No X5, processamos muitos dados em um sistema ERP. Acredita-se que ninguém mais nos processe no SAP ERP e SAP BW na Rússia. Mas há outro ponto - o número de operações e a carga neste sistema estão aumentando rapidamente. Por 3 anos, "lutamos" pelo desempenho de nossos pesos pesados ERP, obtivemos muitos cones e com quais métodos eles foram tratados, contamos abaixo.

ERP X5
Agora, o X5 opera mais de 13.000 lojas. A maioria dos processos de negócios de cada um deles passa por um único sistema ERP. Cada loja pode ter de 3.000 a 30.000 produtos, isso cria problemas com a carga no sistema, porque processos de recálculo regular de preços passam por ele de acordo com promoções e exigências legislativas e com o cálculo da reposição de estoques. Tudo isso é crítico e, se não for calculado em tempo útil quais mercadorias em que quantidade devem ser entregues amanhã à loja ou qual preço deve estar nas mercadorias, os compradores não encontrarão o que procuravam nas prateleiras ou não poderão comprar as mercadorias pelo preço da promoção atual ações. Em geral, além de contabilizar transações financeiras, o sistema ERP é responsável por muito no dia a dia de cada loja.
Um pouco das características de desempenho de um sistema ERP. Sua arquitetura é clássica, de três níveis, com elementos orientados a serviços: além disso, temos mais de 5.000 clientes e terabytes de fluxos de informações de lojas e centros de distribuição, na camada de aplicativos - SAP ABAP com mais de 10.000 processos e, finalmente, Oracle Database com mais de 100 TB de dados. Cada processo ABAP é uma máquina virtual condicional que executa a lógica de negócios ABAP com seu próprio dialeto DBSL e SQL, armazenamento em cache, gerenciamento de memória, ORM, etc. Todos os dias, recebemos mais de 15 TB de alterações no log do banco de dados. O nível de carga é de 500.000 solicitações por segundo.
Essa arquitetura é um ambiente heterogêneo. Cada um dos componentes é multiplataforma, podemos movê-lo para diferentes plataformas, escolher as melhores etc.
O fato de o sistema ERP estar sob carga 24 horas por dia, 365 dias por ano, acrescenta combustível ao incêndio. Disponibilidade - 99,9% do tempo ao longo do ano. A carga é dividida em perfis diurno e noturno e manutenção da casa em tempo livre.
Mas isso não é tudo. O sistema possui um ciclo de liberação apertado. Ele carrega mais de 2.000 trocas de lote por ano. Esse pode ser um novo botão e alterações sérias na lógica dos aplicativos de negócios.

Como resultado, é um sistema grande e altamente carregado, mas ao mesmo tempo estável, previsível e pronto para o crescimento que pode hospedar dezenas de milhares de lojas. Mas esse nem sempre foi o caso.
2014. Ponto de bifurcação
Para mergulhar no material prático, você precisa voltar para 2014. Depois, houve as tarefas mais difíceis de otimizar o sistema. Havia cerca de 5.000 lojas.
O sistema da época estava em tal estado que os processos mais críticos não eram escalonáveis e não respondiam adequadamente à carga crescente (ou seja, ao surgimento de novas lojas e mercadorias). Além disso, dois anos antes, um Hi-End caro foi comprado e, por algum tempo, uma atualização não fazia parte de nossos planos. Além disso, os processos no ERP já estavam prestes a violar o SLA. O fornecedor concluiu que a carga no sistema não é escalável. Ninguém sabia se ela poderia suportar pelo menos + 10% do aumento de carga. E foi planejado abrir duas vezes mais lojas em três anos.
Era impossível simplesmente alimentar o sistema ERP com ferro novo, e isso não ajudaria. Portanto, antes de tudo, decidimos incluir uma técnica de otimização de software no ciclo de lançamento e seguir a regra: o crescimento linear da carga proporcional ao crescimento dos drivers de carga é a chave da previsibilidade e escalabilidade.
Qual foi a técnica de otimização? Este é um processo cíclico, dividido em várias etapas:
- monitoramento (identificar gargalos no sistema e identificar os principais consumidores de recursos)
- análise (criação de perfil de processos do consumidor, identificação de estruturas com maior efeito e não linear na carga)
- desenvolvimento (reduzindo a influência das estruturas na carga, alcançando carga linear)
- testes em um ambiente de avaliação da qualidade ou implementação em um ambiente produtivo
Em seguida, o ciclo foi repetido.
No processo, percebemos que as ferramentas de monitoramento atuais não permitem identificar rapidamente os principais consumidores, identificar gargalos e processos que demandam recursos. Portanto, para acelerar, tentamos as ferramentas de pesquisa elástica e Grafana. Para fazer isso, eles desenvolveram independentemente coletores que, das ferramentas de monitoramento padrão no Oracle / SAP / AIX / Linux, transferiram métricas para a pesquisa elástica e permitiram o monitoramento em tempo real da integridade do sistema. Além disso, eles enriqueceram o monitoramento com suas métricas personalizadas, por exemplo, tempo de resposta e taxa de transferência de componentes SAP específicos ou layout de perfis de carga para processos de negócios.
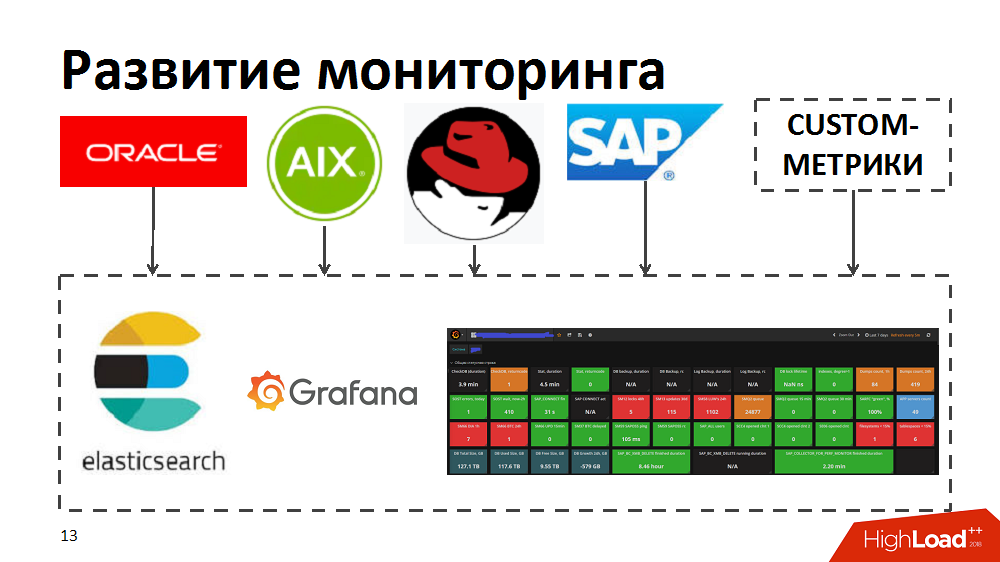
Otimização de código e processo
Antes de tudo, para um menor efeito de gargalos na velocidade, eles garantiam um fornecimento mais suave de carga ao sistema.
A maioria dos processos de negócios em nosso sistema ERP, por exemplo, como preços regulares ou planejamento de reposição de estoque, é um processamento sequencial passo a passo de uma grande quantidade de dados (para todas as mercadorias e todas as lojas). Para implementar o processamento no âmbito de tarefas tão difíceis, uma vez desenvolvemos nosso próprio despachante de processamento paralelo em lote (a seguir denominado agendador de carga). Nesse caso, na forma de um pacote, é apresentada uma etapa de processamento realizada separadamente para uma loja separada.
Inicialmente, a lógica do planejador era tal que primeiro os pacotes do primeiro estágio de processamento eram executados para todas as lojas, depois os pacotes do segundo estágio, etc. Ou seja, o sistema executou simultaneamente processos que criaram o mesmo tipo de carga e causaram a degradação de certos recursos (entrada / saída no banco de dados ou CPU nos servidores de aplicativos, etc.).
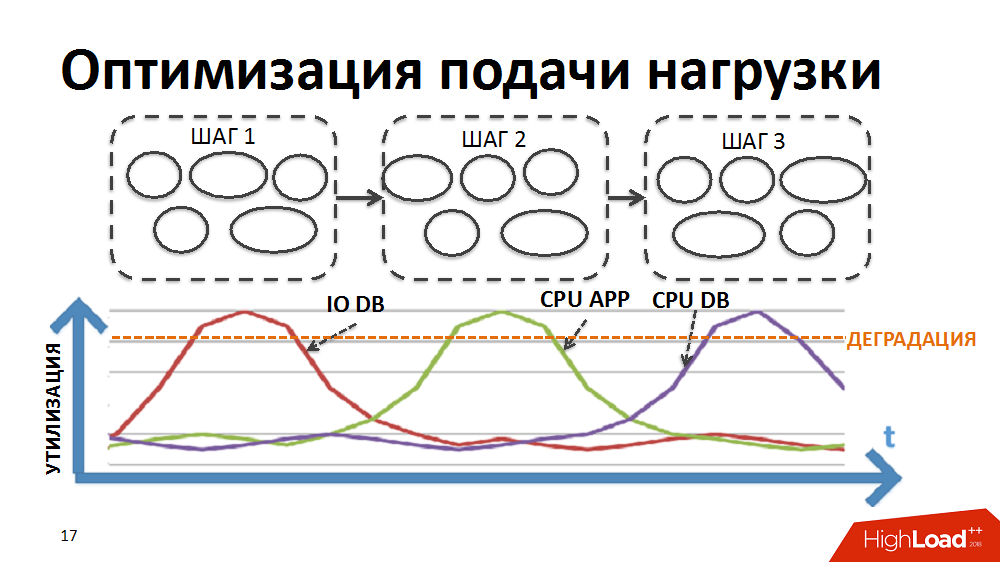
Reescrevemos a lógica do agendador para que a cadeia de pacotes fosse formada separadamente para cada loja e a prioridade do lançamento de novos pacotes fosse construída não por etapas, mas por lojas.
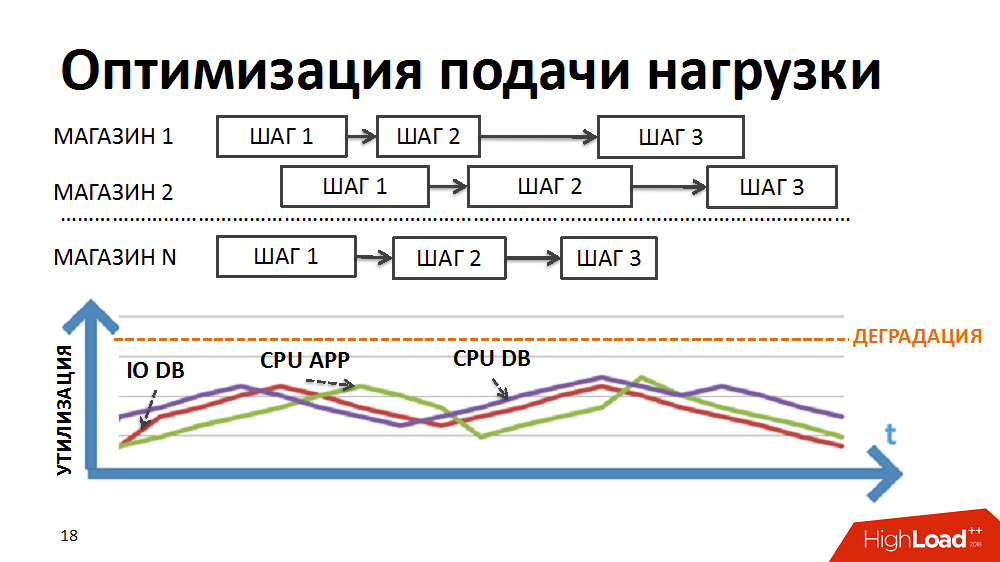
Devido à duração diferente dos pacotes para diferentes lojas e ao grande número controlado de processos executados simultaneamente no âmbito das tarefas do agendador de carga, conseguimos a execução simultânea de processos heterogêneos, carregamento mais suave da carga e eliminação de alguns gargalos.
Então eles começaram a otimizar projetos individuais. Cada pacote individual foi revisado, elaborado com perfil e montado projetos não ideais e abordagens aplicadas para otimizá-los. Posteriormente, essas abordagens foram incluídas nos regulamentos do desenvolvedor para evitar o crescimento indesejável de carga durante o desenvolvimento do sistema. Alguns deles:
- carga excessiva na CPU dos servidores de aplicativos (muitas vezes gerada por algoritmos não lineares no código do programa, por exemplo, a boa e antiga busca linear em loops ou algoritmos não lineares para encontrar interseções de conjuntos de elementos desordenados, etc. para procurar interseções de conjuntos, usamos algoritmos lineares, pré-encomenda de elementos etc.)
- chamadas idênticas ao banco de dados com as mesmas condições no mesmo processo geralmente levam à utilização excessiva da CPU do banco de dados (ele é tratado armazenando em cache os resultados da primeira amostra na memória do programa ou no nível do servidor de aplicativos e usando dados em cache para amostras subsequentes)
- solicitações de junção frequentes (é melhor executá-las, é claro, no nível do banco de dados, mas às vezes nos permitíamos dividi-las em amostras simples, cujo resultado é armazenado em cache, e transferir a lógica de colagem para o aplicativo. Nesses casos, é melhor aquecer o servidor de aplicativos e não o banco de dados. )
- solicitações de junção pesadas, resultando em muitas E / S
Sobre o último em mais detalhes. Nesse caso, o modelo de dados foi traduzido para um formato menos normal. Um exemplo clássico é uma seleção de documentos contábeis para uma data específica para uma loja individual. Muitos funcionários solicitam. A tabela mestre (tabela de cabeçalho) armazena as datas dos documentos, na tabela de posições - a loja e as mercadorias. As consultas mais comuns são uma seleção de todos os documentos de uma loja específica para uma data específica. Com essa solicitação, o filtro por data na tabela de títulos fornece 500 mil registros, o filtro por loja - a mesma quantidade. Ao mesmo tempo, depois de colar em uma loja separada para a data certa, temos um prazo de 3 mil. Independentemente da tabela em que começamos a filtrar e colar dados, sempre obtemos muitas E / S indesejadas.
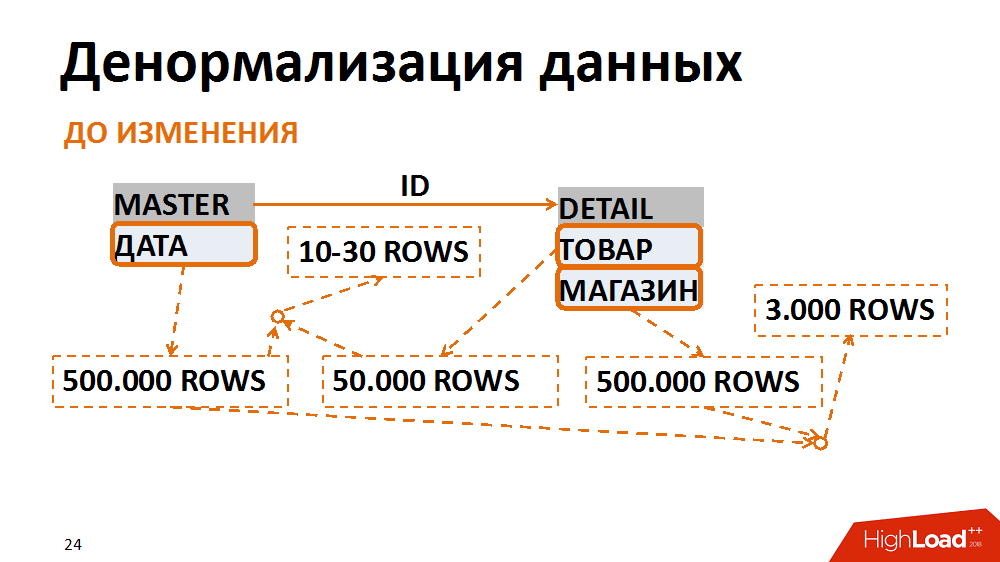
Isso pode ser evitado apresentando os dados de uma forma menos normal. Em um caso, o campo de data foi duplicado na tabela de posições, foi preenchido na criação de documentos, os índices foram coletados para pesquisa rápida e já estavam filtrados de acordo com a tabela de posições. Assim, tendo sacrificado despesas indiretas insignificantes para armazenar um novo campo e índices, reduzimos o número de operações de entrada / saída geradas por consultas problemáticas várias vezes.

2015. O problema de um serviço
Durante um ano e meio, fizemos um ótimo trabalho de otimização do sistema, que se tornou mais previsível. No entanto, os planos para dobrar o número de lojas continuaram relevantes, então os desafios ainda nos enfrentavam.
No caminho, encontramos vários gargalos. Por exemplo, no final de 2015, eles perceberam que haviam descansado no desempenho de um serviço principal da plataforma. Este é um serviço de bloqueio lógico do SAP ABAP. Por causa disso, o sistema claramente não suportaria o crescimento da carga. Perdas de muito dinheiro pairavam no horizonte.
Para esclarecer, a tarefa do serviço é levar a transacionalidade lógica ao nível do servidor de aplicativos. No ABAP, uma única transação pode passar por várias etapas em diferentes fluxos de trabalho. Para que a transação seja concluída, existe um serviço de bloqueio e mecanismos relacionados. As operações de bloqueio e desbloqueio ocorrem rapidamente, mas são atômicas, não podem ser separadas. Houve um problema com E / S síncrona.
O serviço acelerou um pouco depois que os desenvolvedores do SAP lançaram um patch especial, trocamos o serviço por outro hardware e trabalhamos nas configurações do sistema, mas isso ainda não foi suficiente. O teto do serviço de passaporte era de aproximadamente 7 mil operações por segundo e, durante muito tempo, já precisávamos de 10 mil.
Após o teste de carga sintética, verificou-se que a degradação é não linear e, no entanto, estamos no limite de desempenho do serviço acima do qual a degradação inaceitável de todo o sistema ERP é manifestada. Chamadas repetidas para os desenvolvedores deram apenas um veredicto decepcionante - o serviço está funcionando corretamente, apenas exigimos muito na arquitetura atual da solução. Mesmo se nos comprometêssemos imediatamente a refazer toda a arquitetura da solução, levaria vários meses para manter a operacionalidade do sistema atual.
Uma das primeiras opções para tentar estender a vida útil de um serviço de bloqueio é acelerar a E / S e gravar no sistema de arquivos. O que? Experimentos com uma alternativa ao AIX. Transferiu o serviço para o Linux na máquina Power mais poderosa e obteve muito tempo de resposta. O serviço com o sistema de arquivos ativado se comportou da mesma forma que no Aix com os desativados. Em seguida, transferimos esse código para um dos blades x86_64 e obtivemos uma curva de desempenho ainda mais fantástica do que antes. Parecia engraçado.
Pode-se supor que os desenvolvedores do AIX e Linux tenham feito algo diferente no último teste, mas a arquitetura do processador também teve efeito aqui.
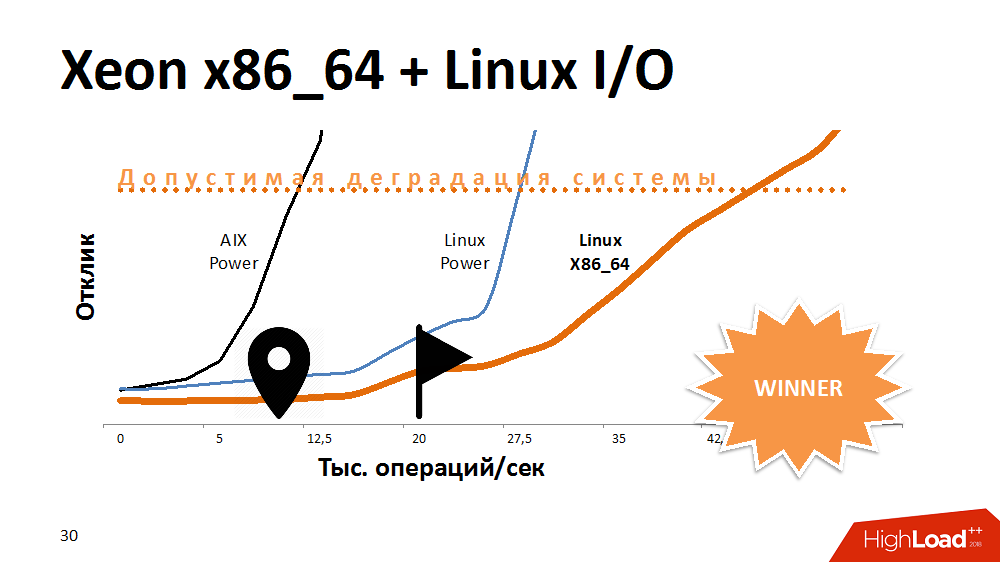
Qual foi a conclusão? Alguma plataforma é ideal para bancos de dados multithread, fornecendo desempenho e tolerância a falhas, mas um processador em uma arquitetura diferente pode lidar melhor com tarefas específicas. Se no início da criação de uma solução para abandonar a plataforma cruzada, você poderá perder espaço para manobras no futuro.
No entanto, descobrimos esse problema e o serviço começou a funcionar 3-4 vezes mais rápido, o que é suficiente para um crescimento muito longo.
2016. Gargalo da CPU do DB
Literalmente seis meses depois, problemas exóticos começaram a ser sentidos com a CPU no banco de dados. Parece claro que, com um aumento na carga, o consumo de recursos do processador aumenta. Mas o SysTime começou a ocupar a maior parte dele, e havia claramente um problema no kernel. Eles começaram a entender, realizar testes de carga sintéticos e perceberam que nosso rendimento era de 300 mil operações por segundo, ou seja, bilhões de solicitações por hora e, em seguida, degradação.
Como resultado, chegamos à conclusão de que o pedido perfeito é aquele que não existe. Expandimos nossa técnica de otimização com novas abordagens e realizamos uma auditoria no sistema ERP: começamos a procurar consultas, por exemplo, com baixa eficiência (100 mil seleções - como resultado de 100 linhas ou 0 em geral) - para refazer. Se as solicitações "vazias" não puderem ser removidas, deixe-as ir para o "cache negativo", se apropriado. Se muitas solicitações para os mesmos dados do produto forem processadas em paralelo, deixe-as atormentar o servidor de aplicativos, e não o banco de dados, armazenamos em cache. Também “ampliamos” um grande número de consultas únicas e frequentes em uma chave na estrutura de um processo, substituindo-a por seleções mais raras de uma parte de uma chave. Ou, por exemplo, para distribuir a carga na cadeia de processamento, diferentes etapas podem ser executadas em diferentes servidores de aplicativos. Isso é bom, mas em estágios diferentes eles podem pedir a mesma coisa da base. Em seguida, deixe a primeira etapa, após iniciar no cache do aplicativo, parte das solicitações, e ela permanece lá para concluir o restante da cadeia.

Com a ajuda de tais truques, vencemos um pouco em todos os lugares, mas no final descarregamos seriamente a base. O sistema ganhou vida. Enquanto isso, descemos para Aix.
Outras experiências revelaram que há um limite de desempenho - as 300.000 chamadas do DataBase já mencionadas por segundo. A raiz do problema foi o desempenho da interface de rede, que tinha um limite - cerca de 300 mil pacotes por segundo em uma direção. À medida que o teto se aproximava, o tempo de chamadas do sistema aumentava. Como se viu depois, também era um legado da pilha de rede do kernel do AIX.
Em geral, nunca tivemos problemas com a latência, o núcleo da rede era produtivo, todos os cabos foram montados em um grande canal indestrutível em uma interface. Fizemos uma solução alternativa: dividimos toda a rede entre servidores de aplicativos e o banco de dados em grupos em diferentes interfaces. Como resultado, cada grupo de servidores de aplicativos se comunicava com o banco de dados por meio de sua própria interface separada. O desempenho máximo de cada interface foi ligeiramente reduzido, mas, no total, fizemos um overclock da rede para 1 milhão de pacotes por segundo em uma direção.
E o princípio "A melhor solicitação é a que não existe" foi adicionado ao Talmud para desenvolvedores, para que isso seja levado em consideração ao escrever o código.
2017. Live to upgrade
Bem, a última etapa da recuperação do nosso sistema, aprovada em 2017. Tudo o que restava era viver um pouco até a atualização e era necessário manter o SLA para nada. O código foi otimizado, mas vimos que quanto maior a carga na CPU do banco de dados, mais lentos os processos funcionam, embora a margem de utilização seja de 10 a 20%. Inicialmente, estimou-se que 100% é o dobro de 50%. E quando há uma reserva de 10 a 20%, é de 10 a 20%. De fato, a uma carga acima de 67-80%, a duração das tarefas aumentou linearmente, ou seja, A lei de Amdahl funcionou. O sistema tinha um limite de paralelização e quando foi excedido, com o envolvimento de um número crescente de processadores no trabalho, o desempenho de cada processador individual diminuiu.
Naquele momento, usamos 125 processadores físicos ou 500 lógicos, considerando o multithreading no nível AIX. O que você sugeriria? Upgrade? Mesmo antes do final de sua coordenação, era necessário aguardar vários meses e não abandonar o SLA.
Em algum momento, eles perceberam que as métricas tradicionais de utilização do processador não são indicativas para nós - elas não mostram o início real da degradação. Para uma avaliação realista da integridade do sistema, começamos a usar a métrica integrada - o resultado de um teste sintético como métrica para o desempenho do processador do banco de dados. Uma vez por minuto, eles fizeram um teste sintético, mediram sua duração e exibiram essa métrica em nossos monitores. E reagiram se a métrica subisse acima do ponto crítico declarado. Mantivemos a carga de nossos planejadores de carga um pouco, para que ela permanecesse na área "torque máximo" do banco de dados.
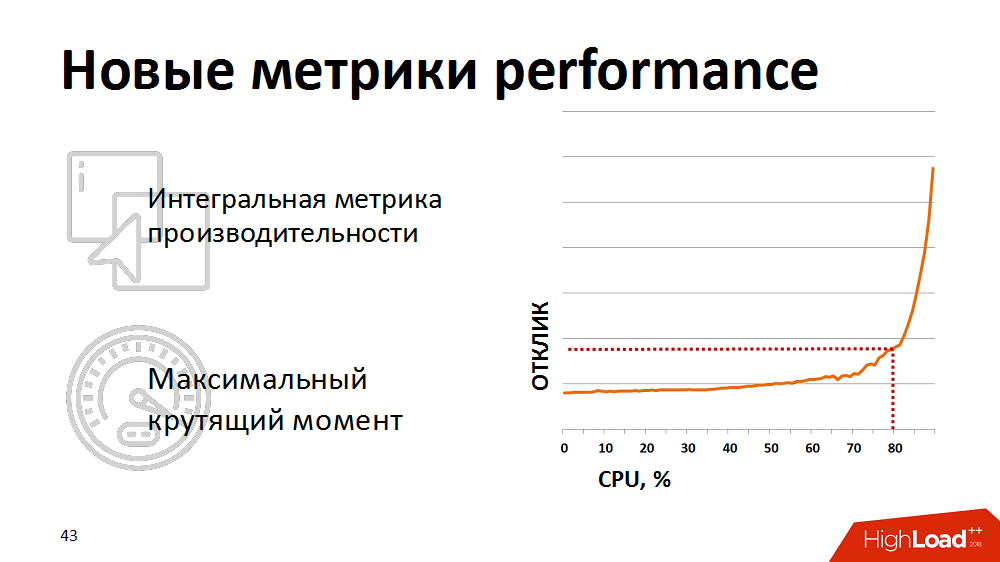
No entanto, o controle manual era ineficaz e estávamos cansados de acordar à noite. Em seguida, reescrevemos o planejador de carga para que ele recebesse feedback sobre as métricas de desempenho atuais. Se as métricas ultrapassassem o limite amarelo (veja a figura), o planejamento de pacotes de baixa prioridade foi congelado e apenas os processos críticos de negócios receberam prioridade. Assim, conseguimos controlar automaticamente a intensidade da carga e os recursos foram utilizados com eficiência. E o mais interessante é que, mantendo o sistema dentro de 80% da carga, na mesma zona de torque máximo, obtivemos uma redução no tempo total para a execução de processos de negócios, porque cada thread começou a trabalhar muito mais rápido.
Algumas dicas para quem trabalha com ERP altamente carregado
- É muito importante monitorar o desempenho dos sistemas no início de um projeto, especialmente com suas próprias métricas.
- Garanta um aumento linear da carga proporcional ao aumento do número de drivers de carga (no nosso caso, eram mercadorias e lojas).
- Elimine construções não lineares no código, use o cache para eliminar consultas idênticas ao banco de dados.
- Se você precisar transferir a carga da CPU do banco de dados para a CPU do servidor de aplicativos, poderá dividir as solicitações de junção em amostras simples.
- Para todas as otimizações, lembre-se de que uma solicitação rápida é boa e, às vezes, uma solicitação rápida e frequente é ruim.
- Tente sempre testar e tirar proveito do ambiente de solução heterogêneo.
- Juntamente com as métricas de desempenho tradicionais, use uma métrica integrada que identifique exclusivamente a degradação; Usando essa métrica, determine a zona de "torque máximo" do seu sistema.
- Forneça às ferramentas de planejamento de carga mecanismos para monitorar as métricas de desempenho atuais e gerenciar taxas de fluxo de carga para usar com eficiência os recursos do sistema
Agradecemos aos organizadores da Highload pela oportunidade de compartilhar essa experiência não apenas em Habré, mas também no palco do maior evento em sistemas altamente carregados.
Dmitry Tsvetkov, Alexander Lishchuk, especialistas em SAP da # ITX5A propósito, a # ITX5 está à procura de consultores da SAP.