Em 1 de novembro de 2017, me tornei o líder da equipe de desenvolvimento no departamento de desenvolvimento de software da Timeweb. E em 12 de novembro de 2018, o chefe do departamento perguntou quando o artigo para Habrahabr estaria pronto, porque o departamento de marketing perguntou, os voluntários haviam terminado e o plano de conteúdo exigia outra coisa)
Portanto, quero dar uma retrospectiva de como os processos de desenvolvimento, teste e entrega de nossos produtos mudaram no ano passado. Sobre processos e ferramentas legados, janela de encaixe, gitlab e como estamos desenvolvendo.
O Timeweb Hoster existe desde 2006. Todo esse tempo, a empresa investe muito esforço para fornecer aos clientes um serviço exclusivo e conveniente que a distingue dos concorrentes. A Timeweb possui seus próprios aplicativos móveis, uma interface de email baseada na Web, painéis de controle de hospedagem virtual, VDS, um programa de afiliados, suas ferramentas de suporte e muito mais.
Existem cerca de 250 projetos em nosso gitlab: são aplicativos clientes, ferramentas internas, bibliotecas, repositórios de configuração. Dezenas deles são ativamente desenvolvidos e suportados: eles se comprometem durante a semana de trabalho, os testam, coletam e os liberam.
Além da grande quantidade de código legado, tudo isso traz consigo um número apropriado de processos herdados e ferramentas relacionadas. Como qualquer legado, eles também precisam ser mantidos, otimizados, refatorados e algumas vezes substituídos.
De toda essa abundância de projetos, os painéis de controle estão mais próximos de hospedar clientes. E é precisamente no projeto "Painel de Controle" que geralmente executamos várias melhorias na infraestrutura e fazemos muitos esforços para manter a infraestrutura conectada em forma. Espalhar a experiência adquirida e gostar de práticas para outros produtos e suas equipes.
Sobre as diferentes mudanças em ferramentas e processos no ano passado, vou contar.
Vagrant → docker-compor
O problema
No primeiro dia útil, tentei levantar os painéis de controle localmente. Naquela época, havia cinco aplicativos da web em um repositório:
- hospedagem virtual de PU 3.0,
- PU VDS 2.0,
- webmasters de PU,
- PESSOAL (suportes de ferramentas),
- Diretrizes (demonstração de componentes front-end padronizados).
Para executar, o Vagrant usado localmente. Vagrant lançou ansible. Para iniciar e configurar, foi preciso a ajuda de colegas e cerca de um dia de tempo limpo. Eu tive que instalar uma versão especial do Virtual Box (havia problemas no atual estável), trabalhar no console dentro da máquina virtual era muito irritante: comandos triviais como o npm / composer install diminuíram significativamente.
O desempenho dos aplicativos em si na máquina virtual estava longe de ser possível, dada a pilha de tecnologia usada e o poder da máquina. Sem mencionar que uma máquina virtual é uma máquina virtual e, por definição, ocupa uma parte significativa dos recursos do seu PC.
Solução
O ambiente de desenvolvimento local foi reescrito para execução em contêineres de docker. A conteinerização baseada no docker é a solução mais comum para isolar o ambiente do aplicativo em todas as etapas do seu ciclo de vida. Portanto, não há alternativas especiais.
Conclusões
Dos profissionais:
- localmente, o aplicativo se tornou mais responsivo, os contêineres exigem menos que as VMs,
- iniciar uma nova instância, como a prática demonstrou, leva alguns minutos e requer apenas docker (-compose) não inferior a determinadas versões. Após a clonagem, faça:
make install-dev make run-dev
Houve alguns compromissos:
- Eu tive que escrever ligações de shell para comandos dockerized (compositor, npm, etc.). Eles, como o docker-compose.yml, não são totalmente de plataforma cruzada em comparação com o Vagrant. Por exemplo, iniciar no Mac requer esforços adicionais e, no Windows, provavelmente será mais fácil executar uma distribuição com docker na máquina virtual linux. Mas este é um compromisso aceitável, pois a equipe usa apenas distribuições baseadas em debian, essa é uma limitação aceitável para desenvolvimento comercial,
- para oferecer suporte a hosts virtuais, um contêiner baseado em
github.com/jwilder/nginx-proxy é iniciado localmente. Não é uma muleta, mas um software adicional, que às vezes precisa ser lembrado, embora não cause problemas.
Sim, todos na equipe tiveram que perceber pelo menos um pouco o que é o docker. Embora graças aos scripts de shell e Makefile mencionados, os desenvolvedores realizam 95% de suas tarefas sem pensar em contêineres, mas em um ambiente idêntico garantido.
newcp-dev → cp-stands
Essas frases estranhas são os nomes de máquinas com bancadas de teste de painéis de controle, novos e antigos, respectivamente.
O problema
As receitas Ansible foram usadas exclusivamente no Vagrant, de modo que a principal vantagem não foi alcançada: as versões dos pacotes no prod e nos estandes diferiam daquilo em que os desenvolvedores trabalhavam.
A incompatibilidade das versões dos pacotes de software para servidor nos antigos está de acordo com o que os desenvolvedores tinham, levou a problemas. A sincronização foi complicada pelo fato de os administradores de sistema usarem um sistema de gerenciamento de configuração diferente, e não é possível integrá-lo ao repositório de desenvolvedores.
Solução
Após a conteinerização, não foi difícil estender a configuração do docker-compose para uso em bancos de teste. Uma nova máquina foi criada para implantar stands em DOCKER_HOST.
Conclusões
Os desenvolvedores agora estão confiantes na relevância dos ambientes locais e de teste.
TeamCity → gitlab-ci
Os problemas
A configuração do projeto no TeamCity é um processo meticuloso e ingrato. A configuração do IC foi armazenada separadamente do código, em xml, ao qual o controle de versão normal não é aplicável e uma visão geral das alterações. Também tivemos problemas com a estabilidade do processo de compilação nos agentes do TeamCity.
Solução
Como o gitlab já era usado como repositório para repositórios, começar a usar seu IC não era apenas lógico, mas também fácil e agradável. Agora toda a configuração do CI / CD está no repositório.
Resultado
Ao longo do ano, quase todos os projetos montados pelo TeamCity foram movidos com segurança para o gitlab-ci. Tivemos a oportunidade de implementar rapidamente uma variedade de recursos para automatizar processos de CI / CD.
As capturas de tela dos pipelines serão as mais óbvias:
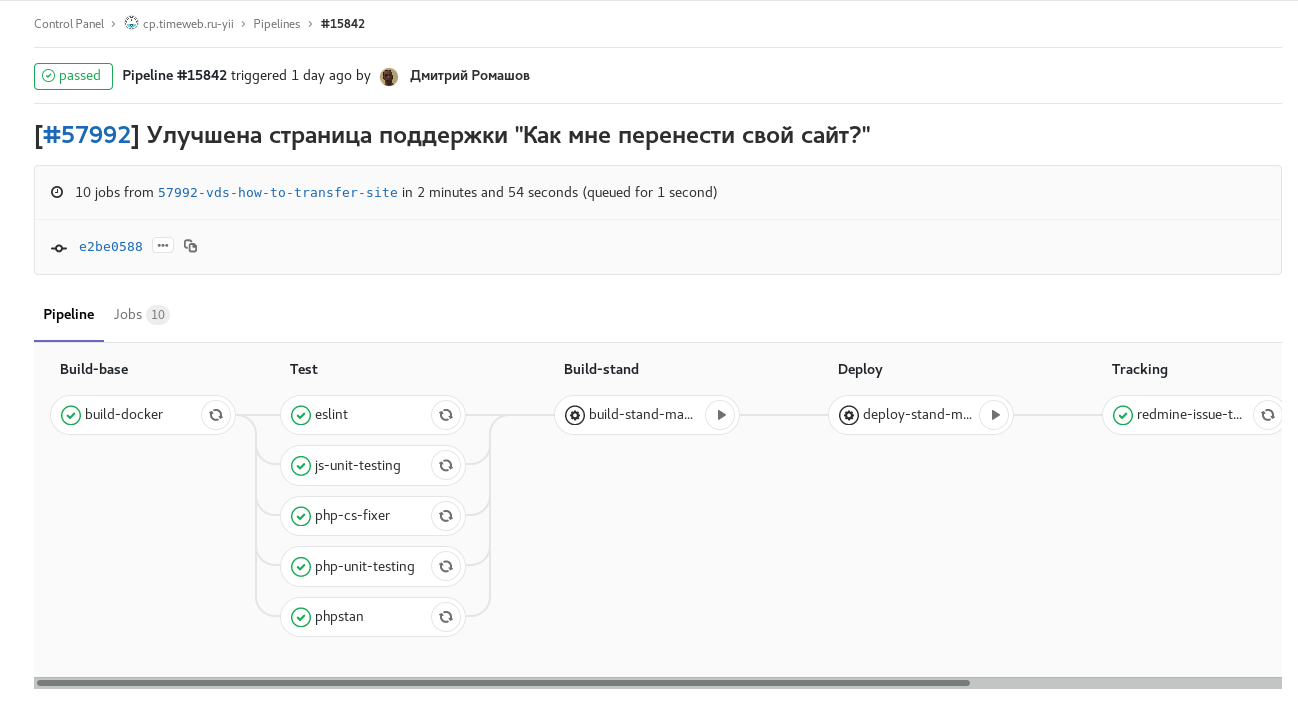 Fig. 1. ramo de recursos: todas as verificações e testes automáticos disponíveis estão incluídos. Quando concluído, envia um comentário com um link para o pipeline para a tarefa redmine. Tarefas manuais para montar e iniciar um estande com esta filial.
Fig. 1. ramo de recursos: todas as verificações e testes automáticos disponíveis estão incluídos. Quando concluído, envia um comentário com um link para o pipeline para a tarefa redmine. Tarefas manuais para montar e iniciar um estande com esta filial.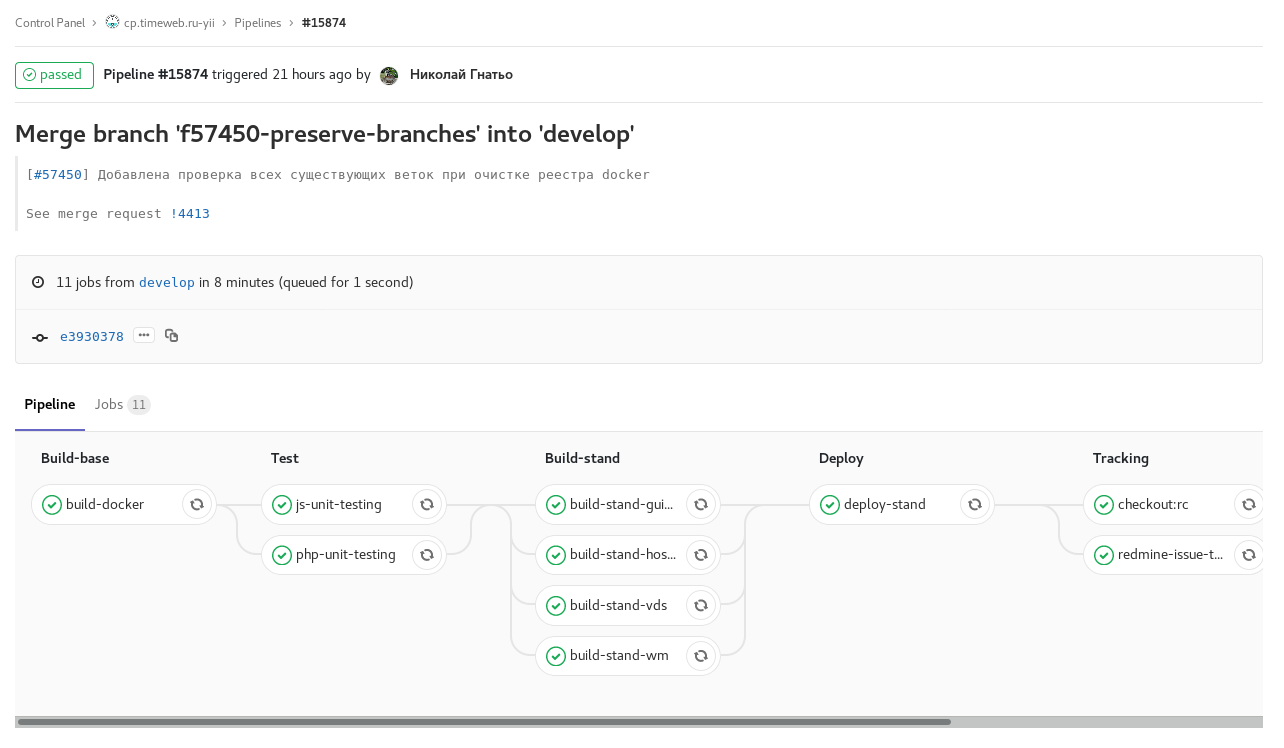 Fig. 2. desenvolver compilação agendada com congelamento de código (checkout: rc): desenvolver desenvolver dentro da programação com congelamento de código. A montagem de imagens para os estandes dos painéis de controle individuais ocorre em paralelo.
Fig. 2. desenvolver compilação agendada com congelamento de código (checkout: rc): desenvolver desenvolver dentro da programação com congelamento de código. A montagem de imagens para os estandes dos painéis de controle individuais ocorre em paralelo.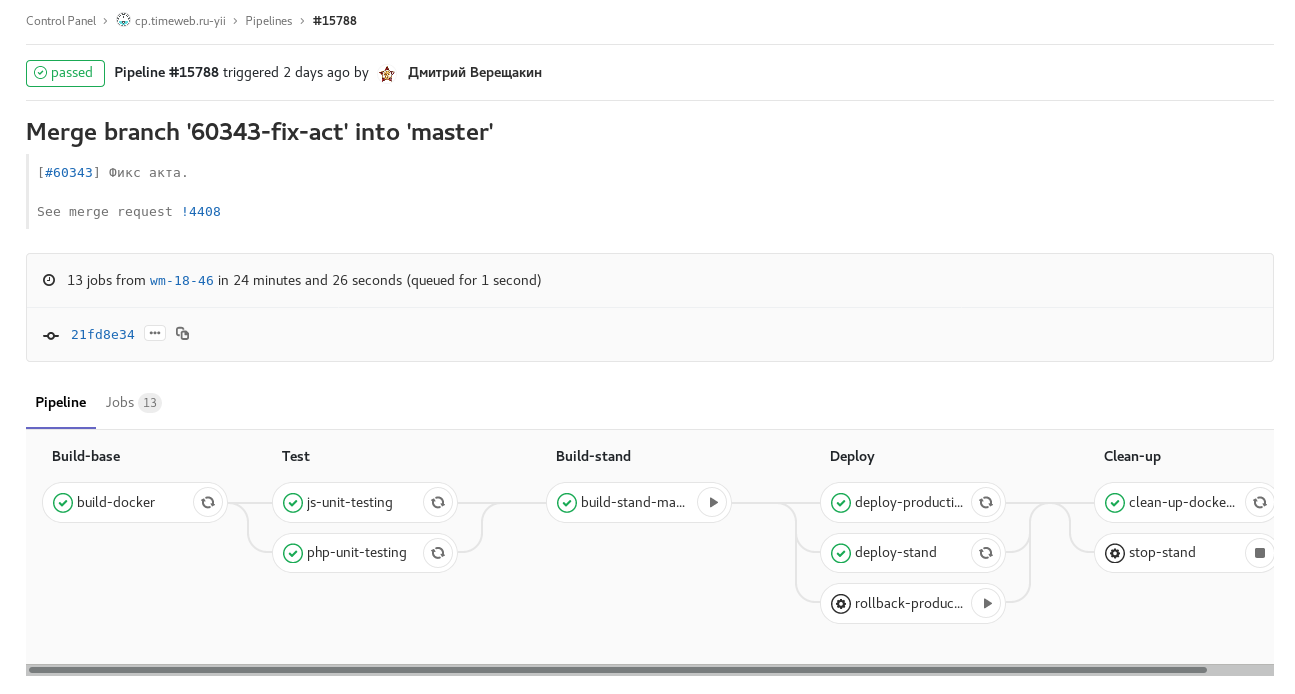 Fig. 3. pipeline de tags: liberação de um dos painéis de controle. Tarefa manual para liberação de reversão.
Fig. 3. pipeline de tags: liberação de um dos painéis de controle. Tarefa manual para liberação de reversão.Além disso, no gitlab-ci, há uma mudança de status e a nomeação de uma pessoa no redmine nos estágios Em andamento → Revisão → controle de qualidade, notificação no Slack sobre lançamentos e atualizações de preparação e reversões.
Isso é conveniente, mas não levamos em conta um ponto metodológico. Depois de implementar essa automação em um projeto, as pessoas se acostumam rapidamente. E, no caso de alternar para outro projeto em que isso ainda não exista, ou o processo for diferente, você pode esquecer de mover e reatribuir a tarefa em redmine ou deixar um comentário com um link para Merge Request (o que o gitlab-ci também faz), forçando o visualizador a procurar o desejado MR você mesmo. Ao mesmo tempo, você não deseja copiar peças .gitlab-ci.yml e o código do shell que os acompanha entre os projetos, porque você precisa oferecer suporte à cópia e colagem.
Conclusão: a automação é boa, mas quando é a mesma no nível de todas as equipes e projetos - ainda melhor. Eu ficaria grato ao público eminente por idéias sobre como organizar a reutilização de tal configuração lindamente.
Duração do pipeline: 80 min → 8 min
Gradualmente, nosso IC começou a levar muito tempo indecentemente. Os testadores sofreram muito com isso: cada correção no mestre teve que esperar uma hora por uma liberação. Parecia assim:
 Fig. 4. pipipeline 80
Fig. 4. pipipeline 80 lvl duração mínima.Eu tive que mergulhar na análise de lugares lentos por vários dias e procurar maneiras de acelerar, mantendo a funcionalidade.
Os locais mais longos do processo foram a instalação de pacotes npm. Sem problemas, eles foram substituídos por fios e salvos em vários lugares por até 7 minutos.
Eles recusaram atualizações automáticas de teste, preferindo o controle manual do status desse estande.
Também adicionamos vários corredores e dividimos em tarefas paralelas a montagem de imagens de aplicativos e todas as verificações. Após essas otimizações, o pipeline da filial principal com a atualização de todos os estandes começou a levar na maioria dos casos de 7 a 8 minutos.
Capistrano → deployer
Para implantação na produção e no qa-stand, o Capistrano foi usado (e continua sendo usado no momento da redação). O cenário principal para essa ferramenta é: clonar o repositório no servidor de destino e executar todas as tarefas nele.
Anteriormente, a implantação era acionada pelas mãos de um engenheiro de QA com as chaves ssh necessárias do Vagrant. Então, quando Vagrant abandonou, Capistrano se mudou para um contêiner separado. Agora, a implantação é feita a partir do contêiner com o Capistrano com gitlab-runners, marcado com tags especiais e com as chaves necessárias, automaticamente quando as tags necessárias aparecerem.
O problema aqui é que todo o processo de compilação:
a) consome significativamente os recursos do servidor de combate (especialmente nó / gole),
b) não há como manter as versões do compositor, npm atualizadas. nó etc.
É mais lógico construir em um servidor de construção (no nosso caso, é o gitlab-runner) e fazer upload de artefatos prontos para o servidor de destino. Isso salvará o servidor de batalha dos utilitários de montagem e da responsabilidade externa.
Agora, consideramos o implantador como um substituto para o capistrano (já que não temos rubists, nem desejamos trabalhar com sua DSL) e planejamos transferir a montagem para o lado do gitlab. Em alguns projetos não críticos, já conseguimos experimentá-lo e até agora estamos satisfeitos: parece mais fácil, não encontramos nenhuma restrição.
Gitflow: rc-branches → tags
O desenvolvimento é realizado em ciclos semanais. Ao longo de cinco dias, uma nova versão está sendo desenvolvida: o desenvolvimento aceita as melhorias e correções planejadas para lançamento na próxima semana. Na sexta-feira à noite, o congelamento do código ocorre automaticamente. Na segunda-feira, começa o teste da nova versão, são feitas melhorias e, no meio da semana de trabalho, ocorre um lançamento.
Anteriormente, usamos ramos com nomes no formato rc18-47, o que significa que o candidato a lançamento é a 47a semana de 2018. O congelamento de código foi fazer o checkout da ramificação rc do develop. Mas em outubro deste ano, mudamos para tags. As tags foram definidas antes, mas após o fato, após o lançamento e a fusão da rc com o master. Agora, a aparência da tag leva a uma implantação automática e o congelamento é uma mesclagem de desenvolvimento no master.
Então, nos livramos de entidades extras no git e de variáveis no processo.
Agora, estamos "puxando" os projetos que estão atrasados no processo para um fluxo de trabalho semelhante.
Conclusão
A automação dos processos, sua otimização e o desenvolvimento são uma questão constante: enquanto o produto estiver se desenvolvendo ativamente e a equipe estiver trabalhando, haverá tarefas correspondentes. Novas idéias aparecem sobre como se livrar de ações rotineiras: os recursos são implementados no gitlab-ci.
À medida que os aplicativos crescem, os processos de IC começam a demorar inaceitavelmente - é hora de trabalhar em seu desempenho. Como as abordagens e ferramentas estão se tornando obsoletas - você precisa de um tempo para refatorar, revisá-las e atualizar.
