
Era uma vez uma conversa espontânea
na frente de uma loja distante e distante :
NB: - ?
GURU : - «» . . . , ...
NB: - , ?
GURU : - google yandex , . . , .
NB: - ?
GURU : - ?… ...
NB parou de perguntar, aparentemente temendo incomodar um interlocutor claramente mais experiente.
GURU revirou os olhos, como se enfatizasse o esgotamento do tópico de procuração e ficou em silêncio ...
Obviamente, o
GURU sabia que uma consulta de pesquisa (por exemplo, com a palavra: proxy) muito em breve levaria o
NB a obter o endereço desejado: lista de portas. Mas após os primeiros experimentos, o
NB , com a mesma rapidez, entenderá:
- Nem todos os endereços em sua lista estão funcionando;
- Nem todos os proxies são igualmente bons;
- "Aderir" manualmente a um site através de um proxy é uma tarefa que requer uma vontade considerável;
- Um proxy "errado" prejudicará a situação, porque o site pode ser suspeitado por scripts de gigantes.
Neste artigo, falarei sobre como improvisado (e mais importante, universal) significa
(sem usar software proprietário específico, como
ZennoPoster , etc ...)
crie uma ferramenta automatizada para obter uma lista de proxies “realmente adequados” e usá-los para organizar visitas (automatizadas) aos promovidos
site usando o
navegador Chrome .
Seguindo as instruções, você receberá uma ferramenta pronta que permitirá:
- “Clique” - (visite) o site de destino completamente automaticamente, sem medo de comprometer-se;
- emular totalmente o comportamento do usuário;
- organizar todas as visitas de acordo com um cronograma (cenário);
- faça tudo o que precede no número de vezes necessário para avançar.
E embora todo o meu trabalho (junto com a pesquisa) tenha levado uma semana, você não precisará de dois dias para criar essa ferramenta, com conhecimentos básicos da
linha de comando ,
PHP e
JavaScript .
No entanto, antes de rolar abaixo do
diagrama a
seguir , direi algumas palavras sobre por que esse material é preparado e para quem.
O material será útil se você quiser entender como as construções (? Ou construtores?) São organizadas com as quais você pode construir um aplicativo de forma relativamente rápida, fácil e sem custos, adaptável às mudanças de carga. Se você estiver interessado na possibilidade de criar um aplicativo com base em um barramento de serviço (
ESB ).
O texto será útil se você deseja se familiarizar com o uso do
Docker para sistemas de construção
instantânea . Ou se você está interessado apenas no
Selenium Server e nas nuances de recebimento de conteúdo / manifestação da atividade HTTPx.
Para "usar imediatamente", ler cuidadosamente tudo isso não vale a pena. O código é certo.
Vá direto para a configuração da ferramenta pronta. A instalação leva menos de 20 minutos.O manual pressupõe que você tem 2 máquinas à sua disposição com o Ubuntu 18.04 instalado.
Um para a infraestrutura (
janela de encaixe ), o outro para controle de
processo (
processo ).
Supõe-se que os seguintes pacotes já estejam instalados na
janela de
encaixe :
git, docker, docker-compor
Supõe-se que os seguintes pacotes já estejam instalados no
processo :
git, php-common, php-cli, php-curl, php-zip, php-memcached, compositor
Se você tiver alguma dúvida neste momento, sugiro que passe 15 minutos lendo todo o material.
estivador
processo
Aguarde, observando o que está acontecendo no painel da web (http: // ip-address-docker-machines: 8080).
O resultado estará disponível na fila
localizada .
Esmagamento e planejamento
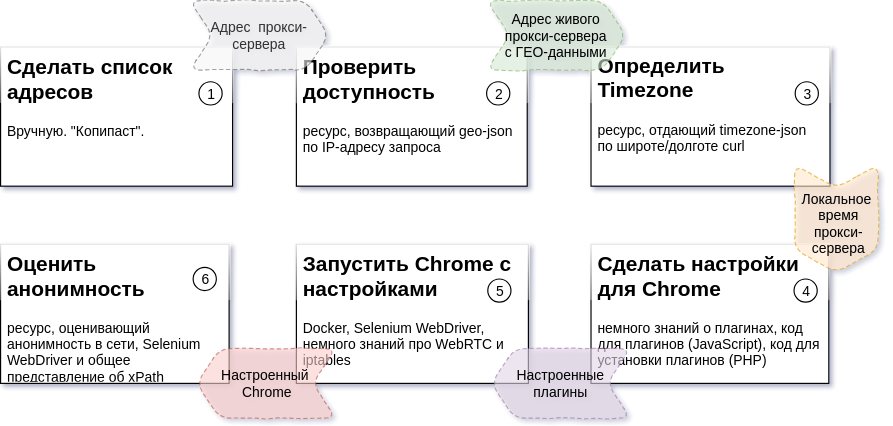
O diagrama acima descreve a sequência das etapas do processo, o resultado esperado para cada etapa e os recursos necessários para criar cada parte (detalhes:
Tarefa 2 ,
Tarefa 3 ,
Tarefa 4,5,6 ).
No meu caso, tudo acontece em duas máquinas
Ubuntu 18.04 . Um deles controla o processo. Por outro lado, vários contêineres de docker de infraestrutura estão em execução.
Desculpas e Falhas
Todo o código do pacote consiste em três partes.
Um deles não é meu (observo que esse é um código bonito e arrumado). A fonte desse código é packagist.org .
Eu mesmo escrevi outro, tentei torná-lo compreensível e dediquei cerca de uma semana a essa parte do código.
O resto é um "difícil legado histórico". Essa parte do código foi criada durante um período bastante longo. Inclusive no momento em que eu não tinha muita habilidade em programação.
Esta é precisamente a razão da localização dos repositórios no meu GitLab e pacotes no meu Satis . Para publicar no GitHub.com e no packagist.org, esse código exigirá processamento e documentação mais completa.
Todas as partes do código estão abertas para uso ilimitado. Repositórios e pacotes estarão disponíveis para sempre.
No entanto, ao republicar o código, serei grato a você por postar um link para mim ou para este artigo.
Um pouco sobre arquitetura
A abordagem usada para criar nossa ferramenta é escrever (ou usar um utilitário pronto) para resolver cada tarefa específica. Além disso, cada utilitário, independentemente da tarefa a ser resolvida, possui duas propriedades comuns a todos:
- o utilitário pode ser iniciado independentemente dos outros na linha de comando com parâmetros contendo a tarefa;
- o utilitário pode retornar o resultado da execução ao stdout (depois de ser configurado de uma certa maneira).
Uma solução feita por esse princípio permite alterar o número de manipuladores de tarefas em execução (trabalhadores) para cada uma das etapas do processo. Um número diferente de trabalhadores para cada etapa levará a um tempo de inatividade "0" para as etapas a seguir devido à duração das tarefas de processamento das etapas anteriores.
O tempo gasto na obtenção de uma unidade do resultado do processo (no nosso caso, é um proxy verificado) depende de fatores externos (o número de proxies inadequados, o tempo de resposta de um recurso externo, etc.).
Alterando o número de trabalhadores para cada uma das etapas do processo, transformamos essa dependência em uma dependência do número de trabalhadores em execução (ou seja, dependendo da capacidade de computação e canal envolvidos).
Para sincronizar a operação de partes independentes individuais, é conveniente usar o servidor da fila de mensagens como um único barramento de dados. Isso permitirá que você acumule os resultados das etapas concluídas na fila e os forneça ao utilitário "próxima etapa" no momento certo como entrada.
Fila de mensagens. MQ e ESB
Como o nível mais baixo (
MQ ), usaremos
beanstalkd . Pequeno, leve, sem configuração, disponível no pacote deb e no contêiner do Docker, um trabalhador discreto. O nível lógico (
ESB ) implementará o código em
PHP .
Duas classes serão usadas para implementação.
esbTask e
nextStepWorker .
esbTask class esbTask // , {
Uma instância dessa classe serve para "endereçar" o
paylod através das etapas do processo. O conceito
ESB aplica vários princípios / padrões. Dois deles merecem atenção separadamente:
- Sobre o caminho (sequência de etapas) do processo, em cada momento do processo,
ninguém sabe, exceto o envelope a ser transmitido;
- Cada envelope tem três direções de resultado possíveis:
- a próxima etapa do processo (continuação normal);
- parada de parada (parada de destino - é selecionada na próxima etapa, se não faz sentido continuar a situação do processo / parada);
- etapa de erro (destino de encerramento de emergência - é selecionado na próxima etapa, no caso de um erro do trabalhador).
O objeto na fila é representado em json, oculto aqui ... nextStepWorkerCada mensagem que aparece na fila é processada pelo trabalhador responsável por ela. Para fazer isso, o seguinte conjunto de funções é implementado:
class nextStepWorker extends workerConstructor {
Trabalhadores para cada uma das etapas do processo são implementados com base nesta classe. Toda a rotina de processamento, endereçamento e envio do próximo passo na rota, a turma cuida.
A solução para cada um dos problemas é:
- Obtenha o esbTask e execute o trabalhador;
- Implemente a lógica armazenando os resultados na carga útil;
- Conclua a execução do trabalhador (de emergência ou normal - não importa).
Se as etapas forem concluídas, o resultado será colocado na fila com o nome apropriado e o próximo trabalhador iniciará o processamento.
Faça isso uma vez. Verificar disponibilidade
De fato, criar um trabalhador para resolver qualquer um dos problemas é a implementação de um método. Um exemplo (simplificado) da implementação de um trabalhador que resolve o
Problema 2 é o seguinte:
Algumas linhas de código e tudo é feito e "destacado" para o próximo estágio.
Defina o fuso horário. TimeZoneDB e para que serve ...
O teste detalhado das solicitações recebidas envolve a correspondência do tempo da janela do navegador com o horário em que o endereço IP de origem da solicitação existe.
Para evitar suspeitas dos contadores, precisamos saber a hora do proxy local.
Para descobrir a hora, tiramos a latitude e a longitude dos resultados da etapa anterior do processo e obtemos dados sobre o fuso horário no qual nossa instância futura da janela do navegador funcionará. Esses dados serão fornecidos a nós por
profissionais da área de tempo .
Um trabalhador simplificado para resolver esse problema (
tarefa 3 ) será completamente semelhante ao
anterior . A única diferença é o URL da solicitação. Você pode encontrar a versão completa no arquivo:
// app / src / Process / worker / timeZone.php
Um pouco sobre infraestrutura
Além do
beanstalkd descrito, nossa ferramenta precisará:
- Memcached - para tarefas de cache;
- Selenium Server - é conveniente executar o Selenium Web Driver em um contêiner separado e você pode monitorar o processo via VNC ;
- Painéis para monitorar o beanstald , o memcached e o VNC .
Para uma rápida implantação de tudo isso, o Docker (
Como instalar no Ubuntu ) é muito conveniente.
E o "orquestrador" para ele é docker-compor (comandos para instalação) ... sudo apt-get -y update sudo apt-get -y install docker-compose
Essas ferramentas permitem que você execute servidores / processos já configurados (por alguém anteriormente) em "contêineres" separados do sistema operacional pai. Para detalhes, recomendo consultar
este ou
este artigo.
Então ...
Para iniciar a infraestrutura, você precisa de vários comandos no console:
Como resultado da execução bem-sucedida do comando na máquina com o endereço XXX.XXX.XXX.XXX,
Você receberá o seguinte conjunto de serviços:
- XXX.XXX.XXX.XXX:11300 - beanstalkd
- XXX.XXX.XXX.XXX:11211 - Memcached
- XXX.XXX.XXX.XXX-00-00444 - Selenium Server
- XXX.XXX.XXX.XXX:5930 - servidor VNC para controlar o que acontece no Chrome
- XXX.XXX.XXX.XXX:8081 - Painel da Web para comunicação com o Memcached (admin: pass)
- XXX.XXX.XXX.XXX:8082 - Painel da Web para comunicação com beanstalkd
- XXX.XXX.XXX.XXX:8083 - Painel da Web para comunicação com o VNC (senha: secreta)
- XXX.XXX.XXX.XXX:8080 - Painel geral da Web
"Veja se tudo está no lugar", "entre no console e o contêiner", "pare a infraestrutura" podem ser comandos no spoiler. Tarefas 4,5,6 - combine em um utilitário
Depois de analisar detalhadamente as tarefas (
diagrama acima ), é fácil garantir que apenas uma das tarefas restantes (
tarefa 6 ) dependa de um recurso externo. Ao executar tarefas com tempos de execução "garantidos condicionalmente" (independentemente de fatores não controlados), não obteremos vantagens adicionais à velocidade de todo o processo. Nesse sentido, essas tarefas (
4,5,6 ) foram combinadas em um trabalhador. O arquivo de trabalho é chamado:
// app / src / Process / worker / whoerChecker.php
Faça as configurações para o Chrome. Plugins
O Chrome é configurado de forma flexível com plug-ins.
Um plug-in para o
Chrome é um arquivo que contém um arquivo
manifest.json . Ele descreve o plugin. O arquivo também contém um conjunto de
JavaScript, html, css e outros arquivos necessários ao plugin (
detalhes ).
No nosso caso, um dos arquivos
JavaScript será executado no contexto da janela de trabalho do
Chrome e todas as configurações necessárias entrarão em vigor.
Nós apenas precisamos pegar o modelo de plug-in e substituir os dados necessários (protocolo de interação, endereço e porta ou fuso horário) pelo servidor proxy em teste nos lugares certos.
Um trecho de código que cria o arquivo morto:
O modelo para o plug-in de ajuste de proxy foi encontrado
no cofrinho dos resultados do trabalho de pessoas que amam sua profissão , alterado na parte do protocolo e adicionado ao repositório.
Mudança na hora da janela
Para alterar o horário global de uma instância do Chrome em execução, precisamos substituir
window.Date por uma classe com funcionalidade semelhante, mas válida no fuso horário correto.
Eu realmente aprecio
o trabalho de Sampo Juustila . O script foi feito para teste automatizado da
interface do
usuário , mas após um pequeno refinamento.
Há uma nuance aqui que quero chamar sua atenção. Está associado ao contexto dos scripts descritos em
manifest.json .
O segredo é que o contexto global (aquele em que o script principal do plug-in é iniciado e as configurações definidas, por exemplo, conectadas à rede) é isolado do contexto da guia na qual a página é carregada.
Empiricamente, verificou-se que o impacto no protótipo da classe no contexto global não levou à sua alteração na guia. No entanto, após registrar o script na página já carregada e executá-lo antes das outras, o problema foi resolvido.
A solução é representada pelo seguinte fragmento de código:
Configurações de proxy
A configuração de um proxy no Chrome é tão simples que ocultarei o código js em um spoiler Caminho dos plug-ins do Chrome
Todos os plugins são nomeados de acordo com o esquema e são adicionados à pasta temporária da máquina que controla o processo.// esquema de nomenclatura para o plugin proxy:
proxy- [endereço] - [porta] - [protocolo]>. zip
time shift - ["-" | ""] - [shift_in_minutes_from_GMT] .zip
Em seguida, precisamos instalar esses plug-ins em um contêiner de docker que esteja sendo executado na máquina responsável pela infraestrutura.
Faremos isso com o ssh.
Para fazer isso, eu conheci o phpseclib (ainda mais tarde me arrependi). Fascinado com o comportamento incomum da biblioteca, passei um dia estudando-o.O cliente do console ssh funcionará melhor aqui e funcionará mais rápido, mas o trabalho já foi feito.Para o nível baixo (trabalhe com SFTP e SSH), a classe base é responsável (abaixo). Substituir esta classe substituirá o phpseclib pelo cliente do console.
Derivado do sshDocker base e da classe proxyHelper já conhecida, ele não apenas produz plugins, mas também os coloca em uma pasta temporária do contêiner de infraestrutura.
Inicie o Chome com configurações
O Selenium Server nos ajudará a lançar o Chrome personalizado . O Selenium Server é uma estrutura criada pela equipe do FaceBook especificamente para testar interfaces WEB. O trabalho de estrutura permite ao desenvolvedor emular programaticamente qualquer ação do usuário em uma janela do navegador (usando o Chrome ou o Firefox ). O Selenium Server é adaptado para uso em vários idiomas e é de fato uma ferramenta padrão para escrever scripts de teste. A melhor maneira de obter uma nova versão para uso em um projeto: composer require facebook/webdriver
A configuração tradicional da instância principal do objeto Selenium Server (RemoteWebDriver) parecia detalhada para mim. E, portanto, reduzi levemente tudo isso, otimizando a configuração para minhas necessidades:
O olho imediatamente se apega a plugins $. $ plugins é uma estrutura de dados responsável pela configuração de plugins. Para cada diretório e para substituir espaços reservados nos arquivos JavaScript do plug-in.A estrutura é descrita no arquivo app / plugs.php e faz parte das opções globais app / settings.php. A análise de uma página com o Selenium WebDriver é muito simples. .... $url = 'https://__/_-_'; $page = $chrome->get($url); ....
Como já escrevi, todas essas ações são implementadas pelo utilitário da terceira etapa ( Tarefa 4,5,6 ):// app / src / Process / worker / whoerChecker.php
Concluindo a descrição do trabalho com o Selenium Server , quero chamar a atenção para o fato de que, ao usar esta tecnologia em escala industrial (1000 - 3000 páginas), não é incomum que uma sessão com o Selenium Server termine incorretamente. A janela não tem dono. E essas janelas podem se acumular muito.Várias maneiras de combater os "broches" foram consideradas. Trabalho "comeu" 2 dias. O mais eficaz foi o cron . A instalação e a configuração corretas no contêiner do Docker se transformaram em uma tarefa separada, descrita de forma cuidadosa e minuciosa por renskiy , em um artigo dedicado apenas a ESTE TÓPICO (o que me surpreendeu).A reconstrução automática da imagem original do Docker e a instalação de vários scripts para fechar broches e limpar plug-ins não utilizados é descrita em docker-compose.yml, o repositório de infraestrutura . A frequência de limpeza é definida no arquivo killcron do mesmo repositório.WebRTC
Apesar de já termos definido a hora correta e o tráfego do nosso navegador passar por um proxy, ainda podemos ser detectados.Além da diferença de horário (navegador e endereço IP), existem mais duas fontes de desanonimização de "sentado atrás de um proxy". Estas são as tecnologias flash e WebRTC incorporadas no navegador. O Flash está desativado em nosso navegador , o WebRTC não.A razão para ambas as possibilidades de falha é a mesma - os pacotes UDP onipresentes e ágeis . Para o WebRTC, essas são duas portas: 3478 e 19302 .Para interromper o êxodo de batedores do contêiner chrome, a regra iptables é aplicada na máquina host com os contêineres de infraestrutura: iptables -t raw -I PREROUTING -p udp -m multiport --dports 3478,19302 -j DROP
O mesmo proxyHelper implementa esta tarefa.O resto dos trabalhadores
Para alcançar com sucesso o objetivo - a implementação de um "clique" no site de destino por meio de um proxy anônimo, precisamos de mais um trabalhador.Será uma versão truncada do whoerChecker . Eu acho que fazer isso sozinho, usando tudo o que está escrito, não será difícil.O resultado de todo o processo, caindo na fila localizada , contém dados sobre o “grau” de anonimato de cada endereço de servidor proxy que foi verificado.Ao "jogar" contra os balcões, o principal é lembrar o anonimato e não se deixar levar pelas visitas robóticas. A conformidade com o princípio de "não se deixe levar pelos cliques" é garantida pela possibilidade de organizar ações em um horário, incorporado no esbTask ( desde o campo de nosso envelope ESB ).Se você tentar fazer tudo com cuidado, a métrica yandex do site de destino será semelhante à figura abaixo.
Como juntar tudo
Então, dado:- utilitários capazes de aceitar "como entrada" (como argumento da linha de comando) esbTask no formato json-string e executar alguma lógica e enviar os resultados para beanstalkd ;
- Enfileiramento de Mensagens ( MQ ), com base no beanstalkd ;
- Máquina Linux (máquina de processo);
Com esse "dado", geralmente eu uso o libevent e o React PHP . Tudo isso, complementado por várias ferramentas, permite controlar o número (dentro dos limites especificados) de instâncias de manipulador para cada estágio do processo automaticamente.No entanto, dado o tamanho do artigo e as especificidades do tópico, terei prazer em descrever tudo isso em um artigo separado. Este artigo é uma tecnologia noserver . O material futuro é " servidor ".A data de sua publicação está relacionada ao seu interesse, caro leitor.. , ,… . , , , , , .
habr , . , , .
. , " server ", README.md .
Em " noserver ", uma instância processará uma fila (uma etapa do processo). Essa abordagem só pode irritar os espíritos que uso ao depurar trabalhadores.Dependendo da velocidade de processamento necessária, você pode iniciar quantas cópias desejar manualmente.Pode ser assim:
O começo estranho do trabalhador é impressionante ... Apesar de cada um dos trabalhadores ser um objeto PHP, usei exec (...) .Isso foi feito para economizar tempo, para não criar trabalhadores separados para " noserver " ou não alterar o trabalhador com o objetivo de iniciar no modo " servidor ".Algumas palavras sobre configuração e implantação
Constantes de configuração
O arquivo de configuração para sua instância é app / settings.php . Ele deve ser criado por você imediatamente após a clonagem do repositório. Para fazer isso, renomeie o arquivo app / settings.php.dist . Todas as constantes são descritas internamente.app / settings.php , entre outras coisas, inclui arquivos com outras constantes.- app / queues.php contém os nomes de filas e trabalhos
- app / plugs.php contém uma descrição dos plugins do Chrome
- app / techs.php contém constantes calculadas
Utilitários
Para a conveniência de processar os resultados do processo e colocar tarefas, existem vários utilitários. Os utilitários são iniciados na linha de comando. Fornecido com descrições de argumento. Localizado: app / src / Utils . backup.php - salva filas em um arquivo
clear.php - limpa filas
exporter.php - exporta de um arquivo com uma fila salva
pares endereço: porta
givethejob.php - envia tarefas para o processo
(fonte - endereço: porta caixa de combinação).
pode excluir alguns endereços da lista
restore.php - restaura uma fila salva
Ajustando os trabalhadores
Ao usar trabalhadores gravados, pode ser conveniente usar as seguintes opções de configuração:
Implantação
O manual pressupõe que você tem 2 máquinas à sua disposição com o Ubuntu 18.04 instalado .Um para a infraestrutura ( janela de encaixe ), o outro para controle de processo ( processo ).estivador
processo
Aguarde, observando o que está acontecendo no painel da web (http: // ip-address-docker-machines: 8080).O resultado estará disponível na fila localizada .E em conclusão
Surpreendentemente, escrever e editar este artigo levou mais tempo do que escrever o próprio código.Na minha opinião, tudo poderia ser o contrário (e a diferença de horário pode ser várias vezes maior), se não fosse por duas ideologias: fila de mensagens e barramento de serviço corporativo .Ficarei muito feliz se você achar útil a abordagem apresentada para escrever aplicativos, cuja carga em diferentes partes não é clara na fase de design.Obrigada