
Em uma postagem anterior, escalamos o conjunto de réplicas do MongoDB e introduzimos o StatefulSet. Agora, assumiremos a orquestração do cluster de alta disponibilidade do Elasticsearch (com outros nós principais, nós de dados e nós clientes) e usaremos o ES-HQ e o Kibana.
Você precisará de:
- Um entendimento básico do Elasticsearch, seus tipos de nós e suas funções.
- Um cluster Kubernetes em funcionamento com pelo menos três nós (pelo menos quatro núcleos, 4 GB).
- Capacidade de trabalhar com Kibana.
Arquitetura de implantação
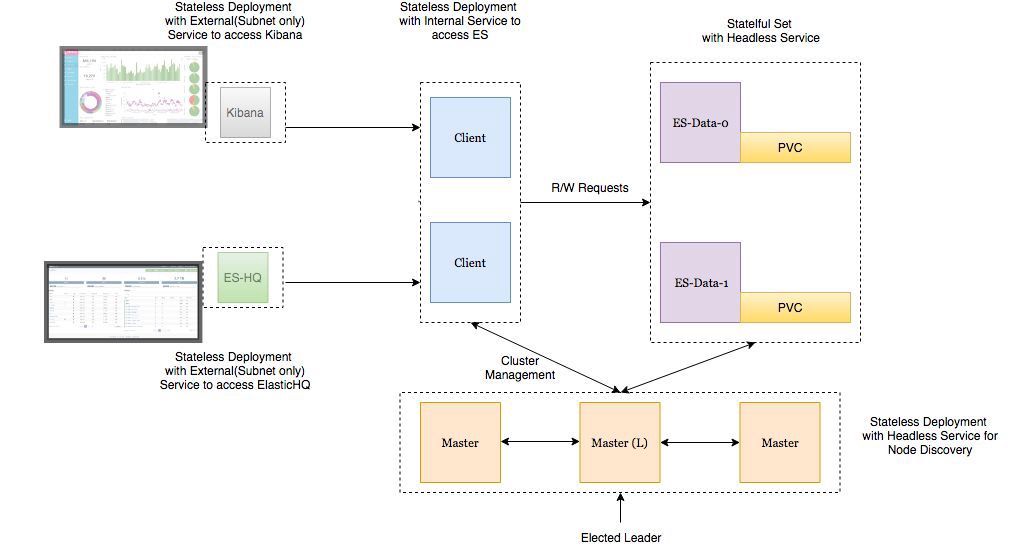
- Os nós de dados do Elasticsearch são implantados como um StatefulSet com um serviço sem cabeça, para que tenhamos identificadores de rede estáveis .
- Os pods de masternode do Elasticsearch são implantados como um ReplicaSet com um serviço sem cabeça. Isto é para descoberta automática .
- Os pods nos nós do cliente Elasticsearch são implantados como um ReplicaSet com um serviço interno para que você possa enviar solicitações de leitura / gravação para os nós de dados.
- Os pods Kibana e ElasticHQ são implantados como ReplicaSet com serviços disponíveis fora do cluster Kubernetes , mas localizados dentro da sub-rede (eles não abrem desnecessariamente).
- O HPA (Horizonal Pod Autoscaler) é implantado nos nós do cliente e é responsável pelo dimensionamento automático horizontal em alta carga.
"Lembre-se de configurar para o ambiente:
- Variável ES_JAVA_OPTS .
- Variável CLUSTER_NAME .
- A variável NUMBER_OF_MASTERS para a implantação dos mestres para evitar a situação de cérebro dividido. Se tivermos 3 mestres, especifique 2.
- Regras de ant afinidade para lareiras semelhantes para garantir alta confiabilidade se o nó de trabalho cair.
"
Vamos implantar esses serviços no cluster GKE.
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-master namespace: elasticsearch labels: component: elasticsearch role: master spec: replicas: 3 template: metadata: labels: component: elasticsearch role: master spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - master topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-master image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NUMBER_OF_MASTERS value: "2" - name: NODE_MASTER value: "true" - name: NODE_INGEST value: "false" - name: NODE_DATA value: "false" - name: HTTP_ENABLE value: "false" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 2 ports: - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumes: - emptyDir: medium: "" name: "storage" --- apiVersion: v1 kind: Service metadata: name: elasticsearch-discovery namespace: elasticsearch labels: component: elasticsearch role: master spec: selector: component: elasticsearch role: master ports: - name: transport port: 9300 protocol: TCP clusterIP: None view rawes-master.yml hosted with love by GitHub
(Implantar e serviço sem cabeçalho para nós principais)
root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-master 3 3 3 3 32s NAME DESIRED CURRENT READY AGE rs/es-master-594b58b86c 3 3 3 31s NAME READY STATUS RESTARTS AGE po/es-master-594b58b86c-9jkj2 1/1 Running 0 31s po/es-master-594b58b86c-bj7g7 1/1 Running 0 31s po/es-master-594b58b86c-lfpps 1/1 Running 0 31s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 31s
É interessante estudar os logs das lareiras nos nós principais e ver como o mestre é selecionado entre eles agora e como será mais tarde quando adicionarmos novos nós de dados e clientes.
root$ kubectl -n elasticsearch logs -f po/es-master-594b58b86c-9jkj2 | grep ClusterApplierService [2018-10-21T07:41:54,958][INFO ][oecsClusterApplierService] [es-master-594b58b86c-9jkj2] detected_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},{es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3]])
Aqui você pode ver que em es-master com o nome es-master-594b58b86c-bj7g7 é selecionado pelo mestre e os outros dois pods são adicionados a ele e um ao outro.
O serviço headless elasticsearch-discovery é instalado por padrão na imagem do Docker como uma variável de ambiente e é usado para detecção em nós. Essa configuração pode ser substituída, se desejado.
Da mesma forma, implantamos nós de dados e clientes . Veja as configurações abaixo.
Implemente o nó de dados:
kind: Namespace metadata: name: elasticsearch --- apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: fast provisioner: kubernetes.io/gce-pd parameters: type: pd-ssd fsType: xfs allowVolumeExpansion: true --- apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: es-data namespace: elasticsearch labels: component: elasticsearch role: data spec: serviceName: elasticsearch-data replicas: 3 template: metadata: labels: component: elasticsearch role: data spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - data topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-data image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NODE_MASTER value: "false" - name: NODE_INGEST value: "false" - name: HTTP_ENABLE value: "false" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 2 ports: - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumeClaimTemplates: - metadata: name: storage annotations: volume.beta.kubernetes.io/storage-class: "fast" spec: accessModes: [ "ReadWriteOnce" ] storageClassName: fast resources: requests: storage: 10Gi --- apiVersion: v1 kind: Service metadata: name: elasticsearch-data namespace: elasticsearch labels: component: elasticsearch role: data spec: ports: - port: 9300 name: transport clusterIP: None selector: component: elasticsearch role: data view rawes-data.yml hosted with love by GitHub
(StatefulSet e serviço sem cabeçalho para nós de dados)
O serviço decapitado em nós de dados emite identificadores de rede estáveis para nós e ajuda a transferir dados entre nós.
É importante formatar o volume permanente antes de anexá-lo à lareira. Basta especificar o tipo de volume ao criar a classe de armazenamento. Você também pode definir um parâmetro que permita a expansão automática do volume . Leia os detalhes aqui .
parameters: type: pd-ssd fsType: xfs allowVolumeExpansion: true ...
Implante nós do cliente:
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-client namespace: elasticsearch labels: component: elasticsearch role: client spec: replicas: 2 template: metadata: labels: component: elasticsearch role: client spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: role operator: In values: - client topologyKey: kubernetes.io/hostname initContainers: - name: init-sysctl image: busybox:1.27.2 command: - sysctl - -w - vm.max_map_count=262144 securityContext: privileged: true containers: - name: es-client image: quay.io/pires/docker-elasticsearch-kubernetes:6.2.4 env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: NODE_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: CLUSTER_NAME value: my-es - name: NODE_MASTER value: "false" - name: NODE_DATA value: "false" - name: HTTP_ENABLE value: "true" - name: ES_JAVA_OPTS value: -Xms256m -Xmx256m - name: NETWORK_HOST value: _site_,_lo_ - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu resources: limits: cpu: 1 ports: - containerPort: 9200 name: http - containerPort: 9300 name: transport volumeMounts: - name: storage mountPath: /data volumes: - emptyDir: medium: "" name: storage --- apiVersion: v1 kind: Service metadata: name: elasticsearch namespace: elasticsearch annotations: cloud.google.com/load-balancer-type: Internal labels: component: elasticsearch role: client spec: selector: component: elasticsearch role: client ports: - name: http port: 9200 type: LoadBalancer view rawes-client.yml hosted with love by GitHub
(Implementar e serviço externo para nós do cliente)
O serviço implantado aqui fornece acesso ao cluster ES fora do cluster Kubernetes, mas ainda está dentro da sub-rede. A anotação cloud.google.com/load-balancer-type: Internal é responsável por isso.
Mas se o aplicativo que acessa o cluster ES para leitura e gravação for implantado dentro do cluster, o acesso ao serviço ElasticSearch poderá ser obtido em http: //elasticsearch.elasticsearch: 9200 .
Quando você expande os nós de dados e clientes, eles serão adicionados ao cluster automaticamente. (Procure o mestre sob os registros)
root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]]) ] [ES-mestre-594b58b86c-bj7g7] adicionou {{ES-mestre-594b58b86c-9jkj2} {} {x9Prp1VbTq6_kALQVNwIWg 7NHUSVpuS0mFDTXzAeKRcg} {} {10,9 10.9.125.81 root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]]) ] [ES-mestre-594b58b86c-bj7g7] adicionou {{ES-data- root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]]) 10.9.125.82} {10.9.125.82 root$ kubectl -n elasticsearch get pods -l role=data NAME READY STATUS RESTARTS AGE es-data-0 1/1 Running 0 48s es-data-1 1/1 Running 0 28s -------------------------------------------------------------------- root$ kubectl apply -f es-client.yml root$ kubectl -n elasticsearch get pods -l role=client NAME READY STATUS RESTARTS AGE es-client-69b84b46d8-kr7j4 1/1 Running 0 47s es-client-69b84b46d8-v5pj2 1/1 Running 0 47s -------------------------------------------------------------------- root$ kubectl -n elasticsearch get all NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deploy/es-client 2 2 2 2 1m deploy/es-master 3 3 3 3 9m NAME DESIRED CURRENT READY AGE rs/es-client-69b84b46d8 2 2 2 1m rs/es-master-594b58b86c 3 3 3 9m NAME DESIRED CURRENT AGE statefulsets/es-data 2 2 3m NAME READY STATUS RESTARTS AGE po/es-client-69b84b46d8-kr7j4 1/1 Running 0 1m po/es-client-69b84b46d8-v5pj2 1/1 Running 0 1m po/es-data-0 1/1 Running 0 3m po/es-data-1 1/1 Running 0 3m po/es-master-594b58b86c-9jkj2 1/1 Running 0 9m po/es-master-594b58b86c-bj7g7 1/1 Running 0 9m po/es-master-594b58b86c-lfpps 1/1 Running 0 9m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/elasticsearch LoadBalancer 10.9.121.160 10.9.120.8 9200:32310/TCP 1m svc/elasticsearch-data ClusterIP None <none> 9300/TCP 3m svc/elasticsearch-discovery ClusterIP None <none> 9300/TCP 9m -------------------------------------------------------------------- #Check logs of es-master leader pod root$ kubectl -n elasticsearch logs po/es-master-594b58b86c-bj7g7 | grep ClusterApplierService [2018-10-21T07:41:53,731][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] new_master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300}, added {{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{es-master-594b58b86c-lfpps}{wZQmXr5fSfWisCpOHBhaMg}{50jGPeKLSpO9RU_HhnVJCA}{10.9.124.81}{10.9.124.81:9300}]]]) [2018-10-21T07:41:55,162][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [3] source [zen-disco-node-join[{es-master-594b58b86c-9jkj2}{x9Prp1VbTq6_kALQVNwIWg}{7NHUSVpuS0mFDTXzAeKRcg}{10.9.125.81}{10.9.125.81:9300}]]]) [2018-10-21T07:48:02,485][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [4] source [zen-disco-node-join[{es-data-0}{SAOhUiLiRkazskZ_TC6EBQ}{qirmfVJBTjSBQtHZnz-QZw}{10.9.126.88}{10.9.126.88:9300}]]]) [2018-10-21T07:48:21,984][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [5] source [zen-disco-node-join[{es-data-1}{fiv5Wh29TRWGPumm5ypJfA}{EXqKGSzIQquRyWRzxIOWhQ}{10.9.125.82}{10.9.125.82:9300}]]]) [2018-10-21T07:50:51,245][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [6] source [zen-disco-node-join[{es-client-69b84b46d8-v5pj2}{MMjA_tlTS7ux-UW44i0osg}{rOE4nB_jSmaIQVDZCjP8Rg}{10.9.125.83}{10.9.125.83:9300}]]]) [2018-10-21T07:50:58,964][INFO ][oecsClusterApplierService] [es-master-594b58b86c-bj7g7] added {{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300},}, reason: apply cluster state (from master [master {es-master-594b58b86c-bj7g7}{1aFT97hQQ7yiaBc2CYShBA}{Q3QzlaG3QGazOwtUl7N75Q}{10.9.126.87}{10.9.126.87:9300} committed version [7] source [zen-disco-node-join[{es-client-69b84b46d8-kr7j4}{gGC7F4diRWy2oM1TLTvNsg}{IgI6g3iZT5Sa0HsFVMpvvw}{10.9.124.82}{10.9.124.82:9300}]]])
Os logs do pod principal principal são mostrados claramente quando cada nó é adicionado ao cluster. Isso é útil para saber ao depurar.
Implementamos todos os componentes e agora precisamos verificar:
1) Implante o Elasticsearch de um cluster Kubernetes usando um contêiner Ubuntu.
root$ kubectl run my-shell --rm -i --tty --image ubuntu -- bash root@my-shell-68974bb7f7-pj9x6:/# curl http://elasticsearch.elasticsearch:9200/_cluster/health?pretty { "cluster_name" : "my-es", "status" : "green", "timed_out" : false, "number_of_nodes" : 7, "number_of_data_nodes" : 2, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
2) Implante o Elasticsearch de fora do cluster por meio do IP do balanceador interno GCP (no nosso caso, 10.9.120.8 ).
root$ curl http://10.9.120.8:9200/_cluster/health?pretty { "cluster_name" : "my-es", "status" : "green", "timed_out" : false, "number_of_nodes" : 7, "number_of_data_nodes" : 2, "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
3) Regras de ant afinidade para lares de ES.
root$ kubectl -n elasticsearch get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE es-client-69b84b46d8-kr7j4 1/1 Running 0 10m 10.8.14.52 gke-cluster1-pool1-d2ef2b34-t6h9 es-client-69b84b46d8-v5pj2 1/1 Running 0 10m 10.8.15.53 gke-cluster1-pool1-42b4fbc4-cncn es-data-0 1/1 Running 0 12m 10.8.16.58 gke-cluster1-pool1-4cfd808c-kpx1 es-data-1 1/1 Running 0 12m 10.8.15.52 gke-cluster1-pool1-42b4fbc4-cncn es-master-594b58b86c-9jkj2 1/1 Running 0 18m 10.8.15.51 gke-cluster1-pool1-42b4fbc4-cncn es-master-594b58b86c-bj7g7 1/1 Running 0 18m 10.8.16.57 gke-cluster1-pool1-4cfd808c-kpx1 es-master-594b58b86c-lfpps 1/1 Running 0 18m 10.8.14.51 gke-cluster1-pool1-d2ef2b34-t6h9
Observe que não temos duas lareiras semelhantes no mesmo nó, portanto garantimos alta confiabilidade no caso de uma falha no nó.
Dimensionamento
Podemos implantar serviços de dimensionamento automático para nós do cliente, dependendo do limite da CPU. Exemplo de HPA para um nó do cliente:
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: es-client namespace: elasticsearch spec: maxReplicas: 5 minReplicas: 2 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: es-client targetCPUUtilizationPercentage: 80
O dimensionamento automático adiciona pods no nó cliente ao cluster, e isso pode ser visto nos logs de qualquer pod no nó mestre.
Para pods em nós de dados , você só precisa aumentar o número de réplicas no painel de controle do Kubernetes ou no console do GKE. O próprio nó de dados criado será adicionado ao cluster e começará a replicar dados de outros nós.
Não preciso de dimensionamento automático nos nós mestres - eles armazenam apenas dados sobre o estado do cluster. Mas se você for adicionar nós de dados, verifique se o número de nós principais no cluster é ímpar e não se esqueça de alterar a variável NUMBER_OF_MASTERS para o ambiente.
Implantar o Kibana e o ES-HQ
Kibana e ES-HQ
O Kibana é uma ferramenta simples para visualizar dados de ES, e o ES-HQ ajuda a administrar e monitorar o cluster do Elasticsearch. Ao implantar o Kibana e o ES-HQ, lembre-se de que:
- Passamos o nome do cluster ES para a imagem do Docker como uma variável de ambiente.
- O serviço de acesso à implantação do Kibana / ES-HQ permanece dentro da empresa, ou seja, um IP público não é criado. Usamos o balanceador de carga GCP interno.
Implantar o Kibana
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-kibana namespace: elasticsearch labels: component: elasticsearch role: kibana spec: replicas: 1 template: metadata: labels: component: elasticsearch role: kibana spec: containers: - name: es-kibana image: docker.elastic.co/kibana/kibana-oss:6.2.2 env: - name: CLUSTER_NAME value: my-es - name: ELASTICSEARCH_URL value: http://elasticsearch:9200 resources: limits: cpu: 0.5 ports: - containerPort: 5601 name: http --- apiVersion: v1 kind: Service metadata: name: kibana annotations: cloud.google.com/load-balancer-type: "Internal" namespace: elasticsearch labels: component: elasticsearch role: kibana spec: selector: component: elasticsearch role: kibana ports: - name: http port: 80 targetPort: 5601 protocol: TCP type: LoadBalancer view rawes-kibana.yml hosted with love by GitHub
(Serviço de implantação e Kibana)
Implantar o ES-HQ
kind: Namespace metadata: name: elasticsearch --- apiVersion: apps/v1beta1 kind: Deployment metadata: name: es-hq namespace: elasticsearch labels: component: elasticsearch role: hq spec: replicas: 1 template: metadata: labels: component: elasticsearch role: hq spec: containers: - name: es-hq image: elastichq/elasticsearch-hq:release-v3.4.0 env: - name: HQ_DEFAULT_URL value: http://elasticsearch:9200 resources: limits: cpu: 0.5 ports: - containerPort: 5000 name: http --- apiVersion: v1 kind: Service metadata: name: hq annotations: cloud.google.com/load-balancer-type: "Internal" namespace: elasticsearch labels: component: elasticsearch role: hq spec: selector: component: elasticsearch role: hq ports: - name: http port: 80 targetPort: 5000 protocol: TCP type: LoadBalancer view rawes-hq.yml hosted with love by GitHub
(Implantar e serviço ES-HQ)
Acessamos os dois serviços por meio do balanceador interno criado.
root$ kubectl -n elasticsearch get svc -l role=kibana NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kibana LoadBalancer 10.9.121.246 10.9.120.10 80:31400/TCP 1m root$ kubectl -n elasticsearch get svc -l role=hq NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hq LoadBalancer 10.9.121.150 10.9.120.9 80:31499/TCP 1m
http: // <Serviço-Ip-Kibana Externo> / app / kibana # / home? _g = ()
(Painel de controle Kibana)
http: // <Iternal-Ip-ES-Hq-Service> / #! / clusters / my-es
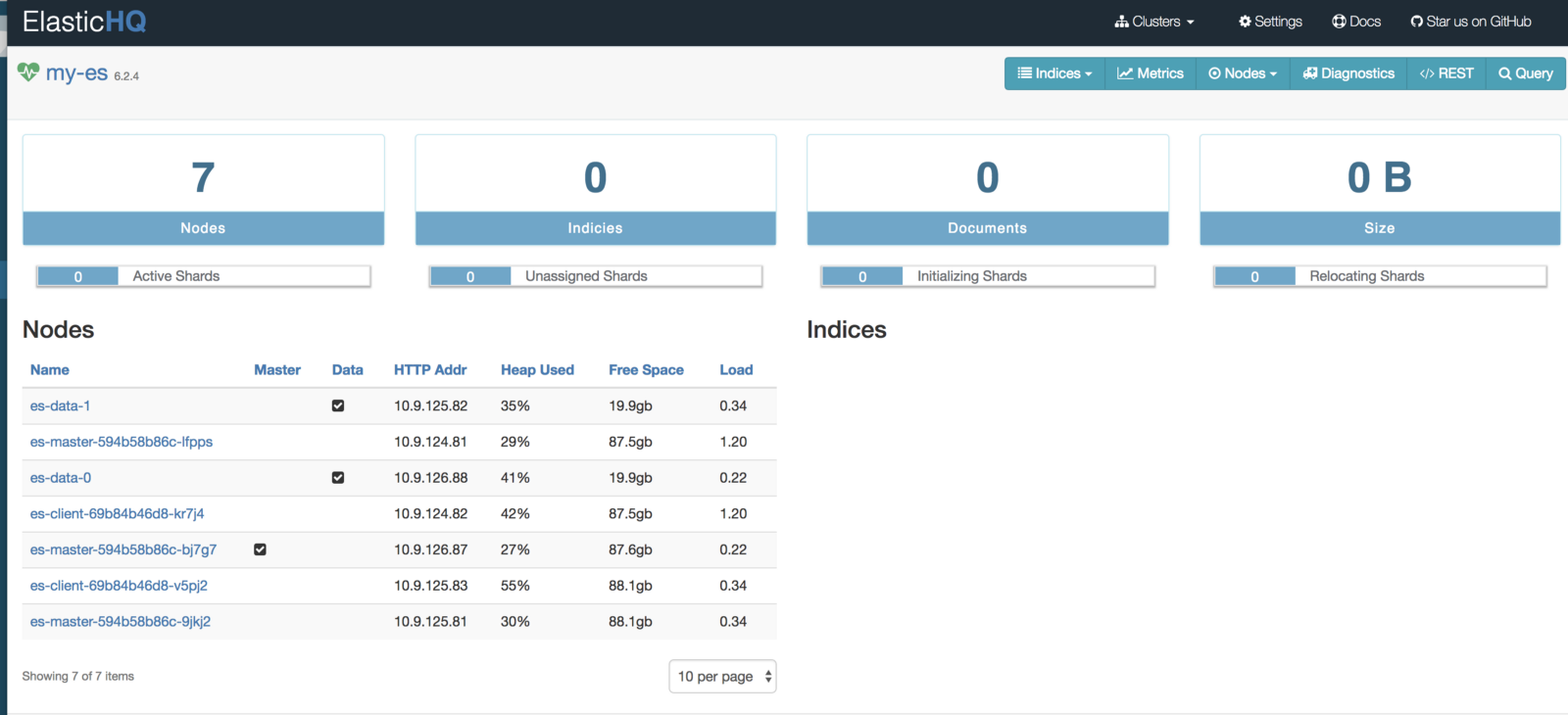
(Painel de controle ElasticHQ para monitorar e gerenciar o cluster)
O ES é um dos sistemas de pesquisa e análise distribuídos mais populares e, no Kubernetes, resolve os principais problemas de dimensionamento e alta disponibilidade. Além disso, novos clusters de ES no Kubernetes são implantados instantaneamente.