Hoje, nos sites temáticos no exterior sobre Big Data, é possível mencionar uma ferramenta relativamente nova para o ecossistema Hadoop como o Apache NiFi. Esta é uma ferramenta moderna de ETL de código aberto. Arquitetura distribuída para carregamento paralelo rápido e processamento de dados, um grande número de plug-ins para origens e transformações, a versão das configurações é apenas parte de suas vantagens. Com todo o seu poder, o NiFi permanece bastante fácil de usar.
Nós da Rostelecom nos esforçamos para desenvolver o trabalho com o Hadoop, por isso já experimentamos e apreciamos as vantagens do Apache NiFi em comparação com outras soluções. Neste artigo, mostrarei como essa ferramenta nos atraiu e como a usamos.
Antecedentes
Há não muito tempo atrás, tivemos a escolha de uma solução para carregar dados de fontes externas em um cluster Hadoop. Durante muito tempo, usamos o
Apache Flume para resolver esses problemas. Não houve queixas sobre o Flume como um todo, exceto por alguns pontos que não nos agradaram.
A primeira coisa que nós, como administradores, não gostamos foi que a gravação da configuração do Flume para realizar o próximo download trivial não pôde ser confiada a um desenvolvedor ou analista que não estava imerso nos meandros dessa ferramenta. Conectar cada nova fonte exigia intervenção obrigatória da equipe de administração.
O segundo ponto foi a tolerância a falhas e o dimensionamento. Para downloads pesados, por exemplo, via syslog, era necessário configurar vários agentes do Flume e definir um balanceador na frente deles. Tudo isso teve que ser monitorado e restaurado de alguma forma no caso de uma falha.
Em terceiro lugar , o Flume não permitiu o download de dados de vários DBMSs e o trabalho com alguns outros protocolos prontos para uso. Obviamente, nas vastas extensões da rede, você pode encontrar maneiras de fazer o Flume funcionar com Oracle ou SFTP, mas o suporte a essas bicicletas não é nada agradável. Para carregar dados do mesmo Oracle, tivemos que usar outra ferramenta -
Apache Sqoop .
Francamente, por minha natureza, sou uma pessoa preguiçosa e não queria apoiar o zoológico de soluções. E não gostei que todo esse trabalho tivesse que ser feito sozinho.
Obviamente, existem soluções bastante poderosas no mercado de ferramentas ETL que podem funcionar com o Hadoop. Isso inclui Informatica, IBM Datastage, SAS e Pentaho Data Integration. Esses são os que mais podem ser ouvidos pelos colegas do workshop e aqueles que primeiro vêm à mente. A propósito, usamos o IBM DataStage for ETL em soluções da classe Data Warehouse. Mas aconteceu historicamente que nossa equipe não pôde usar o DataStage para downloads no Hadoop. Novamente, não precisávamos de todo o poder das soluções desse nível para realizar conversões e downloads de dados bastante simples. O que precisávamos era de uma solução com boa dinâmica de desenvolvimento, capaz de trabalhar com muitos protocolos e com uma interface conveniente e intuitiva que não apenas um administrador que entendesse todas as suas sutilezas fosse capaz de manipular, mas também um desenvolvedor com um analista, que geralmente é para nós. clientes dos próprios dados.
Como você pode ver no título, resolvemos os problemas acima com o Apache NiFi.
O que é o Apache NiFi
O nome NiFi vem de "Niagara Files". O projeto foi desenvolvido pela Agência de Segurança Nacional dos EUA por oito anos e, em novembro de 2014, seu código fonte foi aberto e transferido para a Apache Software Foundation como parte do
NSA Technology Transfer Program .
O NiFi é uma ferramenta ETL / ELT de código aberto que pode funcionar com muitos sistemas, e não apenas nas classes Big Data e Data Warehouse. Aqui estão alguns deles: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, Syslog, HTTPS, SFTP. Você pode ver a lista completa na
documentação oficial.
O trabalho com um DBMS específico é implementado adicionando o driver JDBC apropriado. Existe uma API para gravar seu módulo como um receptor ou conversor de dados adicional. Exemplos podem ser encontrados
aqui e
aqui .
Principais recursos
O NiFi usa uma interface da web para criar o DataFlow. Um analista que recentemente começou a trabalhar com o Hadoop, um desenvolvedor e um administrador barbudo vai lidar com isso. Os dois últimos podem interagir não apenas com “retângulos e setas”, mas também com a
API REST para coletar estatísticas, monitorar e gerenciar componentes DataFlow.
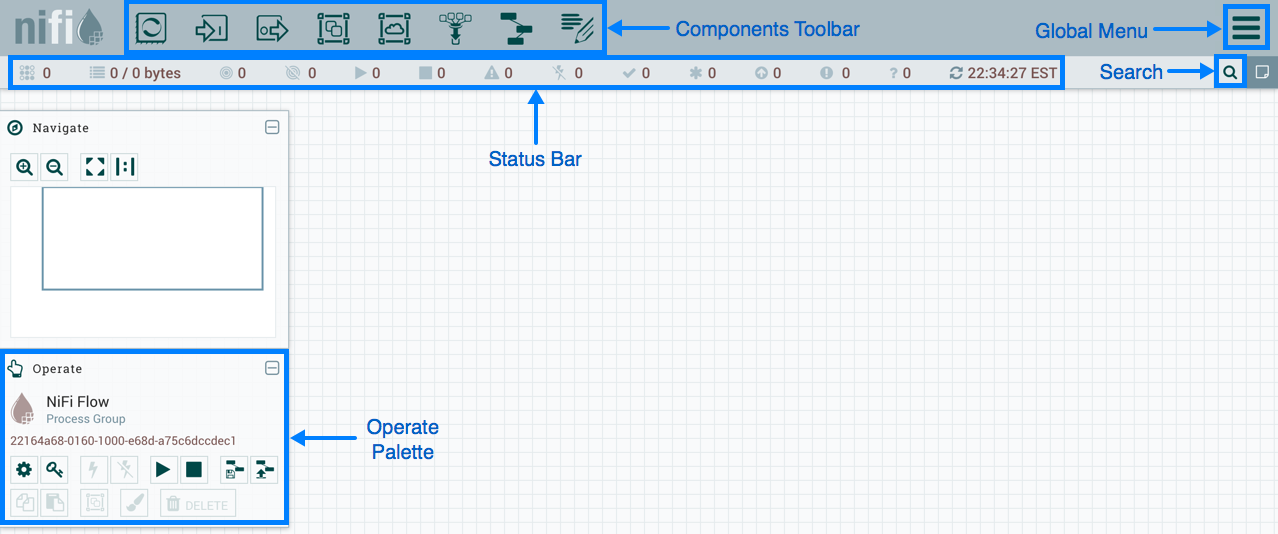 Gerenciamento baseado na Web NiFi
Gerenciamento baseado na Web NiFiAbaixo, mostrarei alguns exemplos do DataFlow para executar algumas operações comuns.
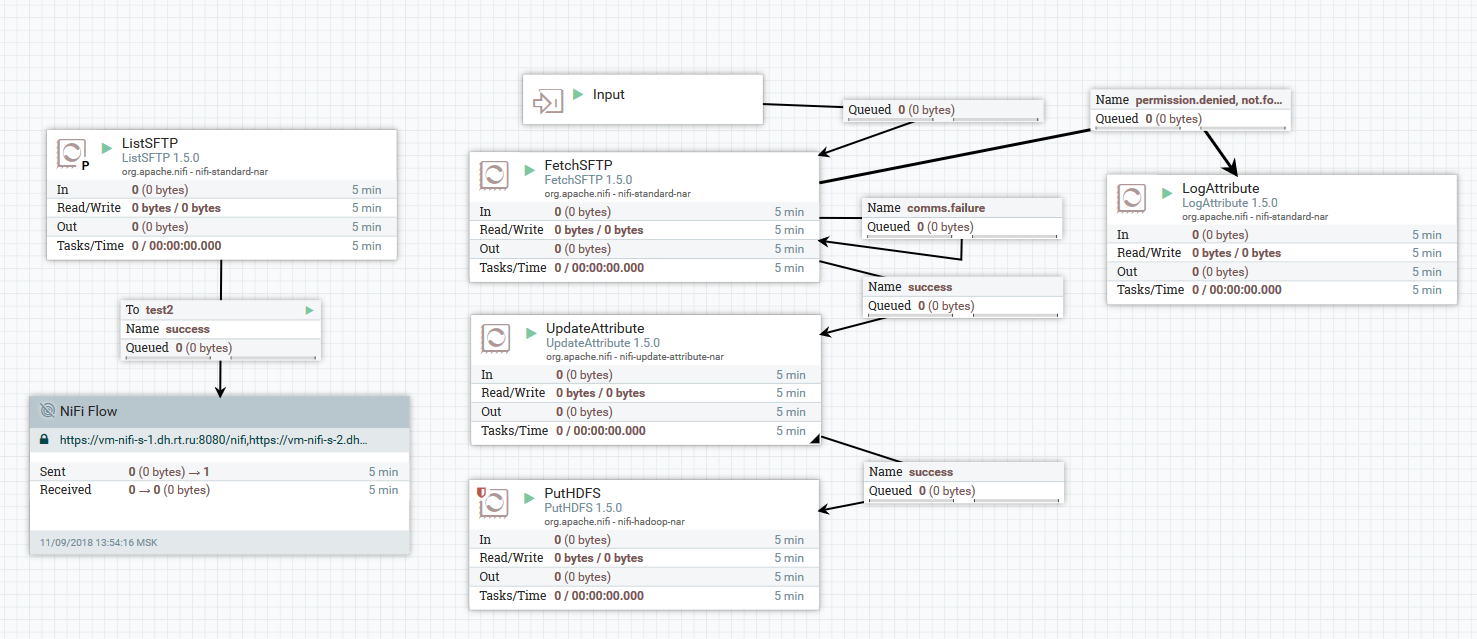 Exemplo de download de arquivos de um servidor SFTP para HDFS
Exemplo de download de arquivos de um servidor SFTP para HDFSNeste exemplo, o processador ListSFTP faz uma lista de arquivos no servidor remoto. O resultado desta listagem é usado para carregamento paralelo de arquivos por todos os nós do cluster pelo processador FetchSFTP. Depois disso, atributos são adicionados a cada arquivo, obtidos pela análise de seu nome, que são então usados pelo processador PutHDFS ao gravar o arquivo no diretório final.
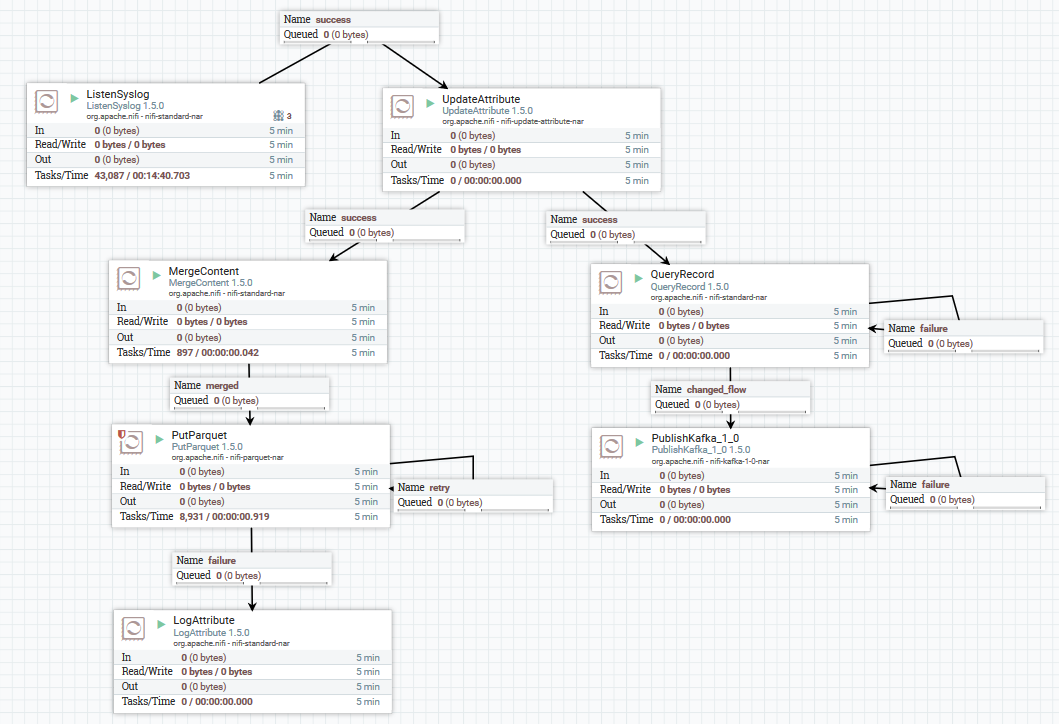 Um exemplo de download de dados syslog no Kafka e HDFS
Um exemplo de download de dados syslog no Kafka e HDFSAqui, usando o processador ListenSyslog, obtemos o fluxo de mensagens de entrada. Depois disso, atributos sobre a hora de chegada ao NiFi e o nome do esquema no Registro do esquema Avro são adicionados a cada grupo de mensagens. Em seguida, a primeira ramificação é enviada para a entrada do processador QueryRecord, que, com base no esquema especificado, lê os dados e os analisa usando SQL e os envia ao Kafka. A segunda ramificação é enviada ao processador MergeContent, que agrega os dados por 10 minutos e, em seguida, o entrega ao próximo processador para conversão no formato Parquet e gravação no HDFS.
Aqui está um exemplo de como mais você pode estilizar o DataFlow:
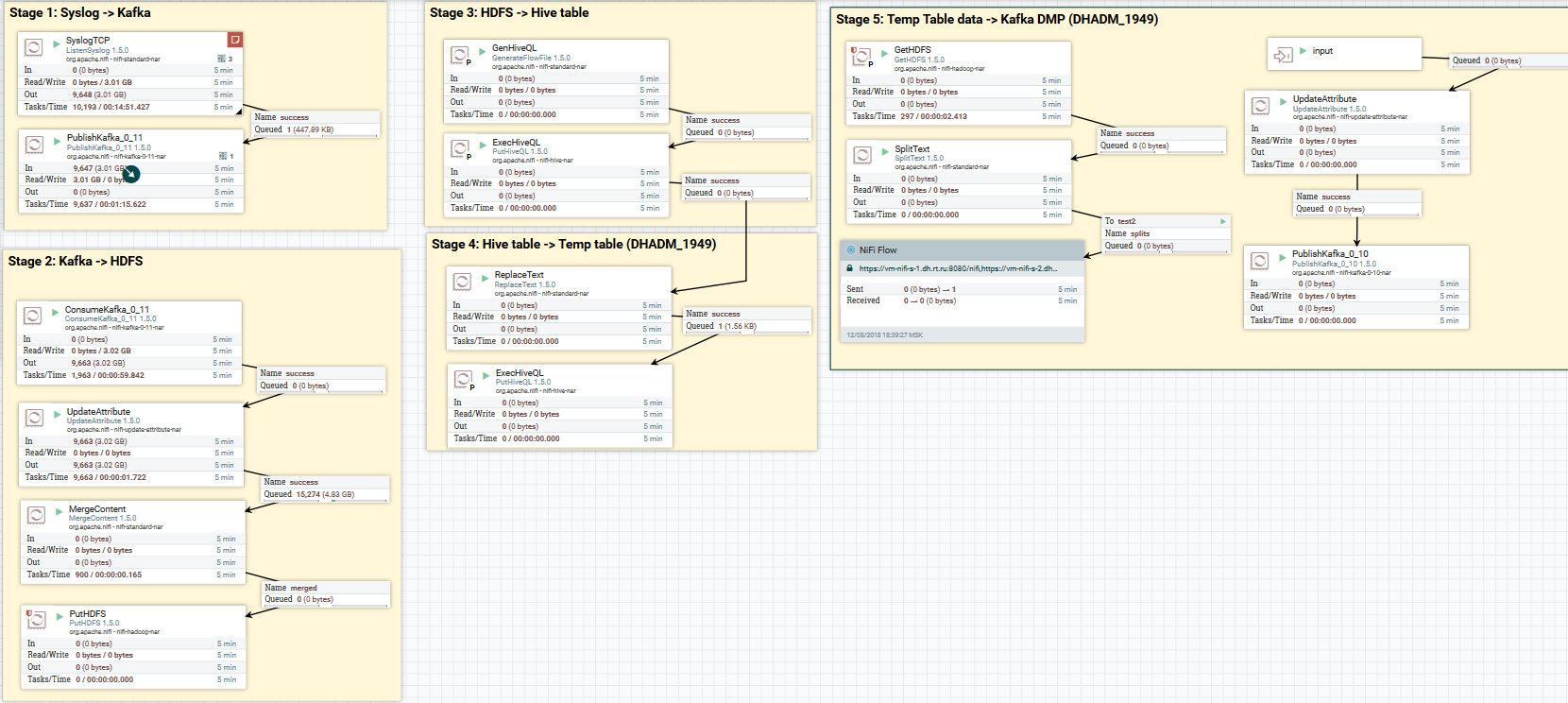 Faça o download dos dados do syslog para Kafka e HDFS. Limpando dados no Hive
Faça o download dos dados do syslog para Kafka e HDFS. Limpando dados no HiveAgora sobre conversão de dados. O NiFi permite analisar dados com dados regulares, executar SQL nele, filtrar e adicionar campos e converter um formato de dados para outro. Ele também possui uma linguagem de expressão própria, rica em vários operadores e funções internas. Com ele, você pode adicionar variáveis e atributos aos dados, comparar e calcular valores, usá-los posteriormente na formação de vários parâmetros, como o caminho para gravar no HDFS ou na consulta SQL no Hive. Leia mais
aqui .
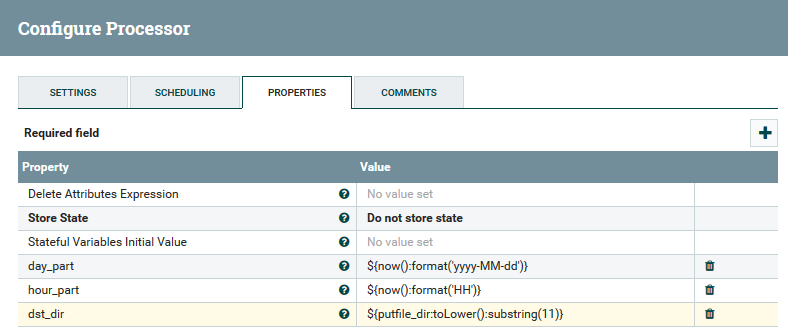 Um exemplo de uso de variáveis e funções no processador UpdateAttribute
Um exemplo de uso de variáveis e funções no processador UpdateAttributeO usuário pode acompanhar o caminho completo dos dados, observar a alteração em seus conteúdos e atributos.
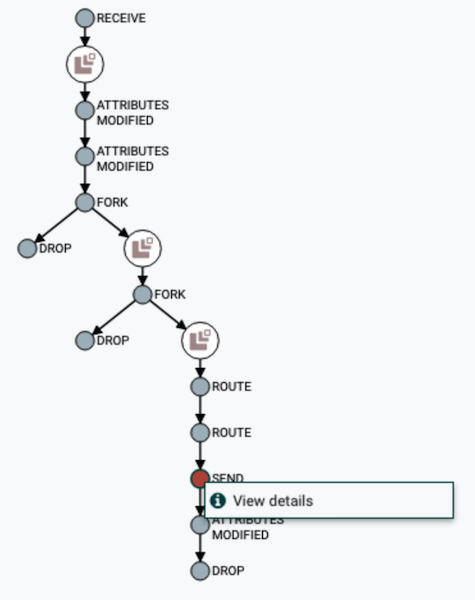 Visualização da cadeia DataFlow
Visualização da cadeia DataFlow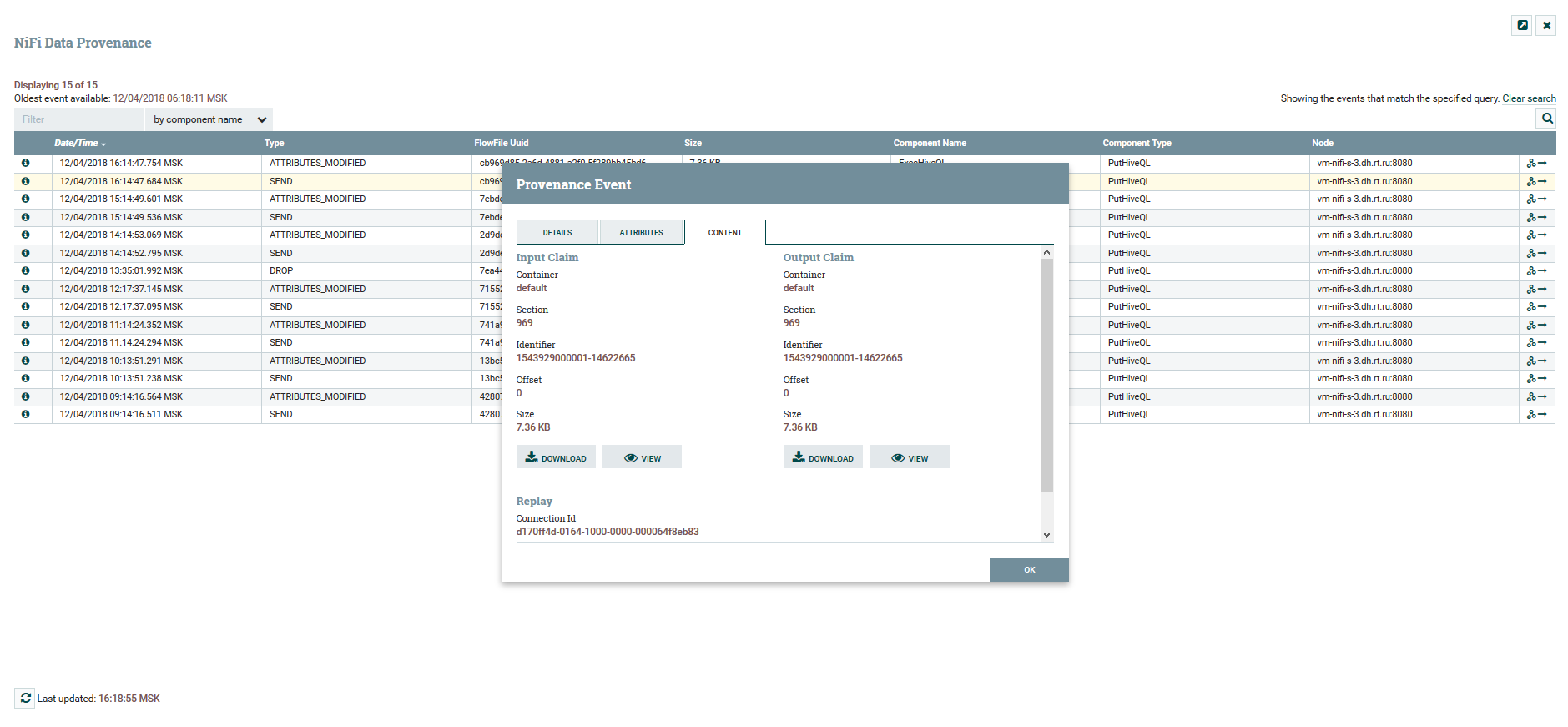 Visualizar atributos de conteúdo e dados
Visualizar atributos de conteúdo e dadosPara versionar o DataFlow, existe um serviço de
registro NiFi separado. Ao configurá-lo, você tem a capacidade de gerenciar alterações. Você pode executar alterações locais, reverter ou baixar qualquer versão anterior.
 Menu de Controle de Versão
Menu de Controle de VersãoNo NiFi, você pode controlar o acesso à interface da web e a separação dos direitos do usuário. Atualmente, os seguintes mecanismos de autenticação são suportados:
O uso simultâneo de vários mecanismos ao mesmo tempo não é suportado. Para autorizar usuários no sistema, FileUserGroupProvider e LdapUserGroupProvider são usados. Leia mais sobre isso
aqui .
Como eu disse, o NiFi pode funcionar no modo de cluster. Isso fornece tolerância a falhas e permite o dimensionamento horizontal da carga. Não há nó principal estaticamente fixo. Em vez disso, o
Apache Zookeeper seleciona um nó como coordenador e um como primário. O coordenador recebe informações sobre seu status de outros nós e é responsável por sua conexão e desconexão do cluster.
O nó primário é usado para iniciar processadores isolados, que não devem ser executados em todos os nós simultaneamente.
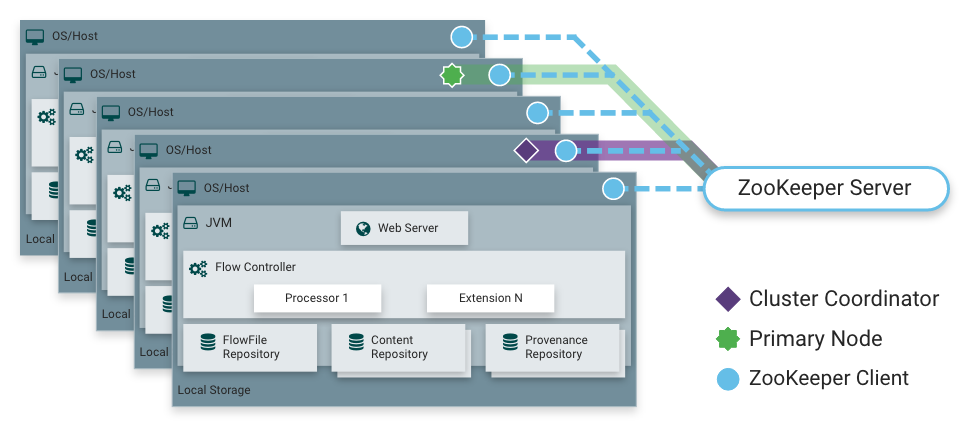 Operação NiFi em um cluster
Operação NiFi em um cluster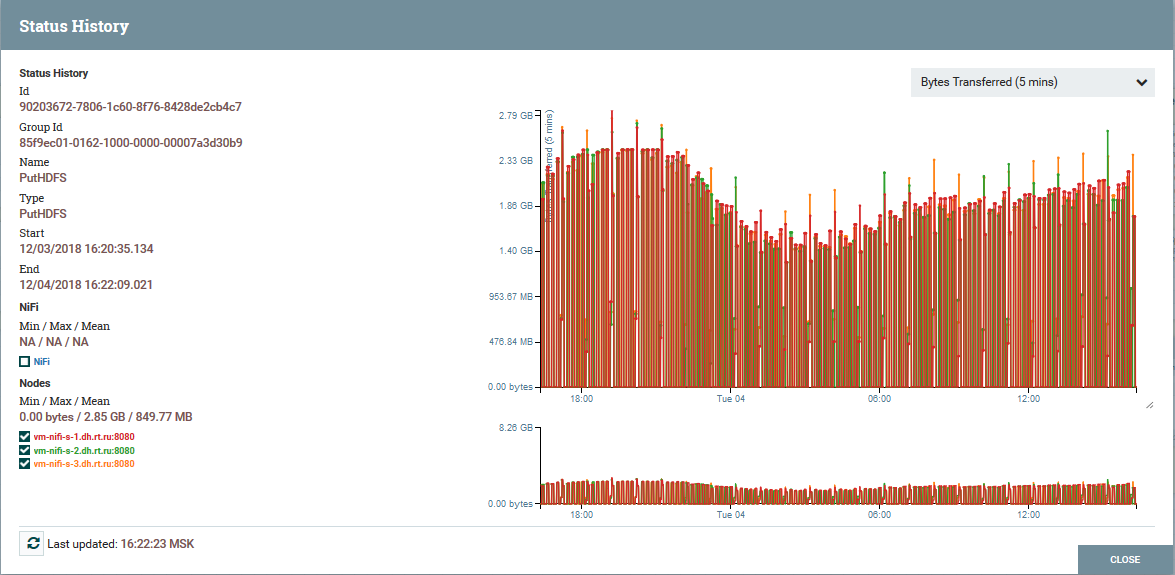 Distribuição de carga por nós de cluster usando o processador PutHDFS como exemplo
Distribuição de carga por nós de cluster usando o processador PutHDFS como exemploUma Breve Descrição da Arquitetura e Componentes NiFi
 Arquitetura da Instância NiFi
Arquitetura da Instância NiFiO NiFi é baseado no conceito de “Flow Based Programming” (
FBP ). Aqui estão os conceitos e componentes básicos que cada usuário encontra:
FlowFile - uma entidade que representa um objeto com conteúdo de zero ou mais bytes e seus atributos correspondentes. Podem ser os próprios dados (por exemplo, o fluxo de mensagens Kafka) ou o resultado do processador (PutSQL, por exemplo), que não contém dados como tais, mas apenas os atributos gerados como resultado da consulta. Atributos são metadados FlowFile.
O Processador FlowFile é exatamente a essência que faz o trabalho básico em NiFi. Um processador, como regra, possui uma ou várias funções para trabalhar com o FlowFile: criação, leitura / gravação e alteração de conteúdo, leitura / gravação / alteração de atributos, roteamento. Por exemplo, o processador ListenSyslog recebe dados usando o protocolo syslog, criando FlowFiles com os atributos syslog.version, syslog.hostname, syslog.sender e outros. O processador RouteOnAttribute lê os atributos do FlowFile de entrada e decide redirecioná-lo para a conexão apropriada com outro processador, dependendo dos valores dos atributos.
Conexão - fornece conexão e transferência de flowFile entre vários processadores e algumas outras entidades de NiFi. A conexão coloca o FlowFile em uma fila e o passa pela cadeia. Você pode configurar como os FlowFiles são selecionados na fila, sua vida útil, número máximo e tamanho máximo de todos os objetos na fila.
Grupo de processos - um conjunto de processadores, suas conexões e outros elementos DataFlow. É um mecanismo para organizar muitos componentes em uma estrutura lógica. Ajuda a simplificar o entendimento do DataFlow. As portas de entrada / saída são usadas para receber e enviar dados de grupos de processos. Leia mais sobre o uso deles
aqui .
O repositório do FlowFile é o local onde o NiFi armazena todas as informações que conhece sobre cada FlowFile existente no sistema.
Repositório de conteúdo - o repositório no qual o conteúdo de todos os FlowFiles está localizado, ou seja, os próprios dados transmitidos.
Repositório de proveniência - contém uma história sobre cada FlowFile. Sempre que um evento ocorre com o FlowFile (criação, alteração, etc.), as informações correspondentes são inseridas neste repositório.
Servidor Web - fornece uma interface web e uma API REST.
Conclusão
Com o NiFi, a Rostelecom conseguiu aprimorar o mecanismo de entrega de dados ao Data Lake no Hadoop. Em geral, todo o processo se tornou mais conveniente e confiável. Hoje, posso dizer com confiança que o NiFi é ótimo para baixar no Hadoop. Não temos problemas em sua operação.
A propósito, o NiFi faz parte da distribuição do Hortonworks Data Flow e é desenvolvido ativamente pelo próprio Hortonworks. Ele também possui um subprojeto interessante do Apache MiNiFi, que permite coletar dados de vários dispositivos e integrá-los ao DataFlow dentro do NiFi.
Informações adicionais sobre o NiFi
Talvez seja só isso. Obrigado a todos pela atenção. Escreva nos comentários se tiver alguma dúvida. Vou respondê-los com prazer.