - eles leram seus dados, começaram a sincronizar e esmagar o resto. Mais três azarados (OSD 9, OSD 4 e OSD 7). Estes três reiniciados, começaram a pressionar todo o cluster, o próximo pacote teve azar.
O aglomerado começa a desmoronar literalmente diante de nossos olhos . A degradação ocorre muito rapidamente, e esse "muito rápido" é geralmente expresso em minutos, no máximo dezenas de minutos. Se você tiver 30 nós (10 nós por rack) e cortá-lo devido a uma falha de energia - após 6 minutos, metade do cluster fica.
Então, temos algo parecido com o seguinte.
Em quase todos os servidores, temos um OSD com falha. E se em cada servidor, ou seja, em cada domínio de falha que temos para o OSD com falha, a
maioria dos nossos dados fica inacessível . Qualquer solicitação é bloqueada - por escrito, por leitura - não faz diferença. Isso é tudo! Nos levantamos.
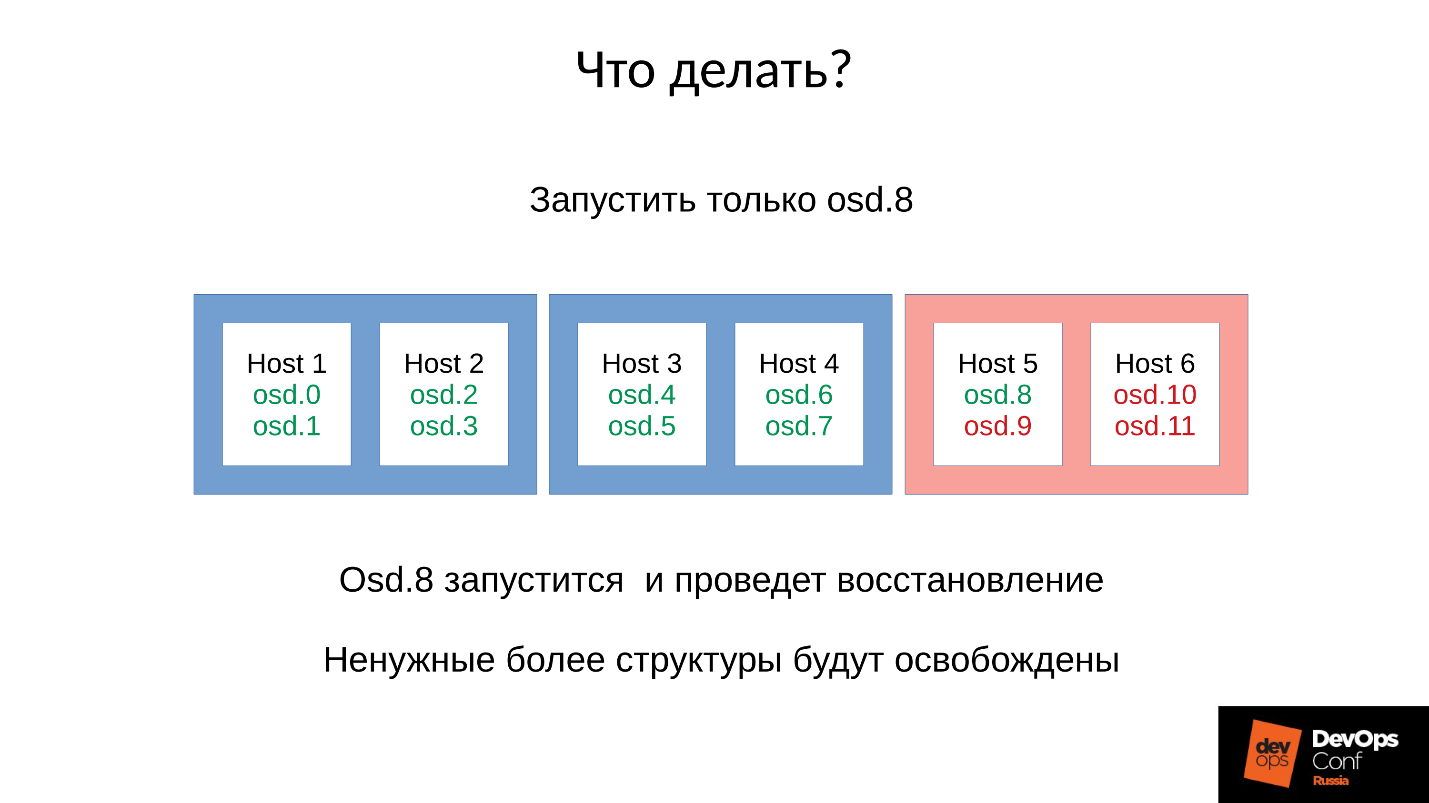
O que fazer em tal situação? Mais precisamente, o
que tinha que ser feito ?
Resposta: Não inicie o cluster imediatamente, ou seja, todo o rack, mas levante cuidadosamente um demônio cada.
Mas nós não sabíamos disso. Começamos imediatamente e conseguimos o que conseguimos. Nesse caso, lançamos um dos quatro daemons (8, 9, 10, 11), o consumo de memória aumentará em cerca de 20%. Como regra, temos um salto. Em seguida, o consumo de memória começa a diminuir, porque algumas das estruturas usadas para armazenar informações sobre como o cluster degradado estão saindo. Ou seja, parte dos grupos de canais retornou ao seu estado normal e tudo o que é necessário para manter o estado degradado é liberado -
em teoria, ele é liberado .
Vamos ver um exemplo. O código C à esquerda e à direita é quase idêntico, a diferença está apenas nas constantes.

Estes dois exemplos solicitam uma quantidade diferente de memória do sistema:
- esquerda - 2048 peças de 1 MB cada;
- à direita - 2097152 peças de 1 Kbyte.
Então os dois exemplos esperam que nós os fotografemos no topo. E depois de pressionar ENTER, eles liberam memória - tudo, exceto a última peça. Isso é muito importante - a última peça permanece. E novamente eles estão esperando por nós para fotografá-los.
Abaixo está o que realmente aconteceu.

- Primeiro, os dois processos iniciaram e consumiram a memória. Parece a verdade - 2 GB RSS.
- Pressione ENTER e fique surpreso. O primeiro programa que se destacou em grandes pedaços retornou memória. Mas o segundo programa não retornou.
A resposta para o porquê disso aconteceu está no malloc do Linux.
Se solicitarmos memória em grandes pedaços, ela será emitida usando o mecanismo mmap anônimo, fornecido ao espaço de endereço do processador, de onde a memória é então cortada para nós. Quando liberamos (), a memória é liberada e as páginas são retornadas ao cache de páginas (sistema).
Se alocamos memória em pedaços pequenos, fazemos sbrk (). sbrk () desloca o ponteiro para o final do heap; em teoria, o final deslocado pode ser retornado retornando páginas de memória ao sistema se a memória não for usada.
Agora olhe para a ilustração. Tínhamos muitos registros no histórico da localização de objetos degradados e, em seguida, veio a sessão do usuário - um objeto de longa duração. Sincronizamos e todas as estruturas extras foram embora, mas o objeto de longa duração permaneceu e não podemos mover o sbrk () de volta.

Ainda temos muito espaço não utilizado que pode ser liberado se tivermos SWAP. Mas somos inteligentes - desativamos o SWAP.
Obviamente, será usada uma parte da memória desde o início do heap, mas essa é apenas uma parte, e um restante muito significativo será mantido ocupado.
O que fazer em tal situação? A resposta está abaixo.
Lançamento controlado
- Iniciamos um daemon OSD.
- Esperamos enquanto está sincronizado, verificamos os orçamentos de memória.
- Se entendermos que sobreviveremos ao início do próximo demônio, iniciaremos o próximo.
- Caso contrário, reinicie rapidamente o daemon que ocupou mais memória. Ele conseguiu ficar inativo por um curto período de tempo, ele não tem muita história, falta de locs e outras coisas, então ele come menos memória, o orçamento da memória aumentará um pouco.
- Corremos pelo cluster, controlamos e aumentamos gradualmente tudo.
- Verificamos se é possível prosseguir para o próximo OSD, vá para ele.
O DigitalOcean realmente conseguiu isso:
"Nossa equipe do Datacenter realiza aumentos de memória, enquanto outra equipe continua lentamente a criar nós enquanto gerencia manualmente o orçamento de memória de cada host".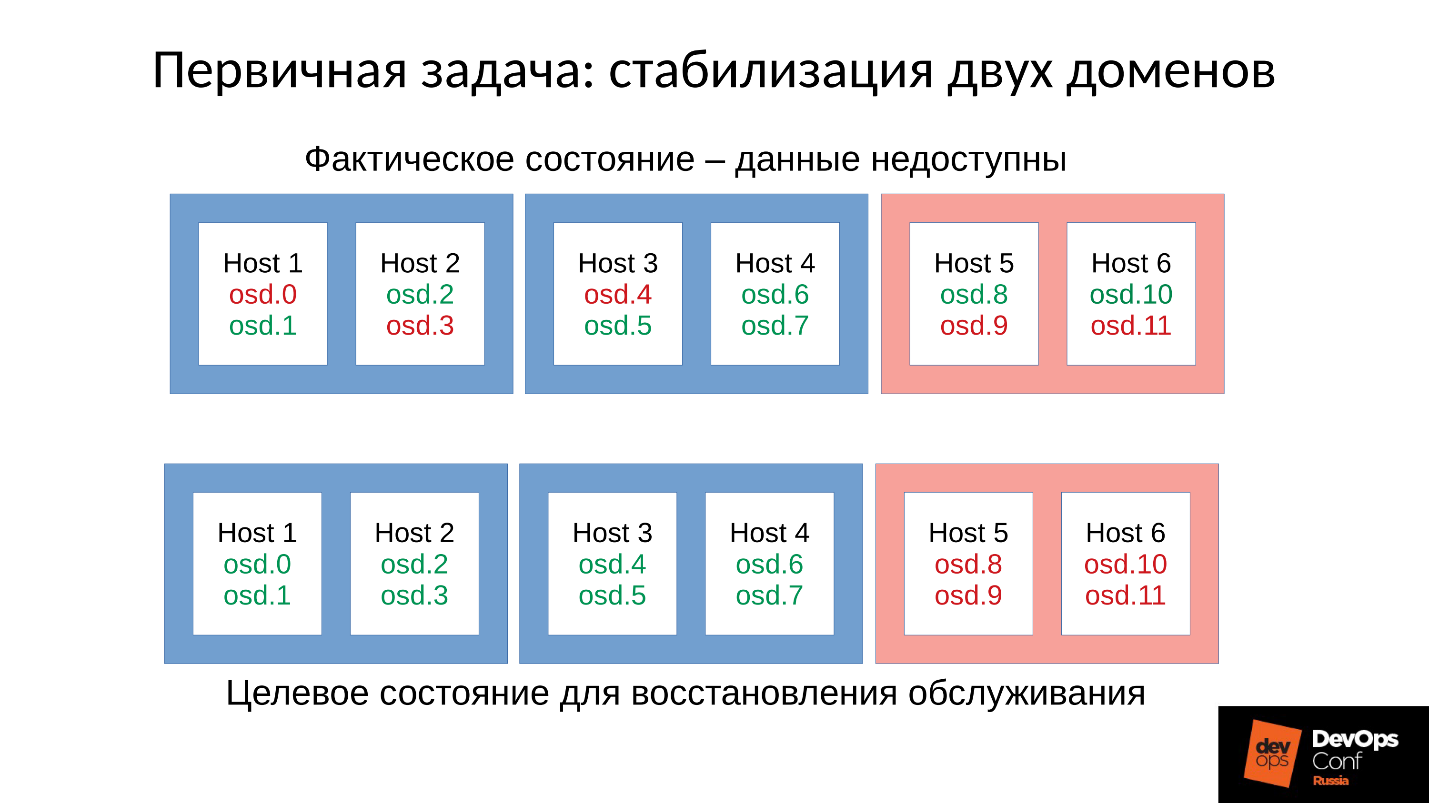
Vamos voltar à nossa configuração e situação atual. Agora, temos um cluster em colapso após uma reação em cadeia do killer de falta de memória. Proibimos o reinício automático do OSD no domínio vermelho e, um a um, iniciamos nós a partir dos domínios azuis. Porque
nossa primeira tarefa é sempre restaurar o serviço , sem entender por que isso aconteceu. Nós entenderemos mais tarde, quando restaurarmos o serviço. Em operação, esse é sempre o caso.
Trazemos o cluster para o estado de destino para restaurar o serviço e, em seguida, começamos a executar um OSD após o outro, de acordo com nossa metodologia. Observamos o primeiro, se necessário, reinicie os outros para ajustar o orçamento da memória, o próximo - 9, 10, 11 - e o cluster parece estar sincronizado e pronto para iniciar a manutenção.
O problema é como a
manutenção de gravação é realizada
no Ceph .
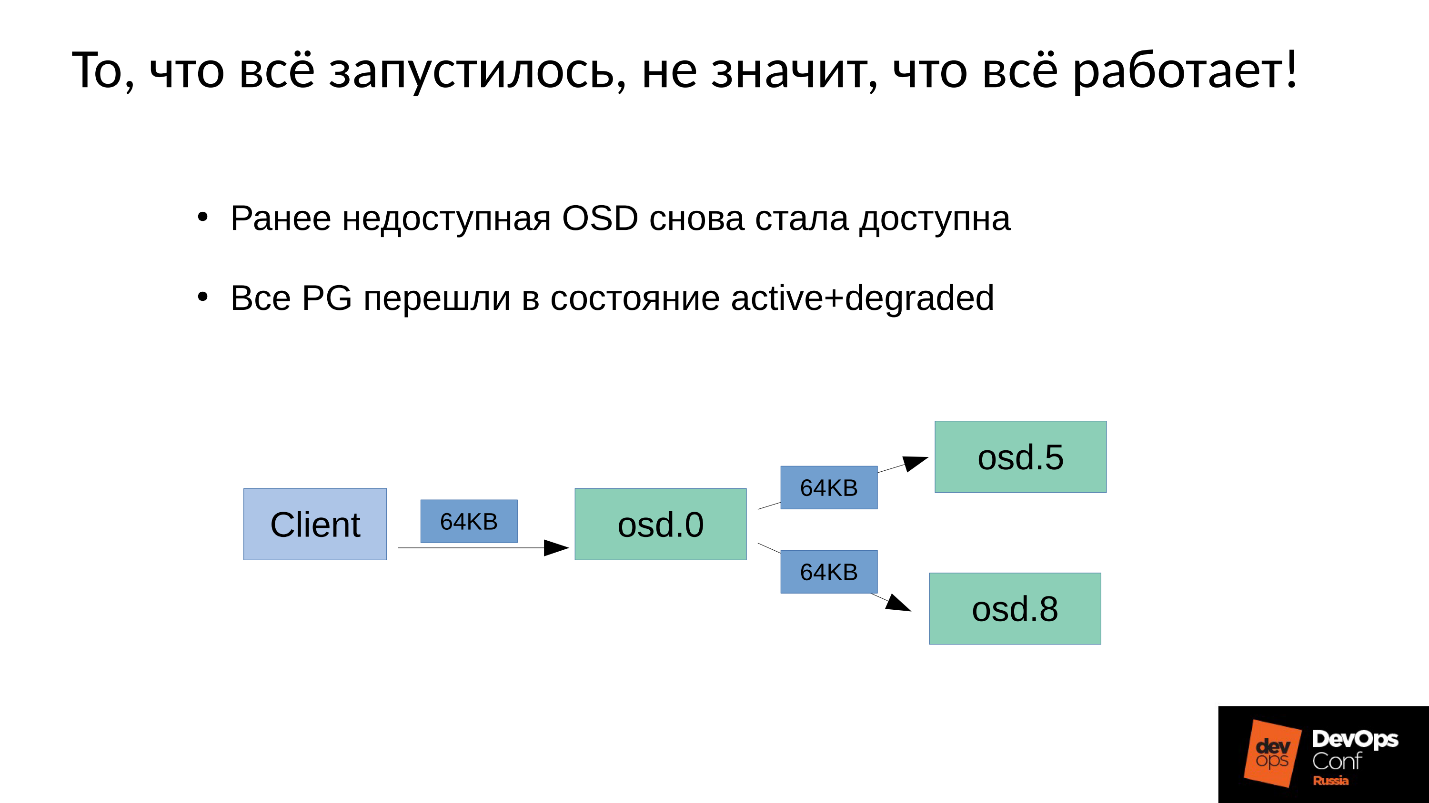
Temos três réplicas: um OSD principal e dois escravos. Esclareceremos que o mestre / escravo em cada Grupo de Colocação tem o seu, mas cada um tem um mestre e dois escravos.
A operação de gravação ou leitura cai no mestre. Ao ler, se o mestre tiver a versão correta, ele a entregará ao cliente. A gravação é um pouco mais complicada, a gravação deve ser repetida em todas as réplicas. Assim, quando o cliente grava 64 KB no OSD 0, os mesmos 64 KB do nosso exemplo vão para o OSD 5 e OSD 8.
Mas o fato é que nosso OSD 8 está muito degradado, porque reiniciamos muitos processos.

Como no Ceph qualquer mudança é uma transição de versão para versão, no OSD 0 e OSD 5, teremos uma nova versão, no OSD 8 - a antiga. , , ( 64 ) OSD 8 — 4 ( ). 4 OSD 0, OSD 8, , . , 64 .
— .

:
- 4 1 , 1000 / 1 .
- 4 ( ) 22 , 45 /.
, , , , .
— .

4 22 , 22 , 1 4 . 45 SSD, 1 —
45 .
, .
- , — (45+1) / 2 = 23 .
- 75% , (45 * 3 + 1) / 4 = 34 .
- 90% —(45 * 9 + 1) / 10 = 41 — 40 , .
Ceph, . , , , .
Ceph .

- — : , , , , .
- — latency. latency , . 100% ( , ). Latency 60 , .

, . 10 , 1 200 /, 300 , , . 10 SSD — 300 , — , - 300 .
, .
, . 900 / ( SSD). 2 500 128 ( , ESXi HyperV 128 ). degraded, 225 . file store, object store, ( ), 110 , - .
SSD 110 — !
?1: —
.

: ; PG;
.
:
- , 45 — .
- ( . ), 14 .
- , 8 ( 10% PG).
, , , , , .
2: —
(order, objectsize) .
, , , 4 2 1 . , , . :
:
(32 ) — !
3: —
Ceph .
, -,
Ceph . , , . .
, — Latency. — , — . Latency 30% , , .
Community , preproduction . , . , .
Conclusão
- , . , Ceph - , , .
●
- .
, . ,
. . , , production. , , , DigitalOcean , . , , , .
, , . , : « ! ?!» , , . , : , , down time.
●
(OSD)., , — , , - , .
OSD — — . , .
●
.OSD .
, . , , , .
●
RAM OSD.●
SWAP.SWAP Ceph' , Linux' . .
●
.100%, 10%. , , , .
●
RBD Rados Getway., .
SWAP — . , SWAP — , , , , .
Este artigo é uma transcrição do melhor relatório do DevOpsConf Russia. Em breve, abriremos o vídeo e publicaremos uma versão em texto de como os tópicos são interessantes. Inscreva-se aqui no youtube ou no boletim informativo se você não perder esses materiais úteis e esteja ciente das notícias do DevOps.