Ontem recebi uma carta de um aluno da décima série da Sibéria que deseja se tornar um desenvolvedor de microprocessadores. Ela já obteve alguns resultados nessa área - acrescentou a instrução de multiplicação ao processador schoolMIPS mais simples, sintetizou-a para o Intel FPGA MAX10 FPGA, determinou a frequência máxima e aumentou a produtividade de programas simples. Ela fez tudo isso primeiro na vila de Burmistrovo, na região de Novosibirsk, e depois em uma conferência em Tomsk.
Agora, Dasha Krivoruchko (esse é o nome da décima série) mudou-se para um internato de Moscou e me pergunta o que mais ela deveria criar. Penso que, nesta fase de sua carreira, ela deveria projetar um acelerador de hardware para redes neurais com base em uma matriz sistólica para multiplicação de matrizes. Use a linguagem de descrição de hardware Verilog e o Intel FPGA FPGA, mas não o MAX10 barato, mas algo mais caro para acomodar uma grande matriz sistólica.
Depois disso, compare o desempenho da solução de hardware com o programa em execução no processador schoolMIPS, bem como com o programa Python em execução no computador desktop. Como exemplo de teste, use o reconhecimento de números de uma pequena matriz.

Na verdade, todas as partes deste exercício já foram desenvolvidas por pessoas diferentes, mas o objetivo principal é colocá-lo em um único exercício documentado, que pode ser usado como base para o curso on-line e para competições práticas:
1) eNano, o departamento educacional da RUSNANO, que no passado organizou seminários Charles Danchek sobre o design da eletrônica moderna (rota RTL para GDSII) para estudantes e atualmente está trabalhando em um curso on-line desse tipo (projetar hardware no nível de transferências de registros + redes neurais). curso para estudantes avançados. Aqui Charles e eu estamos no escritório deles:

2) A base para as Olimpíadas pode estar interessada nas
Olimpíadas da NTI , com as quais levantei essa questão há algumas semanas em Moscou. Para esse exemplo, os participantes das olimpíadas poderiam adicionar um hardware para diferentes funções de ativação. Aqui estão colegas das Olimpíadas da NTI:

Portanto, se Dasha desenvolver isso, ela poderia, teoricamente, introduzir seu acelerador bem descrito tanto no RUSNANO quanto na Olimpíada da NTI. Eu acho que seria benéfico para a administração de sua escola - poderia ser exibido na TV ou enviado ao concurso Intel FPGA em geral. Aqui estão
alguns russos de São Petersburgo na final do concurso Intel FPGA em Santa Clara, Califórnia :

Agora vamos falar sobre o lado técnico do projeto. A idéia do acelerador de massa sistólica é descrita em um artigo traduzido pelo editor de Khabra Vyacheslav Golovanov
SLY_G Por que as TPUs são tão adequadas para o aprendizado profundo?É assim que um gráfico de rede neural de fluxo de dados se parece para facilitar o reconhecimento:

Um elemento de computação primitivo que executa multiplicações e adições:

Uma estrutura fortemente pipelined de tais elementos, essa matriz sistólica para multiplicação de matrizes é:

Na Internet, há um monte de código no Verilog e VHDL com a implementação de uma matriz sistólica, por exemplo, o código está
nesta postagem do blog :

module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9); parameter data_size=8; input wire clk,reset; input wire [data_size-1:0] a1,a2,a3,b1,b2,b3; output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9; wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69; pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1)); pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2)); pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3)); pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4)); pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5)); pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6)); pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7)); pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8)); pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9)); endmodule module pe(clk,reset,in_a,in_b,out_a,out_b,out_c); parameter data_size=8; input wire reset,clk; input wire [data_size-1:0] in_a,in_b; output reg [2*data_size:0] out_c; output reg [data_size-1:0] out_a,out_b; always @(posedge clk)begin if(reset) begin out_a<=0; out_b<=0; out_c<=0; end else begin out_c<=out_c+in_a*in_b; out_a<=in_a; out_b<=in_b; end end endmodule
Observo que esse código não é otimizado e geralmente desajeitado (e mesmo profissionalmente escrito - a fonte no post usa atribuições de bloco em @ (posedge clk) - eu o corrigi). A Dasha poderia, por exemplo, usar o Verilog gerar construções para um código mais elegante.
Além de duas realizações extremas da rede neural (no processador e na matriz sistólica), o Dasha poderia considerar outras opções mais rápidas que o processador, mas não tão vorazes quanto as operações de multiplicação como uma matriz sistólica. É verdade que isso é mais provável não para estudantes, mas para estudantes.
Uma opção é um dispositivo de execução com um grande número de blocos funcionais operando em paralelo, como em um processador fora de ordem:

Outra opção é a chamada Matriz Reconfigurável de Granulação Grossa - uma matriz de elementos de quase processador, cada um dos quais com um pequeno programa. Esses elementos do processador são idealmente semelhantes às células FPGA / FPGA, mas não operam com sinais individuais, mas com grupos de bits / números em barramentos e registros - veja o
relatório ao vivo desde o nascimento de um importante participante no hardware AI, que acelera o TensorFlow e compete com a NVidia " .
Agora a carta original de Dasha:
Bom dia, Yuri.
Em 2017, estudei na sua escola em LSHUP em sua oficina e em outubro de 2017 participei de uma conferência em Tomsk em outubro do mesmo ano com o trabalho dedicado à incorporação da unidade de multiplicação no processador SchooolMIPS.
Eu gostaria de continuar este trabalho agora. No momento, consegui permissão na escola para encarar esse tópico como um pequeno curso. Você tem a oportunidade de me ajudar com a continuação deste trabalho?
PS Como o trabalho é realizado em um formato específico, é necessária uma introdução e uma revisão da literatura sobre o tópico. Por favor, informe as fontes de onde você pode obter informações sobre a história do desenvolvimento deste tópico, sobre filosofias arquitetônicas etc., se você tiver esses recursos em mente.
Além disso, no momento em que moro em Moscou em um colégio interno, pode ser mais fácil interagir.
Atenciosamente
Daria Krivoruchko.
Dasha ensinou Verilog e design em nível de registro com a ajuda de mim e do livro
“Digital Circuitry and Computer Architecture” de David Harris e Sarah Harris . No entanto, se você é um estudante / estudante e quer entender os conceitos básicos em um nível muito simples, a editora DMK-Press lançou uma
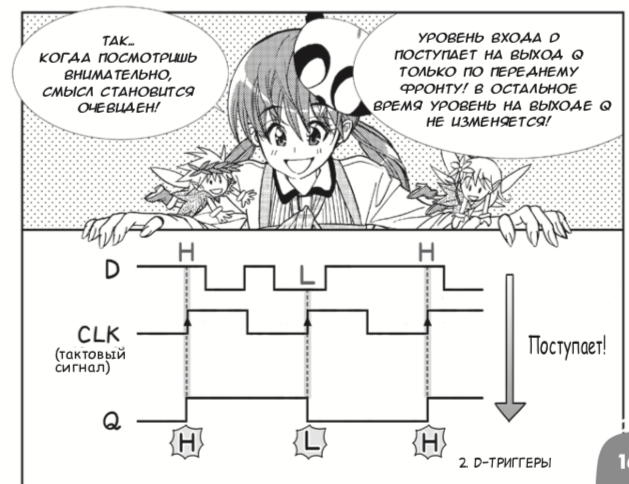
tradução para o russo do mangá japonês 2013 sobre circuitos digitais criados por Amano Hideharu e Meguro Koji. Apesar da forma frívola de apresentação, o livro introduz corretamente os elementos lógicos e os gatilhos D
e vincula isso aos FPGAs :
Veja como era a
Escola de Verão para Jovens Programadores na região de Novosibirsk, onde a Dasha aprendeu o Verilog, FPGAs, uma metodologia de desenvolvimento de transferência de registros (Nível de Transferência de Registros - RTL):


E aqui está o discurso de Dasha na conferência em Tomsk, juntamente com outro aluno da décima série, Arseniy Chegodaev:
Após a conversa de Dasha comigo e Stanislav Zhelnio
sparf , o principal criador do núcleo do processador educacional schoolMIPS para implementação em FPGAs:

O projeto schoolMIPS está com a documentação em
https://github.com/MIPSfpga/schoolMIPS . Na configuração mais simples desse núcleo de processador de treinamento, existem apenas 300 linhas no Verilog, enquanto no núcleo industrial incorporado da classe média existem cerca de 300 mil linhas. No entanto, o Dasha conseguiu sentir como é o trabalho dos designers da indústria, que alteram o decodificador e o dispositivo de execução da mesma maneira quando adicionam novas instruções ao processador:
Em conclusão, apresentamos fotos do reitor da Universidade de Samara, Ilya Kudryavtsev, que está interessado em criar uma escola de verão e olimpíadas com processadores FPGA para futuros candidatos:

E uma foto dos funcionários do Zelenograd MIET que já estão planejando uma escola de verão no próximo ano:

Ambos os materiais da RUSNANO e os possíveis materiais das Olimpíadas da NTI, bem como as conquistas realizadas nos últimos dois anos na implementação de FPGAs e microarquitetura no programa do HSE MIEM, Universidade Estadual de Moscou e
Kazan Innopolis, devem ir bem em um lugar e em outro.