Edição
Quase qualquer sistema de informação requer armazenamento de dados continuamente. Na maioria dos sistemas com carga pequena e média, essa função é executada por DBMSs relacionais, cuja vantagem indiscutível é a garantia da consistência dos dados.
Um exemplo clássico que explica o que é a consistência dos dados - a operação de transferência de fundos de uma conta para outra. No momento em que a operação de alteração do saldo de uma conta já foi concluída e a outra ainda não teve tempo, pode ocorrer uma falha. Os fundos serão debitados de uma conta, mas não serão creditados em outra. Esse estado dos dados do sistema é chamado de inconsistente e, talvez, não seja necessário explicar a quais consequências isso pode levar. Os DBMSs relacionais fornecem um mecanismo de transação que garante a consistência dos dados a qualquer momento. Uma transação é um conjunto finito de operações que transfere um estado consistente para outro estado consistente.
No caso de um erro em qualquer etapa, o DBMS cancela todas as operações executadas anteriormente e retorna os dados ao seu estado original acordado. Em outras palavras, todas as operações serão executadas ou nenhuma.
Quanto aos sistemas de grande escala, nem sempre é possível usar um único banco de dados, devido a uma carga muito pesada. Nesses casos, cada módulo do sistema (serviço) é fornecido com seu próprio banco de dados separado. Nesse caso, surge a questão de como garantir a consistência dos dados para essa arquitetura de cluster.
Solução de consistência de dados
Uma solução são transações distribuídas. Primeiro, todos os nós do cluster devem concordar que a operação é possível; as alterações são confirmadas em todos os nós. Como os nós não têm dispositivo de armazenamento comum, a única maneira de obter uma opinião comum é concordar em usar algum protocolo de consenso distribuído.
Um protocolo simples para capturar transações globais é o commit de duas fases (2PC). O nó que executa a transação é considerado o coordenador. Na fase de preparação (preparação), o coordenador informa os outros nós sobre a confirmação da transação e aguarda a confirmação deles de que eles estão prontos para confirmar. Se pelo menos um nó não estiver pronto, a transação será interrompida. Na fase de confirmação, o coordenador informa todos os nós da decisão de confirmar a transação. Após o recebimento da confirmação de todos de que tudo está correto, o coordenador também captura a transação.

Figura 1 - Esquema geral de um commit de duas fases
Este protocolo evita um mínimo de mensagens, mas não é robusto. Por exemplo, se o coordenador falhar após a fase de preparação, os nós restantes não terão informações sobre se a transação deve ser confirmada ou cancelada (eles terão que aguardar a correção da falha). Outra desvantagem séria do 2PC (e de outros protocolos de transação distribuída, por exemplo 3PC) é que, à medida que o número de nós do cluster aumenta, o desempenho das confirmações de duas fases diminui.

Figura 2 - Dependência da velocidade de uma confirmação de duas bases no número de servidores em um cluster DBMS
Além disso, a abordagem de transação distribuída impõe uma limitação: todos os módulos do sistema devem usar o mesmo DBMS, o que nem sempre é conveniente.
Outra opção é fornecer um mecanismo que permita trabalhar com diferentes bancos de dados (para serviços) como um único banco de dados (para resolver o problema com a integridade dos dados em um banco de dados distribuído). Ao mesmo tempo, é necessário um certo análogo de uma transação para um sistema distribuído ("transação comercial").
Em transações comuns, bem como em confirmações de duas fases, todas as operações são controladas pelo mecanismo de transação (usando bloqueios), e isso é feito para fornecer a capacidade de reverter qualquer operação (abordagem pessimista - consideramos que qualquer operação pode estar causando uma falha). Esse é o gargalo do sistema. Uma alternativa é a chamada abordagem otimista: acreditamos que a maioria das operações é concluída com sucesso. Também realizamos ações adicionais devido ao fato de uma falha. I.e. reduzindo custos para a maioria das operações, o que leva ao aumento da produtividade.
O que é uma Saga e como funciona
Uma alternativa para transações para arquitetura de microsserviço é o Saga. Saga (saga) é um conjunto de etapas executadas por vários módulos do sistema (serviços); o serviço saga também é necessário, responsável pela operação (transação comercial) como um todo. As etapas são vinculadas por meio de um gráfico de eventos. Após a conclusão da saga, o sistema deve passar de um estado acordado para outro (em caso de execução bem-sucedida) ou retornar ao estado acordado anterior (em caso de cancelamento).
Como implementar tal retorno ou reversão de uma transação comercial? Para isso, a saga utiliza o mecanismo de cancelamento de etapas (ações compensatórias). Por exemplo, uma das etapas foi bem-sucedida (por exemplo, uma entrada foi adicionada à tabela do banco de dados do usuário), mas uma das etapas a seguir falhou e a saga inteira deve ser cancelada. Em seguida, o mesmo serviço recebe um comando - cancele a ação. Mas no DBMS de serviço, a transação local já foi concluída, o registro do usuário foi adicionado. Em seguida, para retornar ao estado anterior, o serviço deve executar uma ação de compensação (em nosso exemplo, exclua o registro). O cancelamento de etapas permite que a atomicidade (“tudo ou nada”) seja implementada no âmbito da saga - todas as etapas são executadas ou compensadas.
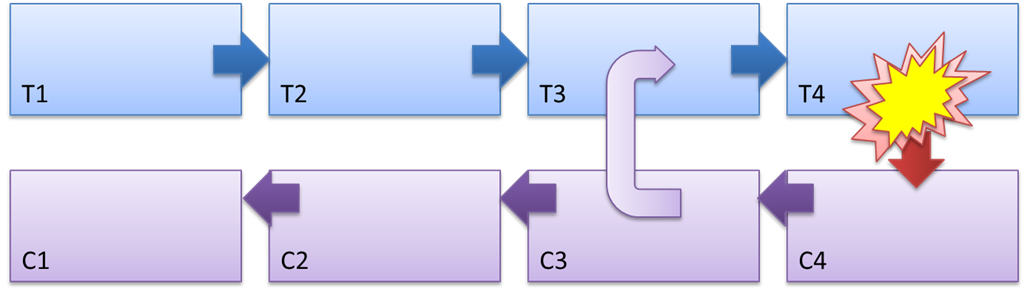
Figura 3 - O mecanismo de trabalho de Saga e a natureza do efeito compensatório
Na Figura 3, as etapas da saga são designadas como T1 ... T4, ações compensatórias: C1 ... C4.
As sagas suportam a idempotência de etapas (uma ação cuja repetição repetida é equivalente a uma única). A abordagem sag fornece a oportunidade de repetir qualquer etapa (por exemplo, se você não recebeu uma resposta após a conclusão bem-sucedida). A idempotência também permite restaurar o estado quando os dados são perdidos em qualquer nó (falha e recuperação). Ao executar uma etapa, cada serviço deve determinar (pela chave de idempotência) se já executou essa etapa ou não (se não, executar, caso contrário, pule). Para ações de compensação, também é possível adicionar chaves de idempotência e repetições de operações (garantindo persistência / estabilidade).
Sumário
Dos quatro requisitos para o sistema de transações ACID (atomicidade, consistência, isolamento, estabilidade), o mecanismo sag permite que três sejam implementados - todos, exceto o isolamento. A falta de isolamento pode levar a anomalias (“leituras sujas”, “leituras não repetíveis”, reescrita de alterações entre diferentes transações comerciais, etc.). Para superar essas situações, é necessário o uso de mecanismos adicionais, por exemplo, controle de versão de objetos mutáveis.
Sagas permitem resolver as seguintes tarefas:
- Fornecer alterações de dados dependentes para dados críticos de negócios;
- Ser capaz de definir uma ordem estrita de etapas;
- Cumprir 100% de consistência (coordenar dados mesmo em caso de acidente);
- Forneça verificações de desempenho em todos os níveis.
Exemplos de escopo e aplicação
Sagas são freqüentemente usados em sistemas com um grande número de solicitações. Por exemplo, serviços de email populares, redes sociais. No entanto, a abordagem pode ser aplicada em projetos de menor escala.
Nossa empresa tem experiência no desenvolvimento de um sistema de contabilidade para uma grande empresa que foi projetada para várias dezenas de usuários e todos os dados foram armazenados em um DBMS relacional. O problema surgiu ao implementar o cálculo automático do trabalho planejado: em alguns casos, os cálculos eram muito grandes e exigiam a inserção de milhões de registros nas tabelas do DBMS, que carregavam significativamente o DBMS e retardavam a operação de todo o sistema.
Foi encontrada uma solução - colocar a lógica de cálculo do trabalho em um serviço separado com seu próprio DBMS para armazenar o trabalho em si e objetos relacionados. A consistência dos dados foi assegurada pela saga. Se o cálculo falhar, o módulo principal do aplicativo receberá um comando para cancelar a operação de cálculo lógico.
Bibliotecas ativadas pelo Saga
O aplicativo foi desenvolvido em .Net e, para essa tecnologia, existem várias bibliotecas do gerenciador de serviços com suporte para sagas. Analisamos as bibliotecas NServiceBus, MassTransit e Rebus. Como resultado, decidimos pelo Rebus - essa biblioteca é mais fácil de aprender, ao mesmo tempo em que realiza o princípio das sagas e é livre para usar. NServiceBus e MassTransit são ferramentas mais sofisticadas com toneladas de recursos adicionais. Eles não foram necessários como parte de nossa tarefa, mas pode ser aconselhável usá-los em projetos futuros com lógica mais complexa.