Uma das funções discretas mas importantes de
nossos sites de anúncios é salvar e exibir o número de visualizações. Nossos sites assistem a visualizações de anúncios há mais de 10 anos. A implementação técnica da funcionalidade conseguiu mudar várias vezes durante esse período, e agora é um (micro) serviço Go, trabalhando com Redis como cache e fila de tarefas e com MongoDB como armazenamento persistente. Alguns anos atrás, ele aprendeu a trabalhar não apenas com a soma de visualizações de anúncios, mas também com estatísticas para cada dia. Mas ele aprendeu a fazer tudo isso com muita rapidez e confiabilidade recentemente.

No total, o serviço processa ~ 300 mil solicitações de leitura e ~ 9.000 solicitações de gravação por minuto, 99% das quais são executadas em até 5 ms. Esses, é claro, não são indicadores astronômicos e nem o lançamento de foguetes em Marte - mas também não é uma tarefa trivial que possa parecer o simples armazenamento de números. Aconteceu que fazer tudo isso, garantindo o armazenamento de dados sem perdas e lendo valores consistentes e relevantes, requer algum esforço, que discutiremos a seguir.
Tarefas do projeto e visão geral
Embora os contadores de exibição não sejam tão críticos para os negócios quanto, por exemplo, processar pagamentos ou
solicitações de empréstimo , eles são importantes antes de tudo para nossos usuários. As pessoas ficam fascinadas ao rastrear a popularidade de seus anúncios: algumas até ligam para o suporte quando percebem informações de visualização imprecisas (isso aconteceu com uma das implementações de serviços anteriores). Além disso, armazenamos e exibimos estatísticas detalhadas nas contas pessoais dos usuários (por exemplo, para avaliar a eficácia do uso de serviços pagos). Tudo isso nos faz cuidar de salvar cada evento de visualização e exibir os valores mais relevantes.
Em geral, a funcionalidade e os princípios do projeto são assim:
- A página da web ou a tela do aplicativo faz uma solicitação por trás dos contadores de exibição de anúncios (a solicitação geralmente é assíncrona para priorizar a saída de informações básicas). E se a página do anúncio for exibida, o cliente solicitará que você aumente e retorne a quantidade atualizada de visualizações.
- Ao processar solicitações de leitura, o serviço tenta obter informações do cache Redis e complementa o desconhecido concluindo uma solicitação ao MongoDB.
- Os pedidos de gravação são enviados para 2 estruturas no rabanete: a fila de atualização incremental (processada em segundo plano, de forma assíncrona) e o cache do número total de visualizações.
- Um processo em segundo plano no mesmo serviço lê elementos da fila, os acumula no buffer local e os grava periodicamente no MongoDB.
Contadores de exibição de registros: armadilhas
Embora as etapas descritas acima pareçam bastante simples, o problema aqui é a organização da interação entre o banco de dados e as instâncias de microsserviço, para que os dados não sejam perdidos, duplicados e atrasados.
Usar apenas um repositório (por exemplo, apenas o MongoDB) resolveria alguns desses problemas. De fato, o serviço funcionava antes, até que enfrentamos os problemas de escala, estabilidade e velocidade.
Uma implementação ingênua de mover dados entre armazenamentos pode levar, por exemplo, a essas anomalias:
- Perda de dados durante a gravação competitiva no cache:
- O processo A aumenta a contagem de visualizações no cache do Redis, mas descobre que ainda não há dados para essa entidade (pode ser uma nova declaração ou uma antiga que foi extrudada do cache), portanto, o processo deve primeiro obter esse valor do MongoDB.
- O processo A obtém a contagem de visualizações do MongoDB - por exemplo, o número 5; depois adiciona 1 a ele e grava no Redis 6 .
- O processo B (iniciado, por exemplo, por outro usuário do site que também inseriu o mesmo anúncio) simultaneamente faz o mesmo.
- O processo A grava um valor de 6 no Redis.
- O processo B grava um valor de 6 no Redis.
- Como resultado, uma visão é perdida devido à corrida ao gravar dados.
O cenário não é tão improvável: por exemplo, temos um serviço pago que coloca um anúncio na página principal do site. Para um novo anúncio, esse curso de eventos pode levar à perda de muitas visualizações ao mesmo tempo devido ao seu repentino influxo.
- Um exemplo de outro cenário é a perda de dados ao mover visualizações do Redis para o MongoDb:
- O processo seleciona um valor pendente do Redis e o armazena na memória para posterior gravação no MongoDB.
- Uma solicitação de gravação falha (ou o processo falha antes de ser executado).
- Os dados são perdidos novamente, o que se tornará aparente na próxima vez que o valor em cache for enviado e substituído pelo valor do banco de dados.
Outros erros podem ocorrer, cujas razões também estão na natureza não atômica das operações entre os bancos de dados, por exemplo, um conflito ao excluir e aumentar as visualizações da mesma entidade.
Gravando contagens de exibição: solução
Nossa abordagem para armazenar e processar dados neste projeto é baseada na expectativa de que, a qualquer momento, o MongoDB possa falhar com maior probabilidade do que o Redis. Isso, é claro, não é uma
regra absoluta - pelo menos não para todos os projetos -, mas em nosso ambiente estamos realmente acostumados a observar tempos limite periódicos para consultas no MongoDB causadas pelo desempenho de operações de disco, que anteriormente era um dos motivos da perda de alguns eventos.
Para evitar muitos dos problemas mencionados acima, usamos filas de tarefas para gravação adiada e lua-scripts, que possibilitam alterar atomicamente dados em várias estruturas de rabanete ao mesmo tempo. Com isso em mente, os detalhes para salvar visualizações são os seguintes:
- Quando um pedido de gravação cai no microsserviço, ele executa o script lua IncrementIfExists para aumentar o contador apenas se ele já existir no cache. O script retornará imediatamente -1 se não houver dados para a entidade sendo exibida no rabanete; caso contrário, aumenta o valor das visualizações no cache via HINCRBY , adiciona o evento à fila para armazenamento subsequente no MongoDB (chamado fila pendente por nós) via LPUSH e retorna a quantidade atualizada de visualizações.
- Se IncrementIfExists retornar um número positivo, esse valor será retornado ao cliente e a solicitação será encerrada.
Caso contrário, o microsserviço pega o contador de visualizações do MongoDb, o incrementa em 1 e o envia para o rabanete.
- A gravação no rabanete é realizada por meio de outro script lua - Upsert - que salva o número total de visualizações no cache, se ainda estiver vazio, ou aumenta em 1 se outra pessoa conseguir preencher o cache entre as etapas 1 e 3.
- Upsert também adiciona um evento de exibição à fila pendente e retorna uma quantia atualizada, que é então enviada ao cliente.
Devido ao fato de os scripts lua
serem executados atomicamente , evitamos muitos problemas em potencial que podem ser causados por uma gravação competitiva.
Outro detalhe importante é garantir a transferência segura de atualizações da fila pendente para o MongoDB. Para fazer isso, usamos o modelo "fila confiável" descrito na
documentação do
Redis , que reduz significativamente as chances de perda de dados, criando uma cópia dos elementos processados em uma fila separada e outra até que eles sejam finalmente armazenados em um armazenamento persistente.
Para entender melhor todas as etapas do processo, preparamos uma pequena visualização. Primeiro, vejamos um cenário normal e bem-sucedido (as etapas estão numeradas no canto superior direito e são descritas em detalhes abaixo):
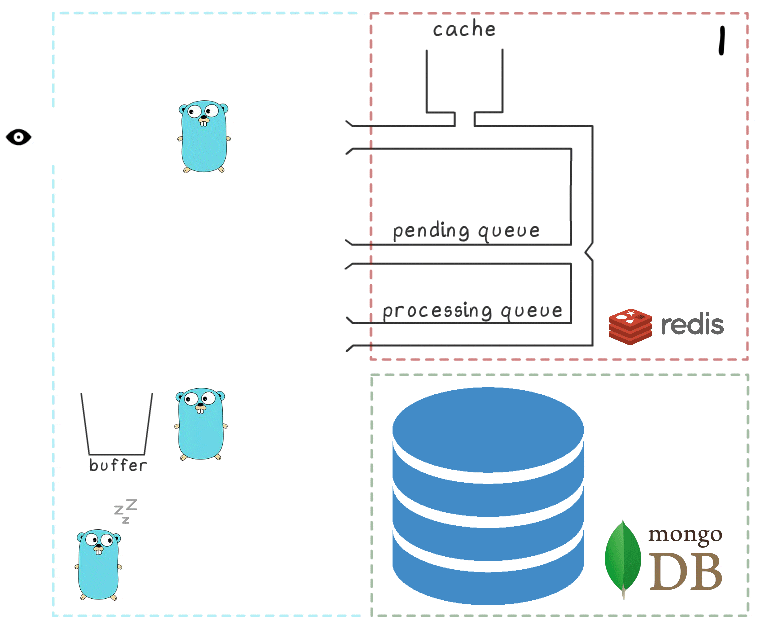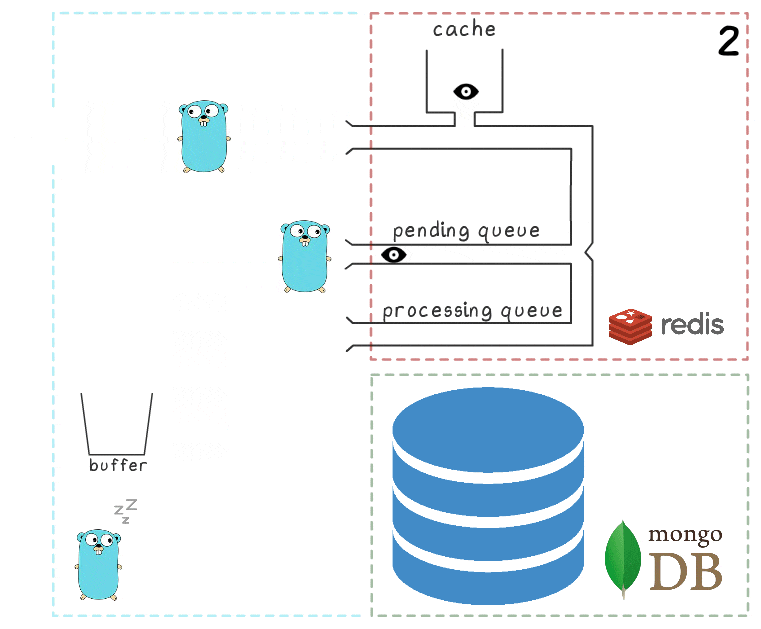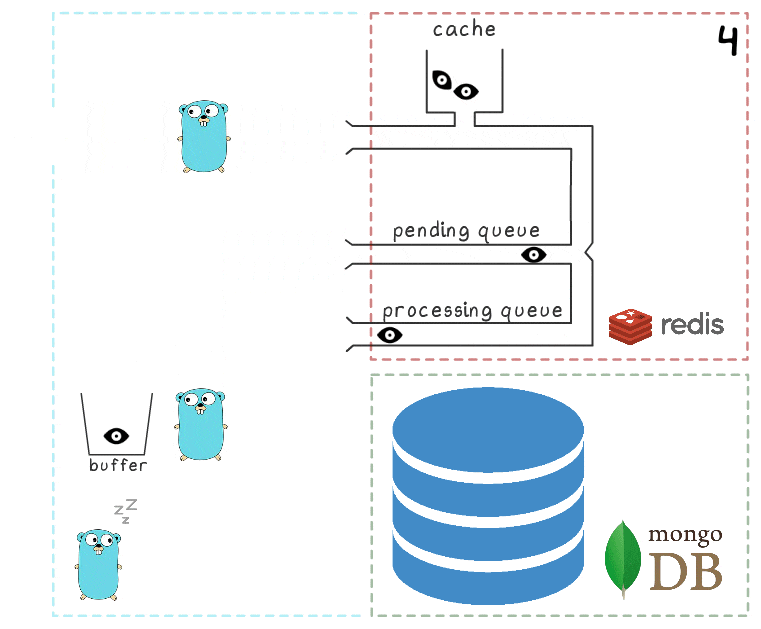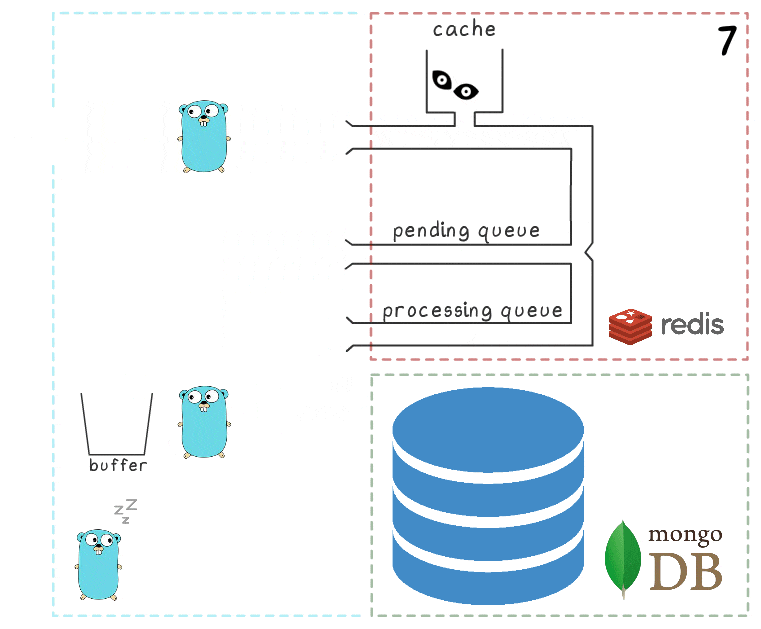
- O microsserviço recebe uma solicitação de gravação
- O manipulador de solicitação o passa para um lua-script que grava a pesquisa no cache (tornando-o imediatamente legível) e na fila para processamento adicional.
- A goroutine em segundo plano (periodicamente) executa a operação BRPopLPush , que move atomicamente um elemento de uma fila para outra (chamamos de “fila de processamento” - uma fila com elementos atualmente processados). O mesmo elemento é então armazenado em um buffer na memória do processo.
- Outra solicitação de gravação chega e está sendo processada, o que nos deixa com 2 elementos no buffer e 2 na fila de processamento.
- Após algum tempo limite, o processo em segundo plano decide liberar o buffer no MongoDB. A gravação de vários valores do buffer é realizada por uma única solicitação, o que afeta positivamente a taxa de transferência. Além disso, antes da gravação, o processo tenta combinar várias visualizações em uma, resumindo seus valores para os mesmos anúncios.
Em cada um dos nossos projetos, são usadas 3 instâncias de microsserviço, cada uma com seu próprio buffer, que é salvo no banco de dados a cada 2 segundos. Durante esse período, aproximadamente 100 elementos são acumulados em um buffer.
- Após uma gravação bem-sucedida, o processo remove itens da fila de processamento, sinalizando que o processamento foi concluído com êxito.
Quando todos os subsistemas estão em ordem, algumas dessas etapas podem parecer redundantes. E o leitor atento também pode ter uma pergunta sobre o que faz o esquilo que dorme no canto inferior esquerdo.
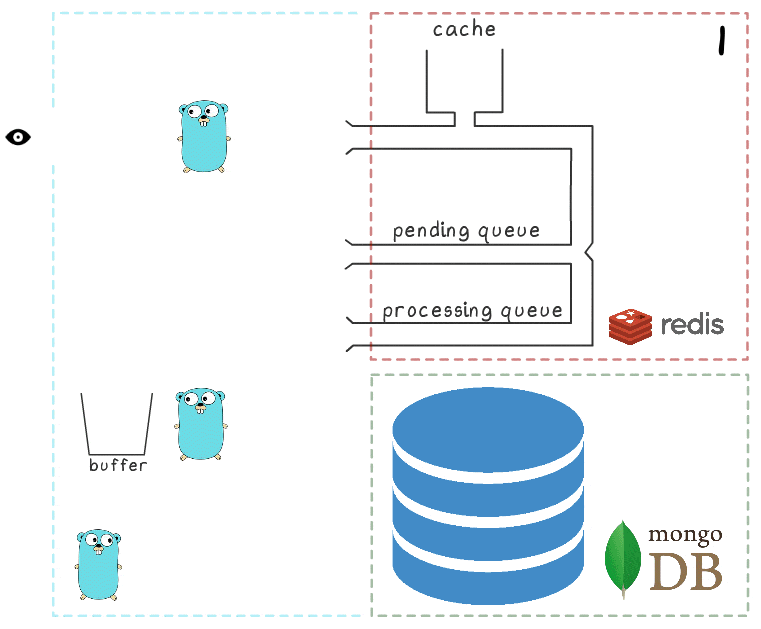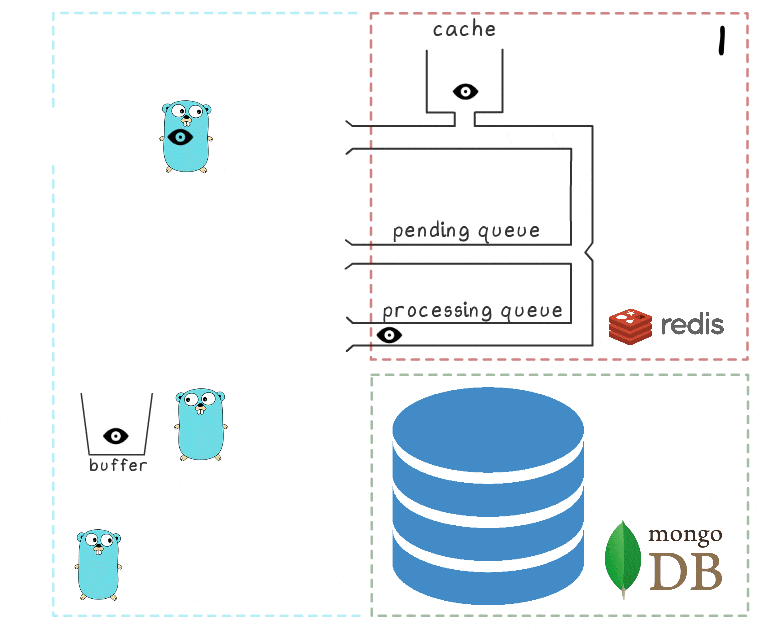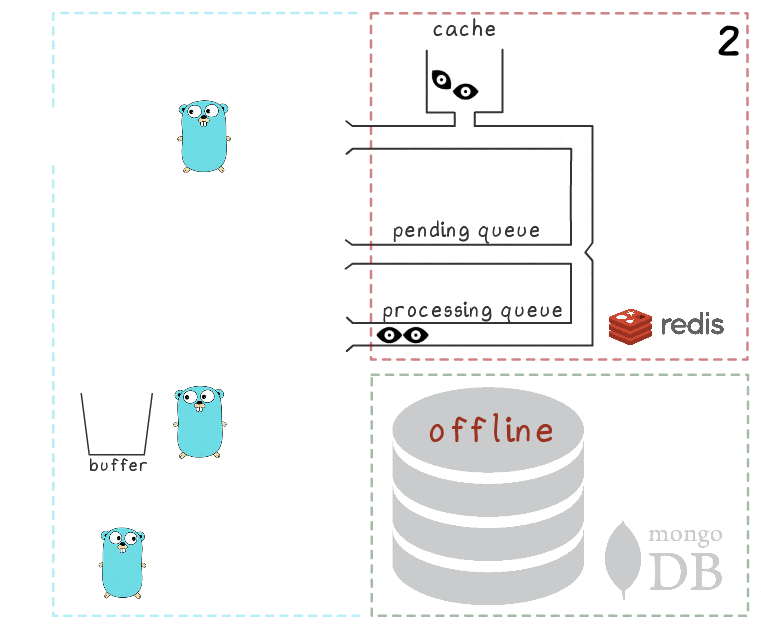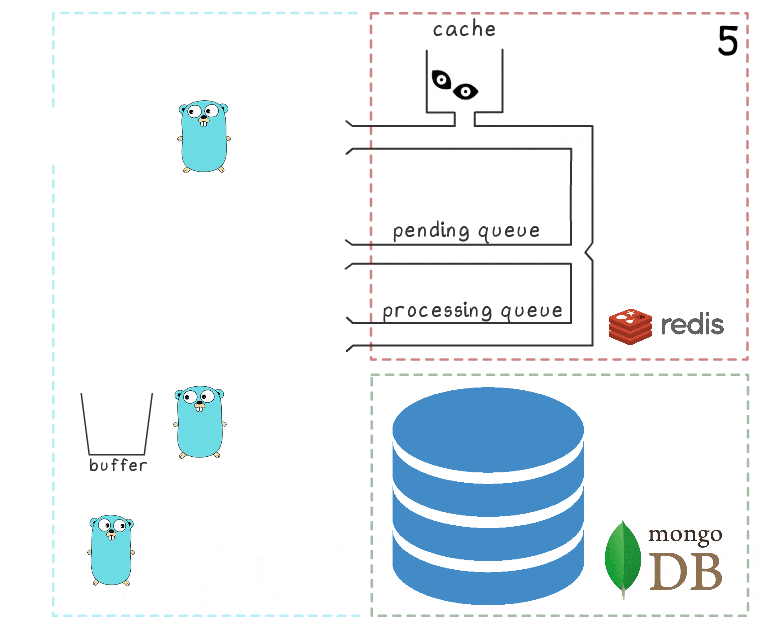
Tudo é explicado ao considerar o cenário em que o MongoDB não está disponível:
- A primeira etapa é idêntica aos eventos do cenário anterior: o serviço recebe 2 solicitações para registrar visualizações e processá-las.
- O processo perde a conexão com o MongoDB (o próprio processo, é claro, ainda não sabe sobre isso).
O manipulador Gorutin, como antes, está tentando liberar seu buffer no banco de dados - mas desta vez sem sucesso. Ela volta a aguardar a próxima iteração.
- Outra goroutine de segundo plano acorda e verifica a fila de processamento. Ela descobre que os elementos foram adicionados a ela há muito tempo; concluindo que o processamento falhou, ela os move de volta para a fila pendente.
- Depois de um tempo, a conexão com o MongoDB é restaurada.
- A primeira goroutine em segundo plano tenta novamente executar uma operação de gravação - desta vez com êxito - e, finalmente, remove permanentemente itens da fila de processamento.
Nesse esquema, existem vários tempos limite e heurísticos importantes derivados de testes e senso comum: por exemplo, os itens são movidos de volta da fila de processamento para a fila pendente após 15 minutos de inatividade. Além disso, a goroutine responsável por esta tarefa executa um
bloqueio antes da execução, para que várias instâncias do microsserviço não tentem restaurar as visualizações "congeladas" simultaneamente.
A rigor, mesmo essas medidas não fornecem garantias teoricamente fundamentadas (por exemplo, ignoramos cenários como o processo congela por 15 minutos) - mas, na prática, funciona de maneira bastante confiável.
Também neste esquema, existem pelo menos mais duas vulnerabilidades conhecidas por nós que são importantes para estar ciente de:
- Se o microsserviço falhar imediatamente após salvar com êxito no MongoDb, mas antes de limpar a lista de filas de processamento, esses dados serão considerados não salvos - e após 15 minutos serão salvos novamente.
Para reduzir a probabilidade de um cenário como esse, fornecemos tentativas repetidas para remover da fila de processamento em caso de erros. Na realidade, ainda não observamos esses casos em produção.
- Quando você reinicia, o rabanete pode perder não apenas o cache, mas também algumas visualizações não salvas das filas, pois está configurado para salvar periodicamente os instantâneos de RDB a cada poucos minutos.
Embora na teoria isso possa ser um problema sério (especialmente se o projeto lida com dados realmente críticos), na prática os nós são extremamente raramente reiniciados. Ao mesmo tempo, de acordo com o monitoramento, os elementos passam em filas por menos de 3 segundos, ou seja, a quantidade possível de perdas é muito limitada.
Pode parecer que há mais problemas do que gostaríamos. No entanto, de fato, o cenário do qual defendemos inicialmente - a falha do MongoDB - é realmente uma ameaça muito mais real, e o novo esquema de processamento de dados garante com sucesso a disponibilidade do serviço e evita perdas.
Um exemplo vívido disso foi quando a instância do MongoDB em um dos projetos ficou absurdamente indisponível a noite toda. Durante todo esse tempo, as contagens de exibição acumularam e giraram em um rabanete de uma fila para outra, até que finalmente foram salvas no banco de dados após a resolução do incidente; a maioria dos usuários nem percebeu a falha.
A contagem de visualizações de leitura
As solicitações de leitura são muito mais simples que as solicitações de gravação: o microsserviço primeiro verifica o cache no rabanete; tudo o que não é encontrado no cache é preenchido com dados do MongoDb e retornado ao cliente.
Não há gravação de ponta a ponta no cache durante as operações de leitura para evitar a sobrecarga de proteção contra gravações competitivas. O hitrate do cache permanece bom, pois, na maioria das vezes, ele já será aquecido graças a outras solicitações de gravação.
As estatísticas diárias de exibição são lidas diretamente no MongoDB, pois são solicitadas com muito menos frequência e o armazenamento em cache é mais difícil. Isso também significa que, quando o banco de dados não está disponível, as estatísticas de leitura param de funcionar; mas afeta apenas uma pequena parte dos usuários.
Esquema de armazenamento de dados do MongoDB
O esquema de coleta do MongoDB para o projeto é baseado
nessas recomendações dos próprios desenvolvedores do banco de dados e tem a seguinte aparência:
- As visualizações são salvas em 2 coleções: em uma existe o valor total, na outra - estatísticas por dia.
- Os dados na coleção de estatísticas são organizados com base em um documento por anúncio por mês . Para novos anúncios, um documento preenchido com trinta e um zero para o mês atual é inserido na coleção; De acordo com o artigo mencionado acima, isso permite que você aloque imediatamente espaço suficiente para um documento no disco, para que o banco de dados não precise movê-lo ao adicionar dados.
Esse item torna o processo de leitura de estatísticas um pouco estranho (as solicitações precisam ser geradas por meses no lado do microsserviço), mas, em geral, o esquema permanece bastante intuitivo.
- A operação upsert é usada para registrar, a fim de atualizar e, se necessário, criar um documento para a entidade desejada dentro da mesma solicitação.
Não usamos os recursos transacionais do MongoDb para atualizar várias coleções ao mesmo tempo, o que significa que corremos o risco de que os dados possam ser gravados em apenas uma coleção. Por enquanto, simplesmente registramos esses casos; existem poucos, e até agora isso não apresenta o mesmo problema significativo que outros cenários.
Teste
Não confiaria em minhas próprias palavras que os cenários descritos realmente funcionam se não fossem cobertos por testes.
Como a maioria do código do projeto trabalha em conjunto com rabanetes e MongoDb, a maioria dos testes são de integração. O ambiente de teste é suportado através do docker-compose, o que significa que ele pode ser implantado rapidamente, fornece reprodutibilidade redefinindo e restaurando o estado a cada inicialização e possibilita a experiência sem afetar os bancos de dados de outras pessoas.
Neste projeto, existem 3 áreas principais de teste:
- Validação da lógica de negócios em cenários típicos, os chamados caminho feliz. Esses testes respondem à pergunta - quando todos os subsistemas estão em ordem, o serviço funciona de acordo com os requisitos funcionais?
- Verificar cenários negativos em que o serviço deve continuar seu trabalho. Por exemplo, o serviço realmente não perde dados quando o MongoDb falha?
Temos certeza de que as informações permanecem consistentes com intervalos periódicos, congelamentos e operações de gravação competitivas? - Verificar cenários negativos em que não esperamos que o serviço continue, mas ainda deve ser fornecido um nível mínimo de funcionalidade. Por exemplo, não há chance de o serviço continuar salvando e fornecendo dados quando nem rabanete nem mongo estiverem disponíveis - mas queremos ter certeza de que, nesses casos, não trava, mas espera recuperação do sistema e volta ao trabalho.
Para verificar cenários sem êxito, o código lógico da empresa de serviços funciona com as interfaces do cliente de banco de dados, que nos testes necessários são substituídas por implementações que retornam erros e / ou simulam atrasos na rede. Também simulamos a operação paralela de várias instâncias de serviço usando o padrão "
objeto de ambiente ". Essa é uma variante da conhecida abordagem de "inversão de controle", na qual as funções não acessam as dependências, mas as recebem através do objeto de ambiente passado nos argumentos. Entre outras vantagens, a abordagem permite simular várias cópias independentes do serviço em um teste, cada uma com seu próprio conjunto de conexões com o banco de dados e reproduz com mais ou menos eficiência o ambiente de produção. Alguns testes executam cada uma dessas instâncias em paralelo e garantem que todos vejam os mesmos dados e que não haja condições de corrida.
Também realizamos um teste de estresse rudimentar, mas ainda bastante útil, baseado em
cerco , que ajudou a estimar aproximadamente a carga permitida e a velocidade de resposta do serviço.
Sobre desempenho
Para 90% das solicitações, o tempo de processamento é muito pequeno e, o mais importante - estável; Aqui está um exemplo de medidas em um dos projetos ao longo de vários dias:
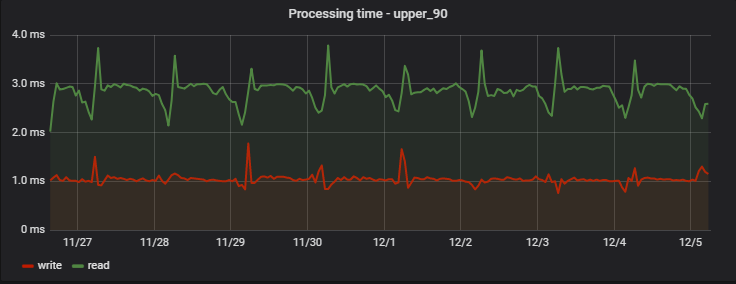
Curiosamente, um registro (que na verdade é uma operação de gravação + leitura, porque retorna valores atualizados) é um pouco mais rápido que a leitura (mas apenas do ponto de vista de um cliente que não observa o registro atrasado real).
Um aumento regular da manhã nos atrasos é um efeito colateral do trabalho de nossa equipe de análise, que coleta suas próprias estatísticas diariamente com base nos dados do serviço, criando uma "carga artificial artificial" para nós.
: ( — MongoDB), ( ), :
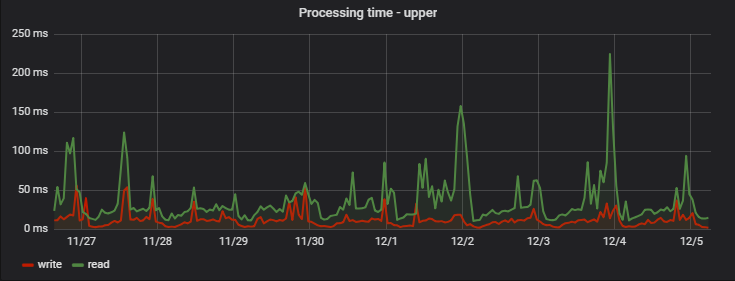
Conclusão
, - , , Redis .
, 95% , . , . 5.
Go, Redis MongoDB . , . , — .