Oi Esta é uma história sobre o que há de novo em nosso plug-in de banco de dados. Nós o liberamos como um produto
DataGrip separado e o enviamos para quase todos os outros IDEs. Haverá muitas fotos e gifs. Para quem tem preguiça de vê-los:
- Suporte de Cassandra
- Criando arquivos SQL a partir de objetos de esquema
- Novas inspeções
- Muitas novas peças de preenchimento automático
- Trabalhar com uma fonte de dados através de uma conexão
- Nova pesquisa
- Esquema de cores de alto contraste
Obrigado àqueles que experimentam a versão do EAP e relatam problemas ao nosso rastreador: isso ajuda a não arrastá-los para o lançamento :) Usuários ativos já recebem assinaturas gratuitas há um ano.

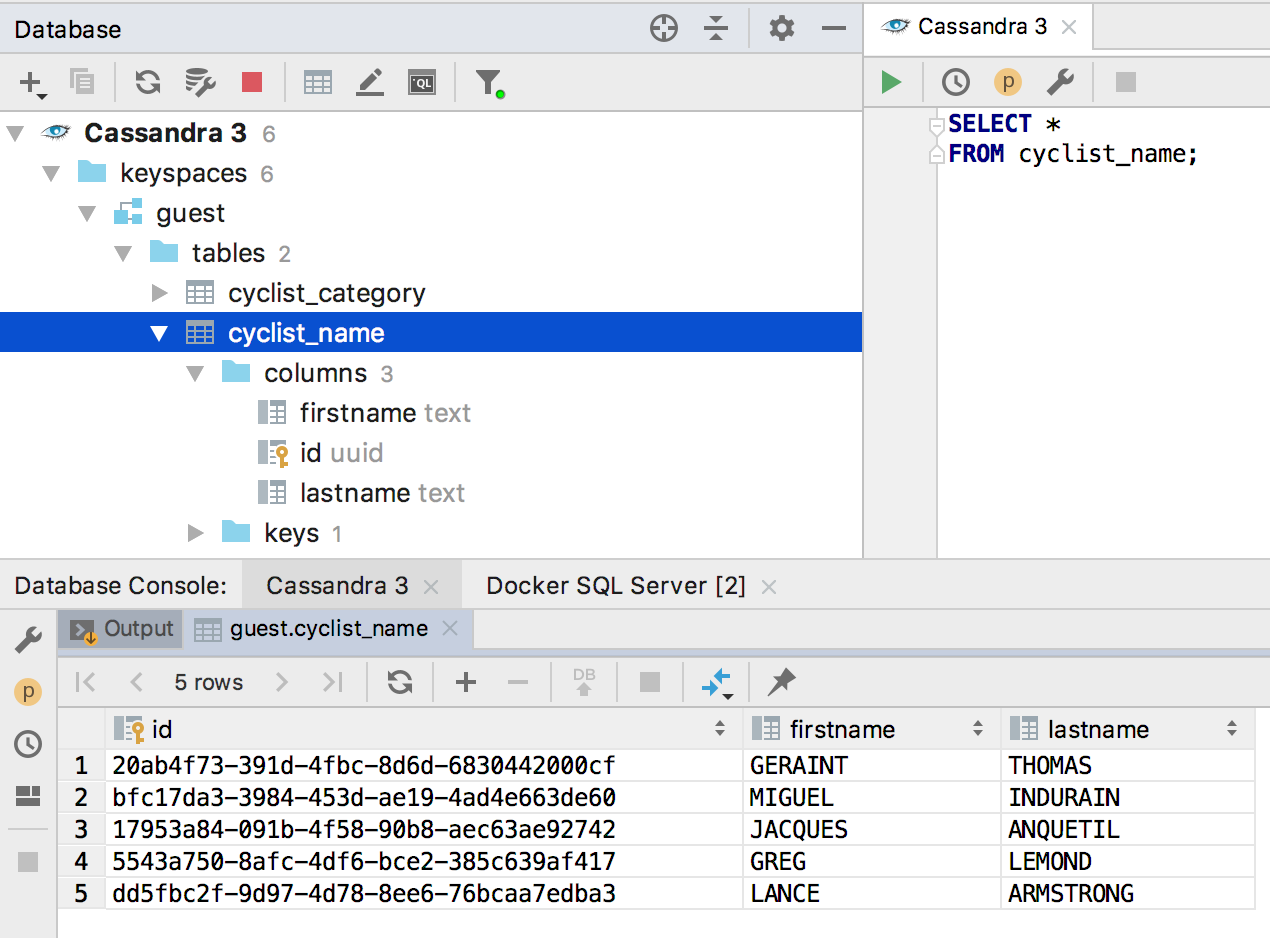
Suporte de Cassandra
Estamos dominando lentamente os bancos de dados NoSQL. Até o momento, apenas aqueles que usam linguagens semelhantes ao SQL para consultas. Apoiamos o Clickhouse em
2018.2.2 e, nesta versão, adicionamos o Cassandra.
Conclusão automática
Há muitas novidades neste subsistema.
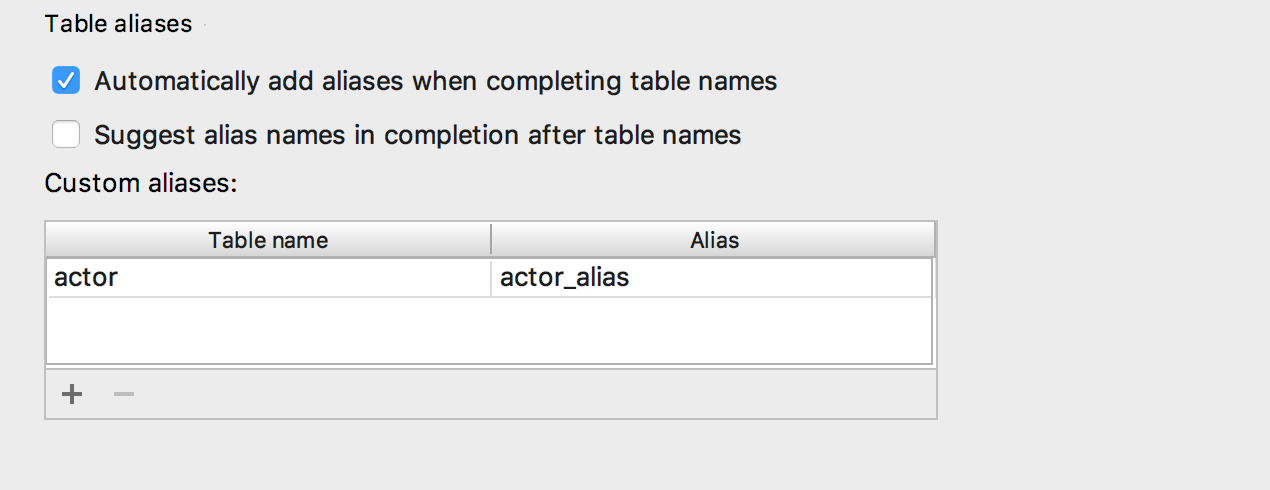
Adicionada a capacidade de inserir
aliases automaticamente após os nomes das tabelas. Se o pseudônimo proposto por nós não combina com você, indique quais pseudônimos devem ser usados para nomes específicos.
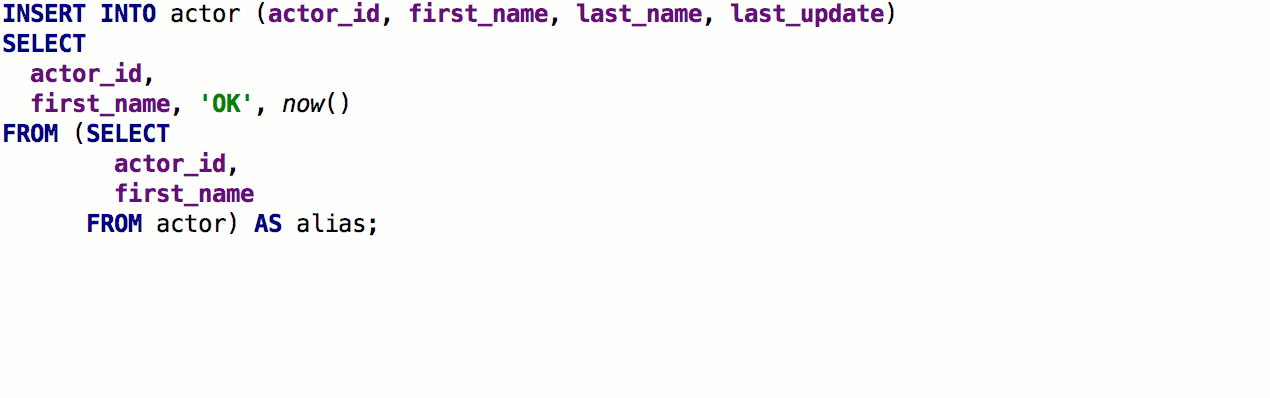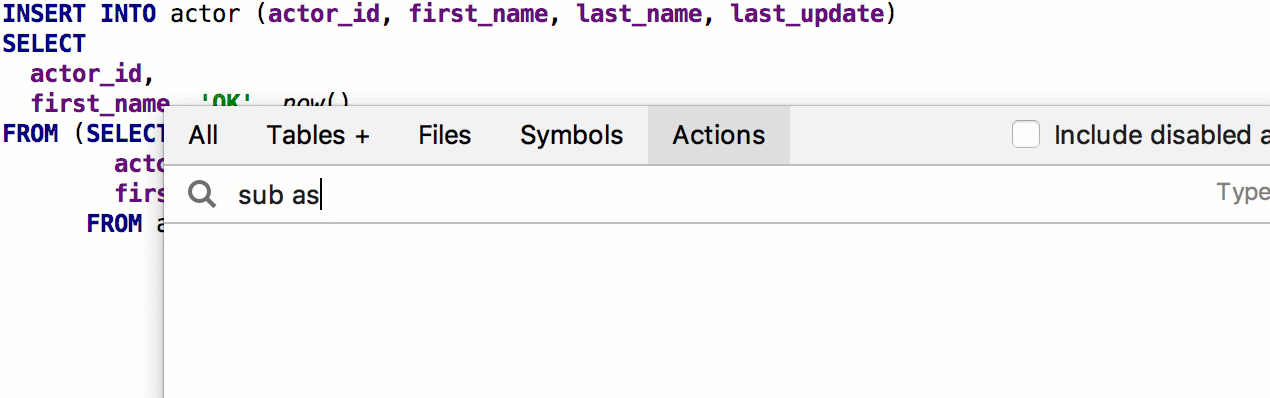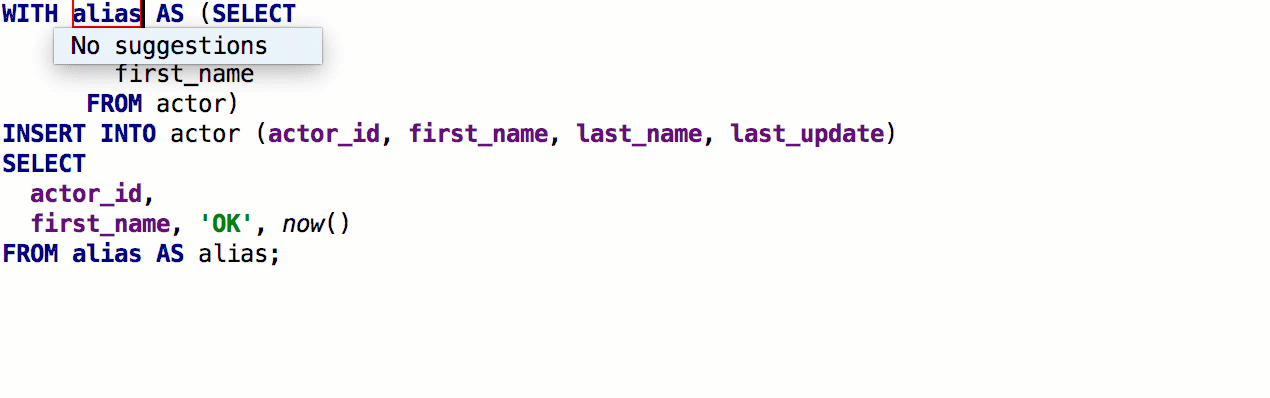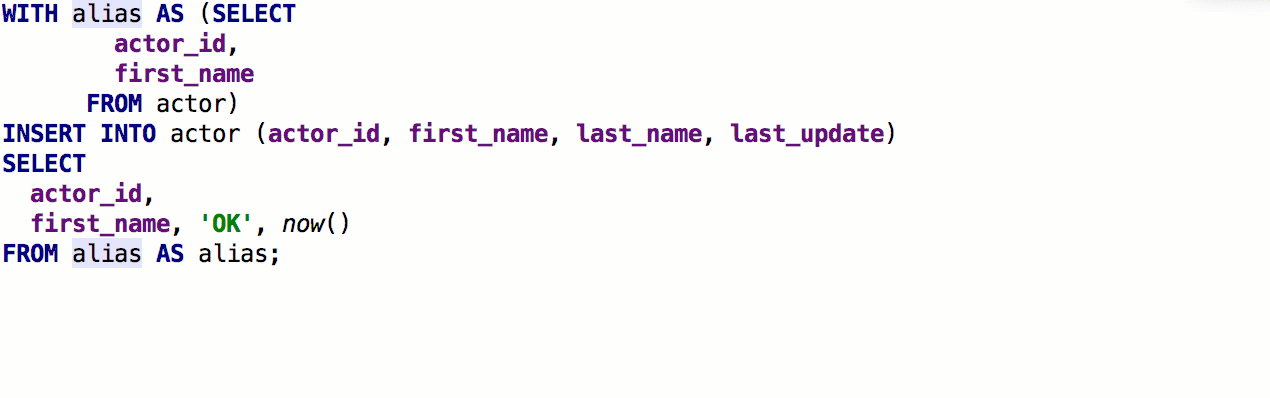
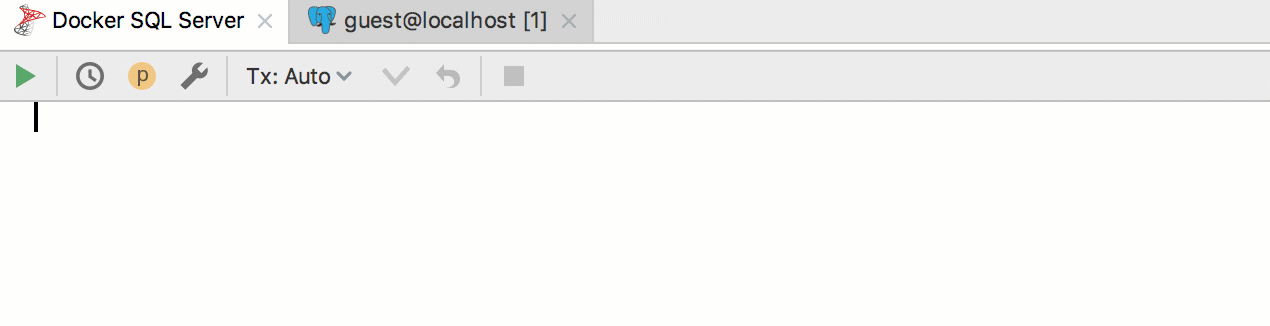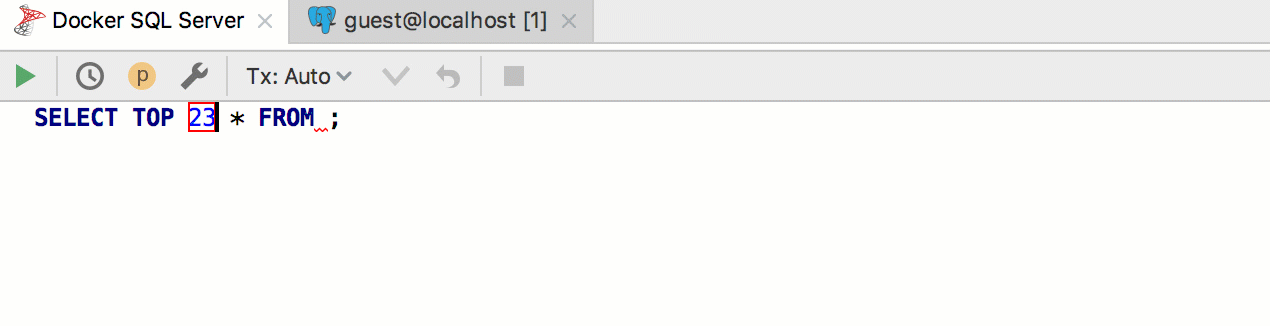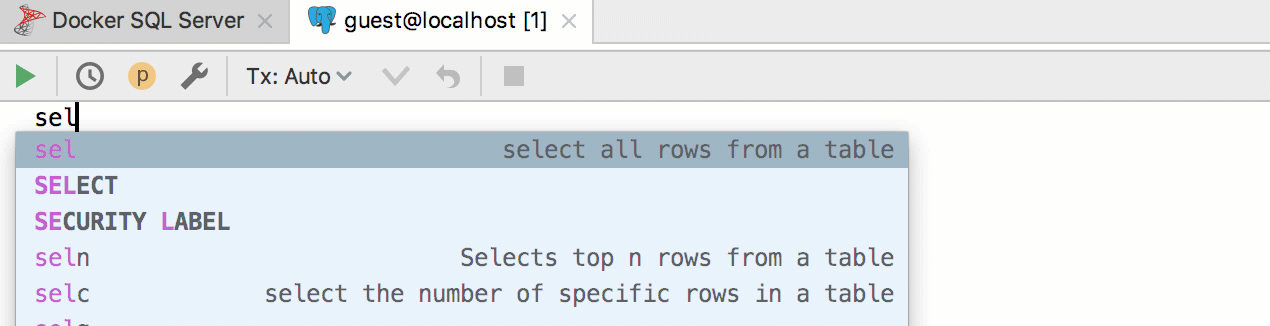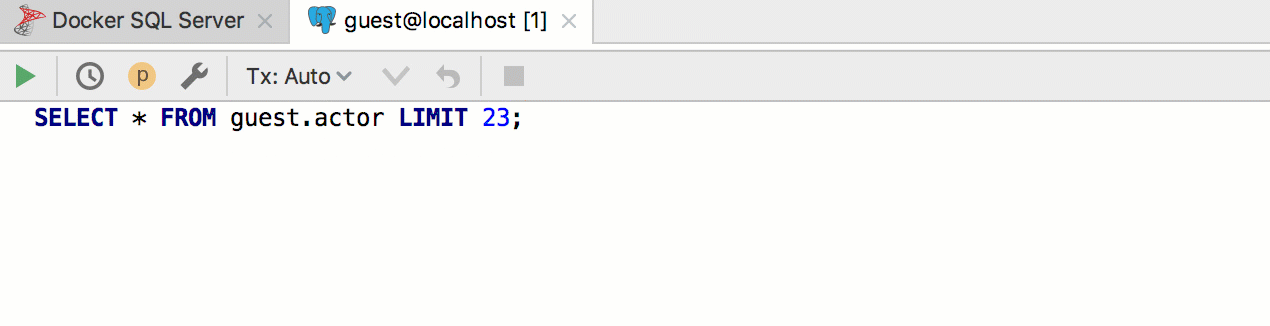
Como resultado, funciona assim:
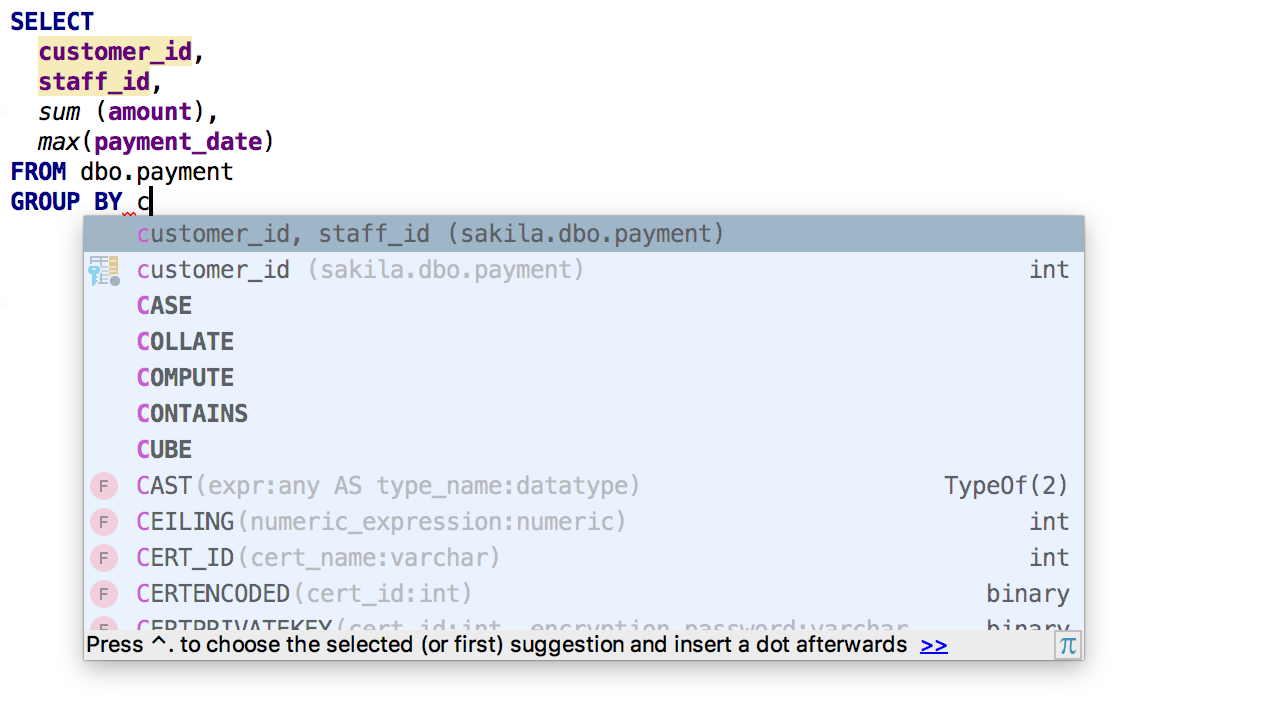
Ao usar
GROUP BY DataGrip, será oferecida uma lista de
colunas não agregadas .
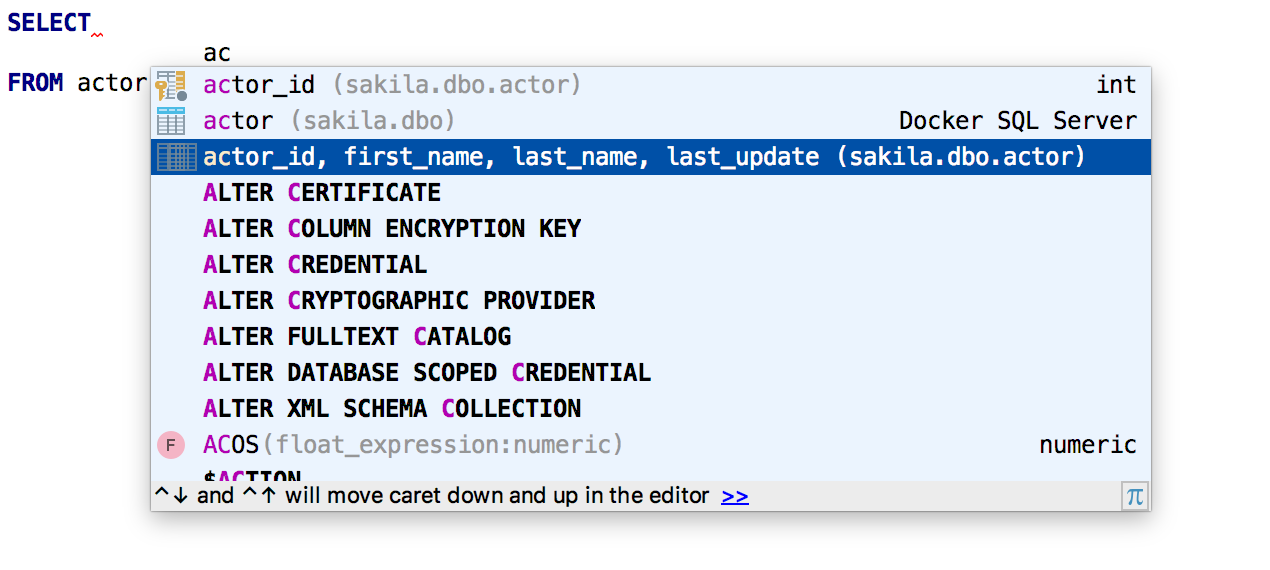
A cláusula SELECT oferece uma
lista de todas as colunas .
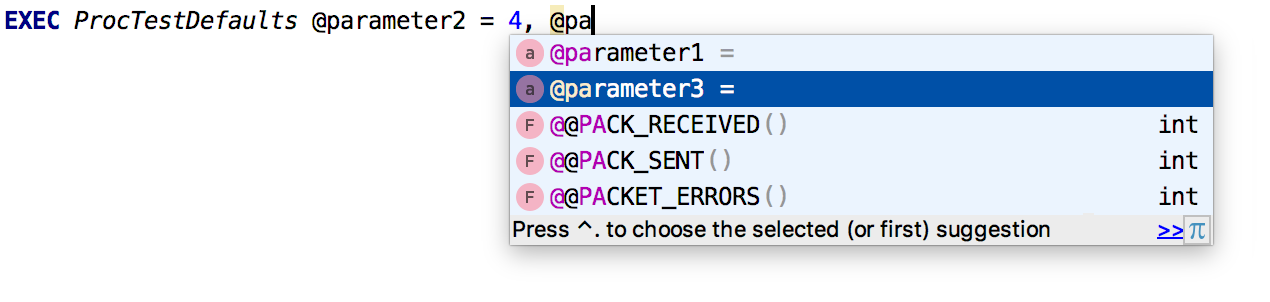
O preenchimento automático funciona para
parâmetros nomeados .
Também adicionamos informações de
contexto para nomes idênticos.
Finalmente feito
a conclusão do postfix : é nesse momento que eles escrevem algo relacionado ao objeto.

Por exemplo, se após
SELECT você escrever o nome da Table.afrom, a
cláusula FROM será expandida na lista de colunas. Ou, em nossa opinião, o mais conveniente, você pode adicionar .cast a uma coluna ou variável.
Melhor ver uma vez:

O preenchimento automático tornou-se melhor para as
funções da janela : OVER () é adicionado automaticamente e o carro é colocado no lugar certo.

Refatoração
Uma coisa importante que já era hora de fazer
: use um alias em vez de uma tabela. Clique na tabela Alt + Enter → Introduzir Alias. As tabelas de uso serão substituídas por aliases.

Após o lançamento anterior, recebemos um feedback detalhado da
speshuric . Por exemplo, ele encontrou muitos scripts não óbvios para a
subconsulta Extract como um CTE. Essa refatoração é chamada através do menu
Refatorar → Extrair → Subconsulta como CTE , mas recomendamos que você se acostume com
Localizar ação (Ctrl + Shift + A).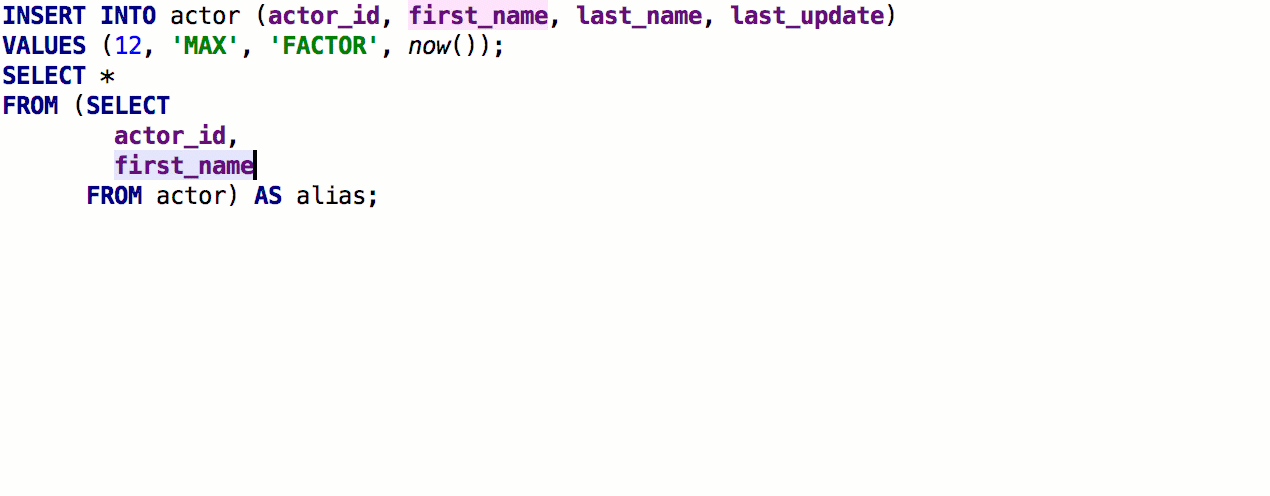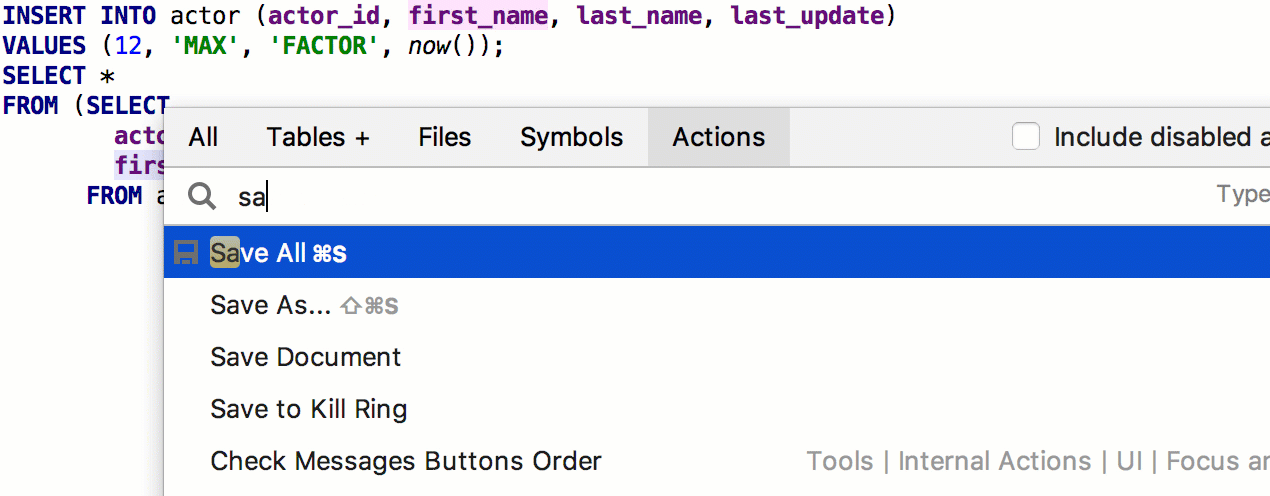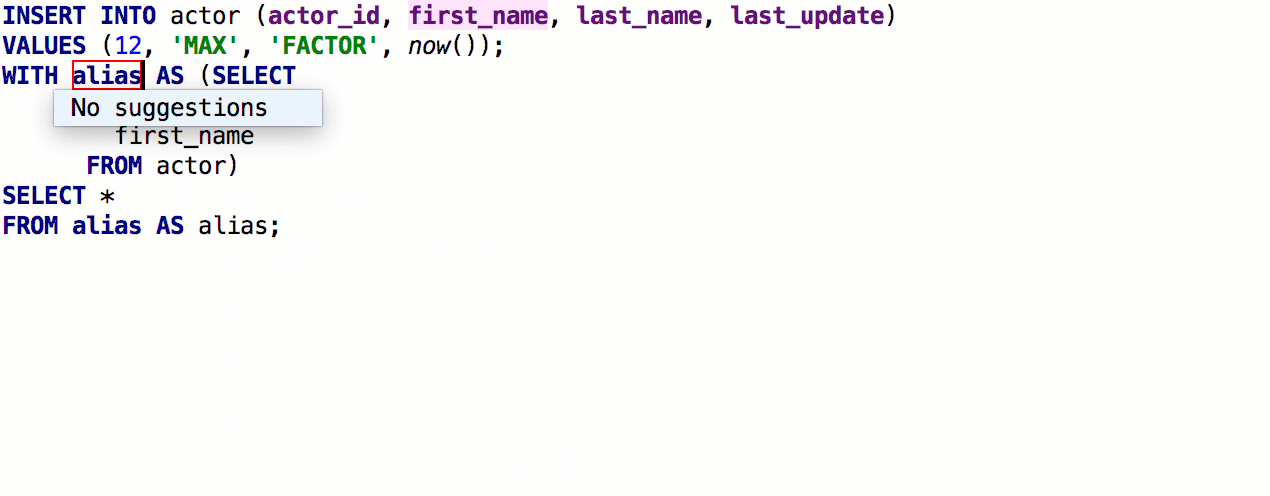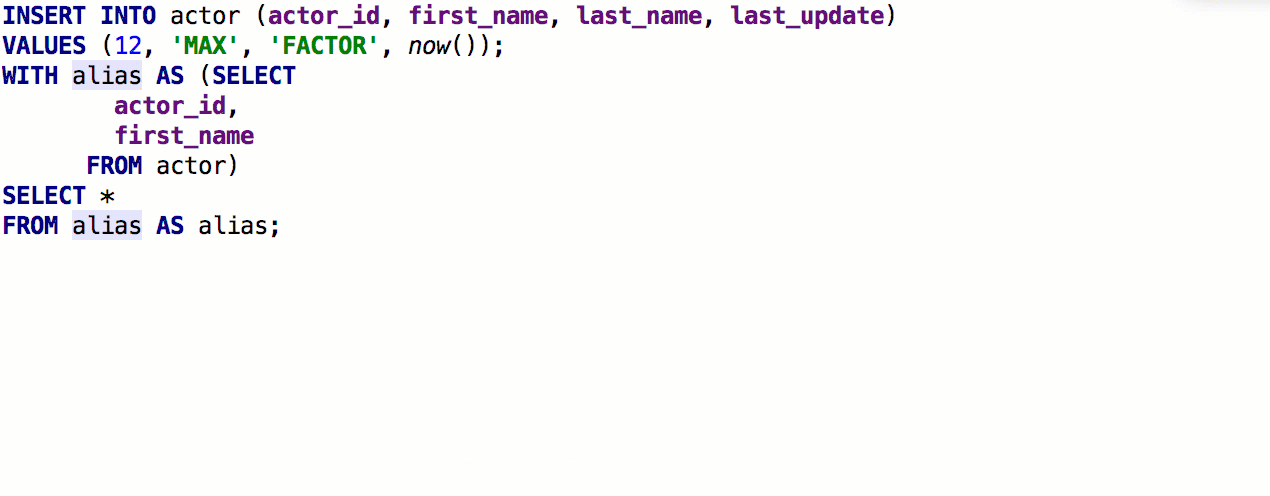
O que fizemos:
- O novo nome para CTE não entra em conflito com o existente:
DBE-6496- Determinamos corretamente o contexto se a solicitação estiver agrupada em outra expressão:
DBE-6503 ,
DBE-6517- Não oferecemos refatoração no caso de
AS TableName :
DBE-6490- Suportado para MySQL 8.
- Funciona como deveria com subconsultas profundas.
DBE-7332 ,
DBE-7333Geração de código
Modelos de código podem ser
anexados a dialetos - um modelo pode funcionar para algumas bases e não para outras.
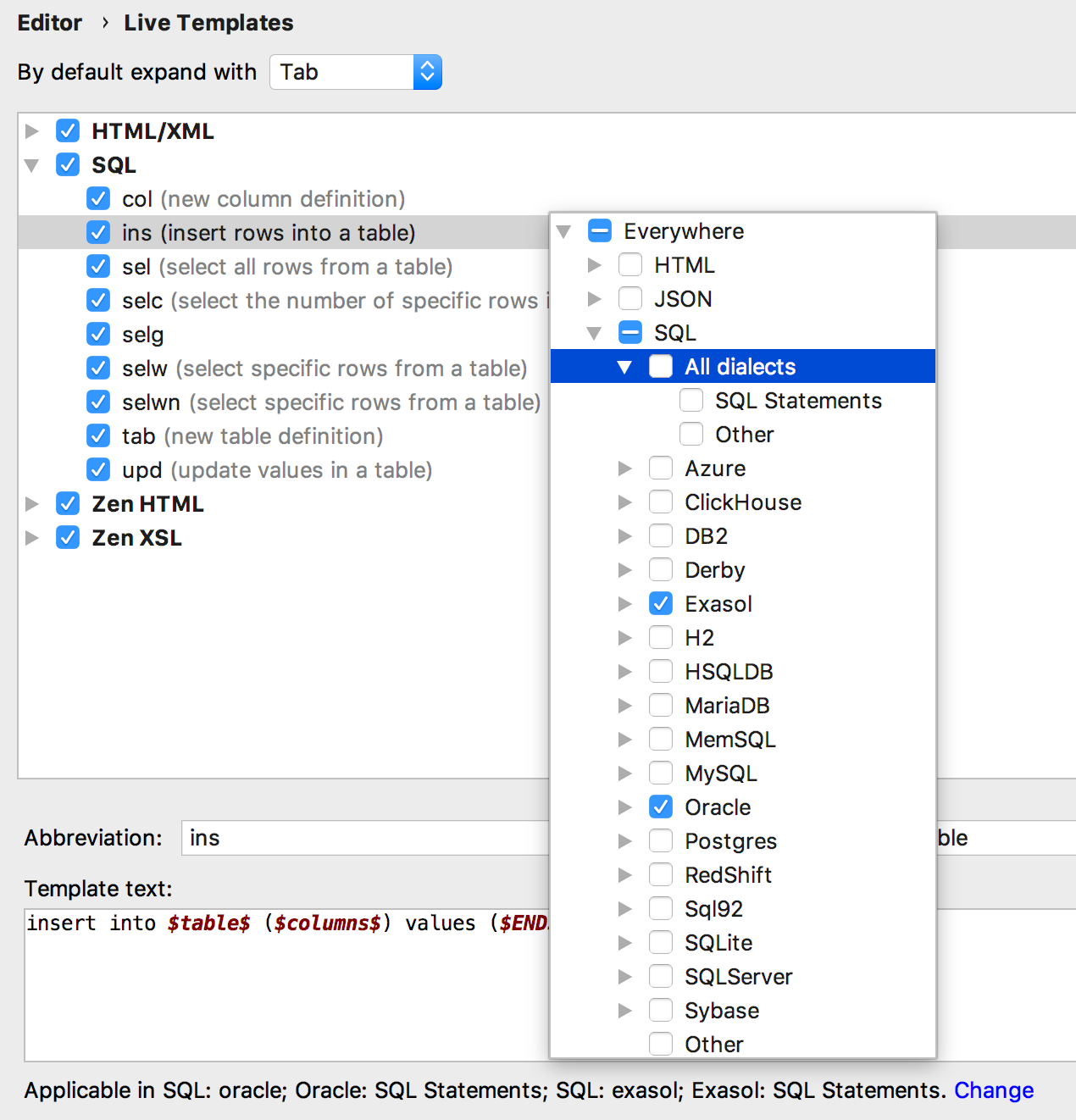
Mais importante: o mesmo modelo pode gerar código diferente para bancos de dados diferentes. Para fazer isso, crie grupos de modelos para cada dialeto, porque os mesmos nomes de modelo não são suportados no mesmo grupo (por padrão, armazenamos modelos no grupo SQL).
Por exemplo, queremos criar um modelo para extrair as primeiras n linhas de uma tabela. O PostgreSQL e o SQL Server usam sintaxe diferente para isso, e sempre usaremos o modelo
seln . Consequentemente, implemente dois padrões em dois grupos diferentes e atribua a eles os dialetos correspondentes.

Acontece assim:
A partir da cláusula SELECT, agora você pode
gerar uma tabela com a mesma assinatura. Para fazer isso, pressione
Alt + Enter -> Criar definição de tabela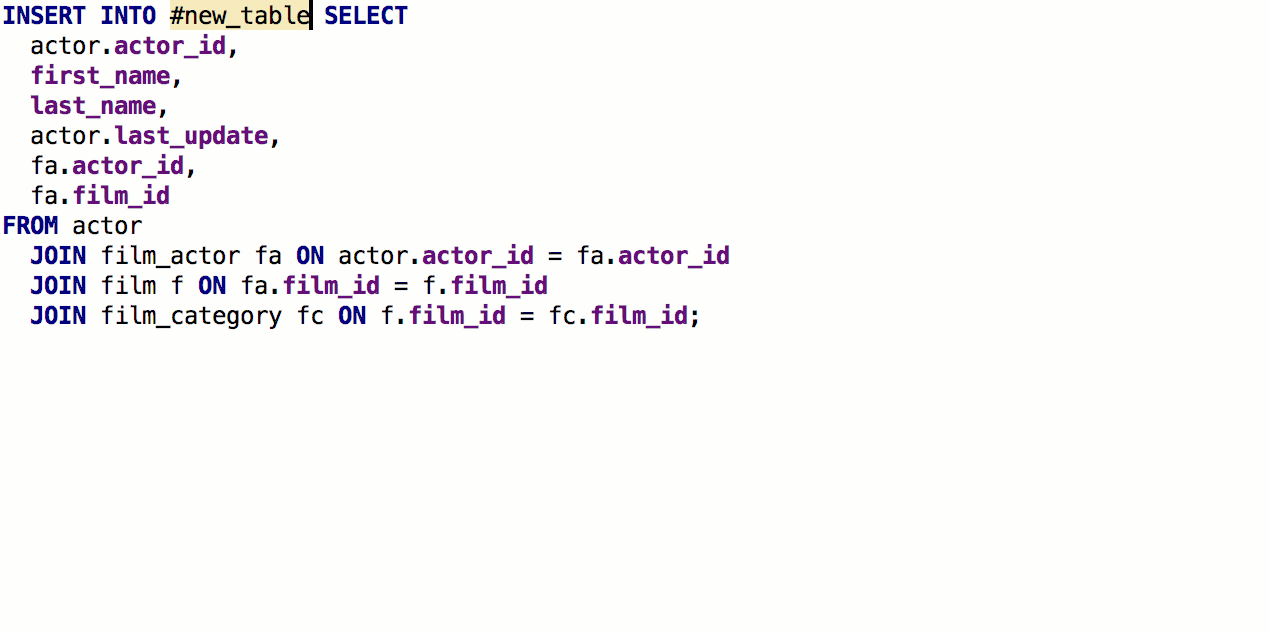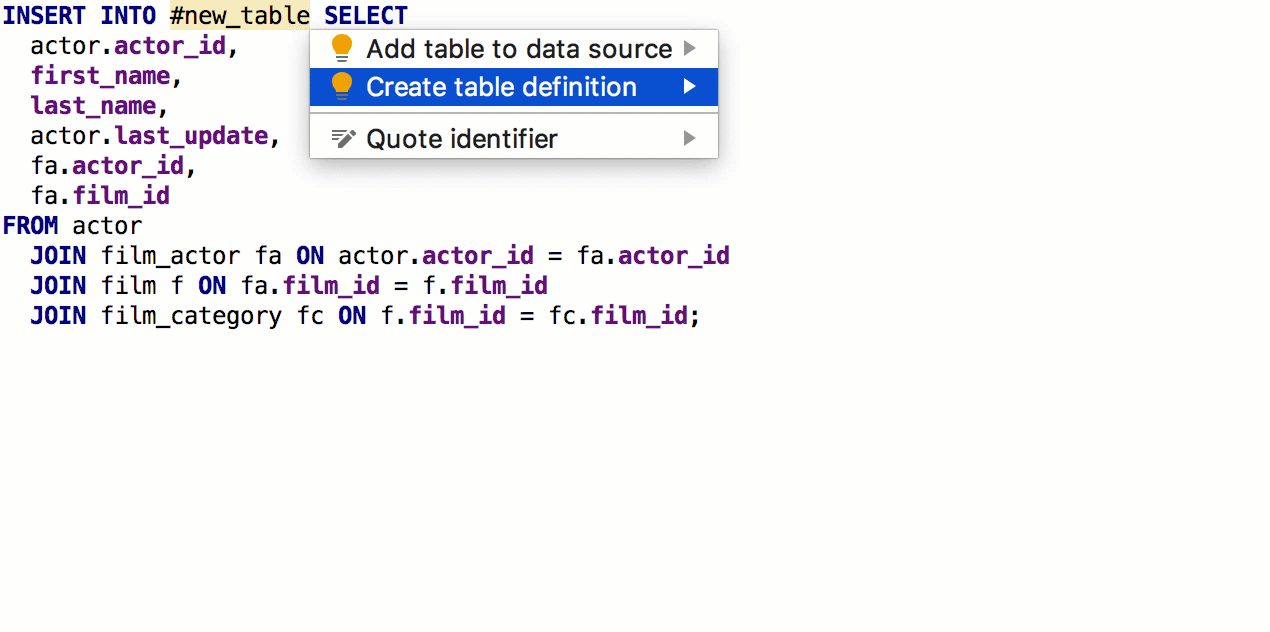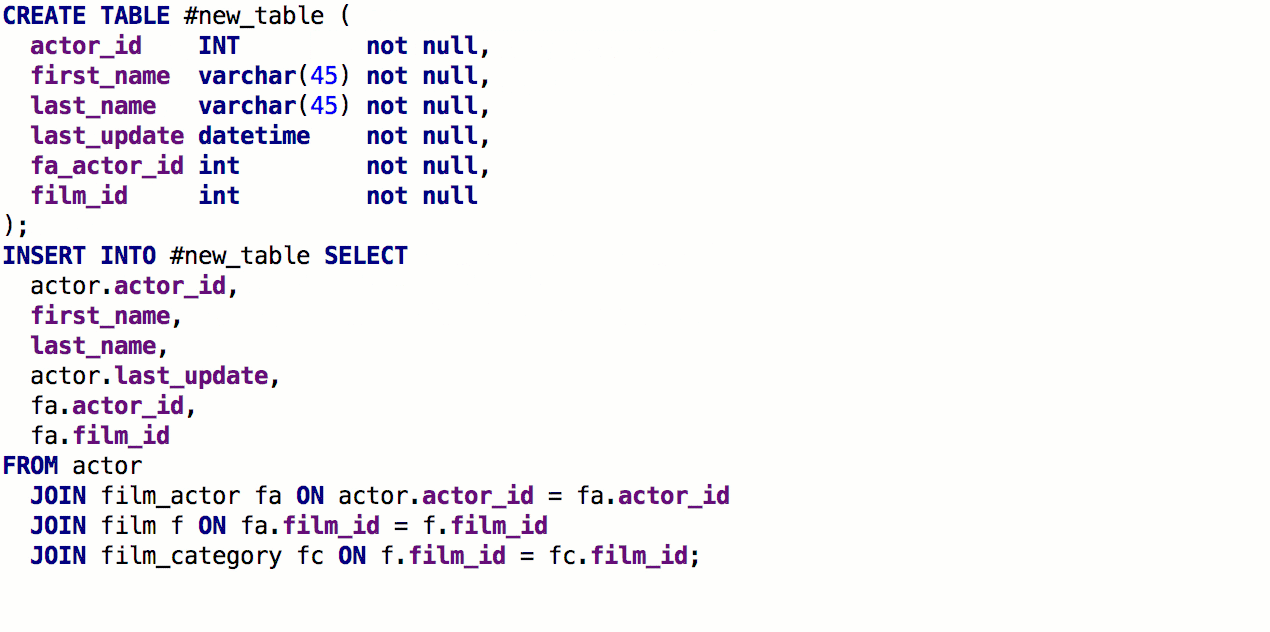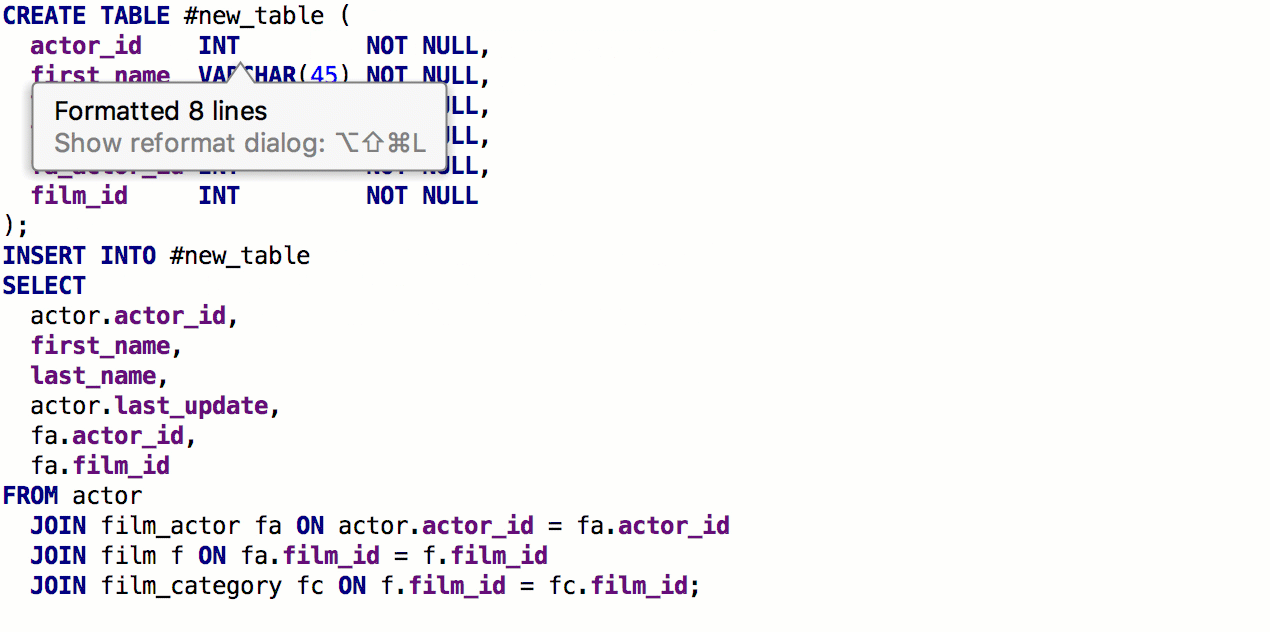
E uma pequena correção para o modelo
INS -
dicas de ferramentas para nomes de colunas são mostradas automaticamente.

Análise de código
Adicionamos inspeções sobre
DELETE e
UPDATE inseguras - avisaremos que você perderá dados.


E se você correr, esclareceremos :)

Outra inspeção encontrará as
colunas não utilizadas
da subconsulta .
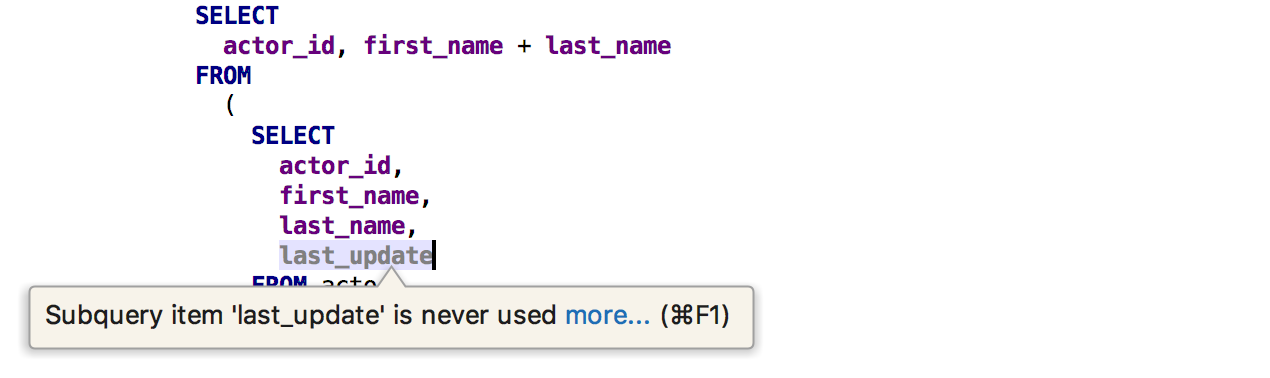
E o outro é um
código não utilizado.
Objetos de banco de dados
O SQL Generator (
Ctrl / Cmd + Alt + G ) aprendeu
a escrever os resultados em um arquivo : para isso, clique no botão
Salvar .
Por padrão, dois métodos de organização de arquivos estão disponíveis, mas se você precisar de mais, escreva nos comentários.
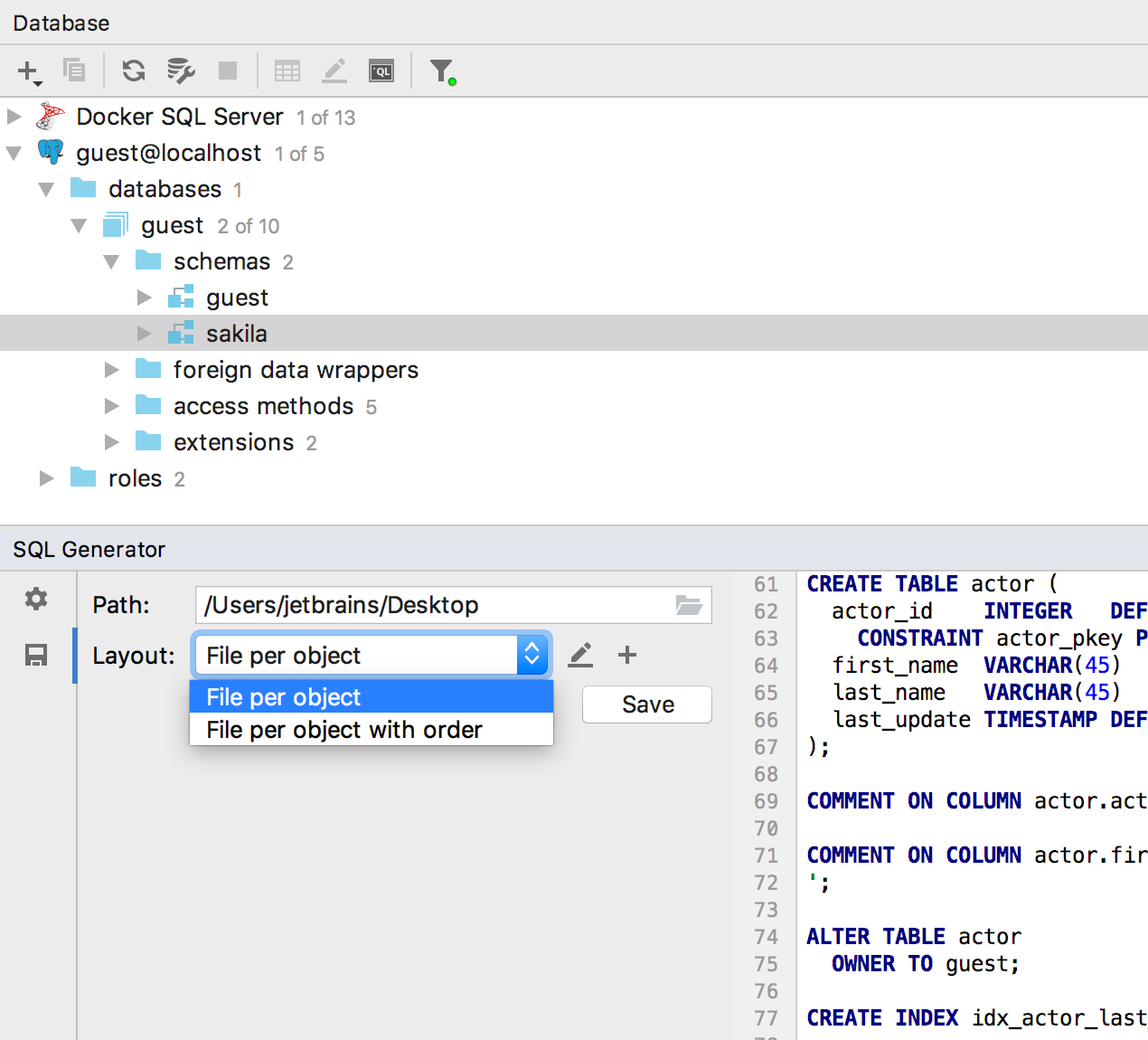
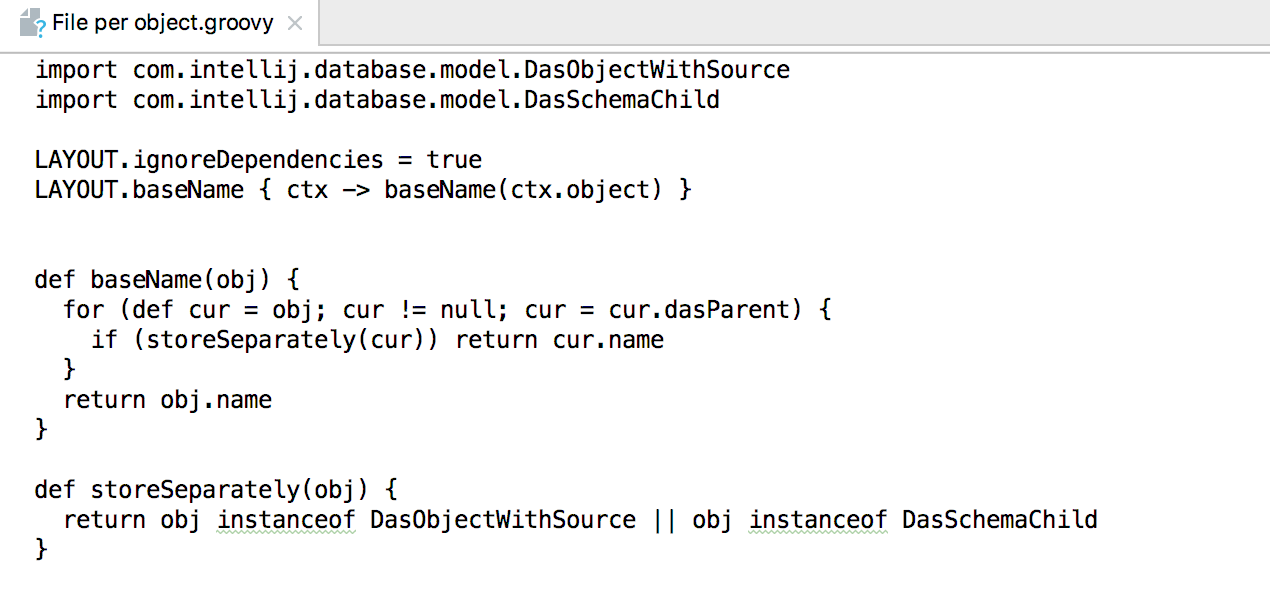
Ou agora, se você clicar no lápis à direita, poderá editar os scripts correspondentes no groovy. Ou crie o seu próprio.
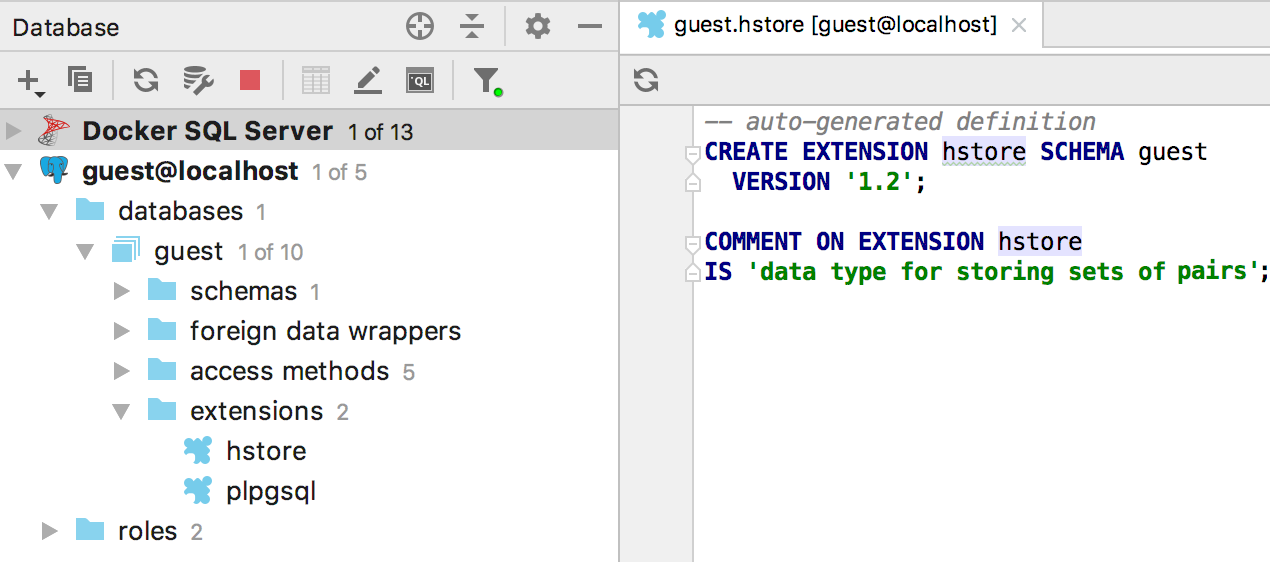
 Extensões
Extensões suportadas no PostgreSQL.
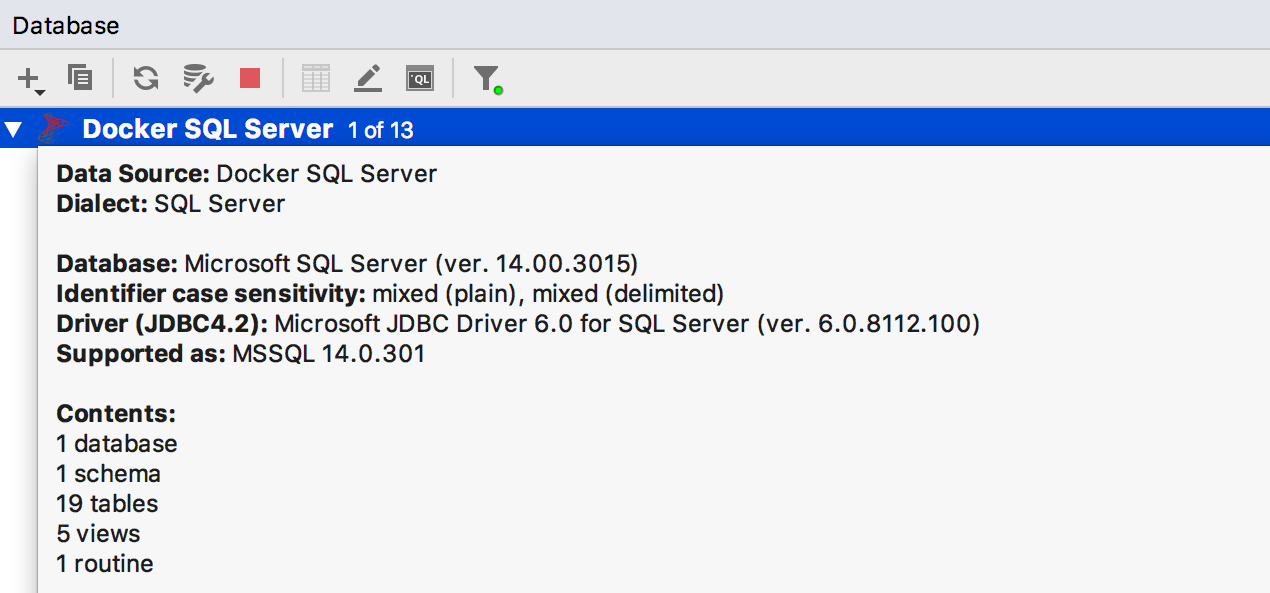
Mostramos
estatísticas na janela de informações da fonte de dados (Ctrl + Q para Windows / Linux, F1 para OSX), incluindo o número de objetos diferentes.
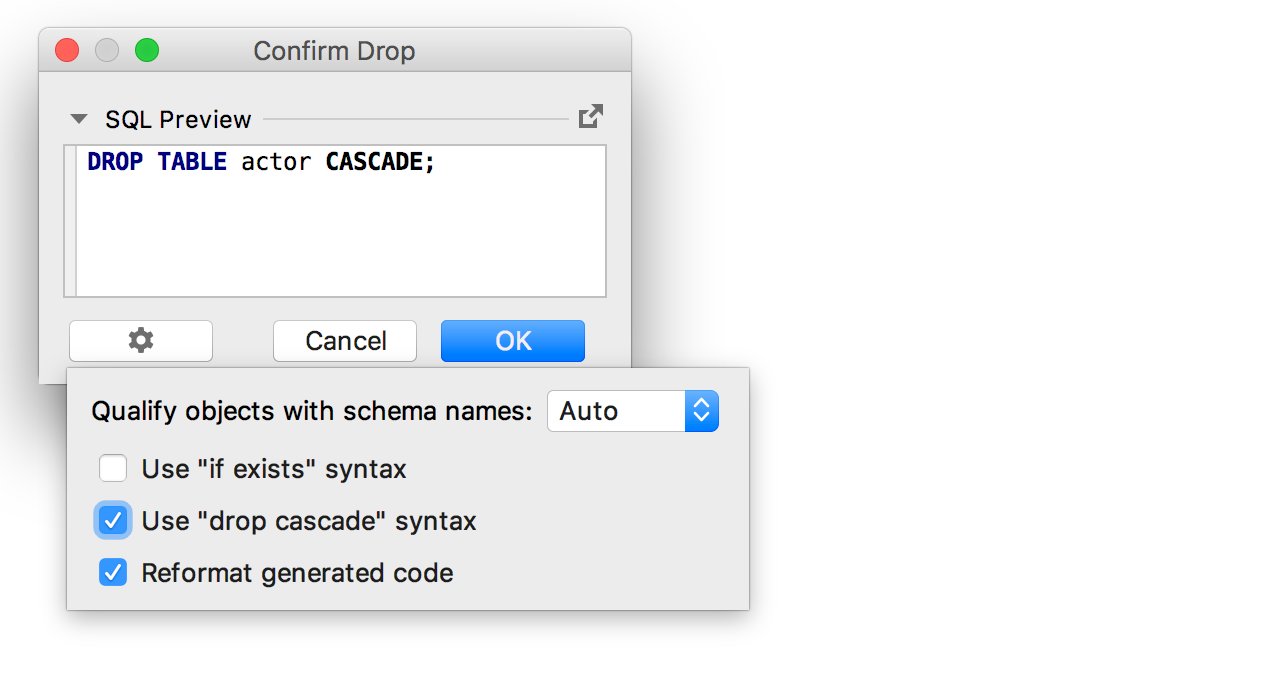
E ao gerar código para excluir o objeto, a opção
' Usar sintaxe da cascata de queda ' foi adicionada.
Ligação
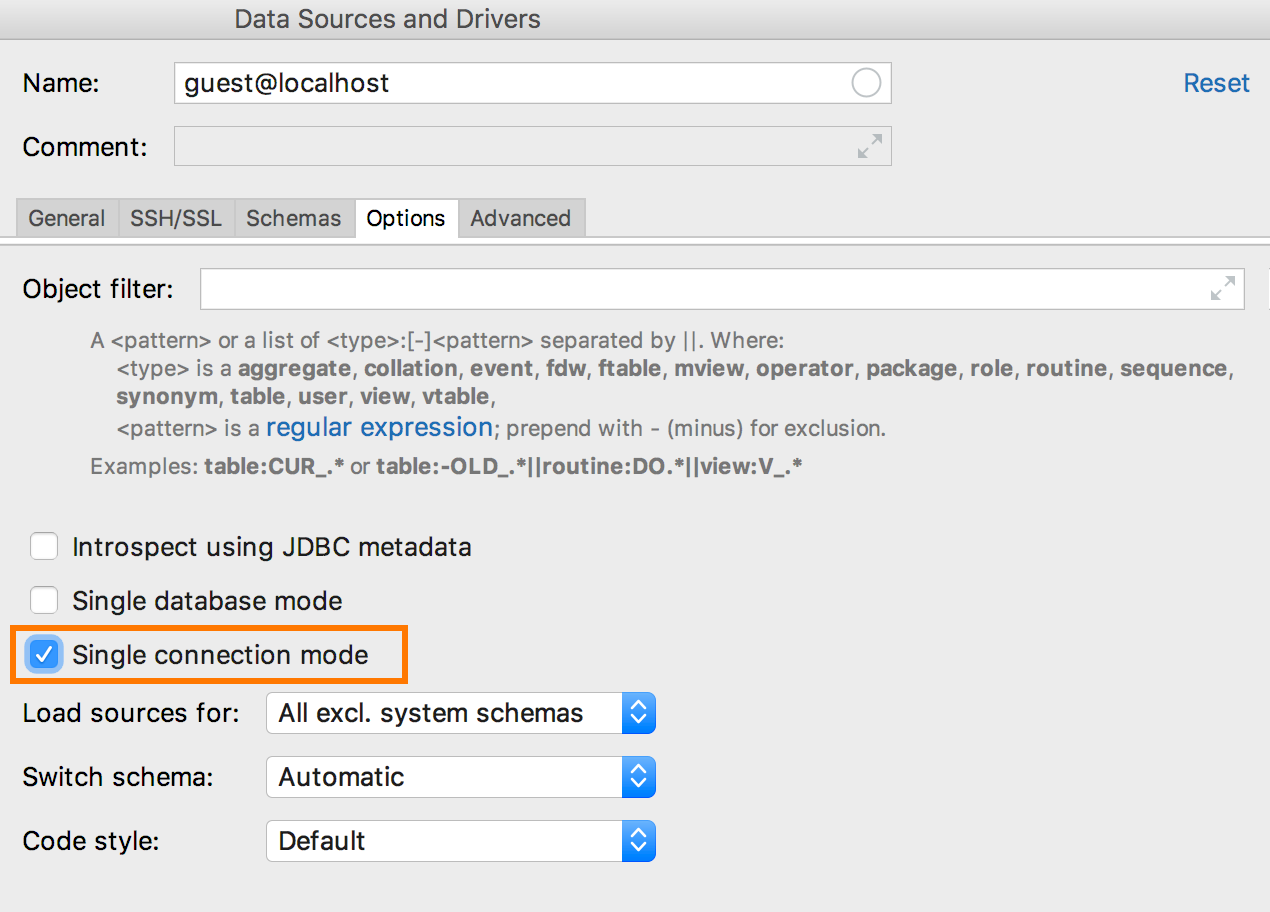
Antes da versão atual, cada novo console significava uma nova conexão. Outras coisas que não exigiam o console também criaram conexões separadas: executando scripts, importando, uma interface gráfica para criar tabelas. Em 2018.3, se você ativar o
modo de conexão Única nas propriedades da fonte de dados, todo o trabalho com ela ocorrerá através de uma conexão.
Como resultado, objetos temporários aparecerão na árvore e os consoles e editores de dados funcionarão na mesma transação. Este é o primeiro passo para gerenciar totalmente as conexões que estamos prestes a resolver.
E eles também fizeram isso para que o próprio IDE se
reconecte após o tempo ocioso.
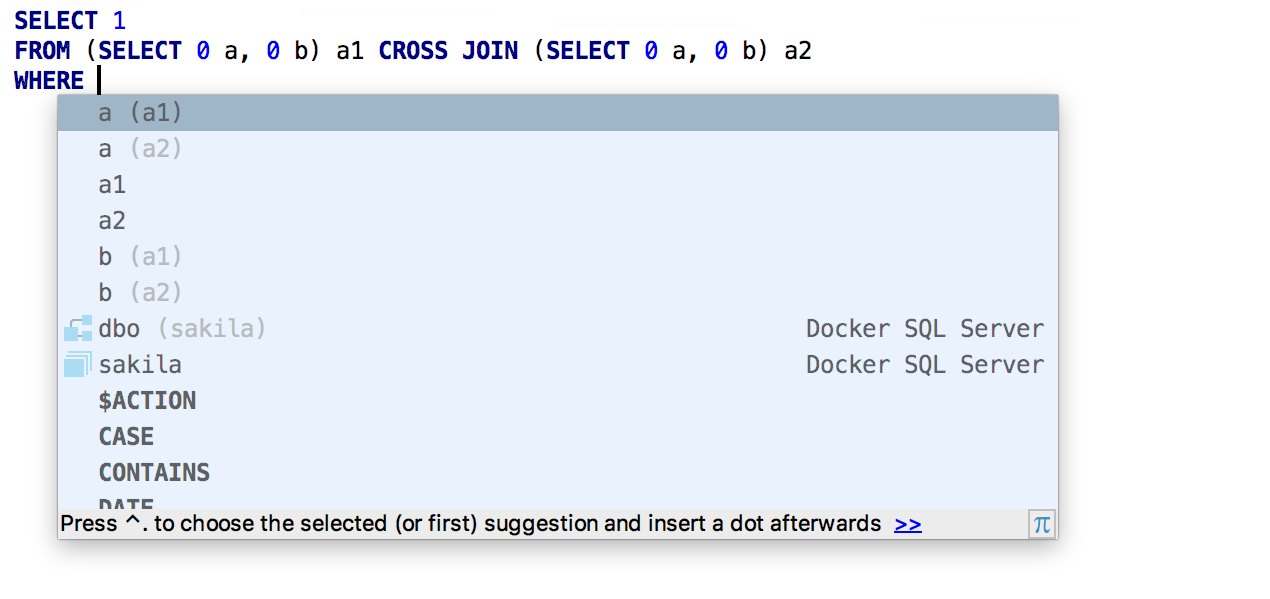
Pesquisa e navegação
A plataforma IntelliJ introduziu uma
nova pesquisa : combina diferentes tipos de pesquisas fragmentadas:
Pesquisar em todos os lugares ,
Encontrar ação ,
Ir para tabela / exibir / procedimento / ,
Ir para arquivo e
Ir para símbolo . No DataGrip, a segunda guia é chamada de Tabelas e, em outros IDEs, é chamada de Classes. Mas ela faz o mesmo: procura objetos e classes do banco de dados. A tecla Tab alterna as guias.
Não alteramos seriamente os algoritmos de pesquisa: se de repente você procurava algo bem, mas agora ele é mal pesquisado, escreva.
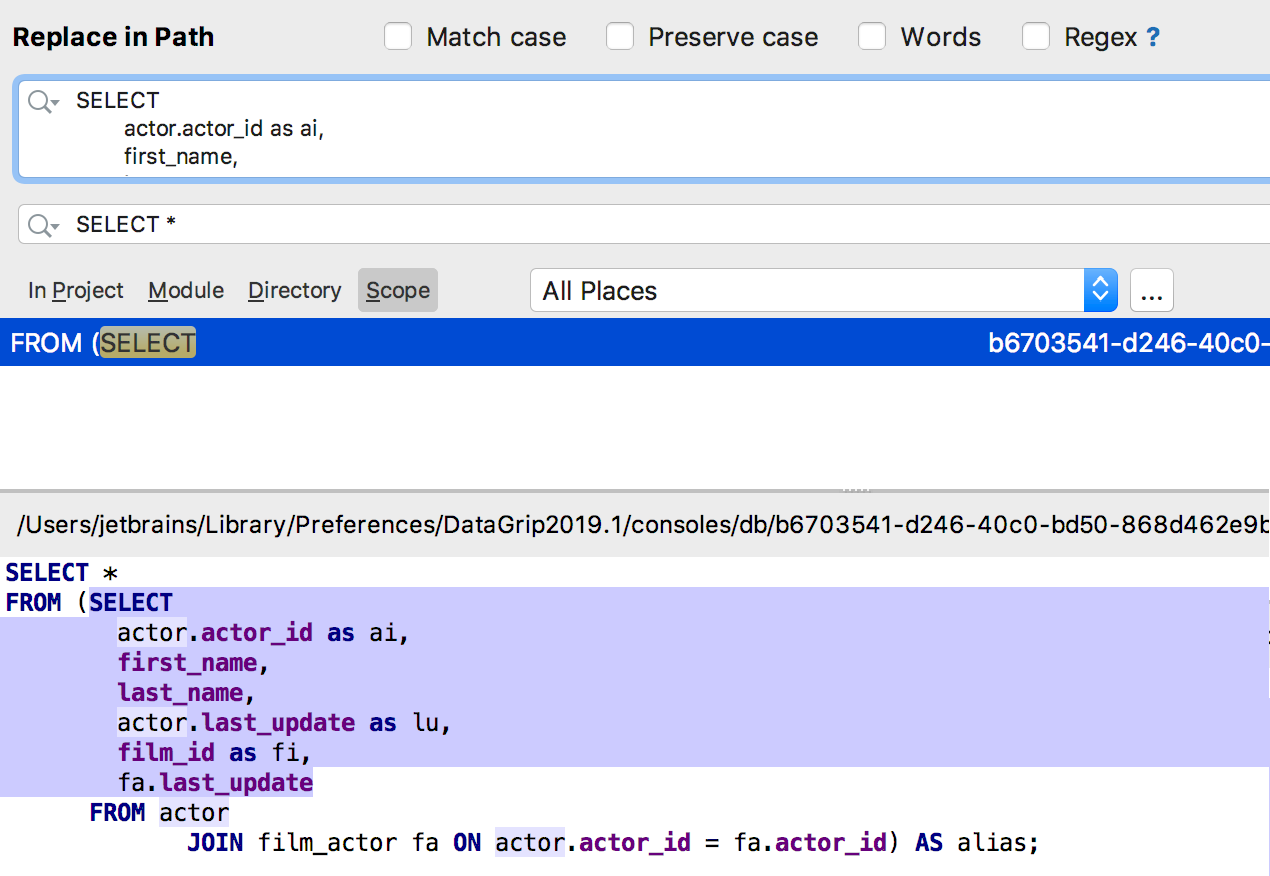
 Várias linhas ao mesmo tempo
Várias linhas ao mesmo tempo agora podem ser encontradas em "Localizar no caminho". Especialmente útil para SQL - a consulta pode ser encontrada dentro do código fonte dos objetos.
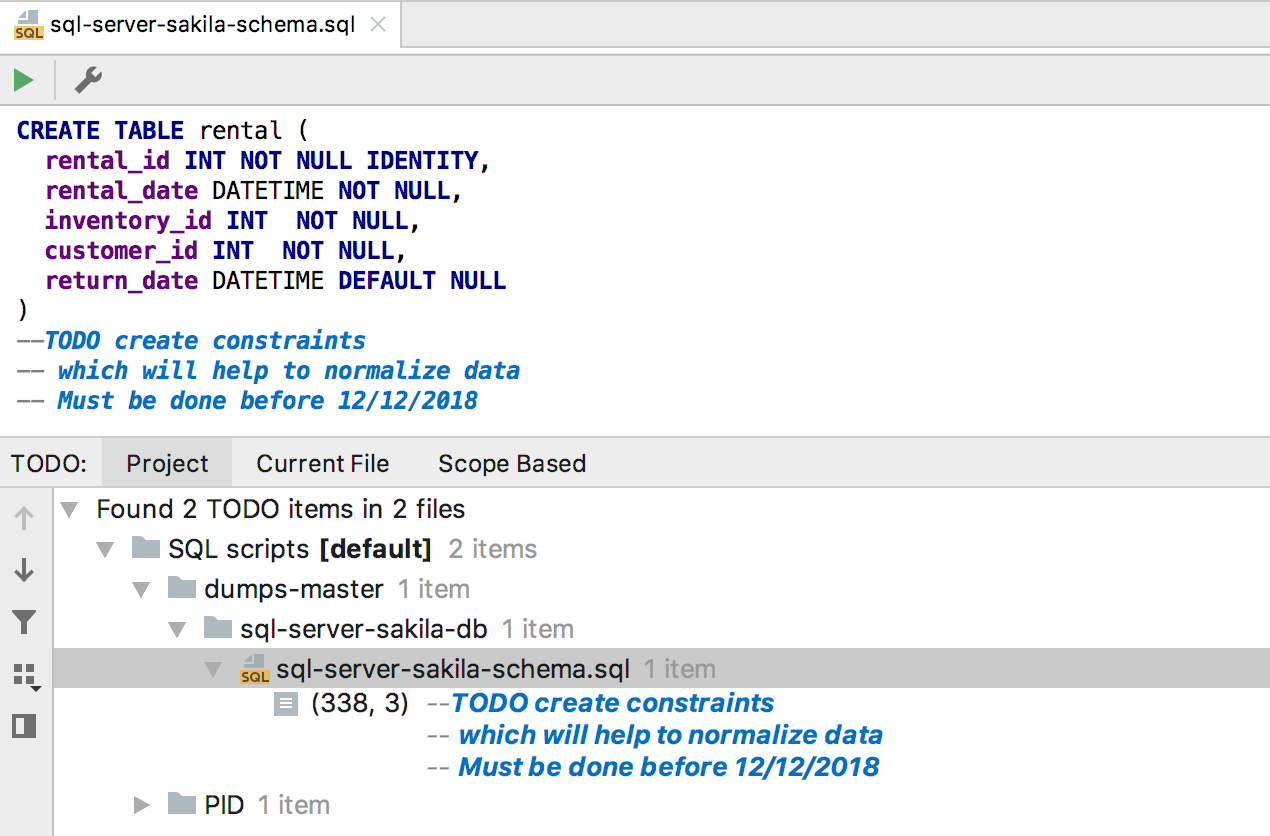
 Os comentários do TODO
Os comentários do TODO agora podem ser multilinhas. Para capturar as seguintes linhas em um comentário, separe-as com um espaço do símbolo de comentário. As tarefas apresentadas dessa maneira se enquadram na
janela da ferramenta TODO .
A imagem é mais clara:
Interface
O novo esquema de cores é muito contrastante.
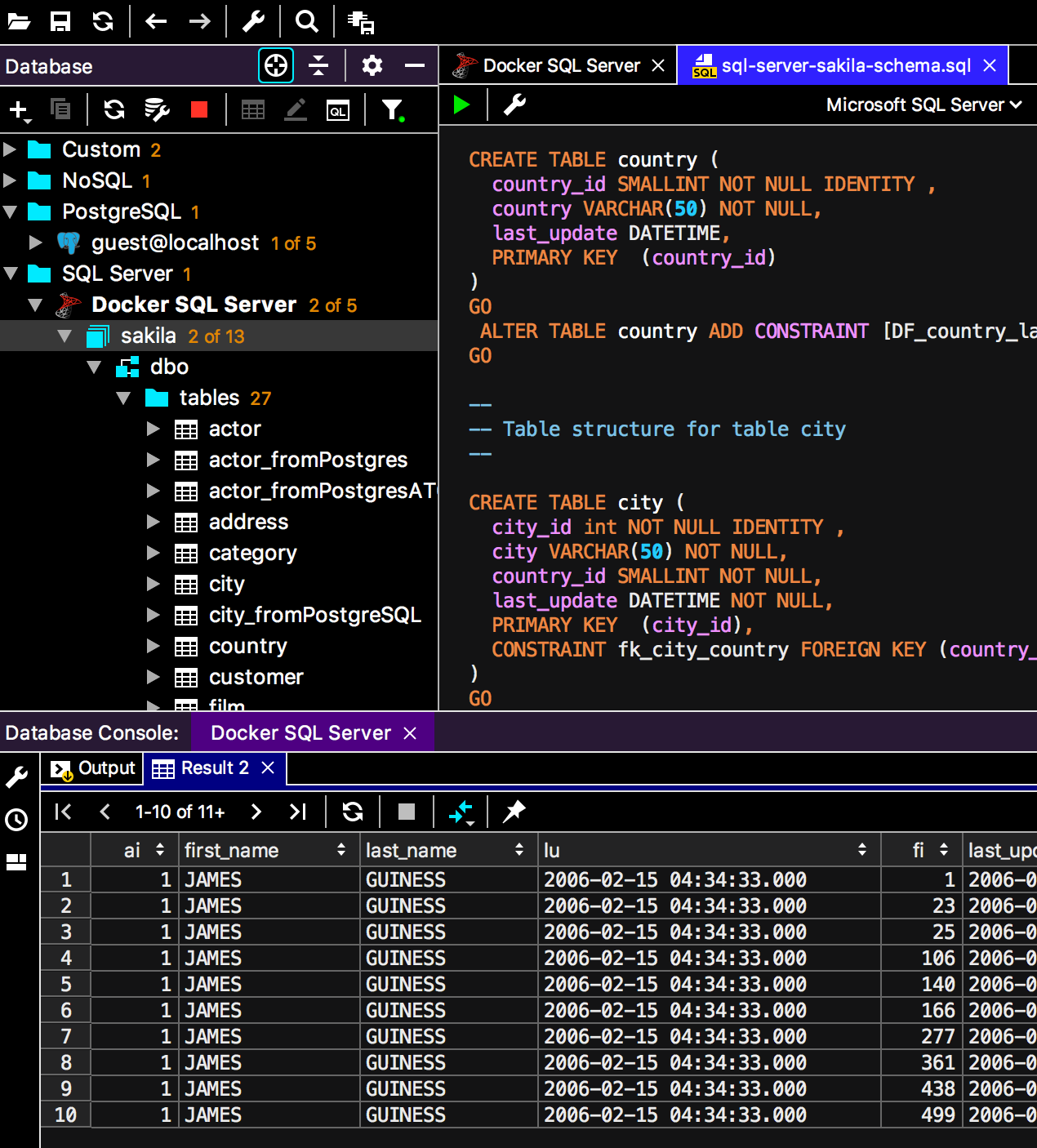
Alterne esquemas como este: Pressione
Ctrl + `e selecione Aparência.
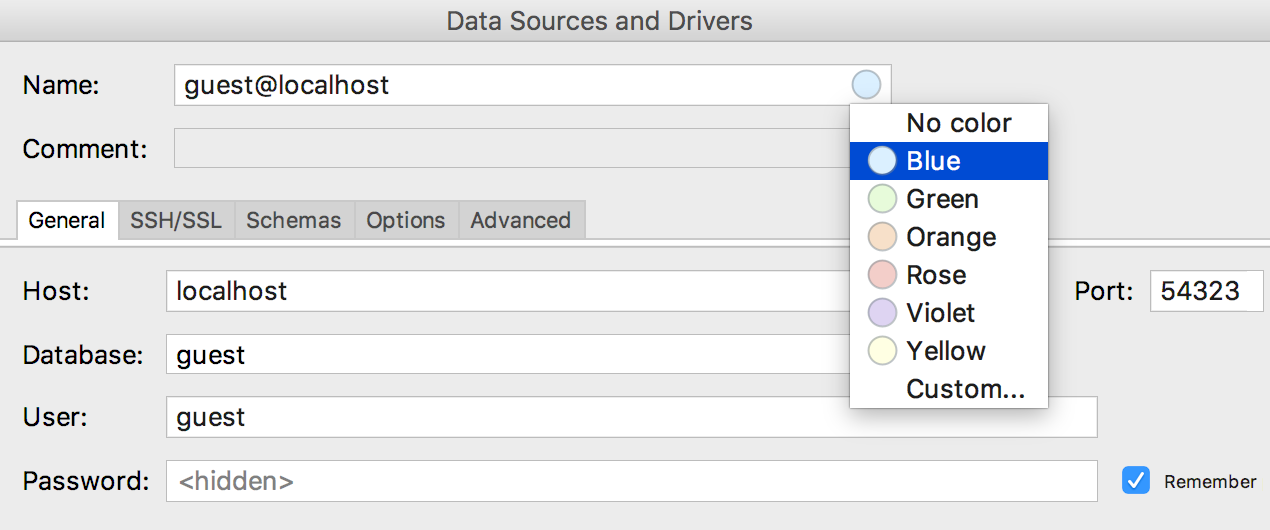
Um menu foi exibido para
selecionar a cor da fonte de dados em sua janela de propriedades.
E um pouco de simpatia foi adicionada à caixa de seleção de linha na página. Anteriormente, para o resultado mostrar todas as linhas, você precisava escrever -1 aqui :)
Agora há uma caixa de seleção.

Isso é tudo!
→
Mais detalhes aqui→
Faça o download da avaliação por um mês→ O
tweeter que lemos→ O e-
mail que lemos→
Bug TrackerEquipe do DataGrip