
O DeepMind cria algoritmos verdadeiramente surpreendentes, capazes do que os sistemas de máquinas não poderiam alcançar antes. Em particular, a rede neural
AlphaGo foi capaz de vencer os melhores jogadores do mundo. Segundo especialistas, agora as capacidades do sistema cresceram tanto que nem faz sentido tentar derrotá-lo - o resultado é predeterminado.
No entanto, a empresa não pára por aí, mas continua a trabalhar. Graças à pesquisa de seus funcionários, nasceu
uma versão aprimorada do AlphaGo, chamada AlphaZero. Conforme indicado no título, o próprio sistema foi capaz de aprender a jogar três jogos lógicos ao mesmo tempo - xadrez, shogi e partida.
A diferença entre a nova versão e todas as anteriores
era que o próprio sistema aprendeu quase tudo. Ela começou do zero e aprendeu rapidamente a jogar os três jogos perfeitamente. Ninguém ajudou o AlphaZero - o sistema "conseguiu tudo sozinho".
O xadrez foi incluído no conjunto, de acordo com a tradição - não é nada difícil ensinar um computador a jogar xadrez, não. Pela primeira vez, um sistema de computador foi trazido para o jogo na década de 1950. Então, já nos anos 60, foi criado o programa
Mac Hack IV , que começou a derrotar rivais humanos. Com o tempo, os programas de xadrez melhoraram gradualmente e, em 1997, a IBM desenvolveu o "Chess Computer" Deep Blue, que conseguiu derrotar o Grandmaster e o Campeão do Mundo Garry Kasparov.
Como ele mesmo aponta, atualmente muitas aplicações em um smartphone jogam xadrez melhor do que o Deep Blue. Tendo alcançado perfeição na criação de sistemas capazes de jogar xadrez, os desenvolvedores começaram a criar novas versões de rivais de computadores humanos - em particular, eles conseguiram ensinar o computador a jogar. Anteriormente, esse jogo com mil anos de história era considerado um dos mais inacessíveis ao "entendimento" do computador. Mas os tempos mudaram. Como mencionado acima, o AlphaGo alcançou um nível tão alto de domínio do jogo que a pessoa não estava por perto.
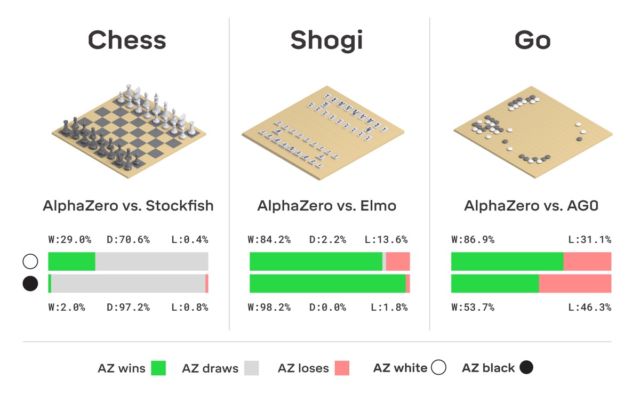
A propósito, este ano o AlphaGo recebeu uma atualização, graças à qual a rede neural agora pode aprender várias estratégias para jogar sem intervenção humana. Jogando consigo mesmo várias vezes, o AlphaGo está melhorando. É esse tipo de sistema de treinamento usado pelos “descendentes” do AlphaGo - a rede neural do AlphaZero. Em apenas três dias, ela alcançou tal nível de domínio no Go que venceu a versão original do AlphaGo com uma pontuação de 100 a 0. A única coisa que o sistema recebe inicialmente são as regras do jogo.
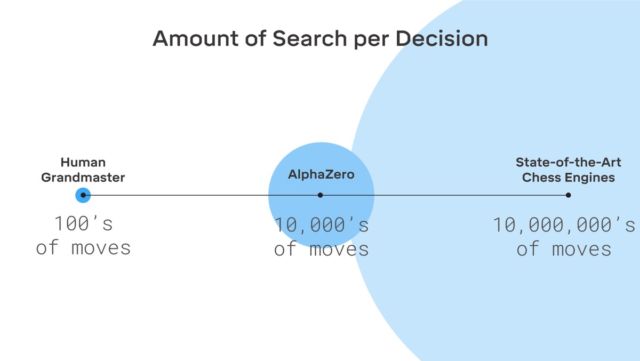
Não há ficção aqui, o DeepMind usa o conhecido sistema de aprendizado de máquina de reforço. O computador busca vencer, porque para cada vitória recebe uma recompensa (pontos). Além disso, o AlphaZero perde milhões de combinações no processo de aprendizado. O AlphaZero gasta apenas 0,4 segundos para calcular mal a próxima jogada e avaliar a probabilidade de ganhar. Quanto ao AlphaGo da versão original, a rede neural consistia em dois elementos, duas redes neurais - uma determinava o próximo movimento possível e a segunda calculava as probabilidades.
Para atingir o nível principal no Go AlphaZero, você precisa "rolar" cerca de 4,5 milhões de jogos ao jogar sozinho. Mas o AlphaGo exigiu 30 milhões de jogos.
Vale ressaltar que o AlphaZero foi criado especificamente para jogar go. A empresa não se esqueceu disso. Mas além de ir, o sistema é capaz de aprender e outros dois jogos, que foram mencionados acima. O sistema usado é o mesmo - aprendizado de máquina com reforço. Vale ressaltar que o AlphaZero trabalha apenas com tarefas que possuem um certo número de soluções. O sistema também precisa de um modelo de ambiente (virtual).
Curiosamente, o próprio Kasparov acredita que uma pessoa pode obter muito de sistemas como o AlphaGo - você pode aprender muito com eles.
Atualmente, os desenvolvedores enfrentam a tarefa de ensinar um computador a jogar pôquer melhor do que qualquer outra pessoa, além de criar um sistema que pode derrotar qualquer atleta em uma luta justa. De qualquer forma, é claro que as redes neurais e a IA são capazes de muito.