
A loja on-line Ozon tem praticamente tudo: geladeiras, comida para bebê, laptops por 100.000, etc. Isso significa que tudo isso também está nos armazéns da empresa - e quanto mais tempo os produtos estiverem lá, mais cara a empresa será. Para descobrir quanto e o que as pessoas gostariam de pedir, e o Ozon precisaria comprar, usamos o aprendizado de máquina.
Previsão de vendas: desafios
Antes de nos aprofundarmos na declaração do problema, começamos com um exemplo. Este é um cronograma de vendas real da Ozon por um tempo. Pergunta: onde ele irá a seguir?
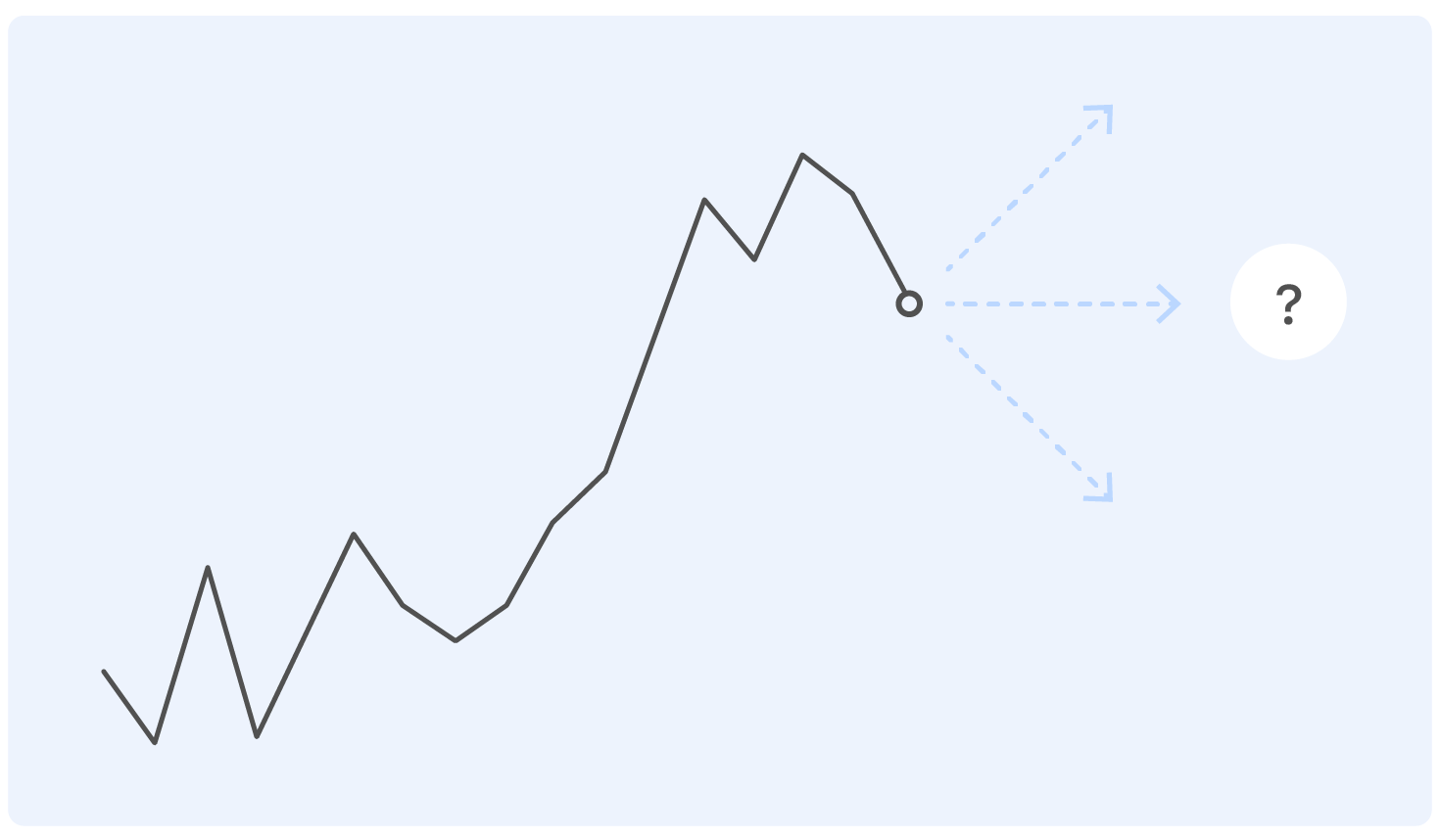
Uma pessoa com formação quase técnica para essa formulação do problema terá perguntas: Onde estão os eixos? E que tipo de produto? E em que unidades? De que instituto você se formou? - e muitos outros não incluídos neste artigo por razões éticas.
De fato, ninguém pode responder corretamente à pergunta em tal afirmação, e se alguém puder, provavelmente será enganado.
Adicione mais informações a este gráfico: eixos e mudanças de preço no site da Ozon (azul) e no site do concorrente (laranja).
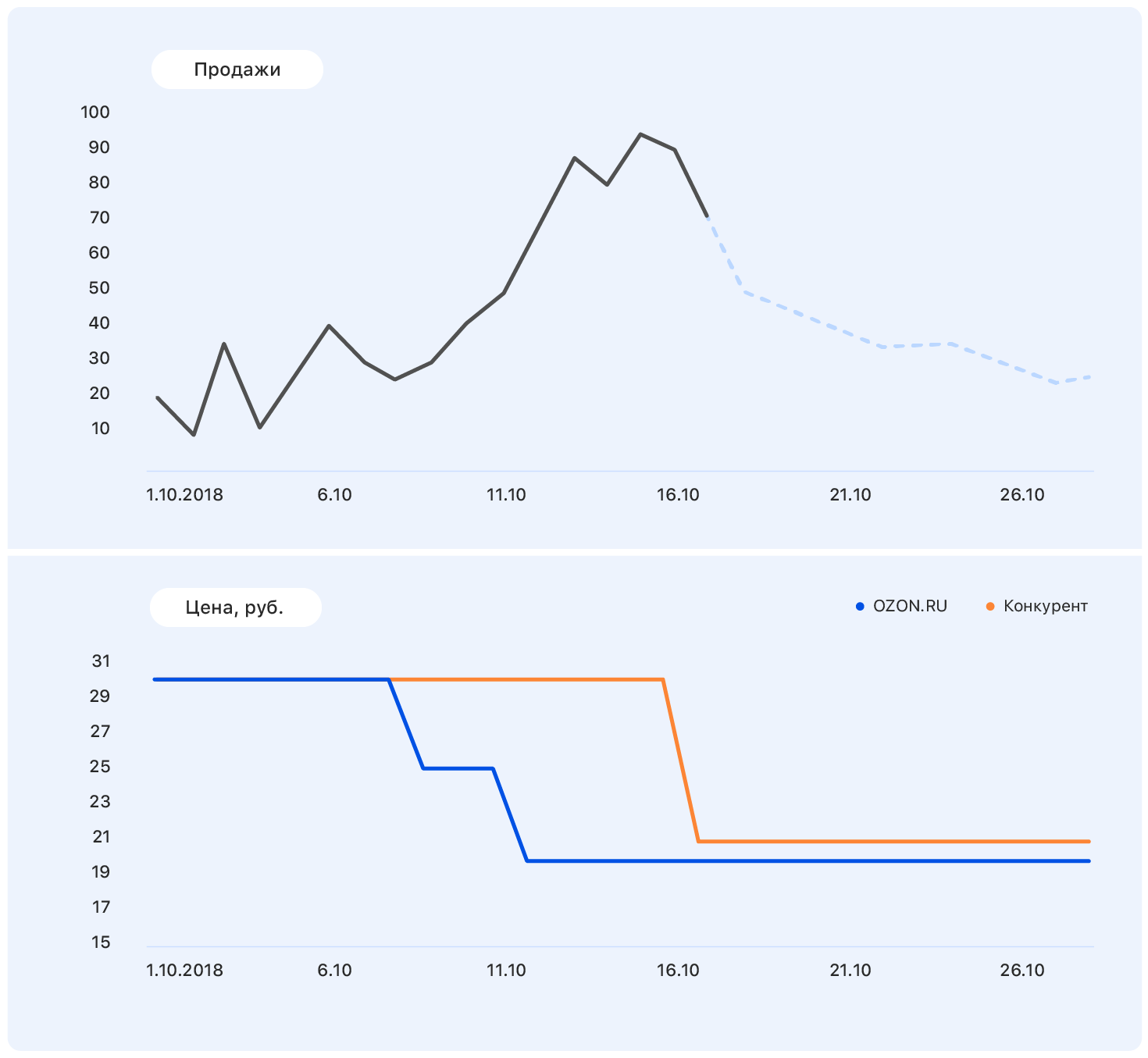
Nosso preço caiu em algum momento, mas a concorrência permaneceu a mesma - e as vendas da Ozon aumentaram. Conhecemos os planos de preços: nosso preço permanecerá no mesmo nível, mas o concorrente, seguindo Ozon, reduziu o preço para quase o nosso.
Esses dados são suficientes para fazer uma suposição significativa - por exemplo, que as vendas retornarão ao nível anterior. E se você olhar para o gráfico, verifica-se que será assim.
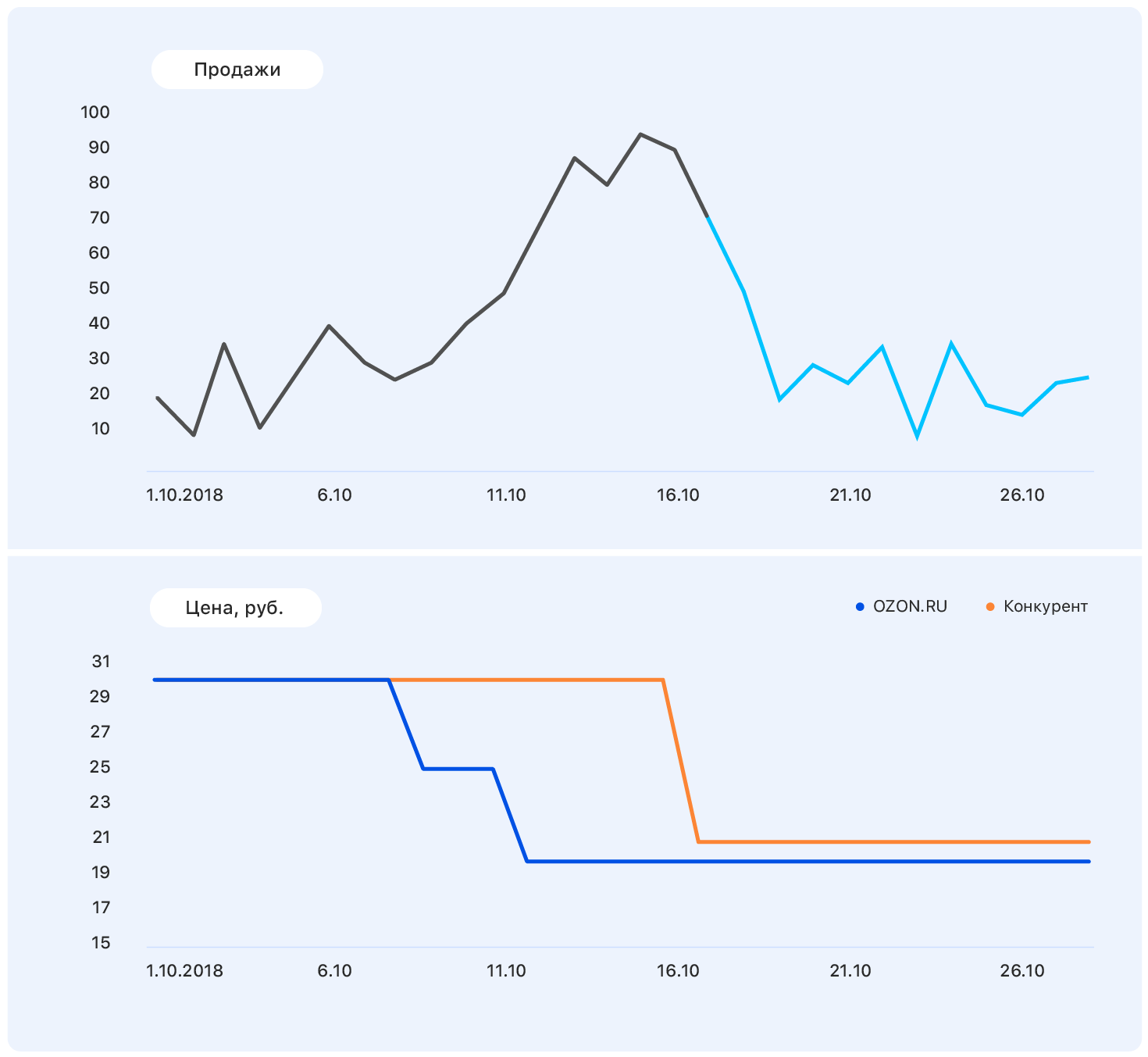
O problema é que, de fato, a demanda por este produto não é muito afetada pelo preço, e o crescimento das vendas foi causado, entre outras coisas, pela ausência da maioria dos concorrentes desse produto em nossa loja. Ainda existem muitos fatores que não levamos em consideração: os produtos foram anunciados na TV? ou talvez sejam doces, e logo em 8 de março?
Uma coisa é clara: fazer uma previsão "no joelho" não funcionará. Seguimos o caminho padrão de um
ancinho e muletas para construir qualquer algoritmo de ML. E é assim que foi.
Seleção de métricas
A escolha de uma métrica é por onde começar se pelo menos uma outra pessoa além de você usar sua previsão.
Considere um exemplo: temos três opções de previsão. Qual é melhor?
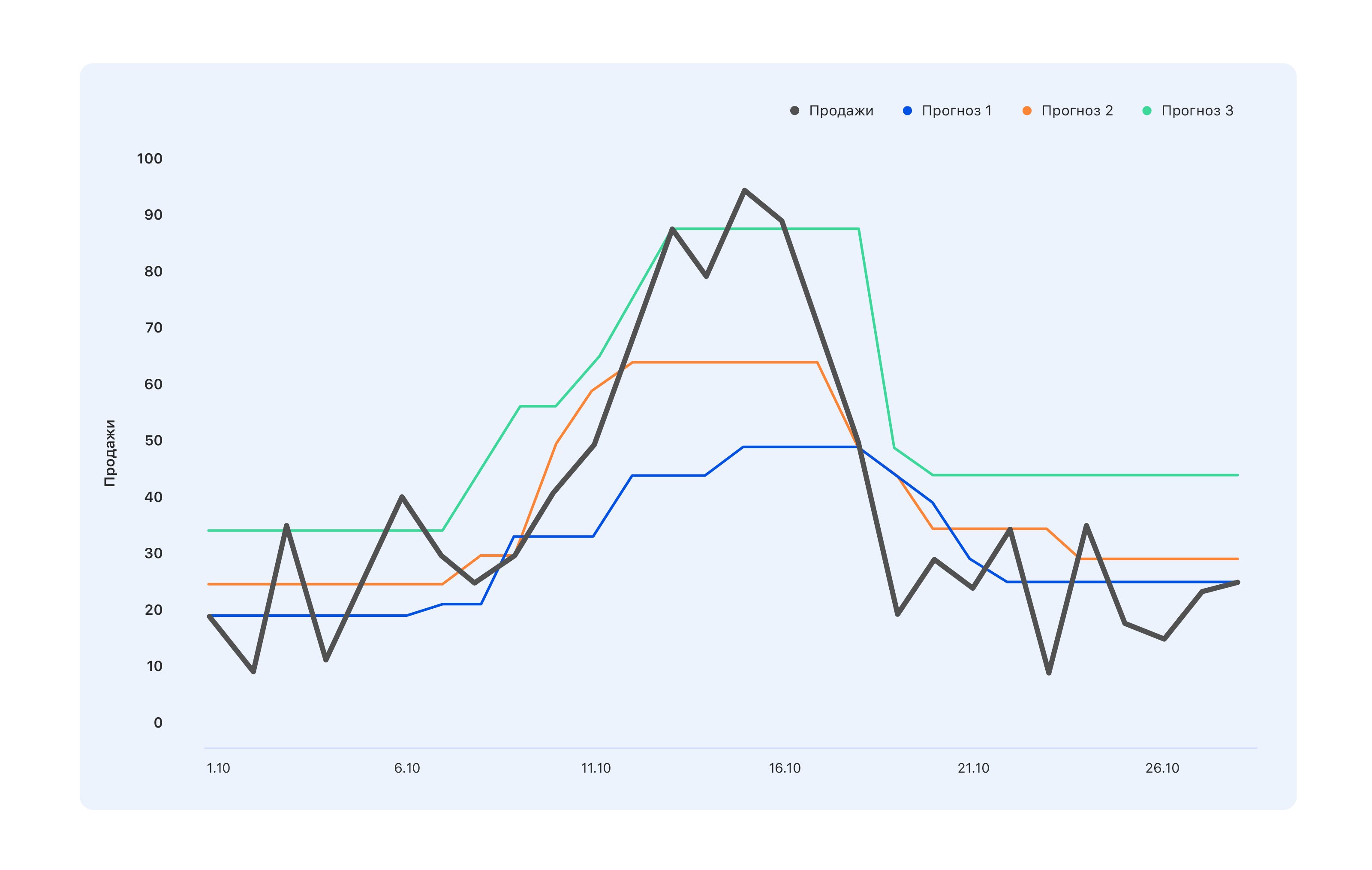
Do ponto de vista dos especialistas no armazém, precisamos de uma previsão azul - compraremos um pouco menos e vamos perder o pico em meados de outubro, mas nada permanecerá no armazém. Os especialistas cujo KPI está vinculado às vendas têm a opinião oposta: mesmo a previsão turquesa não é muito correta, nem todos os saltos na demanda se refletiram - vá modificá-la. Mas, do ponto de vista de uma pessoa, de fora, geralmente algo melhor está em ordem - para que todos se sintam bem ou vice-versa.
Portanto, antes de fazer uma previsão, é necessário determinar quem o usará e por quê. Ou seja, escolha uma métrica e entenda o que esperar de uma previsão criada com base nessa métrica. E espere por isso.
Escolhemos o MAE - o erro absoluto médio. Essa métrica é adequada para nossa amostra de treinamento altamente desequilibrada. Como o sortimento é muito amplo (1,5 milhão de itens), cada produto individualmente em uma região específica é vendido em pequenas quantidades. E se no total vendermos centenas de vestidos verdes, um vestido verde específico com gatos será vendido a 2-3 por dia. Como resultado, a amostra muda para valores pequenos. Por outro lado, existem iPhones, spinners, um novo livro de Olga Buzova (uma piada), etc. - e são vendidos em qualquer cidade em grandes quantidades. O MAE permite que você não receba multas enormes em iPhones condicionais e geralmente funcione bem na maior parte dos produtos.
Primeiros passos
Começamos construindo a previsão mais estúpida que poderia ser: um número aleatório de 0 a 1000 será vendido na próxima semana e obterá a métrica MAE = 496. Provavelmente, pode ser pior, mas isso já é muito ruim. Então, temos uma orientação: se obtivermos um valor tão métrico, obviamente estaremos fazendo algo errado.
Em seguida, começamos a interpretar pessoas que sabem como fazer uma previsão sem aprendizado de máquina e tentamos prever as vendas de mercadorias na próxima semana iguais às vendas médias de todas as últimas semanas e obtivemos a métrica MAE = 1,45 - que é muito melhor.
Continuando a raciocinar, decidimos que as vendas da semana passada não seriam mais relevantes para a previsão de vendas para a próxima semana. Para tal previsão, o MAE foi de 1,26. Na próxima rodada de pensamento prognóstico, decidimos levar em conta os fatores e prever vendas para a próxima semana como a soma de 50% das vendas médias e 50% das vendas na semana passada - obtivemos MAE = 1,23.
Mas parecia-nos muito simples e decidimos complicar as coisas. Coletamos uma pequena amostra de treinamento na qual os sinais eram vendas passadas e médias, e as metas eram vendas na semana seguinte e treinamos nela uma regressão linear simples. Obtivemos pesos de 0,46 e 0,55 para a média e as últimas semanas e o MAE na amostra de teste foi igual a 1,2.
Conclusão: nossos dados têm potencial preditivo.
Engenharia de recursos
Tendo decidido que construir uma previsão por dois motivos não é o nosso nível, sentamos para gerar novos recursos complexos. São informações sobre vendas anteriores - 1, 2, 3, 4 semanas atrás, uma semana exatamente há um ano, etc. E visualizações nas últimas semanas, adições à cesta, conversão de visualizações e adições à cesta em pedidos - e tudo isso por diferentes períodos.
Precisávamos fornecer um modelo de conhecimento sobre como o produto como um todo é vendido, como a dinâmica de suas vendas mudou recentemente, como o interesse está evoluindo, como suas vendas dependem do preço e de outros fatores que, em nossa opinião, podem ser úteis.
Quando nossas idéias acabaram, fomos aos especialistas do departamento de vendas. Lá, por exemplo, aprendemos que o próximo ano é o ano do porco, portanto, produtos pelo menos remotamente parecidos com porcos serão muito populares. Ou, por exemplo, que o “não congelamento” que nosso pessoal não compra com antecedência, mas exatamente no dia das primeiras geadas - por isso, leve em consideração a previsão do tempo. Em geral, todos estavam satisfeitos. Nós - porque recebemos um monte de novas idéias que nunca teríamos pensado em nós mesmos e nos empresários - que em breve será possível fazer algo mais interessante do que a previsão de vendas.
Mas ainda é muito simples - e adicionamos sintomas combinados:
- conversão de visualizações em vendas - como foi, como mudou;
- a proporção de vendas ao longo de 4 semanas e vendas na semana passada (se esse valor for muito diferente de 4, no momento a demanda por esse produto está sujeita a "turbulência");
- a proporção entre vendas de produtos e vendas em toda a categoria - se esse valor for próximo de um, o produto será um "monopolista".
Nesta fase, você precisa apresentar o máximo possível - jogue fora sinais não informativos na fase de treinamento.
Como resultado, temos 170 sinais. No futuro, a maior importância dos recursos
- Vendas da semana passada (para duas, três e quatro).
- A disponibilidade do produto na semana passada é a porcentagem de tempo em que o produto esteve presente no site.
- O coeficiente angular do cronograma de vendas de mercadorias nos últimos 7 dias.
- A proporção do preço passado para o futuro - com um grande desconto, comece a comprar mercadorias de forma mais ativa.
- O número de concorrentes diretos em nosso site. Se, por exemplo, esta caneta for a única em sua categoria, as vendas serão bastante estacionárias.
- Dimensões do produto - descobriu-se que o comprimento e a largura afetam significativamente a previsibilidade das vendas. Por alguma razão, para objetos longos e estreitos - guarda-chuvas ou varas de pesca, por exemplo - o cronograma é muito mais volátil. Ainda não sabemos como explicar isso.
- Número do dia do ano - mostra se o Ano Novo está chegando, 8 de março, o início de um aumento sazonal nas vendas, etc.
Amostragem
A amostra de treinamento é dor. Nós o coletamos por cerca de quatro semanas, duas das quais foram apenas para guardiões de dados diferentes e pedimos uma olhada no que eles têm. Isso acontece sempre que você precisar de dados por um longo período. Mesmo em um sistema ideal de coleta de dados, por muito tempo, algo acontecerá no espírito de "costumávamos pensar assim, mas depois começamos a pensar de maneira diferente e a escrever os dados na mesma coluna". Ou há um ou dois anos, o servidor travou, mas ninguém anotou exatamente quando - e os zeros não significam mais que não houve vendas.
Como resultado, tivemos informações sobre o que as pessoas fizeram no site, o que e em que quantidades foram adicionadas aos favoritos e a uma cesta e compradas. Coletamos uma amostra de aproximadamente 15 milhões de amostras de 170 recursos cada, o objetivo era o número de vendas para a próxima semana.
Escrevemos 2 mil linhas de código no Spark. Funcionou devagar, mas permitiu mastigar grandes quantidades de dados. Parece que calcular a inclinação de uma linha reta é simples. E fazê-lo 10kk vezes quando as vendas são puxadas de várias bases - a tarefa não é para os fracos de coração.
Por mais uma semana, estivemos envolvidos na limpeza de dados, para que o modelo não se distraísse com as emissões e os recursos de amostragem local, mas extraímos apenas as verdadeiras dependências inerentes às vendas da Ozon. Aqui estão 3 métodos sigma e mais astutos para procurar anomalias. O caso mais difícil é restaurar as vendas durante períodos de falta de mercadorias em estoque. A solução mais simples é descartar as semanas em que o produto foi lançado durante a semana "segmentada".
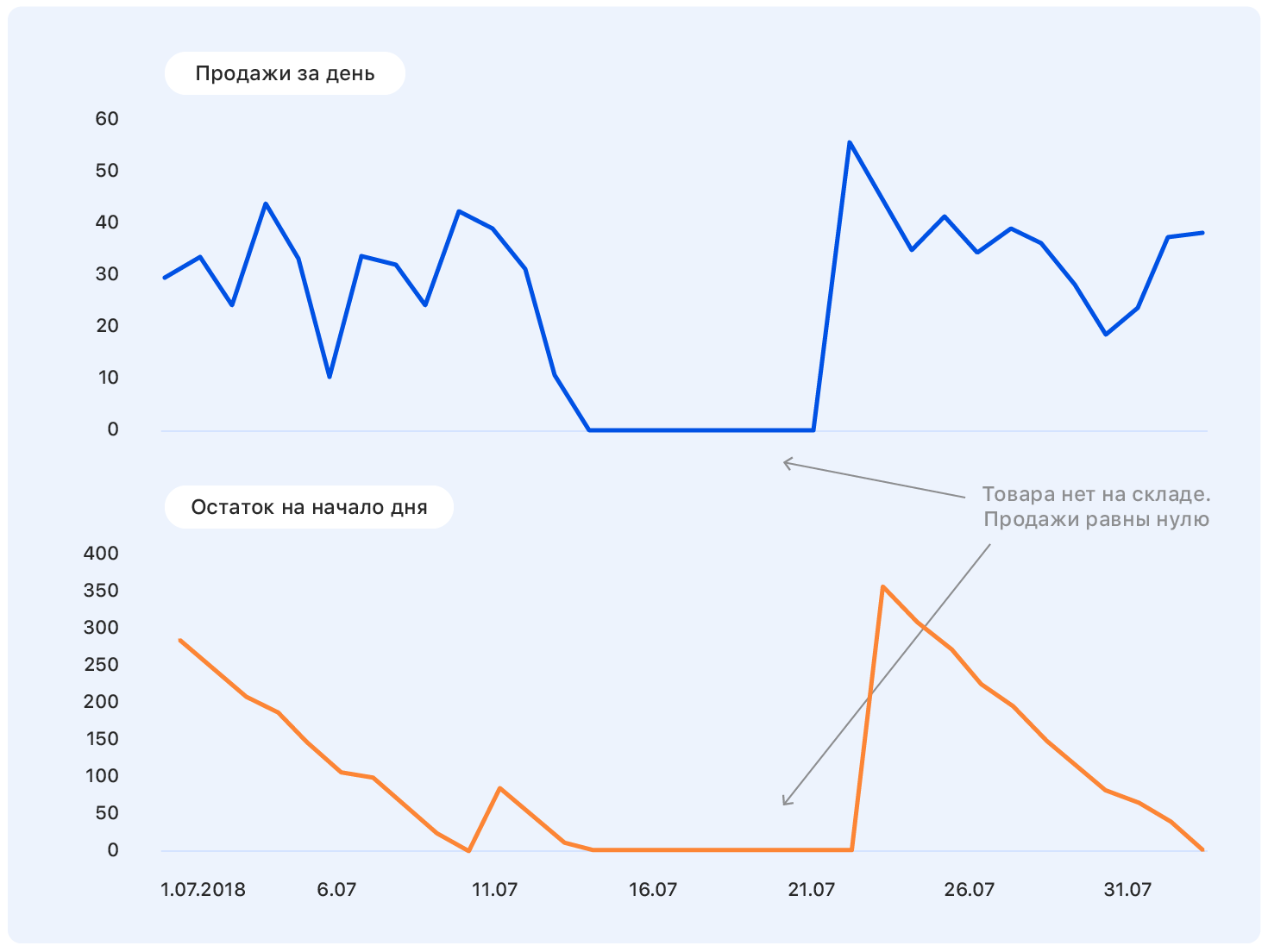
Como resultado, de 15 milhões de amostras, restaram 10 milhões.É importante aqui não se deixar levar e não perder a integridade da amostra (de fato, a falta de mercadorias no armazém é uma característica indireta de sua importância para a empresa; remover esses bens da amostra não é o mesmo que jogar amostras aleatórias )
Tempo ML
Em uma amostra limpa e começou a treinar modelos. Naturalmente, começamos com regressão linear e obtivemos MAE = 1,15. Parece que este é um aumento muito pequeno, mas quando você tem uma amostra de 10 milhões em que os valores médios são de 5 a 10, mesmo uma pequena alteração no valor da métrica fornece um aumento incomensurável na qualidade visual da previsão. E como você eventualmente terá que apresentar a solução para os clientes corporativos, aumentar o nível de alegria é um fator importante.
A seguir, foi apresentado o sklearn.ensemble.RandomForestRegressor, que após uma pequena seleção de hiperparâmetros mostrou MAE = 1,10. Em seguida, tentamos o XGBoost (onde sem ele) - tudo ficaria bem e o MAE = 1,03 - apenas por muito tempo. Infelizmente, não tivemos acesso à GPU para treinar o XGBoost e, nos processadores, um modelo foi treinado por muito tempo. Tentamos encontrar algo mais rápido e adotamos o LightGBM - ele treinou duas vezes mais rápido e mostrou o MAE ainda um pouco menos - 1,01.
Dividimos todos os produtos em 13 categorias, como no catálogo do site: mesas, laptops, garrafas e, para cada categoria, treinamos modelos com diferentes profundidades de previsão - de 5 a 16 dias.
O treinamento levou cerca de cinco dias e, para isso, criamos enormes clusters de computação. Desenvolvemos esse pipeline: a pesquisa aleatória funciona por um longo tempo, fornece os 10 principais conjuntos de hiperparâmetros e, em seguida, o cientista trabalha com eles manualmente - cria métricas adicionais de qualidade (calculamos o MAE para diferentes faixas de objetivos), cria curvas de aprendizado (por exemplo, descartamos parte do treinamento amostras e treinadas novamente, verificando se novos dados reduzem a perda na amostra de teste) e outros gráficos.
Um exemplo de uma análise detalhada para um dos conjuntos de hiperparâmetros:
Métrica de qualidade detalhadaConjunto de trem:
| Conjunto de teste:
|
| Para destino = 0, MAE = 0,142222484602 | Para 0 MAE = 0,141900737761 |
| Para o destino> 0, MAPE = 45.168530676 | Para> 0 MAPE = 45.5771812826 |
| Erros maiores que 0 - 67.931341691% | Erros maiores que 0 - 51.6405939896% |
| Erros maiores que 1 - 19.0346986379% | Erros maiores que 1 - 12.1977096603% |
| Erros mais de 2 - 8.94313926245% | Erros mais de 2 - 5.16977226441% |
| Erros mais de 3 - 5,42406856507% | Erros mais de 3 - 3,12760834969% |
Erros mais de 4 - 3.67938161595%
| Erros mais de 4 - 2.10263125679% |
Erros mais de 5 - 2,67322988948%
| Erros mais de 5 - 1,56473158807%
|
Erros mais de 6 - 2,0618556701%
| Erros mais de 6 - 1.19599209102%
|
| Erros mais de 7 - 1,65887701209% | Erros maiores que 7 - 0,949300173983%
|
Erros mais de 8 - 1,36821095777%
| Erros mais de 8 - 0,77810772461% |
| Erros mais de 9 - 1,15368611519% | Erros maiores que 9 - 0,659205318158%
|
| Erros mais de 10 - 0,99199395014% | Erros mais de 10 - 0,554593106723% |
| Erros mais de 11 - 0,863969667827% | Erros mais de 11 - 0,490045146476%
|
Erros mais de 12 - 0,764347266082%
| Erros mais de 12 - 0,428835873827%
|
| Erros mais de 13 - 0,68086818247% | Erros com mais de 13 - 0,386545830907%
|
| Erros mais de 14 - 0,613446089087% | Erros mais de 14 - 0,343884822697%
|
Erros mais de 15 - 0,556297016335%
| Erros mais de 15 - 0,316433391328%
|
Para destino = 0, MAE = 0,142222484602
| Para destino = 0, MAE = 0,141900737761
|
Para destino = 1, MAE = 0,63978556493
| Para destino = 1, MAE = 0,660823509405 |
| Para destino = 2, MAE = 1,01528075312 | Para destino = 2, MAE = 1,01098070566 |
| Para destino = 3, MAE = 1,43762342295 | Para destino = 3, MAE = 1,44836233499 |
Para destino = 4, MAE = 1,82790678437
| Para destino = 4, MAE = 1,86539223382
|
Para destino = 5, MAE = 2,15369976552
| Para destino = 5, MAE = 2,16017884573 |
Para destino = 6, MAE = 2,51629758129
| Para destino = 6, MAE = 2,51987403661
|
Para destino = 7, MAE = 2,80225497415
| Para destino = 7, MAE = 2,97580015564
|
Para destino = 8, MAE = 3,09405048248
| Para destino = 8, MAE = 3,21914648525
|
Para destino = 9, MAE = 3,39256765159
| Para destino = 9, MAE = 3,54572928241
|
| Para destino = 10, MAE = 3,6640339953 | Para destino = 10, MAE = 3,84409605282
|
Para destino = 11, MAE = 4,02797747118
| Para destino = 11, MAE = 4,21828735273
|
Para destino = 12, MAE = 4,17163467899
| Para destino = 12, MAE = 3,92536509115
|
Para meta = 14, MAE = 4,789090364522
| Para destino = 14, MAE = 5,11290428675 |
Para destino = 15, MAE = 4,89409916994
| Para destino = 15, MAE = 5,20892023117
|
Perda de trem = 0,535842111392
Perda de teste = 0,895529959873
Previsão de gráfico (alvo) para o conjunto de treinamento Previsão de gráfico (alvo) para amostra de teste Erro de previsão de tempos em tempos Classificar erro crescente na amostra de teste Se nenhum deles corresponder, procure aleatoriamente novamente. Foi assim que treinamos o modelo por 5 ou 5 dias no ritmo industrial. Estávamos de serviço, alguém à noite, alguém acordou de manhã, olhou para os 10 principais parâmetros, reiniciou ou salvou o modelo e foi dormir mais. Nesse modo, trabalhamos por uma semana e treinamos 130 modelos - 13 tipos de produtos e 10 profundidades de previsão, cada um com 170 recursos. O MAE médio para a série temporal cv de 5 vezes é igual a 1.
Pode parecer que isso não é muito legal - e é assim, a menos que você tenha uma grande parte na seleção de unidades. Como uma análise dos resultados mostra, as unidades são as piores de todas - o fato de um produto ser comprado uma vez por semana não diz nada sobre se existe demanda por ele. Uma vez que qualquer coisa pode ser vendida - existe uma pessoa que compra uma estatueta de porcelana na forma de um dentista, e isso não diz nada sobre vendas futuras ou sobre vendas passadas. Em geral, não ficamos muito chateados com isso.
Dicas e truques
O que deu errado e como isso pode ser evitado?
O primeiro problema é a seleção de parâmetros. Começamos a usar o RandomizedSearchCV - uma ferramenta conhecida da sklearn para classificar hiperparâmetros. É aqui que a primeira surpresa nos esperava.
Assimfrom sklearn.model_selection import ParameterSampler
from sklearn.model_selection import RandomizedSearchCV
estimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=72)
param_grid = {'boosting_type': boosting_type, 'num_leaves': num_leaves, 'max_depth': max_depth, 'learning_rate':learning_rate, 'n_estimators': n_estimators, 'subsample_for_bin': subsample_for_bin, 'min_child_samples': min_child_samples, 'colsample_bytree': colsample_bytree, 'reg_alpha': reg_alpha, 'max_bin': max_bin}
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=1, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
O cálculo simplesmente pára (o que é importante, não cai, mas continua a funcionar, mas em um número cada vez menor de núcleos e, em algum momento, apenas pára).
Eu tive que paralelizar o processo devido ao RandomizedSearchCVestimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=1)
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=72, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
Mas o RandomizedSearchCV pega quase todo o conjunto de dados para cada "trabalho". Portanto, é necessário expandir bastante a quantidade de RAM, possivelmente sacrificando o número de núcleos.
Quem nos diria então sobre coisas maravilhosas como o hiperopt! Desde que aprendemos, usamos apenas.
Outro truque que ocorreu mais perto do final do projeto foi escolher modelos que tivessem o parâmetro colsample_bytree (este é o parâmetro LightGBM, que indica a porcentagem de recursos a serem oferecidos a cada lener) na região de 0,2-0,3, porque quando o carro Funciona na produção, pode não haver tabelas e os recursos individuais podem não ser contados corretamente. Essa regularização permite garantir que esses recursos não contabilizados afetem pelo menos nem todos os lerners do modelo.
Empiricamente, chegamos à conclusão de que precisamos fazer mais estimadores e distorcer mais a regularização. Esta não é uma regra de trabalho com o LightGBM, mas esse esquema funcionou para nós.
Bem e, claro, Spark. Por exemplo, existe um bug que o próprio Spark conhece: se você pegar várias colunas de uma tabela e criar uma nova, e depois pegar outras da mesma tabela e criar uma nova, e depois sintonizar as tabelas que você recebe, tudo vai quebrar, embora não deva. Você pode ser salvo apenas se livrando de todos os cálculos preguiçosos. Até escrevemos uma função especial - bumb_df, que transforma o Data Frame em um RDD de volta em um Data Frame. Ou seja, redefine todos os cálculos preguiçosos. Isso pode se proteger da maioria dos problemas do Spark.
bumb_dfdef bump_df(df):
# to avoid problem: AnalysisException: resolved attribute(s)
df_rdd = df.rdd
if df_rdd.isEmpty():
df = df_rdd.toDF(schema=df.schema)
return df
else:
return df_rdd.toDF(schema=df.schema)
A previsão está pronta: quanto vamos pedir?
A previsão de vendas é uma tarefa puramente matemática, e se a distribuição normal de um erro com média zero for uma vitória para um matemático, então para comerciantes que têm todos os rublos em sua conta, isso é inaceitável.
Se um iPhone extra ou um vestido da moda no armazém não é um problema, mas um estoque de seguros, a ausência do mesmo iPhone no armazém é uma perda de pelo menos margem e no máximo de imagem, e isso não pode ser permitido.
Para ensinar o algoritmo a comprar o quanto for necessário, tivemos que calcular o custo de recompra e subcompra de cada produto e treinar um modelo simples para minimizar possíveis perdas de dinheiro.
O modelo recebe uma previsão de vendas na entrada, adiciona ruído aleatório e normalmente distribuído (simulamos as imperfeições dos fornecedores) e aprende a adicionar exatamente o mesmo à previsão de cada produto em particular para minimizar as perdas de dinheiro.
Assim, um pedido é uma previsão + estoque de segurança, que garante a cobertura do erro de previsão e da imperfeição do mundo exterior.
Como no prod
O Ozon possui seu próprio cluster de computação bastante grande, no qual todas as noites um pipeline (usamos fluxo de ar) de mais de 15 trabalhos é lançado. É assim:

Todas as noites, o algoritmo é lançado, extrai cerca de 20 GB de dados de várias fontes para hdfs locais, seleciona um fornecedor para cada produto, coleta recursos para cada produto, faz uma previsão de vendas e gera pedidos com base no cronograma de entrega. Às 6-7 da manhã, damos à mesa as pessoas responsáveis por trabalhar com os fornecedores de mesas prontas que voam com um clique de um botão para os fornecedores.
Nem uma única previsão
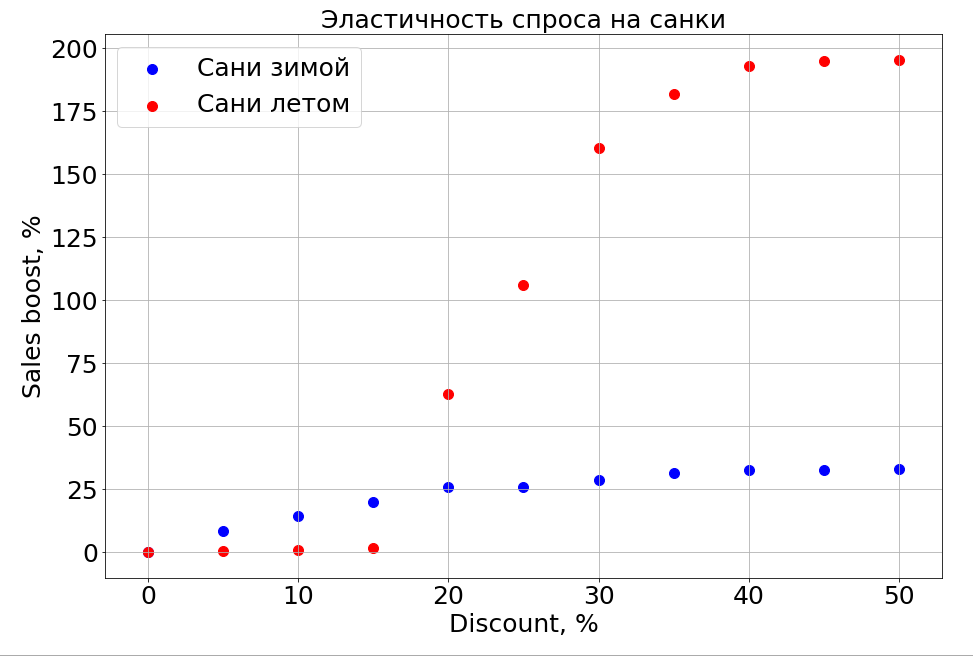
O modelo treinado conhece a dependência da previsão em qualquer recurso e, como resultado, se você congelar os sinais N-1 e começar a mudar um, poderá observar como isso afeta a previsão. Obviamente, o mais interessante é como as vendas dependem do preço.
É importante observar que a demanda depende não apenas do preço. Por exemplo, se você fizer pequenos descontos em trenós no verão, isso ainda não os ajudará a vender. Estamos fazendo mais descontos, e aparecem pessoas que estão "preparando um trenó no verão". Mas até um certo nível de descontos, ainda não conseguimos alcançar a parte do cérebro responsável pelo planejamento. No inverno, funciona como qualquer produto - você faz um desconto e vende mais rapidamente.
Planos
Agora, estamos estudando ativamente o agrupamento de séries temporais para distribuir mercadorias entre os clusters com base na natureza da curva que descreve suas vendas. Por exemplo, sazonal, tradicionalmente popular no verão ou, inversamente, no inverno. Quando aprendemos a separar produtos com um longo histórico de vendas, planejamos destacar os recursos baseados em itens que informarão qual será o padrão de vendas para um novo produto recém-lançado - por enquanto, essa é a nossa principal tarefa.
Redes neurais e modelos paramétricos de séries temporais, e tudo isso no conjunto, certamente serão maiores.
Particularmente, graças ao novo sistema de previsão, a Ozon passou da compra de mercadorias com estoque para entregas cíclicas, quando compramos de um suprimento para outro e não armazenamos saldos em estoque.
Agora temos que decidir como ensinar o algoritmo a prever vendas de novos produtos e categorias inteiras. No próximo ano, a empresa planeja aumentar 10 vezes as vendas nas categorias e 2,5 nas áreas de atendimento. E precisamos dizer aos modelos que esses dados antigos são relevantes, mas para um armazenamento passado diferente. E enquanto estamos pensando em como fazê-lo.
A segunda coisa irracional por natureza que precisamos aprender a prever é a moda. Como alguém poderia prever que um girador venderia assim? Como prever as vendas de novos livros de Dan Brown se um de seus livros estiver esgotado e o outro não? Enquanto estamos trabalhando nisso.
Se você souber fazer melhor ou tiver histórias sobre o uso de aprendizado de máquina em batalha nos comentários, discutiremos isso.