Todos nós usamos algum tipo de gerenciador de pacotes, incluindo a faxineira tia Galya, que tem um iPhone no bolso agora atualizado. Mas não há um acordo geral sobre as funções dos gerenciadores de pacotes, e os sistemas operacionais rpm e dpkg e sistemas de compilação são chamados de gerenciadores de pacotes. Oferecemos refletir sobre o tema de suas funções - o que é e por que elas são necessárias no mundo moderno. E então vamos nos aprofundar no Kubernetes e considerar cuidadosamente o Helm em termos dessas funções.
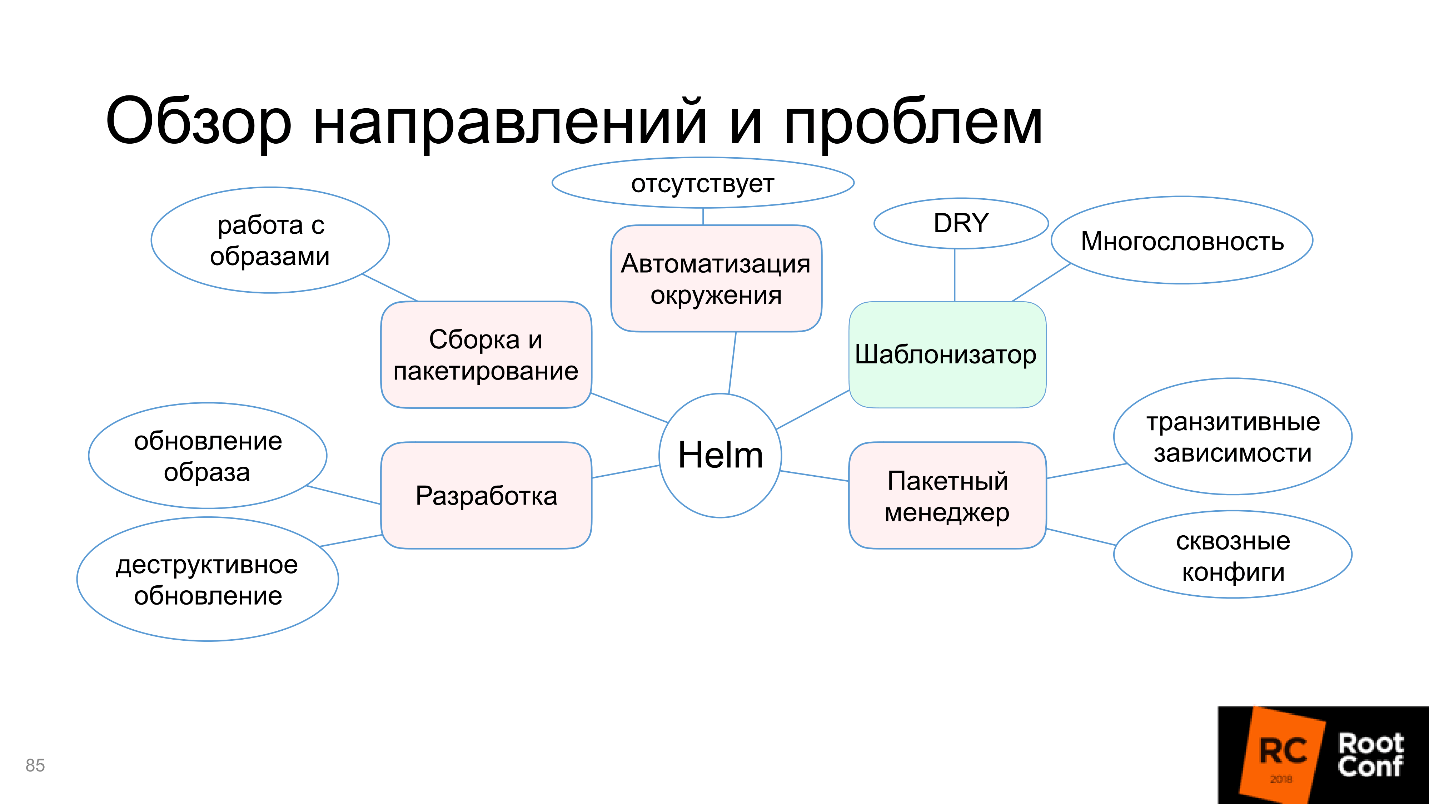
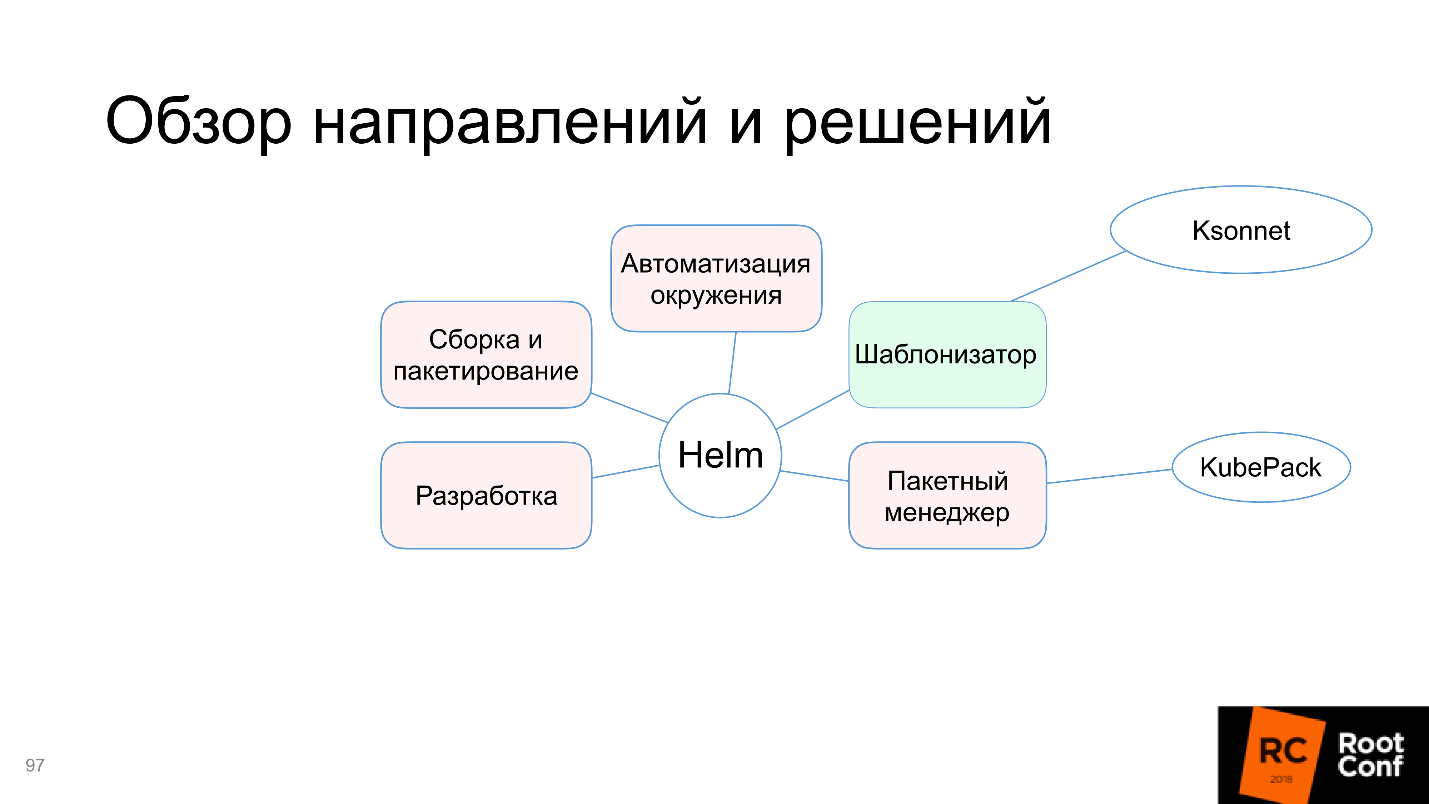
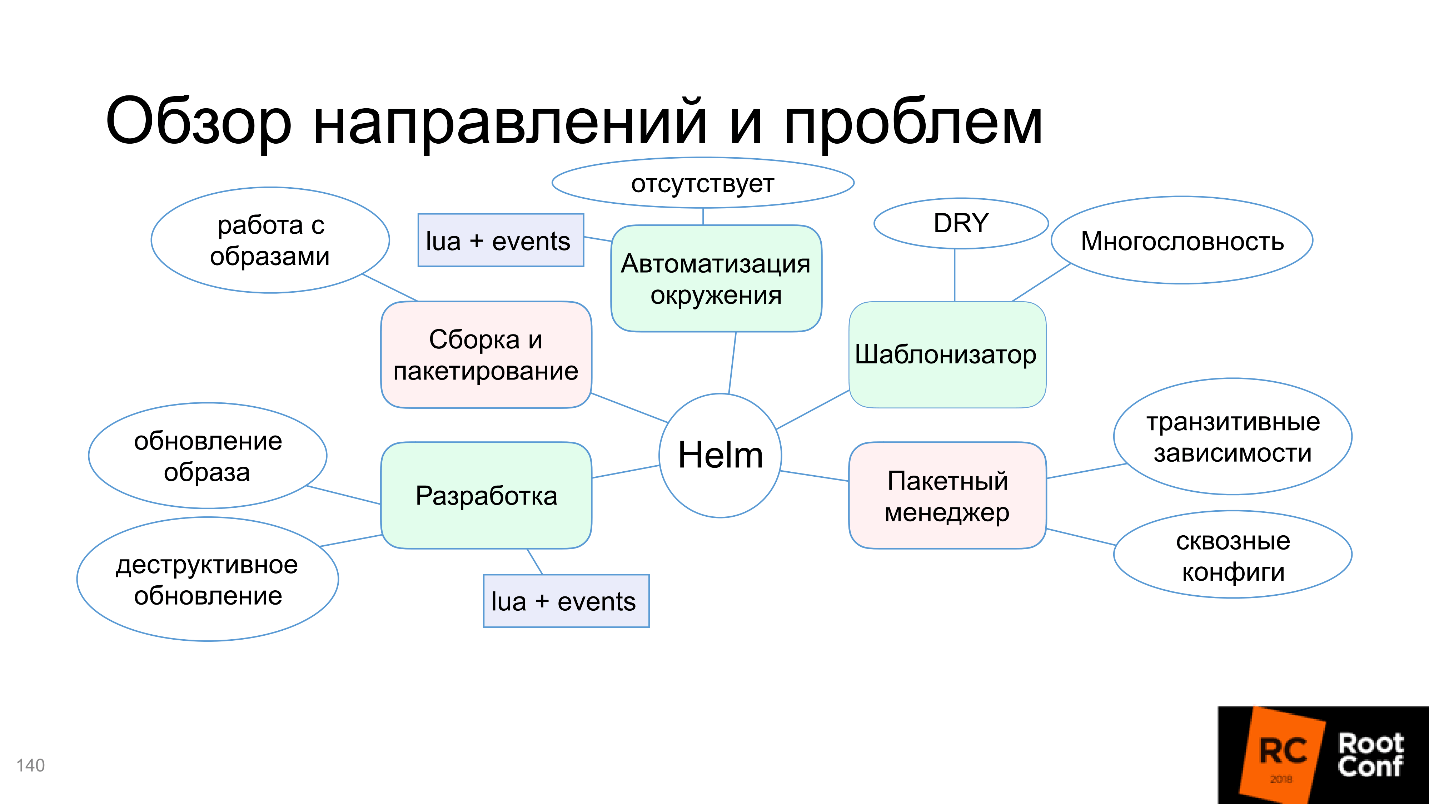
Entenderemos por que, neste diagrama, apenas a função de modelo é destacada em verde e quais são os problemas com montagem e empacotamento, automação do ambiente e muito mais. Mas não se preocupe, o artigo não termina com o fato de que tudo está ruim. A comunidade não conseguiu chegar a um acordo com isso e oferece ferramentas e soluções alternativas - vamos lidar com elas.
Ivan Glushkov (
gli ) nos ajudou nisso com seu relatório sobre o RIT ++, um vídeo e uma versão em texto desta apresentação detalhada e detalhada abaixo.
Vídeos deste e de outros discursos do DevOps sobre o RIT ++ são publicados e abertos para visualização gratuita em nosso canal do youtube - procure respostas para suas perguntas de trabalho.
Sobre o palestrante: Ivan Glushkov desenvolve software há 15 anos. Consegui trabalhar no MZ, no Echo em uma plataforma para comentários, participar do desenvolvimento de compiladores para o processador Elbrus no MCST. Atualmente, ele está envolvido em projetos de infraestrutura nos Postmates. Ivan é um dos principais podcasts do
DevZen em que eles conversam sobre nossas conferências:
aqui é sobre RIT ++ e
aqui sobre HighLoad ++.
Gerenciadores de pacotes
Embora todos usem algum tipo de gerenciador de pacotes, não existe um acordo único sobre o que é. Existe um entendimento comum, e cada um tem o seu.
Vamos lembrar que tipos de gerenciadores de pacotes vêm à mente primeiro:
- Gerenciadores de pacotes padrão de todos os sistemas operacionais: rpm, dpkg, portage , ...
- Gerenciadores de pacotes para diferentes linguagens de programação: cargo, cabal, rebar3, mix , ...
Sua principal função é executar comandos para instalar um pacote, atualizar um pacote, remover um pacote e gerenciar dependências. Nos gerenciadores de pacotes dentro das linguagens de programação, as coisas são um pouco mais complicadas. Por exemplo, existem comandos como "iniciar um pacote" ou "criar uma liberação" (compilar / executar / liberar). Acontece que este já é um sistema de compilação, embora também o chamemos de gerenciador de pacotes.

Tudo isso é devido ao fato de que você não pode simplesmente pegar e ... deixar os amantes de Haskell perdoarem essa comparação. Você pode executar o arquivo binário, mas não pode executar o programa em Haskell ou C, primeiro é necessário prepará-lo de alguma forma. E essa preparação é bastante complicada, e os usuários querem que tudo seja feito automaticamente.
Desenvolvimento
Quem trabalhou com o GNU libtool, feito para um grande projeto que consiste em um grande número de componentes, não ri do circo. Isso é realmente muito difícil, e alguns casos não podem ser resolvidos em princípio, mas só podem ser contornados.
Comparado a isso, os gerenciadores de idiomas de pacotes modernos, como o cargo para Rust, são muito mais convenientes - você pressiona o botão e tudo funciona. Embora, de fato, sob o capô, um grande número de problemas seja resolvido. Além disso, todas essas novas funções requerem algo adicional, em particular, um banco de dados. Embora no próprio gerenciador de pacotes possa ser chamado como você quiser, chamo de banco de dados, porque os dados são armazenados lá: sobre pacotes instalados, sobre suas versões, repositórios conectados, versões nesses repositórios. Tudo isso deve ser armazenado em algum lugar, para que haja um banco de dados interno.
O desenvolvimento dessa linguagem de programação, o teste dessa linguagem de programação é iniciado - tudo isso é incorporado e localizado no interior, o
trabalho se torna muito conveniente . A maioria das linguagens modernas suportou essa abordagem. Mesmo aqueles que não apoiaram começam a apoiar, porque a comunidade pressiona e diz que no mundo moderno é impossível sem ele.
Mas qualquer solução sempre tem não apenas vantagens, mas também desvantagens . A desvantagem aqui é que você precisa de invólucros, utilitários adicionais e um "banco de dados" embutido.
Docker
Você acha que o Docker é um gerenciador de pacotes ou não?
Não importa como, mas essencialmente sim. Não conheço um utilitário mais correto para reunir completamente o aplicativo com todas as dependências e fazê-lo funcionar com o clique de um botão. O que é isso se não um gerenciador de pacotes? Este é um ótimo gerenciador de pacotes!
Maxim Lapshin já
disse que com o Docker ficou muito mais fácil, e é assim. O Docker possui um sistema de compilação interno, todos esses bancos de dados, ligações, utilitários.
Qual é o preço de todos os benefícios? Quem trabalha com o Docker pensa pouco em aplicações industriais. Eu tenho essa experiência, e o preço é realmente muito alto:
- A quantidade de informações (tamanho da imagem) que devem ser armazenadas na imagem do Docker. Todas as dependências, partes de utilitários, bibliotecas devem ser empacotadas, a imagem é grande e você precisa trabalhar com ela.
- É muito mais complicado que uma mudança de paradigma esteja ocorrendo.
Por exemplo, tive a tarefa de transferir um programa para usar o Docker. O programa foi desenvolvido ao longo dos anos por uma equipe. Eu venho, fazemos tudo o que está escrito nos livros: pintamos histórias, papéis dos usuários, vemos o que e como eles fazem, suas rotinas padrão.
Eu digo:
- O Docker pode resolver todos os seus problemas. Veja como isso é feito.
- Tudo estará no botão - ótimo! Mas queremos que o SSH faça dentro dos contêineres do Kubernetes.
- Espere, não SSH em qualquer lugar.
- Sim, sim, está tudo bem ... Mas o SSH é possível?
Para transformar a percepção dos usuários em uma nova direção, leva muito tempo, é preciso trabalho educacional e muito esforço.
Outro fator de preço é que o
Docker-registry é um repositório externo de imagens, que precisa ser instalado e controlado de alguma forma. Ele tem seus próprios problemas, um coletor de lixo e assim por diante, e muitas vezes pode cair se você não o seguir, mas tudo está resolvido.
Kubernetes
Finalmente chegamos a Kubernetes. Este é um sistema de gerenciamento de aplicativos OpenSource que é suportado ativamente pela comunidade. Embora originalmente tenha saído de uma empresa, o Kubernetes agora tem uma comunidade enorme e é impossível acompanhá-la, praticamente não há alternativas.
Curiosamente, todos os nós do Kubernetes funcionam no próprio Kubernetes através de contêineres, e todos os aplicativos externos funcionam através de contêineres -
tudo funciona através de contêineres ! Isso é um mais e um menos.
O Kubernetes possui muitas funcionalidades e propriedades úteis: distribuição, tolerância a falhas, capacidade de trabalhar com diferentes serviços em nuvem e orientação para a arquitetura de microsserviço. Tudo isso é interessante e legal, mas como instalar o aplicativo no Kubernetes?
Como instalar o aplicativo?
Instale a imagem do Docker no registro do Docker.
Por trás dessa frase está um abismo. Você imagina - você tem um aplicativo escrito, digamos, em Ruby e deve colocar a imagem do Docker no registro do Docker. Isso significa que você deve:
- Preparar uma imagem do Docker
- entender como está indo, em quais versões se baseia;
- ser capaz de testá-lo;
- coletar, preencha o registro do Docker, que você já instalou antes.
De fato, é uma dor muito grande em uma linha.
Além disso, você ainda precisa descrever o manifesto do aplicativo em termos (recursos) de k8s. A opção mais fácil:
- descrever implantação + pod, serviço + ingresso (possivelmente);
- execute o comando kubectl apply -f resources.yaml e transfira todos os recursos para este comando.

Gandhi esfrega as mãos no slide - parece que eu encontrei o gerenciador de pacotes no Kubernetes. Mas o kubectl não é um gerenciador de pacotes. Ele apenas diz que eu quero ver um estado final do sistema. Isso não é instalar um pacote, não trabalhar com dependências, não criar - é apenas "Eu quero ver esse estado final".
Elmo
Finalmente chegamos a Helm. Helm é um utilitário multiuso. Agora vamos considerar quais são as áreas de desenvolvimento do Helm e trabalhar com ele.
Mecanismo de modelo
Em primeiro lugar, Helm é um mecanismo de modelo. Discutimos quais recursos precisam ser preparados, e o problema é escrever em termos de Kubernetes (e não apenas no yaml). O mais interessante é que esses são arquivos estáticos para seu aplicativo específico nesse ambiente específico.
No entanto, se você trabalha com vários ambientes e não possui apenas Produção, mas também Preparo, Teste, Desenvolvimento e ambientes diferentes para equipes diferentes, é necessário ter vários manifestos semelhantes. Por exemplo, porque em um deles existem vários servidores, e você precisa ter um grande número de réplicas e no outro - apenas uma réplica. Não há banco de dados, acesso ao RDS, e você precisa instalar o PostgreSQL dentro. E aqui temos a versão antiga e precisamos reescrever tudo um pouco.
Toda essa diversidade leva ao fato de que você precisa levar seu manifesto para o Kubernetes, copiá-lo em qualquer lugar e consertá-lo em qualquer lugar: aqui substitua um dígito, aqui está outra coisa. Isso está se tornando muito desconfortável.
A solução é simples - você precisa
inserir modelos . Ou seja, você forma um manifesto, define variáveis nele e envia as variáveis definidas externamente como um arquivo. O modelo cria o manifesto final. Acontece reutilizar o mesmo manifesto para todos os ambientes, o que é muito mais conveniente.
Por exemplo, o manifesto para Helm.

- A parte mais importante no Helm é o Chart.yaml , que descreve que tipo de manifesto é, quais versões, como funciona.
- modelos são apenas modelos de recursos do Kubernetes que contêm algum tipo de variável dentro de si. Essas variáveis devem ser definidas em um arquivo externo ou na linha de comando, mas sempre externamente.
- values.yaml é o nome padrão para o arquivo com variáveis para esses modelos.
O comando de inicialização mais simples para a instalação do gráfico é helm install ./wordpress (pasta). Para redefinir alguns parâmetros, dizemos: "Quero redefinir com precisão esses parâmetros e definir esses e esses valores".
Helm lida com essa tarefa, portanto, no diagrama, marcamos como verde.
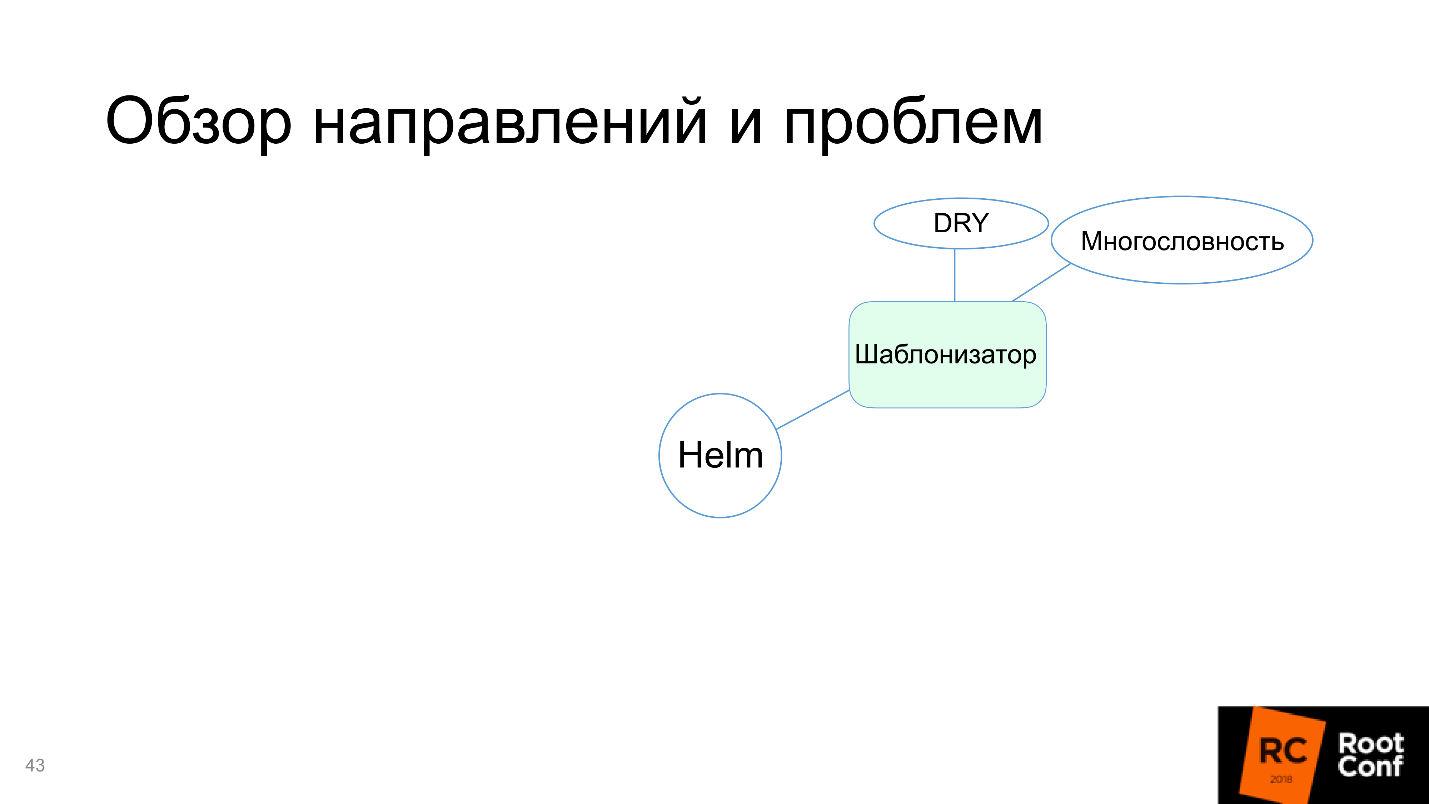
É verdade que os contras aparecem:
- Verbosidade . Os recursos são definidos completamente em termos de Kubernetes, os conceitos de níveis adicionais de abstração não são introduzidos: simplesmente escrevemos tudo o que gostaríamos de escrever para o Kubernetes e substituímos as variáveis lá.
- Não se repita - não aplicável. Muitas vezes é necessário repetir a mesma coisa. Se você tiver dois serviços semelhantes com nomes diferentes, precisará copiar completamente a pasta inteira (geralmente eles fazem isso) e alterar os arquivos necessários.
Antes de mergulhar na direção do Helm - um gerenciador de pacotes, para o qual digo tudo isso, vamos ver como o Helm trabalha com dependências.
Trabalhar com dependências
Helm é difícil trabalhar com dependências. Primeiro, existe um arquivo requirements.yaml que se encaixa no que dependemos. Enquanto trabalha com requisitos, ele faz requirements.lock - este é o estado atual (nugget) de todas as dependências. Depois disso, ele os baixa para uma pasta chamada / charts.
Existem ferramentas para gerenciar: quem, como, onde conectar -
tags e condições , com as quais é determinado em qual ambiente, dependendo de quais parâmetros externos, conectar ou não conectar algumas dependências.
Digamos que você tenha o PostgreSQL para o ambiente de armazenamento temporário (ou RDS para produção ou NoSQL para testes). Ao instalar este pacote no Production, você não instalará o PostgreSQL, porque não é necessário lá - apenas usando tags e condições.
O que é interessante aqui?
- Helm combina todos os recursos de todas as dependências e aplicativos;
- ordenar -> instalar / atualizar
Depois de baixar todas as dependências em / charts (essas dependências podem ser, por exemplo, 100), o Helm pega e copia todos os recursos internos. Depois de renderizar os modelos, ele coleta todos os recursos em um único local e classifica em algum tipo de ordem própria. Você não pode influenciar essa ordem. Você deve determinar por si mesmo do que seu pacote depende e, se o pacote tiver dependências transitivas, será necessário incluir todos eles na descrição em requirements.yaml. Isso deve ser lembrado.
Gerenciador de pacotes
O Helm instala aplicativos e dependências, e você pode dizer ao Helm install - e ele instalará o pacote. Portanto, este é um gerenciador de pacotes.
Ao mesmo tempo, se você possui um repositório externo no qual faz o upload do pacote, pode acessá-lo não como uma pasta local, mas simplesmente diz: “Neste repositório, pegue este pacote, instale-o com esses e tais parâmetros.”
Existem repositórios abertos com muitos pacotes. Por exemplo, você pode executar: helm install -f prod / values.yaml stable / wordpress
No repositório estável, você pegará o wordpress e o instalará por si mesmo. Você pode fazer tudo: pesquisar / atualizar / excluir. Acontece que Helm é um gerenciador de pacotes.
Mas há contras: todas
as dependências transitivas devem ser incluídas dentro. Esse é um grande problema quando as dependências transitivas são aplicativos independentes e você deseja trabalhar com eles separadamente para teste e desenvolvimento.
Outro ponto negativo é
a configuração de ponta a ponta . Quando você tem um banco de dados e seu nome precisa ser transferido para todos os pacotes, pode ser, mas é difícil.

Mais frequentemente, você instalou um pacote pequeno e ele funciona. O mundo é complexo: o aplicativo depende do aplicativo, que por sua vez também depende do aplicativo - você precisa configurá-los de alguma maneira inteligente. Helm não sabe como apoiar isso, ou o suporta com grandes problemas, e às vezes você precisa dançar muito com um pandeiro para fazê-lo funcionar. Como isso é ruim, o "gerenciador de pacotes" no diagrama é destacado em vermelho.
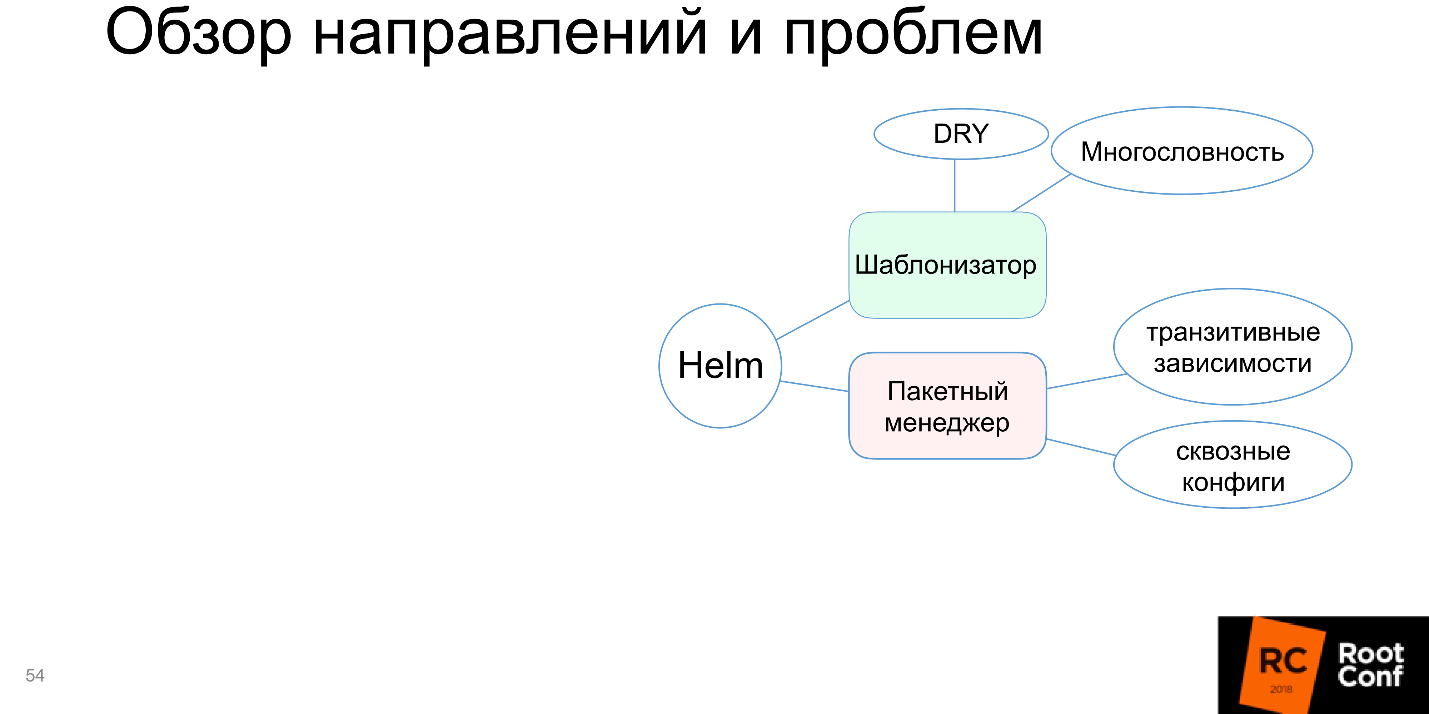
Montagem e embalagem
"Você não pode simplesmente obter e executar" o aplicativo no Kubernetes. Você precisa montá-la, ou seja, criar uma imagem do Docker, gravá-la no registro do Docker, etc. Embora toda a definição de pacote no Helm seja. Determinamos o que é o pacote, quais funções e campos devem existir, assinaturas e autenticação (o sistema de segurança da sua empresa ficará muito feliz). Portanto, por um lado, a montagem e o empacotamento parecem ter suporte e, por outro lado, o trabalho com imagens do Docker não está configurado.
O Helm não permite executar o aplicativo sem uma imagem do Docker. Ao mesmo tempo, o Helm não está configurado para montagem e empacotamento, ou seja, não sabe como trabalhar com imagens do Docker.
É o mesmo que se, para fazer uma instalação de atualização para alguma pequena biblioteca, você fosse enviado para uma pasta distante para executar o compilador.
Portanto, dizemos que Helm não sabe trabalhar com imagens.

Desenvolvimento
A próxima dor de cabeça é o desenvolvimento. No desenvolvimento, queremos alterar rápida e convenientemente nosso código. O tempo passou quando você fez furos em cartões perfurados, e o resultado foi obtido após 5 dias. Todo mundo está acostumado a substituir uma letra por outra no editor, pressionando a compilação, e o programa já modificado funciona.
Acontece aqui que, ao alterar o código, são necessárias muitas ações adicionais: prepare um arquivo Docker; Execute o Docker para criar a imagem; empurrá-lo para algum lugar; implantar no cluster Kubernetes. E somente então você obterá o que deseja na Produção e poderá verificar o código.
Ainda existem inconvenientes devido à
atualização destrutiva do leme de atualização. Você olhou como tudo funciona, através do kubectl exec você olhou dentro do container, está tudo bem. Nesse ponto, você inicia a atualização, uma nova imagem é baixada, novos recursos são lançados e os antigos são excluídos - você precisa iniciar tudo desde o início.
A maior dor são as
grandes imagens . A maioria das empresas não trabalha com aplicativos pequenos. Muitas vezes, se não um supermonólito, pelo menos um pequeno monolítico. Com o tempo, os anéis anuais aumentam, a base de código aumenta e, gradualmente, o aplicativo se torna bastante grande. Me deparei com imagens Docker com mais de 2 GB. Imagine agora que você está fazendo uma alteração em um byte no programa, pressione um botão e uma imagem do Docker de dois gigabytes começa a se agrupar. Em seguida, você pressiona o botão seguinte e a transferência de 2 GB para o servidor começa.
O Docker permite trabalhar com camadas, ou seja, verifica se há uma camada ou outra e envia a que está faltando. Mas o mundo é tal que, na maioria das vezes, será uma grande camada. Enquanto 2 GB irão para o servidor, enquanto eles irão para o Kubernetes com o registro do Docker, eles serão implementados de todas as formas, até você finalmente começar - você pode beber chá com segurança.
O Helm não oferece nenhuma ajuda com imagens grandes do Docker. Acredito que isso não deveria acontecer, mas os desenvolvedores do Helm sabem melhor do que todos os usuários, e Steve Jobs sorri.

O bloco com o desenvolvimento também ficou vermelho.
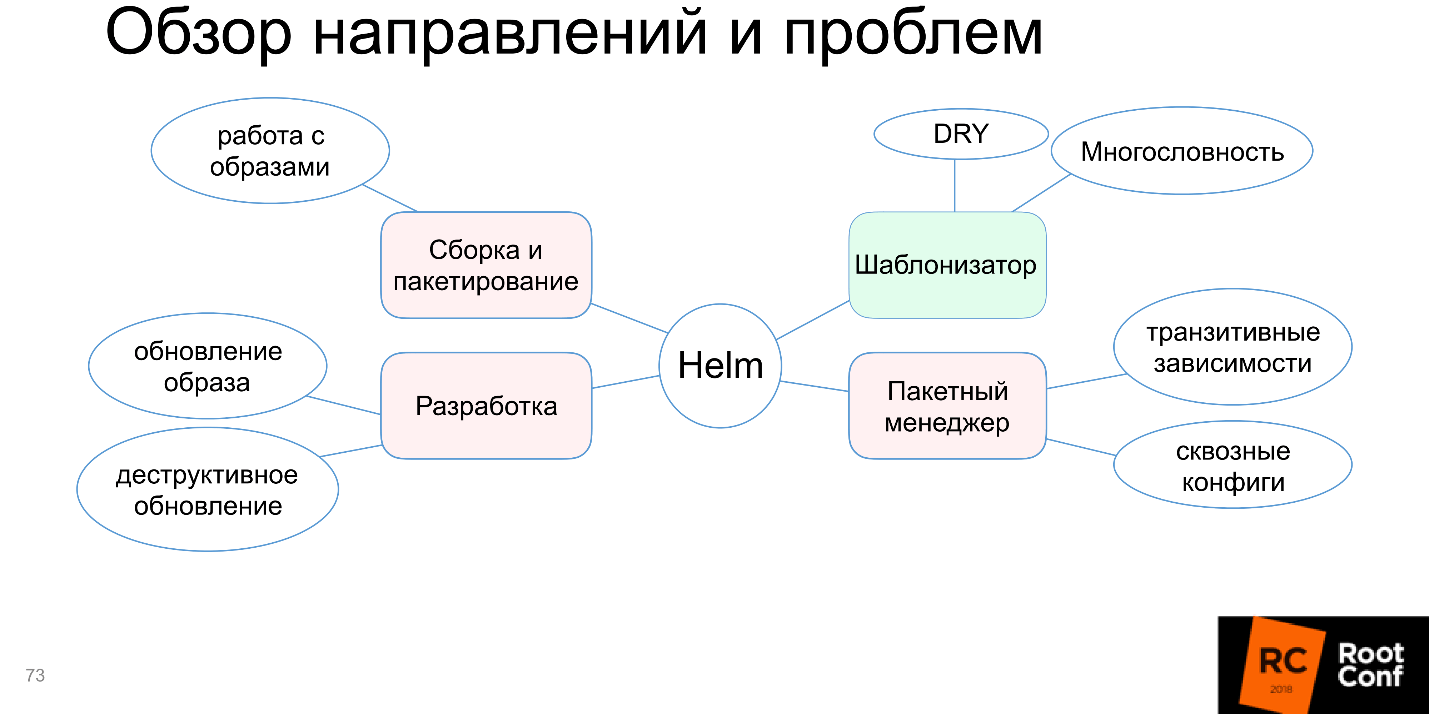
Automação de ambiente
A última direção - automação do ambiente - é uma área interessante. Antes do mundo do Docker (e do Kubernetes, como um modelo relacionado), não havia como dizer: "Quero instalar meu aplicativo neste servidor ou nesses servidores para que haja n réplicas, 50 dependências e tudo funcione automaticamente!" Pode-se dizer que tal era, mas não era!
O Kubernetes fornece isso e é lógico usá-lo de alguma forma, por exemplo, para dizer: "Estou implantando um novo ambiente aqui e quero que todas as equipes de desenvolvimento que prepararam seus aplicativos possam clicar em um botão e todos esses aplicativos sejam instalados automaticamente no novo ambiente" . Teoricamente, o Helm deve ajudar nisso, para que a configuração possa ser obtida de uma fonte de dados externa - S3, GitHub - de qualquer lugar.
É aconselhável que exista um botão especial no Helm "Faça-me o bem, finalmente!" - e isso imediatamente se tornaria bom. O Kubernetes permite que você faça isso.
Isso é especialmente conveniente porque o Kubernetes pode ser executado em qualquer lugar e funciona através da API. Ao iniciar o minikube localmente, na AWS ou no Google Cloud Engine, você obtém o Kubernetes imediatamente e trabalha da mesma maneira em qualquer lugar: pressione um botão e tudo ficará bem imediatamente.
Parece que, naturalmente, o Helm permite que você faça isso. Porque, caso contrário, qual era o objetivo de criar o Helm em geral?
Mas acontece que não!
Não há automação do ambiente.
Alternativas
Quando existe um aplicativo do Kubernetes que todos usam (agora é a solução número 1), mas Helm tem os problemas discutidos acima, a comunidade não pôde deixar de responder. Começou a criar ferramentas e soluções alternativas.
Mecanismos de modelo
Parece que, como um mecanismo de modelo, Helm resolveu todos os problemas, mas ainda assim a comunidade cria alternativas. Deixe-me lembrá-lo dos problemas do mecanismo de modelo: verbosidade e reutilização de código.
Um bom representante aqui é o
Ksonnet. Ele usa um modelo fundamentalmente diferente de dados e conceitos e não funciona com os recursos do Kubernetes, mas com suas próprias definições:
protótipo (parâmetros) -> componente -> aplicativo -> ambientes.
Existem partes que compõem o protótipo. O protótipo é parametrizado por dados externos e o componente é exibido. Vários componentes compõem um aplicativo que você pode executar. É executado em diferentes ambientes. Existem alguns links claros para os recursos do Kubernetes aqui, mas pode não haver uma analogia direta.
O principal objetivo do Ksonnet era, é claro,
reutilizar recursos . Eles queriam garantir que, depois de escrever o código, você pudesse usá-lo posteriormente em qualquer lugar, o que aumenta a velocidade do desenvolvimento. Se você criar uma grande biblioteca externa, as pessoas poderão publicar seus recursos constantemente, e toda a comunidade poderá reutilizá-los.
Teoricamente, isso é conveniente. .
, — , , . Ksonnet . Ksonnet Helm , , .. , , , .

, , , , . . , , , 0.1. , .
, —
KubePack , .
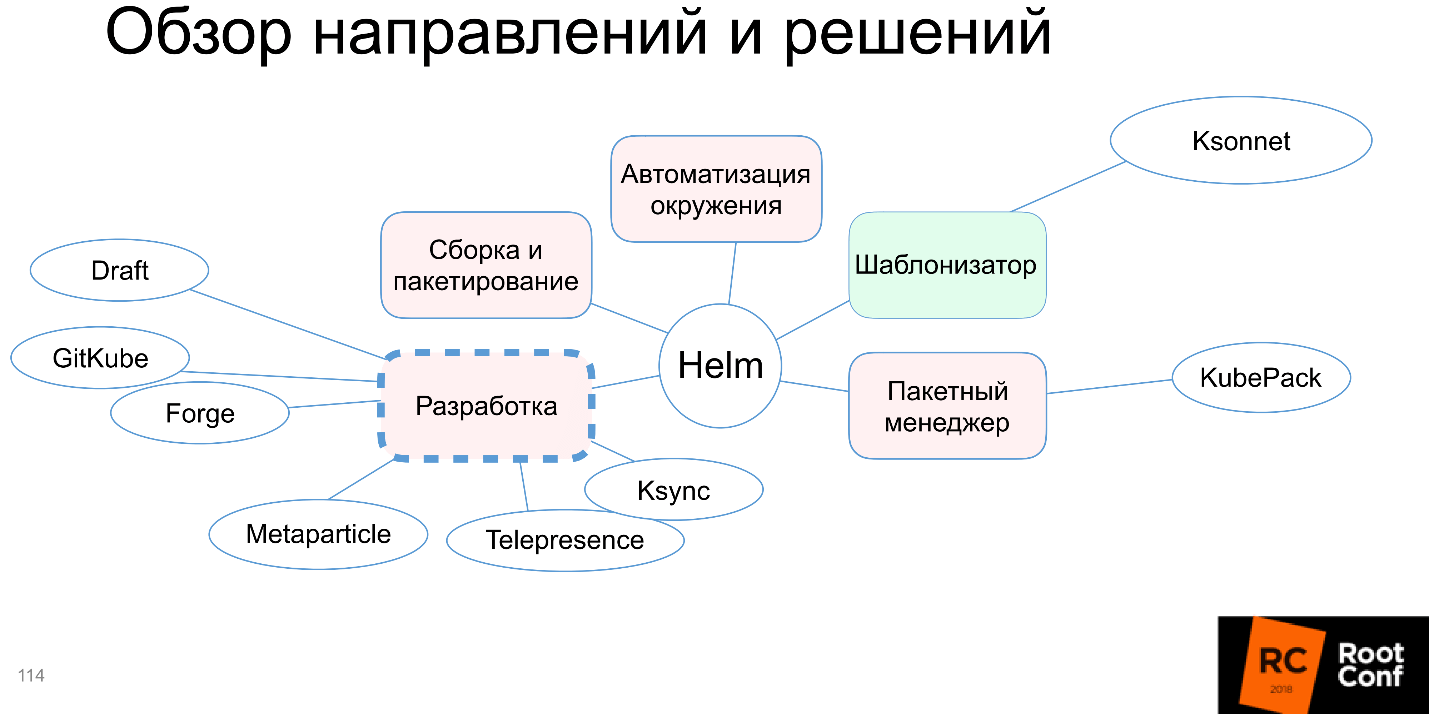
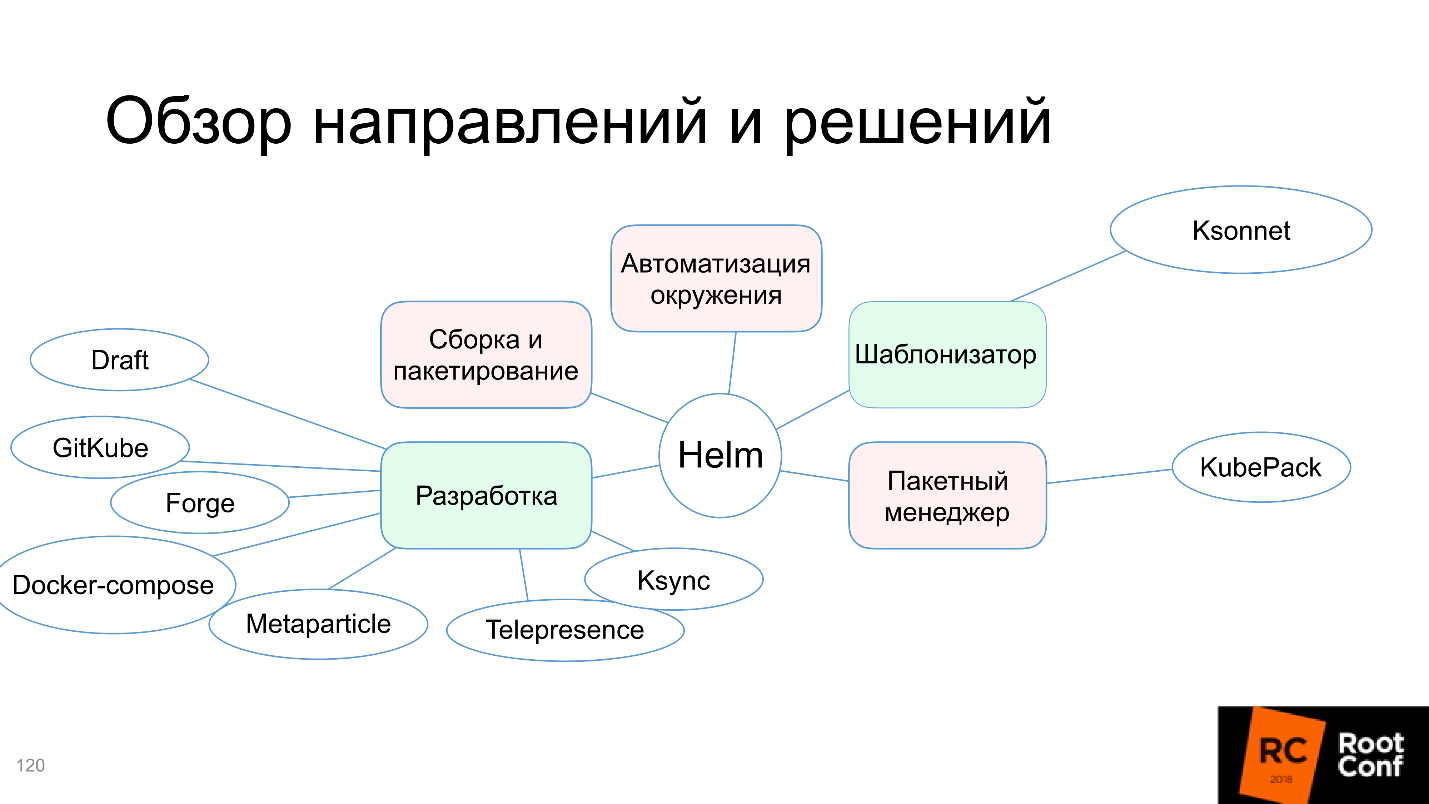
Desenvolvimento
:
- Helm;
- Helm;
- , ;
- , .
1. Helm
—
Draft . — , , . Draft — Heroku-style:
- (pack);
- , , Python «Hello, world!»;
- , Docker- ( );
- , , docker-registry, ;
- .
, , .
Helm, Draft Helm-, production ready, , Draft Helm-, . .
, Draft , Helm-. Draft — .
2. Helm
Helm Charts Kubernetes-, Helm Charts. :
Helm, . , , command line interface, Chart , git push .
, docker build, docker push kubectl rollout. , Helm, . .
3.
— . —
Metaparticle . , Python, Python , .
, , , sysconfig .. .
, , , - Kubernetes-.
: , ; , ; ..

, , , - , Python- Kubernetes-. ?
- , . . , , preinstall , - . Kubernetes-, Metaparticle, .
, , Kubernetes- . , , Metaparticle.
Metaparticle, Helm . , .
Telepresence/Ksync — . , , Helm-, . , - , - , , . , Production-, Production - .
Kubernetes , Docker, registry, Kubernetes. . , .
, , , Development . : , , , , — , , , Helm, , .
, .
4. Kubernetes Kubernetes
, Kubernetes Kubernetes. , Helm- , . , . , Docker-compose .
Docker-compose , , , , Docker, Kubernetes, Docker-compose, . , . , Docker. .
minikube , Docker-compose, . , , Docker-compose — 10 . , .
Docker-compose, , .
, — Helm, , , Helm - . CI/CD, , . — Helm, ? , , .
CI/CD, , docker', set-, , — .
CI/CD — , .
Sumário

5 Helm . , . , , . , , , .
Helm
, , Helm . , Helm , . , , , Helm.
, Road Map.
Kuberneres Helm community , ,
Helm V3 .
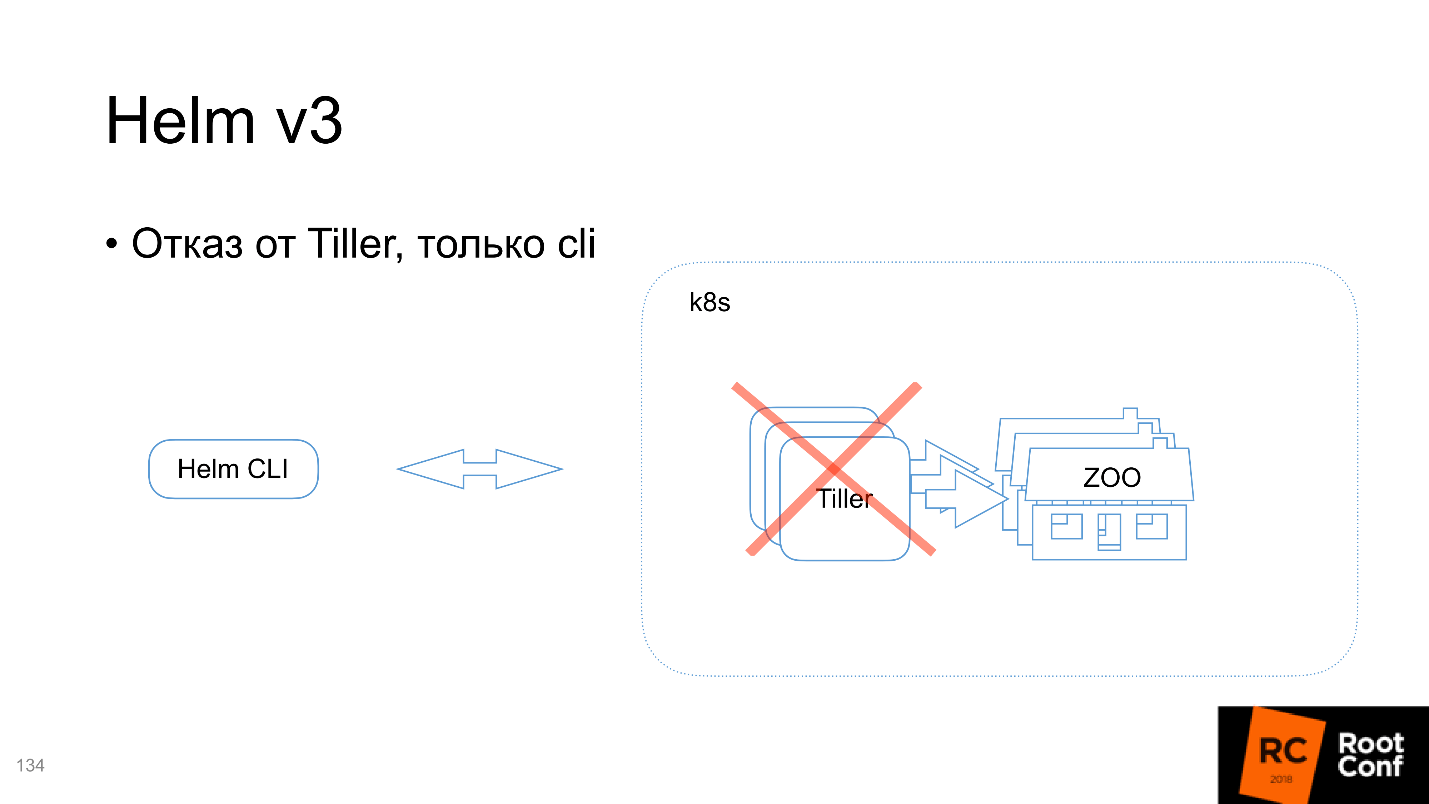
Tiller, cli
, . Helm :
- , (cmd ..).
- Tiller — , Kubernetes.
Tiller , Command Line Interface. : « Chart» — Helm , , Tiller', : «, - ! , Kubernetes-» — .
Helm, Tiller , . , , , , Tiller' — namespace . Tiller namespace, , . , .
V3 Tiller .
? , , Command Line Interface, , Kubernetes. , Kubernetes , Tiller. kubectl cli .
Tiller
. , Kubernetes Command Line Interface : , , , pre- post-. .
Lua- Chart
, — ,
lua- . Chart lua-, . . , . , , , .
Lua , , , - , , .
, , . , . Kubernetes, - , , , , . Vamos ver o que acontece.
Release- + secret
, ,
Release- , Release . , Release-, , , CRD, , .
namespace
Release- namespace, , -
Tiller' namespace — , .
CRD: controller
, CRD-controller Helm , push-. .
, .

,
Helm . , , , . , , . Helm — - Kubernetes. - , , .
,
CI/CD , .
Slack, temos um bot que informa quando uma nova compilação é aprovada no master e que todos os testes foram bem-sucedidos. Você diz a ele: "Quero instalar isso no Staging" - e ele instala, você diz: "Quero executar um teste lá!" - e ele começa. Bastante confortável.Para o desenvolvimento, use Docker-composite ou Telepresence.Várias versões de um serviço
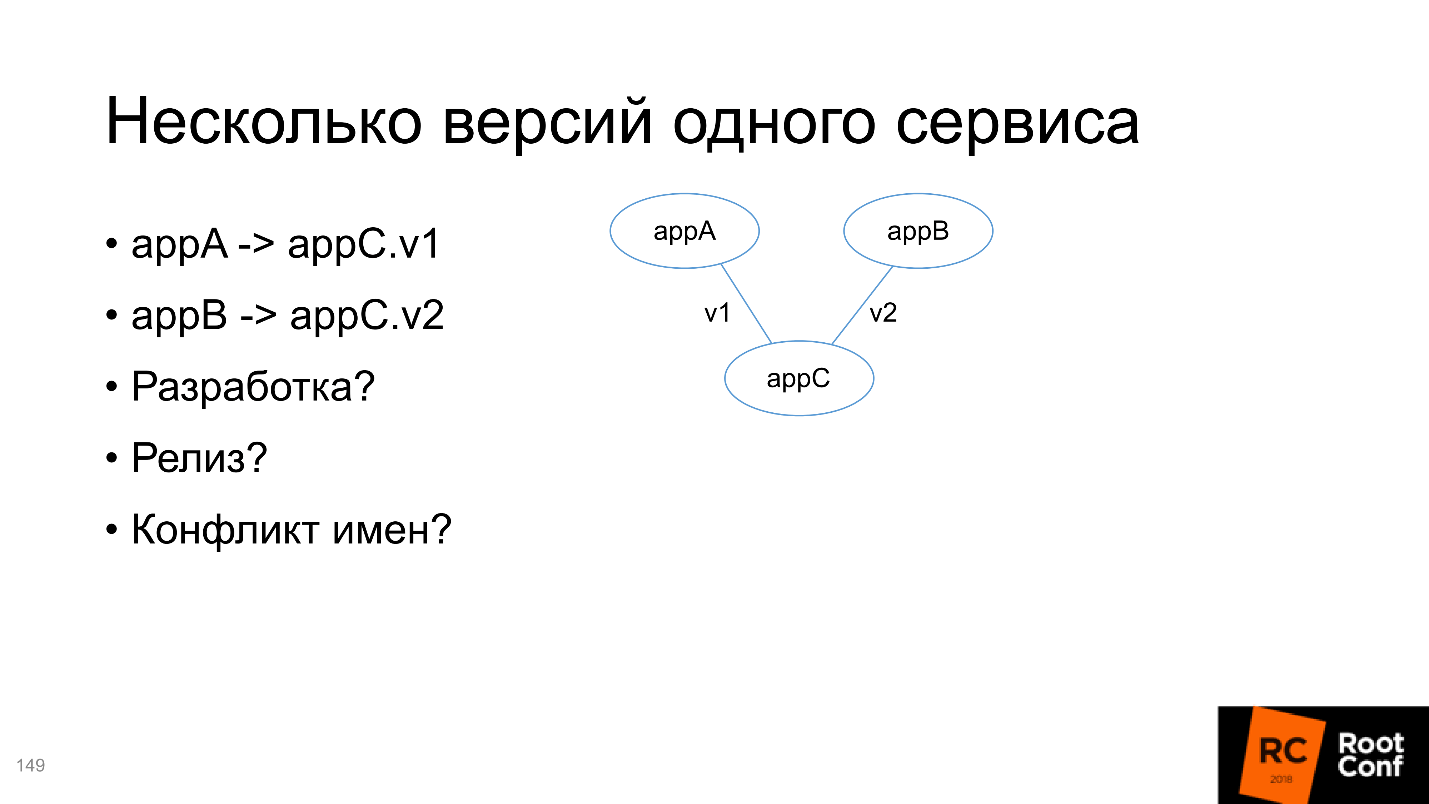
No final, analisaremos a situação quando houver dois aplicativos A e B, que dependem de C, mas C de versões diferentes. Precisa resolver este problema:
- para desenvolvimento, porque de fato temos que desenvolver a mesma coisa, mas duas versões diferentes;
- para liberação;
- para um conflito de nome, porque em todos os gerenciadores de pacotes padrão, a instalação de dois pacotes de versões diferentes pode causar problemas.
De fato, o Kubernetes decide tudo por nós - você só precisa usá-lo corretamente.

Eu recomendaria a criação de 4 gráficos em termos de Helm, 3 repositórios (para o repositório C, serão apenas duas ramificações diferentes). O mais interessante é que todas as instalações da v1 e da v2 devem conter dentro de si informações sobre a versão ou para qual serviço foi criado. Uma solução no slide, apêndice C; o nome do release indica que esta é a versão v1 do serviço A; o nome do serviço também contém a versão. Este é o exemplo mais simples, você pode fazer isso de maneira completamente diferente. Mas o mais importante é que os nomes sejam únicos.
O segundo são dependências transitivas, e aqui é mais complicado.
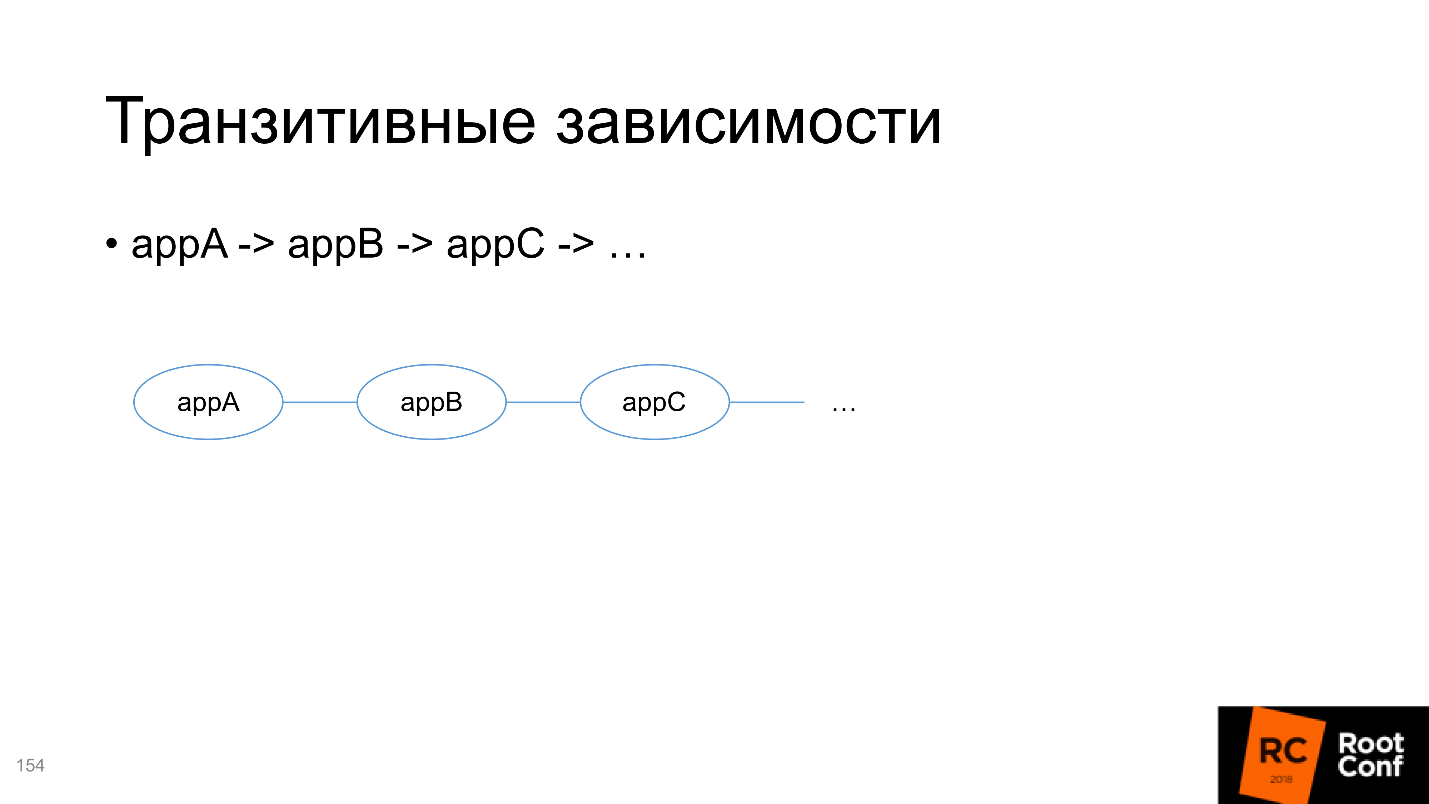
Por exemplo, você está desenvolvendo uma cadeia de serviços e deseja testar A. Para isso, você deve passar todas as dependências das quais A depende, incluindo transitivas, para a definição Helm do seu pacote. Mas, ao mesmo tempo, você deseja desenvolver B e também testá-lo - como fazer isso é incompreensível, porque você precisa colocar todas as dependências transitivas nele também.
Portanto, aconselho você a não adicionar todas as dependências dentro de cada pacote, mas torná-las independentes e controlar externamente o que está sendo executado. Isso é inconveniente, mas é o menor dos dois males.
Links úteis
•
Rascunho•
GitKube•
leme•
Ksonnet• Adesivos de telegrama:
um ,
dois•
Sig-Apps•
KubePack•
Metaparícula•
Skaffold•
leme v3•
Docker-compor•
Ksync•
Telepresença•
Drone•
ForjarPerfil do palestrante Ivan Glushkov no
GitHub , no
twitter , no
Habr .
Ótimas notícias
Em nosso canal no youtube, abrimos um vídeo de todos os relatórios sobre DevOps do festival RIT ++ . Esta é uma lista de reprodução separada, mas na lista completa de vídeos há muitas coisas úteis de outras conferências.
Melhor ainda, assine o canal e a newsletter , porque no próximo ano teremos muitos devops : em maio, o framework do RIT ++; na primavera, verão e outono como uma seção do HighLoad ++ e um outono separado do DevOpsConf na Rússia .