O GitHub usa o MySQL como seu data warehouse principal para tudo que não está relacionado ao git , portanto, a disponibilidade do MySQL é essencial para a operação normal do GitHub. O site em si, a API do GitHub, o sistema de autenticação e muitos outros recursos requerem acesso aos bancos de dados. Usamos vários clusters do MySQL para lidar com vários serviços e tarefas. Eles são configurados de acordo com o esquema clássico, com um nó principal disponível para gravação e suas réplicas. As réplicas (outros nós do cluster) reproduzem assincronamente as alterações no nó principal e fornecem acesso de leitura.
A disponibilidade de sites host é crítica. Sem o nó principal, o cluster não suporta a gravação, o que significa que você não pode salvar as alterações necessárias. Corrigir transações, registrar problemas, criar novos usuários, repositórios, revisões e muito mais será simplesmente impossível.
Para suportar a gravação, é necessário um nó acessível correspondente - o nó principal no cluster. No entanto, a capacidade de identificar ou detectar esse nó é igualmente importante.
Em caso de falha do nó principal atual, é importante garantir a aparência imediata de um novo servidor para substituí-lo, além de poder notificar rapidamente todos os serviços sobre essa alteração. O tempo de inatividade total consiste no tempo gasto para detectar uma falha, executar failover e notificar sobre um novo nó principal.

Esta publicação descreve uma solução para garantir a alta disponibilidade do MySQL no GitHub e descobrir o serviço principal, o que nos permite executar operações de maneira confiável que abrangem vários data centers, manter a operacionalidade quando alguns desses centros não estiverem disponíveis e garantir tempo de inatividade mínimo em caso de falha.
Objetivos de alta disponibilidade
A solução descrita neste artigo é uma versão nova e aprimorada das soluções anteriores de alta disponibilidade (HA) implementadas no GitHub. À medida que crescemos, precisamos adaptar a estratégia de alta disponibilidade do MySQL para mudar. Nós nos esforçamos para seguir abordagens semelhantes para o MySQL e outros serviços no GitHub.
Para encontrar a solução certa para alta disponibilidade e descoberta de serviços, você deve primeiro responder a algumas perguntas específicas. Aqui está uma lista de amostra deles:
- Qual tempo de inatividade máximo não é crítico para você?
- Quão confiáveis são as ferramentas de detecção de falhas? Os falsos positivos (processamento prematuro de falhas) são críticos para você?
- Quão confiável é o sistema de failover? Onde pode ocorrer uma falha?
- Qual a eficácia da solução em vários data centers? Qual a eficácia da solução em redes de baixa e alta latência?
- A solução continuará funcionando no caso de uma falha completa do datacenter (DPC) ou isolamento da rede?
- Que mecanismo (se houver) evita ou mitiga as conseqüências do surgimento de dois servidores principais no cluster que registram independentemente?
- A perda de dados é crítica para você? Em caso afirmativo, até que ponto?
Para demonstrar, vamos primeiro considerar a solução anterior e discutir por que decidimos abandoná-la.
Recusa em usar VIP e DNS para descoberta
Como parte da solução anterior, usamos:
- orquestrador para detecção de falhas e failover;
- VIP e DNS para descoberta de host.
Nesse caso, os clientes descobriram um nó de gravação por seu nome, por exemplo, mysql-writer-1.github.net . O nome foi usado para determinar o endereço IP virtual (VIP) do nó principal.
Assim, em uma situação normal, os clientes simplesmente precisavam resolver o nome e se conectar ao endereço IP recebido, onde o nó principal já estava esperando por eles.
Considere a seguinte topologia de replicação que abrange três datacenters diferentes:
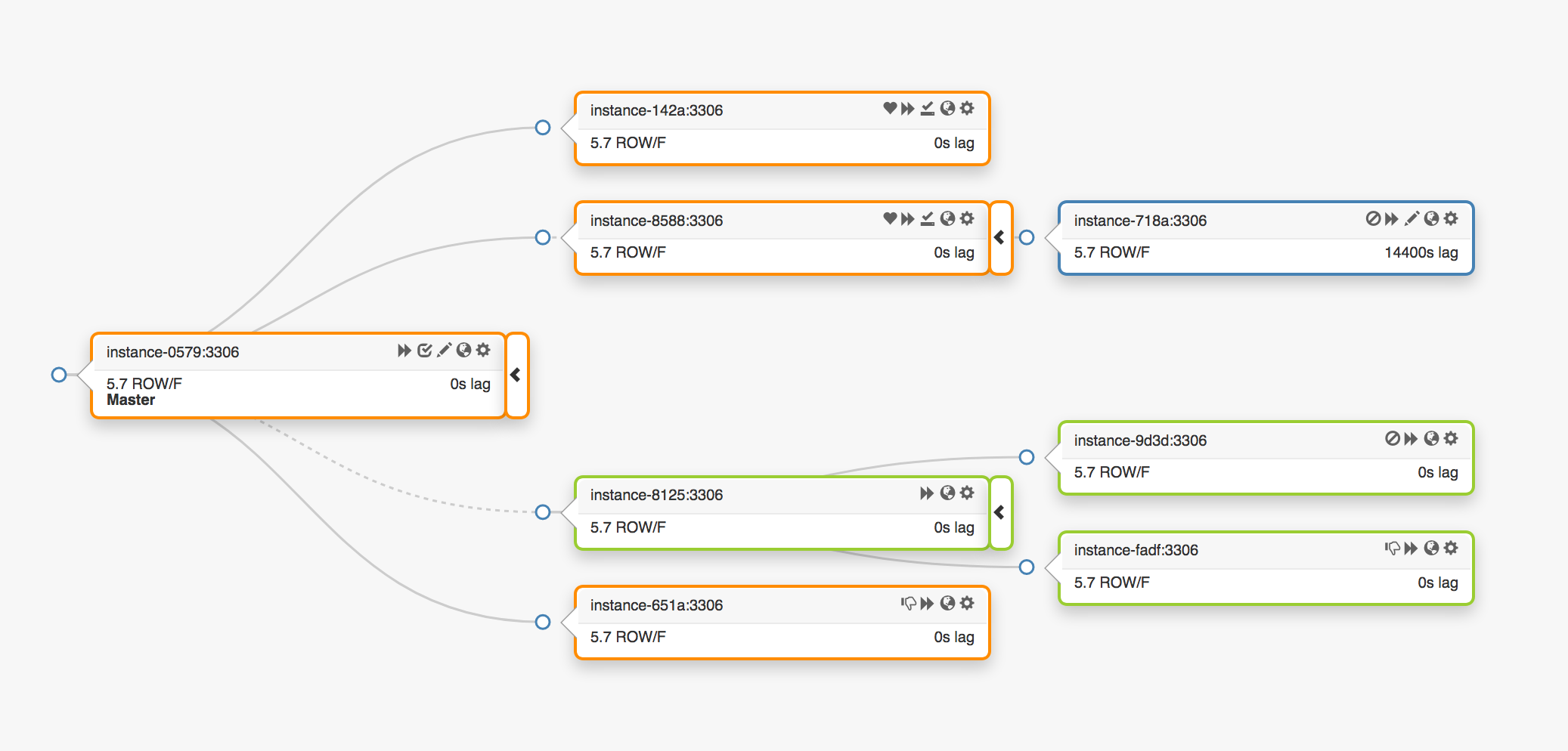
No caso de uma falha do nó principal, um novo servidor deve ser designado ao seu local (uma das réplicas).
orchestrator detecta uma falha, seleciona um novo nó principal e depois atribui o nome / VIP. Na verdade, os clientes não sabem a identidade do nó principal, eles apenas conhecem o nome, que agora deve apontar para o novo nó. No entanto, preste atenção nisso.
Os endereços VIP são compartilhados, os próprios servidores de banco de dados solicitam e os possuem. Para receber ou liberar um VIP, o servidor deve enviar uma solicitação ARP. O servidor que possui o VIP deve primeiro liberá-lo antes que o novo mestre possa acessar esse endereço. Essa abordagem leva a algumas consequências indesejáveis:
- No modo normal, o sistema de failover entrará em contato primeiro com o nó principal com falha e solicitará a liberação do VIP e, em seguida, passará para o novo servidor principal com uma solicitação de atribuição VIP. Mas o que fazer se o primeiro nó principal estiver indisponível ou recusar uma solicitação para liberar o endereço VIP? Dado que o servidor está atualmente em um estado de falha, é improvável que ele possa responder a uma solicitação a tempo ou responder a ela de alguma forma.
- Como resultado, uma situação pode surgir quando dois hosts reivindicam seus direitos ao mesmo VIP. Clientes diferentes podem se conectar a qualquer um desses servidores, dependendo do caminho mais curto da rede.
- A operação correta nessa situação depende da interação de dois servidores independentes e essa configuração não é confiável.
- Mesmo que o primeiro nó principal responda às solicitações, perdemos um tempo valioso: a mudança para o novo servidor principal não ocorre enquanto entramos em contato com o antigo.
- Além disso, mesmo no caso de reatribuição de VIPs, não há garantia de que as conexões de clientes existentes no servidor antigo sejam desconectadas. Novamente, corremos o risco de estar em uma situação com dois nós principais independentes.
Aqui e ali, em nosso ambiente, os endereços VIP são associados a um local físico. Eles são atribuídos a um switch ou roteador. Portanto, podemos reatribuir um endereço VIP apenas para um servidor localizado no mesmo ambiente que o host original. Em particular, em alguns casos, não poderemos atribuir um servidor VIP em outro datacenter e precisaremos fazer alterações no DNS.
- A distribuição de alterações no DNS leva mais tempo. Os clientes armazenam nomes DNS por um período predefinido. O failover envolvendo vários data centers acarreta maior tempo de inatividade, pois leva mais tempo para fornecer a todos os clientes informações sobre o novo nó principal.
Essas restrições foram suficientes para nos forçar a começar a busca por uma nova solução, mas também tivemos que levar em consideração o seguinte:
- Os nós principais transmitiram independentemente os pacotes de pulsos através do
pt-heartbeat para medir o atraso e a regulação de carga . O serviço teve que ser transferido para o nó principal recém-nomeado. Se possível, ele deveria ter sido desativado no servidor antigo. - Da mesma forma, os principais nós controlavam independentemente a operação do Pseudo-GTID . Foi necessário iniciar esse processo no novo nó principal e, de preferência, parar no antigo.
- O novo nó principal tornou-se gravável. O nó antigo (se possível) deve ter
read_only (somente leitura).
Essas etapas adicionais levaram a um aumento no tempo de inatividade geral e adicionaram seus próprios pontos de falha e problemas.
A solução funcionou e o GitHub tratou com êxito as falhas do MySQL em segundo plano, mas queríamos melhorar nossa abordagem ao HA da seguinte forma:
- garantir independência de data centers específicos;
- garantir a operacionalidade em caso de falhas no data center;
- Abandonar fluxos de trabalho colaborativos não confiáveis
- reduzir o tempo de inatividade total;
- Execute, na medida do possível, failover sem perda.
Solução GitHub HA: orquestrador, cônsul, GLB
Nossa nova estratégia, juntamente com as melhorias anexas, elimina a maioria dos problemas mencionados acima ou atenua suas conseqüências. Nosso sistema atual de alta disponibilidade consiste nos seguintes elementos:
- orquestrador para detecção de falhas e failover. Usamos o esquema orquestrador / jangada com vários data centers, como mostra a figura abaixo;
- Cônsul Hashicorp para descoberta de serviços;
- GLB / HAProxy como uma camada de proxy entre clientes e nós de gravação. O código fonte do GLB Director está aberto;
- tecnologia
anycast para roteamento de rede.
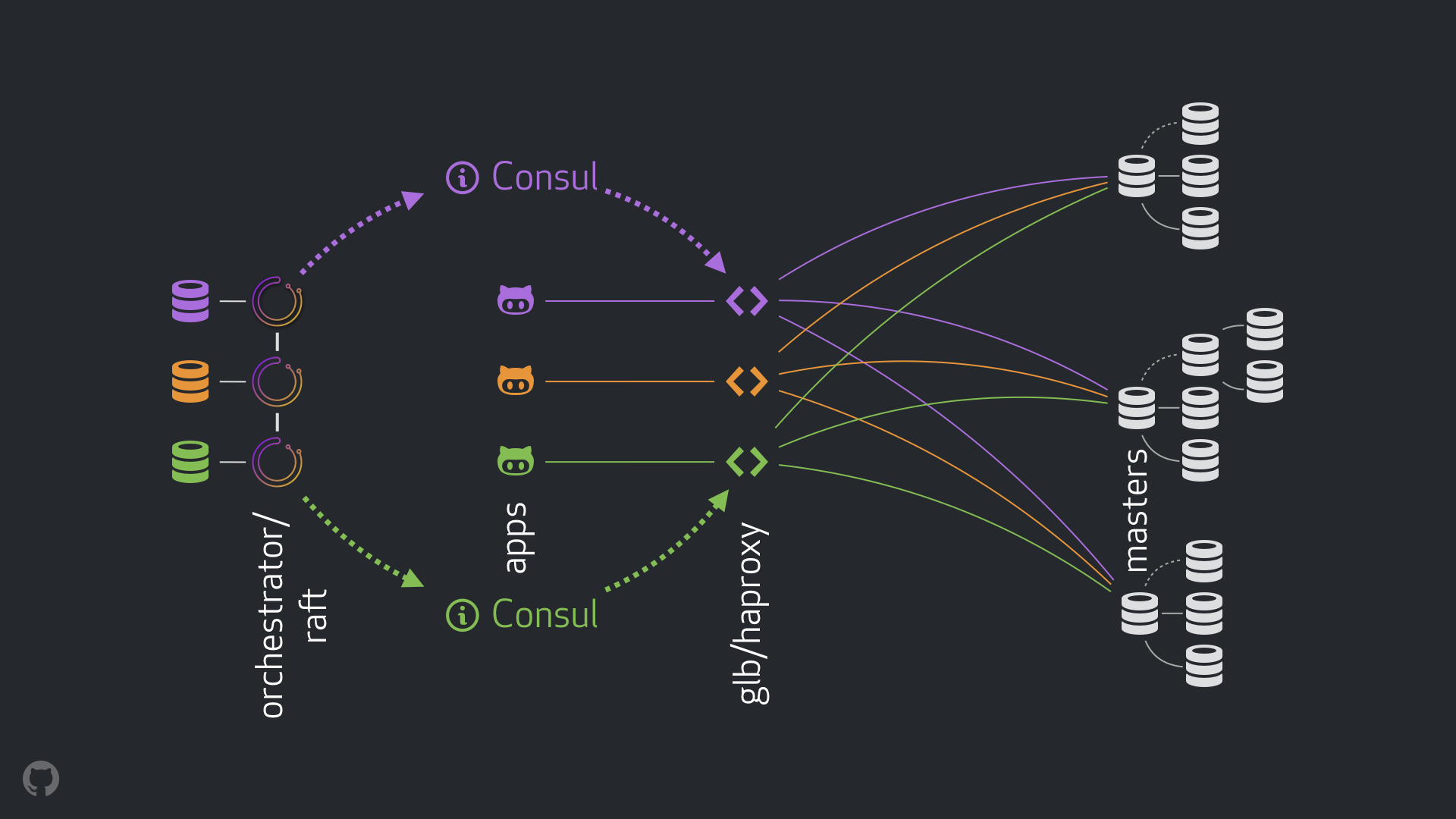
O novo esquema permitiu abandonar completamente as alterações no VIP e no DNS. Agora, ao introduzir novos componentes, podemos separá-los e simplificar a tarefa. Além disso, tivemos a oportunidade de usar soluções confiáveis e estáveis. Uma análise detalhada da nova solução é fornecida abaixo.
Fluxo normal
Em uma situação normal, os aplicativos se conectam aos nós de gravação via GLB / HAProxy.
Os aplicativos não recebem a identidade do servidor principal. Como antes, eles usam apenas o nome. Por exemplo, o nó principal do cluster1 seria mysql-writer-1.github.net . No entanto, em nossa configuração atual, esse nome é resolvido para o endereço IP do anycast .
Graças à tecnologia anycast , o nome é resolvido para o mesmo endereço IP em qualquer lugar, mas o tráfego é direcionado de maneira diferente, dada a localização do cliente. Em particular, várias instâncias do GLB, nosso balanceador de carga altamente disponível, são implantadas em cada um de nossos data centers. O tráfego no mysql-writer-1.github.net sempre roteado para o cluster GLB do data center local. Por esse motivo, todos os clientes são atendidos por proxies locais.
Executamos o GLB em cima do HAProxy . Nosso servidor HAProxy fornece pools de gravação : um para cada cluster do MySQL. Além disso, cada pool possui apenas um servidor (o nó principal do cluster). Todas as instâncias GLB / HAProxy em todos os datacenters têm os mesmos conjuntos e todas apontam para os mesmos servidores nesses conjuntos. Portanto, se o aplicativo deseja gravar dados no banco de dados no mysql-writer-1.github.net , não importa em qual servidor GLB ele se conecta. Em qualquer um dos casos, um redirecionamento para o nó principal do cluster principal cluster1 será executado.
Para aplicativos, a descoberta termina no GLB e a nova descoberta não é necessária. Esse GLB redireciona o tráfego para o lugar certo.
Onde o GLB obtém informações sobre quais servidores listar? Como fazemos alterações no GLB?
Descoberta através do Consul
O serviço Consul é amplamente conhecido como uma solução de descoberta de serviço e também assume funções de DNS. No entanto, no nosso caso, nós o usamos como um armazenamento altamente acessível de valores-chave (KV).
No repositório KV no Consul, registramos a identidade dos principais nós do cluster. Para cada cluster, há um conjunto de registros KV apontando para os dados do nó principal correspondente: seus endereços fqdn , port, ipv4 e ipv6.
Cada nó GLB / HAProxy inicia um consul-template , um serviço que rastreia alterações nos dados do Consul (no nosso caso, alterações nos dados dos nós principais). O consul-template cria um arquivo de configuração e pode recarregar o HAProxy ao alterar as configurações.
Por esse motivo, informações sobre como alterar a identidade do nó principal no Consul estão disponíveis para cada instância GLB / HAProxy. Com base nessas informações, a configuração das instâncias é realizada, os novos nós principais são indicados como a única entidade no pool de servidores de cluster. Depois disso, as instâncias são recarregadas para que as alterações entrem em vigor.
Implantamos instâncias do Consul em cada data center e cada instância fornece alta disponibilidade. No entanto, essas instâncias são independentes uma da outra. Eles não são replicados e não trocam dados.
Onde a Consul obtém informações sobre alterações e como elas são distribuídas entre os data centers?
orquestrador / de jangada
Usamos o esquema orchestrator/raft : os nós do orchestrator comunicam através do consenso da jangada . Em cada data center, temos um ou dois nós do orchestrator .
orchestrator é responsável por detectar falhas, failover do MySQL e transferir os dados alterados do nó principal para o Consul. O failover é gerenciado por um único host de orchestrator/raft , mas as alterações , notícias de que o cluster agora é um novo mestre, são propagadas para todos os nós do orchestrator usando o mecanismo de raft .
Quando os nós do orchestrator recebem notícias sobre uma alteração nos dados do nó principal, cada um deles entra em contato com sua própria instância local do Consul e inicia uma gravação KV. Os data centers com várias instâncias do orchestrator receberão vários registros (idênticos) no Consul.
Visualização generalizada de todo o fluxo
Se o nó principal falhar:
- nós do
orchestrator detectam falhas; orchestrator/raft mestre do orchestrator/raft inicia a recuperação. Um novo nó mestre é designado;- o esquema
orchestrator/raft transfere os dados sobre a alteração do nó principal para todos os nós do cluster de raft ; - cada instância do
orchestrator/raft recebe uma notificação sobre uma alteração de nó e grava a identidade do novo nó mestre no armazenamento KV local no Consul; - em cada instância GLB / HAProxy, o serviço
consul-template é iniciado, que monitora as alterações no repositório KV no Consul, reconfigura e reinicia o HAProxy; - O tráfego do cliente é redirecionado para o novo nó principal.
Para cada componente, as responsabilidades são claramente distribuídas e toda a estrutura é diversificada e simplificada. orchestrator não interage com os balanceadores de carga. O Consul não exige informações sobre a origem das informações. Servidores proxy funcionam apenas com o Consul. Os clientes trabalham apenas com servidores proxy.
Além disso:
- Não há necessidade de fazer alterações no DNS e disseminar informações sobre eles;
- TTL não é usado;
- o encadeamento não aguarda respostas do host em um estado de erro. Em geral, é ignorado.
Para estabilizar o fluxo, também aplicamos os seguintes métodos:
- O parâmetro HAProxy
hard-stop-after forçada hard-stop-after é definido como um valor muito pequeno. Quando o HAProxy é reinicializado com o novo servidor no pool de gravação, o servidor termina automaticamente todas as conexões existentes com o nó principal antigo.
- A configuração do parâmetro
hard-stop-after permite que você não espere nenhuma ação dos clientes. Além disso, as consequências negativas da possível ocorrência de dois nós principais no cluster são minimizadas. É importante entender que não há mágica aqui e, de qualquer forma, algum tempo passa antes que os velhos laços sejam rompidos. Mas há um momento no qual podemos parar de esperar por surpresas desagradáveis.
- Não exigimos a disponibilidade continuada do serviço Consul. De fato, precisamos que ele esteja disponível apenas durante o failover. Se o serviço Consul não estiver respondendo, o GLB continuará trabalhando com os mais recentes valores conhecidos e não tomará medidas drásticas.
- O GLB está configurado para verificar a identidade do nó principal recém-atribuído. Assim como em nossos pools MySQL sensíveis ao contexto , é realizada uma verificação para confirmar se o servidor é realmente gravável. Se excluirmos acidentalmente a identidade do nó principal no Consul, não haverá problemas, um registro vazio será ignorado. Se escrevermos por engano o nome de outro servidor (não o principal) no Consul, então, tudo bem: o GLB não o atualizará e continuará trabalhando com o último estado válido.
Nas seções a seguir, analisamos os problemas e analisamos os objetivos de alta disponibilidade.
Detecção de falha com orquestrador / jangada
orchestrator adota uma abordagem abrangente para a detecção de falhas, o que garante alta confiabilidade da ferramenta. Não encontramos resultados falsos positivos, falhas prematuras não são realizadas, o que significa que o tempo de inatividade desnecessário é excluído.
O circuito do orchestrator/raft também lida com situações de isolamento completo da rede do data center (esgrima do data center). O isolamento da rede do datacenter pode causar confusão: os servidores dentro do datacenter podem se comunicar. Como entender quem é realmente isolado - servidores em um determinado data center ou em todos os outros data centers?
No esquema orchestrator/raft , o mestre da orchestrator/raft é o failover. O nó se torna o líder, que recebe o apoio da maioria no grupo (quorum). Implementamos o nó do orchestrator maneira que nenhum data center possa fornecer a maioria, enquanto qualquer data center n-1 pode fornecê-lo.
No caso de isolamento completo da rede do centro de dados, os nós do orchestrator neste centro são desconectados dos nós semelhantes em outros centros de dados. Como resultado, os nós do orchestrator em um datacenter isolado não podem se tornar líderes em um cluster de raft . Se esse nó era o mestre, ele perde esse status. Um novo host receberá um dos nós dos outros datacenters. Esse líder terá o suporte de todos os outros data centers que podem interagir entre si.
Dessa maneira, o mestre do orchestrator estará sempre fora do data center isolado na rede. Se o nó principal estava no datacenter isolado, o orchestrator inicia um failover para substituí-lo pelo servidor de um dos datacenters disponíveis. Atenuamos o impacto do isolamento do datacenter delegando decisões ao quorum de datacenters disponíveis.
Notificação mais rápida
O tempo de inatividade total pode ser reduzido ainda mais acelerando a notificação de uma alteração no nó principal. Como conseguir isso?
Quando o orchestrator inicia o failover, ele considera um grupo de servidores, um dos quais pode ser atribuído como principal. Dadas as regras, recomendações e limitações de replicação, ele é capaz de tomar uma decisão informada sobre o melhor curso de ação.
De acordo com os seguintes sinais, ele também pode entender que um servidor acessível é um candidato ideal para o compromisso principal:
- nada impede que o servidor fique elevado (e talvez o usuário recomende esse servidor);
- é esperado que o servidor possa usar todos os outros servidores como réplicas.
Nesse caso, o orchestrator primeiro configura o servidor como gravável e anuncia imediatamente um aumento em seu status (no nosso caso, ele grava o registro no repositório KV no Consul). orchestrator , .
, , GLB , , . : !
MySQL , . : , , , .
, . , , . , , , .
: 500 . . ( ), .
( ) . , .
, . , , . , , , .
, / pt-heartbeat / , . , pt-heartbeat , read_only , .
pt-heartbeat , . . . , pt-heartbeat .
orchestrator
orchestrator :
- Pseudo-GTID;
- , ;
- (
read_only ), .
, . , , , . orchestrator .
- , , . , -, .
, .
, , , - . . STONITH . , , , «» - . , , .
: Consul , . . , , , , .
orchestrator/GLB/Consul :
- ;
- ;
- ;
- ;
- , ( );
- ;
10-13 .
20 , — 25 .
Conclusão
«// » , , . . , .