Entrada
Como parte do programa de empréstimos, o banco coopera com muitas lojas de varejo.
Um dos elementos principais de um pedido de empréstimo é uma fotografia do mutuário - um agente da loja parceira fotografa o comprador; essa fotografia cai no “arquivo pessoal” do cliente e é usada no futuro como uma das maneiras de confirmar sua presença no momento da solicitação de um empréstimo.
Infelizmente, sempre existe o risco de comportamento desonesto de um agente que pode transferir fotos imprecisas para o banco - por exemplo, fotos de clientes de redes sociais ou passaportes.
Normalmente, os bancos resolvem esse problema verificando se os funcionários do escritório de fotografia veem as fotos e tentam identificar imagens imprecisas.
Queríamos tentar automatizar o processo e resolver o problema usando redes neurais.
Formalização de tarefas
Examinamos apenas fotografias nas quais existem pessoas. As imagens sem rosto podem ser
cortadas usando a biblioteca
Dlib aberta.
Para maior clareza, damos exemplos de fotografias (os funcionários do banco são retratados):
 Fig 1. Fotos do ponto de venda
Fig 1. Fotos do ponto de venda Fig 2. Fotos de redes sociais
Fig 2. Fotos de redes sociais Fig 3. Foto do passaporte
Fig 3. Foto do passaporteEntão, precisamos escrever um modelo analisando o fundo da fotografia. O resultado de seu trabalho foi determinar a probabilidade de a foto ser tirada em um dos pontos de venda de nossos parceiros. Identificamos três maneiras de solucionar esse problema: segmentação, comparação com outras fotos no mesmo ponto de venda, classificação. Vamos considerar cada um deles com mais detalhes.
A) Segmentação
A primeira coisa que veio à mente foi resolver esse problema, segmentando a imagem, identificando áreas com o histórico de lojas parceiras.
Contras:
- A preparação da amostra de treinamento leva muito tempo.
- Um serviço criado nesse modelo não funcionará rapidamente.
Decidiu-se retornar a esse método apenas em caso de abandono de opções alternativas. Spoiler: não retornou.
B) Comparação com outras fotos no mesmo ponto de venda
Juntamente com a foto, recebemos informações sobre em que loja de varejo específica ela foi criada. Ou seja, temos grupos de fotos tiradas nos mesmos pontos de venda. O número total de fotos em cada grupo varia de algumas unidades a vários milhares.
Outra idéia surgiu: construir um modelo que compare duas fotografias e preveja a probabilidade de serem tiradas em um ponto de venda. Em seguida, podemos comparar a foto recém-recebida com as fotos existentes na mesma loja. Se for semelhante a eles, então a imagem é definitivamente confiável. Se a imagem for nocauteada, também a enviaremos para verificação manual.
Contras:
- Amostragem desequilibrada.
- O serviço funcionará por muito tempo se houver muitas fotos no ponto de venda.
- Quando um novo ponto de venda aparecer, você precisará treinar novamente o modelo.
Apesar das desvantagens, implementamos o modelo do
artigo usando os blocos das redes neurais VGG-16 e ResNet-50. E ... eles receberam uma porcentagem de respostas corretas não muito superiores a 50% nos dois casos :(
B) Classificação!
A idéia mais tentadora foi criar um classificador simples que dividisse as fotos em três grupos: fotos de pontos de venda, passaportes e redes sociais. Resta apenas verificar se essa abordagem funciona. Bem, também gaste algum tempo preparando os dados para o treinamento.
Preparação de dados
No conjunto de dados de imagens de redes sociais que usam a biblioteca Dlib, foram selecionadas apenas as fotos que possuem pessoas.
As fotografias de passaporte tiveram que ser cortadas de maneira diferente, deixando apenas o rosto. Aqui, novamente, Dlib veio em socorro. O princípio do trabalho resultou assim: usando a biblioteca encontrou as coordenadas do rosto -> cortou a foto do passaporte, deixando o rosto.
Em cada uma das três classes, deixou 40.000 fotos. Não se esqueça do
aumento de dadosModelo
ResNet-50 usado. Eles resolveram o problema como um problema de classificação de várias classes com classes desunidas. Ou seja, acreditava-se que uma foto pode pertencer a apenas uma classe.
model = keras.applications.resnet50.ResNet50() model.layers.pop() for layer in model.layers: layer.trainable=True last = model.layers[-1].output x = Dense(3, activation="softmax")(last) resnet50_1 = Model(model.input, x) resnet50_1.compile(optimizer=Adam(lr=0.00001), loss='categorical_crossentropy', metrics=[ 'accuracy'])
Resultados
Na amostra de teste, 24.000 fotos foram deixadas, ou seja, 20%. A matriz de erros foi a seguinte:
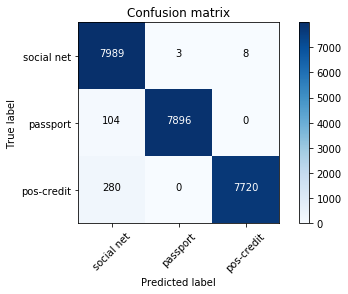
rede social - redes sociais;
passaporte - passaportes;
pos-credit - pontos de venda, parceiros que concedem empréstimos.
A porcentagem total de erros é de 1,6%, para fotos nos pontos de venda - 1,2%. A maioria das imagens definidas erroneamente são semelhantes a duas classes ao mesmo tempo. Por exemplo, quase todas as fotos definidas incorretamente da classe pós-crédito foram tiradas de ângulos sem êxito (contra a parede branca, apenas o rosto é visível). Portanto, eles também eram semelhantes às fotos da classe da rede social. Tais fotografias tinham uma probabilidade máxima baixa.
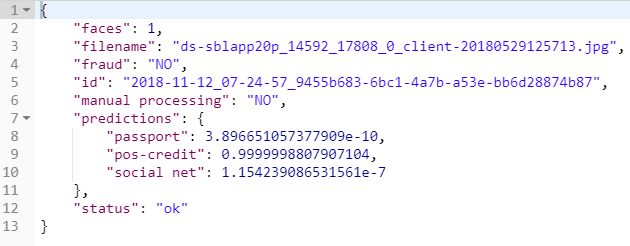
Adicionamos um limite para a probabilidade máxima. Se o valor final for maior - confiamos no classificador, menor - enviamos a imagem para verificação manual.
Como resultado, o resultado do serviço de fotografia

é assim:
Sumário
Assim, usando um modelo simples, aprendemos a determinar automaticamente que uma fotografia foi tirada em um dos pontos de venda de nossos parceiros. Isso nos permitiu automatizar parte do grande processo de aprovação de um pedido de empréstimo.