Recentemente, Yegor Budnikov, analista de sistemas do departamento de tecnologia da ABBYY, falou na Yandex na conferência
Data & Science: Law and Records Management . Ele contou como a visão por computador funciona, o processamento de texto ocorre, o que é importante prestar atenção ao extrair informações de documentos legais e muito mais.
- Uma empresa pode ter desenvolvido metodologias para análise de dados e gerenciamento eletrônico de documentos, enquanto os documentos criados no Word podem ser provenientes de clientes ou de departamentos vizinhos da empresa, enquanto impressos, fotocopiados, digitalizados e levados para uma unidade flash.
O que fazer com o fluxo de documentos, que é agora, com documentos “sujos”, com armazenamento de papel, até o fato de que os documentos podem ser armazenados por até 70 anos antes de serem digitalizados e devem ser reconhecidos?
A ABBYY está desenvolvendo tecnologias de inteligência artificial para tarefas de negócios. A inteligência artificial deve ser capaz de fazer aproximadamente a mesma coisa que uma pessoa faz nas atividades cotidianas ou profissionais, a saber: ler informações sobre o mundo real a partir de uma imagem ou fluxo de imagens. Isso pode ser não apenas a visão do computador, mas também a audição ou o reconhecimento de dados dos sensores, por exemplo, dos sensores de fumaça ou temperatura. Além disso, os dados desses sensores entram no sistema e devem participar da decisão. Para implementar com êxito essa função, o sistema deve evitar erros lógicos estúpidos, como na figura:

Os textos são difíceis de analisar: a diversidade e o desenvolvimento da linguagem os tornam belos e expressivos, mas isso complica a tarefa de seu processamento automático. Geralmente, a ambiguidade das palavras é superada pelo fato de podermos determinar pelo contexto o que uma palavra específica significa, mas às vezes o contexto deixa espaço para interpretação. Na frase "
Esses tipos de aço estão em estoque ", é impossível entender com absoluta precisão em termos de contexto: se são pessoas na sala que almoçam ou se são alguns tipos de aço armazenados no armazém. Para resolver essa ambiguidade, é necessário um contexto mais amplo.
A parte inferior da colagem é um quadro do filme "Operação" Y "e outras aventuras de Shurik".No caso geral, a inteligência artificial ou um robô inteligente deve poder se mover no espaço e interagir com êxito com objetos - por exemplo, pegue a caixa repetidamente, o que o instrutor bate em suas mãos.
Finalmente, o intelecto geral e a representação do conhecimento: o conhecimento difere da informação, pois suas partes interagem ativamente entre si, gerando novos conhecimentos. Para resolver efetivamente o problema de misturar coquetéis, você pode seguir o caminho simples: liste os ingredientes e indique em que ordem os misturar. Nesse caso, o sistema não poderá responder a perguntas arbitrárias sobre o assunto de seu interesse. Por exemplo, o que acontece se você substituir o suco de tomate por abacaxi. Para que o sistema domine o material mais profundamente, bancos de dados, taxonomias (árvores de conceito logicamente relacionadas entre si), um procedimento de inferência lógica deve ser adicionado. Nesse caso, podemos realmente dizer que o sistema entende o que está fazendo e poderá responder a uma pergunta arbitrária sobre o processo.
A inteligência artificial desenvolvida pela ABBYY processa documentos, ou seja, transforma papel, mídia digitalizada e eletrônica em informações estruturadas extraídas desses documentos. Vamos nos debruçar sobre dois componentes, como visão computacional e processamento de texto. A visão computacional permite transformar PDF, imagens digitalizadas e imagens em formatos de texto editáveis. Por que essa é uma tarefa difícil? Em primeiro lugar, os documentos podem ter uma estrutura arbitrária.
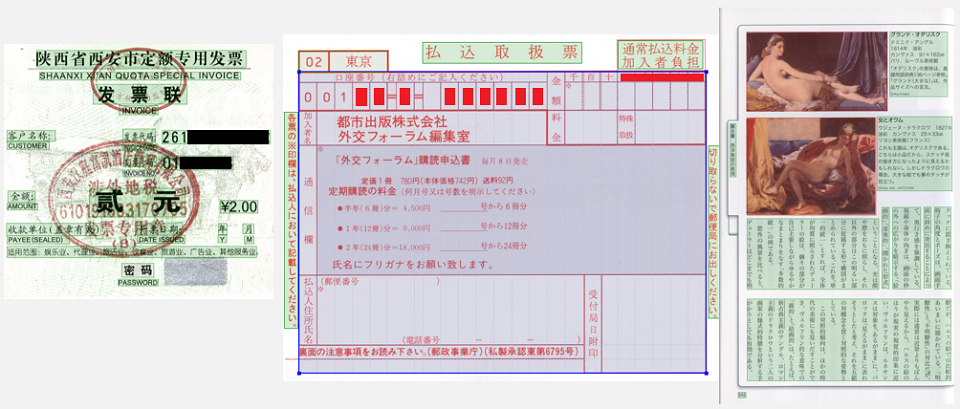
Isso significa que primeiro você precisa resolver o problema da análise estrutural de documentos: para entender onde os blocos de texto, figuras, tabelas, listas estão localizados e depois determinar como eles interagem entre si. Em segundo lugar, os documentos podem estar em diferentes idiomas. Isso significa que é necessário apoiar a detecção de diferentes tipos de escrita e a capacidade de reconhecer palavras e caracteres que podem ser muito diferentes um do outro. Terceiro, as imagens chegam do mundo real, o que significa que tudo pode acontecer com elas. Eles podem estar distorcidos, fotografados com a perspectiva errada, podem ter manchas de café, riscos na impressora e depois no scanner. Tudo isso deve ser de alguma forma gerenciado para extrair informações posteriormente.
Como o reconhecimento de imagem funciona conosco? Na primeira etapa, recebemos e processamos imagens. O documento está nivelado, as distorções são corrigidas. Em seguida, é realizada uma análise da estrutura da página; nesse estágio, os tipos de blocos são encontrados e determinados. Quando os blocos são definidos, as linhas ou colunas são alinhadas, é possível dividir essas linhas em palavras e símbolos - por exemplo, por histogramas verticais e horizontais da distribuição da cor preta.
Assim, é possível determinar onde estão os limites dos símbolos e das palavras e depois reconhecer quais são esses símbolos e palavras. Finalmente, os blocos reconhecidos são sintetizados em documentos de texto único e exportados.
Você pode ver esse processo do ponto de vista de entidades de diferentes níveis. Primeiro, temos um documento que é paginado. Então essas páginas devem ser divididas em blocos, blocos em linhas, linhas em palavras, palavras em caracteres e, em seguida, esses caracteres devem ser reconhecidos. Depois disso, coletamos os caracteres reconhecidos em palavras, palavras em linhas, linhas em blocos, blocos em páginas, páginas em um documento. Além disso, no caminho de volta, a partição inicial pode variar. O exemplo mais simples é se os blocos quebrados inicialmente pertencerem à mesma lista numerada; portanto, eles deverão pertencer ao mesmo bloco com o tipo de lista estruturada. Em outras palavras, etapas adjacentes podem se influenciar para melhorar a qualidade do reconhecimento.
O documento foi reconhecido, então você precisa extrair informações dele. Os documentos podem ser divididos em mais estruturados e menos estruturados. Os mais estruturados incluem cartões de visita, cheques, faturas. Os menos estruturados incluem procuração, cartas, artigos em revistas. Se o tipo de documento é fixo, é mais ou menos estruturado e os documentos desse tipo diferem pouco um do outro na estrutura, você pode aplicar métodos que aprendem a extrair diretamente os atributos necessários de um documento de texto usando atributos de texto e gráficos. Por exemplo, usando redes neurais recorrentes, você pode extrair itens de produtos de faturas. Faturas são documentos nos quais são apresentadas as posições das mercadorias e uma descrição dos métodos de pagamento para essas mercadorias.

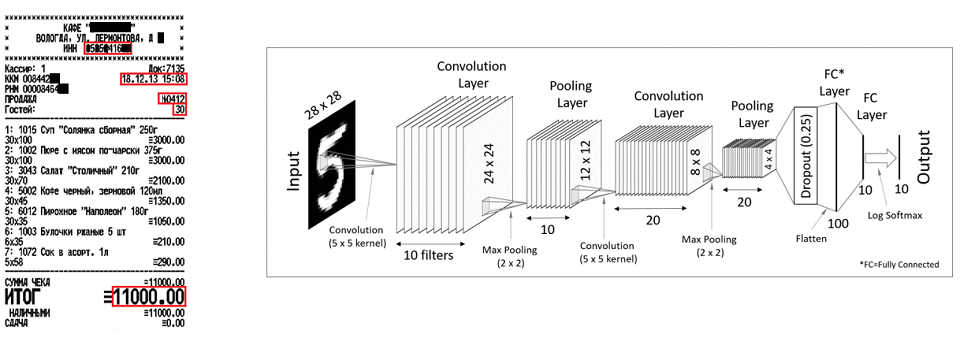
Outro exemplo são os cheques. Usando redes neurais convolucionais, você pode recuperar atributos únicos, como NIF, número do cheque, data e hora, pontuação total. Francamente falando, métodos e cheques são usados em cheques e faturas, mas para propósitos diferentes. Redes neurais convolucionais são boas para atributos únicos que têm algum tipo de posição, e redes recorrentes são para elementos repetidos.
Se os documentos são menos estruturados, os métodos de processamento de linguagem natural, processamento de linguagem natural ou PNL entram em jogo. Por que isso é difícil? Eu já falei sobre a polissemia das palavras. A palavra endereço, por exemplo, pode significar o endereço de uma empresa ou o compromisso de resolver alguns problemas do cliente.
Além disso, os textos são frequentemente omitidos, mas as palavras estão implícitas. Para extrair informações, você precisa recuperar essas palavras ausentes. Esse efeito na linguística é chamado de "elipse".
A linguagem é diversa e geralmente existem inúmeras maneiras de expressar o mesmo pensamento. Para processar automaticamente os textos, é necessário reduzir de alguma forma essa variabilidade: o uso de sinônimos e construções semelhantes para substituir uma única palavra ou expressão; permutação de palavras ou mudança de voz gramatical. Por exemplo, “empresas concluíram um acordo” e “um acordo foi concluído entre empresas” para dizer a mesma coisa. No caso de sinônimos, pode-se introduzir o chamado espaço semântico, um espaço vetorial no qual as palavras são representadas como pontos. Pontos próximos indicam conceitos relacionados, pontos distantes indicam conceitos mais distantes. Para reduzir a variabilidade das formulações, é possível introduzir árvores de análise sintática e semântica. Nesse caso, um problema semelhante também é resolvido, e o algoritmo de extração de informações é capaz de extrair informações, mesmo que encontre construções ou palavras que não foram encontradas anteriormente no conjunto de treinamento.
Como as informações são extraídas? Na primeira etapa, é realizada uma análise lexical do documento. O texto é dividido em parágrafos, parágrafos em sentenças, sentenças em palavras. Isso pode não ser trivial: aqueles que conhecem a PNL podem saber que mesmo uma tarefa aparentemente simples como dividir o texto em frases pode ser difícil: pontos nem sempre indicam o fim de uma frase. Essas podem ser abreviações desconhecidas; portanto, na análise lexical, tentamos separar todas as opções possíveis para dividir frases em palavras e deixar as mais prováveis. Este problema, como regra, encontramos em idiomas em que um número pequeno ou completa ausência de espaços, como japonês ou chinês. Ou quem tem uma rica formação de palavras. Por exemplo, é um idioma como o alemão: possui palavras muito longas que consistem em várias palavras (essas são chamadas de compostos). Além disso, para todas essas palavras, todas as possíveis interpretações são calculadas. Por exemplo, se "g" aparecer no texto com um ponto, pode significar muito: cidade, ano, grama, senhor e até o quarto parágrafo (a, b, c, d).

Em seguida, é realizada a segmentação, ou seja, uma pesquisa pelas seções de seu interesse. É produzido por vários motivos, por exemplo, para acelerar o processamento de documentos ou encontrar informações que nos interessam; para encontrar alguma parte do documento que descreva as obrigações da parte. Ou isso é uma aceleração do processamento, por exemplo, nosso documento pode consistir em várias dezenas ou até centenas de páginas em casos especialmente avançados, enquanto informações interessantes estão contidas em apenas algumas páginas. A segmentação permite encontrar essas peças interessantes e analisá-las apenas. Então, uma análise semântica do documento pode ou não ser realizada, depende da tarefa e, nesta etapa, é feita a busca pelas melhores interpretações das sentenças, todas as sentenças do documento ou apenas aquelas que encontramos na etapa anterior. Recursos semânticos para o classificador também são gerados na próxima etapa.
Finalmente, o estágio de extração direta de atributos. Modelos treinados por máquina são usados aqui ou padrões simples são escritos. De uma forma ou de outra, eles contam com sinais gerados pelas etapas anteriores. Essas são características estruturais, tanto lexicais quanto semânticas. Dependendo da complexidade da tarefa, usamos muitos métodos diferentes: métodos de aprendizado de máquina e métodos de escrita de modelo. Nesta fase, estamos procurando os atributos que nos interessam. Podem ser os nomes das partes, obrigações, data de assinatura, etc.
Finalmente, alguns atributos podem exigir pós-processamento. Trazendo para a forma normal ou transmitindo para um modelo de data. Alguns atributos podem ser calculados em princípio, eles não são extraídos do contrato, mas são calculados com base nos atributos que são extraídos do contrato. Por exemplo, a duração do contrato com base no início da ação e seu fim.
Considere isso em um dos cenários, chamado "Abrir uma conta com uma entidade legal". Qual é o desafio? Uma entidade legal, ou melhor, seu representante, vem ao banco e traz uma pilha pesada de documentos. Em um bom caso, ele já digitalizou esses documentos, mas não está claro com qual qualidade. Para otimizar o processo, reduzir o número de erros ao inserir essas informações no sistema, acelerar esse processo e, portanto, acelerar a tomada de decisões e aumentar a fidelidade do cliente, o seguinte esquema foi proposto:
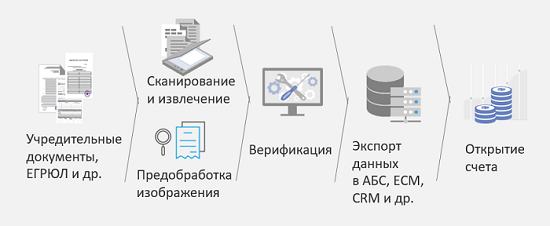
Os documentos constituintes, que incluem muitos tipos diferentes, são digitalizados primeiro e depois reconhecidos. Além disso, após o reconhecimento, eles são classificados por diferentes tipos e, dependendo do tipo, diferentes algoritmos podem ser usados para reconhecer e extrair informações. Em seguida, essas informações extraídas, se necessário, são enviadas às pessoas para verificação e, depois disso, já é possível tomar uma decisão: abrir uma conta ou são necessários outros documentos adicionais. O principal resultado dessa decisão é reduzir pela metade o custo da entrada de dados ao abrir uma conta. Resultados baseados em medições do nosso cliente.
Quais atributos você precisa recuperar? Muitas coisas. Suponha que tenhamos algum tipo de carta patente entrando. Primeiro nós a reconhecemos. Como lembramos, isso pode ser bastante problemático se for uma digitalização ou fotografia. Em seguida, determinamos o tipo de documento, e isso é importante porque as informações de que precisamos podem estar contidas em um capítulo ou subcláusula específica e, portanto, o conhecimento de quando esse capítulo ou subcláusula começa ou termina ajuda muito o algoritmo de extração de informações.
Em seguida, a máquina recupera todas as entidades básicas que pode alcançar:
Isso é necessário para que, no próximo estágio de extração de atributos ou definição de funções, o algoritmo possa usar não apenas o contexto, mas também as características que foram geradas nos estágios anteriores. Por exemplo, pode simplificar bastante a tarefa de determinar quem é o diretor de uma entidade legal, informações de que esse é algum tipo de pessoa. Portanto, dentre o conjunto de pessoas que aparecem no documento, devemos classificá-las, o diretor ou não. Quando temos um número limitado de objetos, isso simplifica bastante a tarefa.
Nos últimos dois anos, encontramos várias outras tarefas de clientes e as resolvemos com sucesso. Por exemplo, monitoramento de mídia para riscos corporativos.
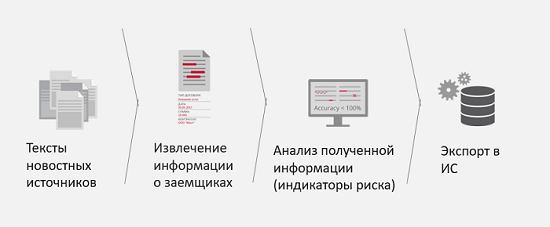
Qual é o desafio comercial aqui? Por exemplo, você tem um parceiro ou cliente em potencial que deseja fazer um empréstimo com você. Para acelerar o processamento dos dados deste cliente e reduzir os riscos de uma má parceria ou a falência futura dessa entidade legal, sugere-se que a mídia seja monitorada quanto a referências a esse indivíduo ou entidade legal e à presença dos chamados indicadores de risco nas notícias. Ou seja, se, por exemplo, nas notícias constantemente aparecer que uma entidade legal está envolvida em processos judiciais ou que uma empresa está quebrada por conflitos de acionistas, é melhor descobrir mais cedo para passar essas informações aos analistas ou ao sistema analítico e entender o quão ruim ou bom é para seus negócios. . O resultado da solução desse problema é obter informações mais completas e precisas sobre o mutuário, e a quantidade de tempo para obter essas informações também é reduzida.

Outro exemplo de aplicação em que é necessário reduzir a quantidade de rotina e o número de erros ao inserir informações no sistema é a extração de dados de contratos. Propõe-se que os contratos reconheçam, extraiam informações deles e os enviem imediatamente para o sistema. Depois disso, o departamento de pessoal agradece você em lágrimas e calorosamente em todas as reuniões.
O departamento de recursos humanos não apenas sofre muito trabalho de rotina com a documentação recebida, mas também os departamentos de contabilidade, departamentos de vendas e departamentos de compras. Os funcionários precisam gastar muito tempo inserindo informações de faturas, atos recebidos e assim por diante.

De fato, todos esses documentos são estruturados e, portanto, é fácil reconhecer e extrair informações deles. A velocidade da entrada de dados é aumentada em até 5 vezes e o número de erros é reduzido, porque o fator humano é excluído. Condicionalmente, se um funcionário retornar após o almoço, ele poderá começar a inserir dados de forma desatenta. Nossas próprias medições e o setor, que de uma maneira ou de outra estão envolvidos na entrada manual de informações nos sistemas, sugerem que, se uma pessoa digita dados de um documento e faz isso continuamente e em um fluxo, ela raramente obtém uma qualidade de mais de 95%, e com mais frequência e mais de 90%. Portanto, uma pessoa precisa ser contada, verificada duas vezes mais do que atrás de uma máquina.
Além disso, se a máquina der algum tipo de avaliação de confiança que não extraiu - por exemplo, algum documento pode estar sujo - e a máquina não tem certeza disso, mas pode sinalizar ao verificador que não tem muita certeza desse resultado : "Verifique novamente." E uma pessoa verifica as informações individuais para que sejam de alta qualidade. Esta não é uma operação rotineira: ele verifica apenas momentos realmente importantes e difíceis, seus olhos não estão embaçados.
Se informações podem ser extraídas de documentos, essas informações podem ser comparadas.
Isso é importante em dois casos. Em primeiro lugar, para comparar versões diferentes de um documento, por exemplo, um contrato que há muito tempo é consistente, são constantemente feitas alterações nos dois lados. Em segundo lugar, é uma comparação de documentos de vários tipos, por exemplo, se houver um acordo que indique o que deve vir do nosso parceiro, por outro lado, existem diferentes faturas e relatórios, estimativas, etc. Precisamos correlacioná-los e entender que tudo está em ordem, e se não estiver em ordem, de alguma forma sinaliza isso para as pessoas responsáveis.
O desenvolvimento atual da tecnologia em visão computacional, o processamento de documentos estruturados e não estruturados é tão alto que, mesmo agora e nos próximos anos, haverá uma transformação digital de processos de rotina nas empresas, porque é mais barato, mais rápido e frequentemente melhor.
Além disso, todos esses métodos não têm a intenção de substituir as pessoas. Em vez disso, gosto do exemplo de comparação com a ferramenta Excel, na qual você pode fazer muito e essa ferramenta não se destina a substituir analistas, gerentes ou qualquer outra pessoa. Ele foi projetado para expandir as capacidades humanas e simplificar a solução de tarefas para ele.
Assim, soluções relacionadas à inteligência artificial também são projetadas para reduzir o número de operações repetitivas de rotina nas quais uma pessoa geralmente comete mais erros do que uma máquina, a fim de descarregar os recursos da empresa e direcioná-los para resolver tarefas mais criativas e intelectuais. E parece que estamos nos mudando para lá a todo vapor. Obrigada