Existem várias maneiras de lidar com erros nas linguagens de programação:
- exceções padrão para muitas linguagens (Java, Scala e outras JVMs, python e muitas outras)
- códigos ou sinalizadores de status (Go, bash)
- várias estruturas de dados algébricos, cujos valores podem ser resultados bem-sucedidos e descrições de erros (Scala, haskell e outras linguagens funcionais)
As exceções são usadas muito amplamente, por outro lado, costumam ser lentas. Mas os oponentes de uma abordagem funcional frequentemente apelam para o desempenho.
Recentemente, tenho trabalhado com o Scala, onde também posso usar exceções e vários tipos de dados para o tratamento de erros. Por isso, pergunto-me qual abordagem será mais conveniente e mais rápida.
Descartaremos imediatamente o uso de códigos e sinalizadores, pois essa abordagem não é aceita nos idiomas da JVM e, na minha opinião, é muito propensa a erros (peço desculpas pelo trocadilho). Portanto, compararemos exceções e diferentes tipos de ADT. Além disso, o ADT pode ser considerado como o uso de códigos de erro em um estilo funcional.
UPDATE : exceções sem rastreamento de pilha são adicionadas à comparação
Participantes
Um pouco mais sobre tipos de dados algébricosPara aqueles que não estão muito familiarizados com o ADT ( ADT ) - um tipo algébrico consiste em vários valores possíveis, cada um dos quais pode ser um valor composto (estrutura, registro).
Um exemplo é o tipo Option[T] = Some(value: T) | None Option[T] = Some(value: T) | None , que é usado em vez de nulos: um valor desse tipo pode ser Some(t) se houver um valor, ou None se não houver.
Outro exemplo seria Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) , que descreve o resultado de um cálculo que pode ser concluído com êxito ou com erro.
Então, nossos concorrentes:
- Boas exceções antigas
- Exceções sem um rastreamento de pilha, pois o preenchimento de um rastreamento de pilha é uma operação muito lenta
Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) - as mesmas exceções, mas em um wrapper funcionalEither[String, T] = Left(error: String) | Right(value: T) Either[String, T] = Left(error: String) | Right(value: T) - um tipo que contém o resultado ou uma descrição do erroValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) ValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) - um tipo da biblioteca Cats , que, no caso de um erro, pode conter várias mensagens sobre erros diferentes (a List não List usada lá, mas não importa)
OBSERVAÇÃO Em essência, as exceções são comparadas com o rastreamento de pilha, sem e ATD, mas vários tipos são selecionados, pois o Scala não possui uma abordagem única e é interessante comparar várias.
Além das exceções, as strings são usadas para descrever erros, mas com o mesmo sucesso em uma situação real, diferentes classes seriam usadas ( Either[Failure, T] ).
O problema
Para testar o tratamento de erros, resolvemos o problema de análise e validação de dados:
case class Person(name: String, age: Int, isMale: Boolean) type Result[T] = Either[String, T] trait PersonParser { def parse(data: Map[String, String]): Result[Person] }
isto é tendo dados brutos Map[String, String] é necessário obter Person ou um erro se os dados não forem válidos.
Arremesso
Uma solução para a testa usando exceções (daqui em diante darei apenas a função person , você pode ver o código completo no github ):
Throwparser.scala
def person(data: Map[String, String]): Person = { val name = string(data.getOrElse("name", null)) val age = integer(data.getOrElse("age", null)) val isMale = boolean(data.getOrElse("isMale", null)) require(name.nonEmpty, "name should not be empty") require(age > 0, "age should be positive") Person(name, age, isMale) }
here string , integer e boolean validam a presença e o formato de tipos simples e realizam a conversão.
Em geral, é bastante simples e compreensível.
ThrowNST (sem rastreamento de pilha)
O código é o mesmo do caso anterior, mas as exceções são usadas sem um rastreamento de pilha sempre que possível: ThrowNSTParser.scala
Experimente
A solução captura exceções anteriormente e permite combinar os resultados via for (não deve ser confundido com loops em outros idiomas):
TryParser.scala
def person(data: Map[String, String]): Try[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
um pouco mais incomum para um olho frágil, mas devido ao uso de for , é muito semelhante à versão com exceções, além disso, a validação da presença de um campo e a análise do tipo desejado ocorrem separadamente (o flatMap pode ser lido aqui como and then )
Ou
Aqui, o tipo Either está oculto por trás do alias Result pois o tipo de erro foi corrigido:
EitherParser.scala
def person(data: Map[String, String]): Result[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
Como o padrão Either como Try forma uma mônada no Scala, o código saiu exatamente o mesmo, a diferença aqui é que a string aparece aqui como um erro e as exceções são minimamente usadas (apenas para manipular erros ao analisar um número)
Validado
Aqui a biblioteca Cats é usada para não obter a primeira coisa que aconteceu, mas o máximo possível (por exemplo, se vários campos não forem válidos, o resultado conterá erros de análise para todos esses campos)
ValidatedParser.scala
def person(data: Map[String, String]): Validated[Person] = { val name: Validated[String] = required(data.get("name")) .ensure(one("name should not be empty"))(_.nonEmpty) val age: Validated[Int] = required(data.get("age")) .andThen(integer) .ensure(one("age should be positive"))(_ > 0) val isMale: Validated[Boolean] = required(data.get("isMale")) .andThen(boolean) (name, age, isMale).mapN(Person) }
esse código já é menos semelhante à versão original, com exceções, mas a verificação de restrições adicionais não é separada dos campos de análise e ainda temos vários erros em vez de um, vale a pena!
Teste
Para o teste, um conjunto de dados foi gerado com uma porcentagem diferente de erros e analisado em cada uma das maneiras.
Resultado em todas as porcentagens de erros:

Mais detalhadamente, com uma baixa porcentagem de erros (o tempo é diferente aqui desde que uma amostra maior foi usada):
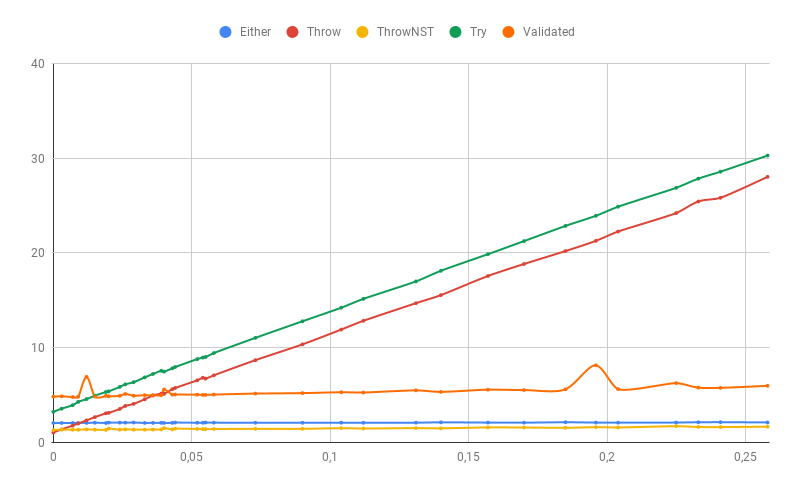
Se alguma parte dos erros ainda for uma exceção no rastreamento de pilha (no nosso caso, o erro de analisar o número será uma exceção que não controlamos), é claro que o desempenho dos métodos de tratamento de erros “rápidos” se deteriorará significativamente. Validated especialmente afetado, pois coleta todos os erros e, como resultado, recebe uma exceção lenta mais do que outros:

Conclusões
Como o experimento mostrou, as exceções com rastreios de pilha são realmente muito lentas (100% dos erros são a diferença entre Throw e E mais de 50 vezes!) E, quando praticamente não há exceções, o uso do ADT tem um preço. No entanto, o uso de exceções sem rastreios de pilha é tão rápido (e com uma baixa porcentagem de erros mais rápido) quanto o ADT; no entanto, se essas exceções vão além da mesma validação, o rastreamento de sua origem não será fácil.
No total, se a probabilidade de uma exceção for superior a 1%, as exceções sem rastreios de pilha funcionarão mais rapidamente, Validated ou regulares Either quase tão rápidas. Com um grande número de erros, Either pode ser um pouco mais rápido que o Validated devido à semântica de falha rápida.
O uso do ADT para tratamento de erros fornece outra vantagem sobre as exceções: a possibilidade de um erro está ligada ao próprio tipo e é mais difícil de ser perdida, como ao usar Option vez de nulos.