
Tudo começou brega - há um ano, minha empresa paga uma taxa mensal por um serviço que sabia como encontrar uma região com placas na foto. Esta função é usada para esboçar números automaticamente para alguns clientes.
E um belo dia, o Ministério da Administração Interna da Ucrânia abriu o acesso ao
registro de veículos . Agora, usando a placa do veículo, tornou-se possível verificar algumas informações sobre o carro (marca, modelo, ano de fabricação, cor, etc.)! A rotina chata da programação linear desapareceu antes de uma nova tarefa - ler números em toda a base de fotos e validar esses dados com aqueles que o usuário especificou. Você mesmo sabe como isso acontece "olhos iluminados" - a ligação foi aceita, todas as outras tarefas ficaram chatas e monótonas por um tempo ... Começamos a trabalhar e obtivemos bons resultados, que, de fato, decidimos compartilhar com a comunidade.
Para referência: ao site AUTO.RIA.com, são adicionadas cerca de 100.000 fotos por dia.
Os dataaentists há muito que sabem e são capazes de resolver esses problemas, então
dimabendera e
eu escrevemos este artigo para programadores. Se você não tem medo da frase “redes convolucionais” e sabe como escrever “Hello World” em python - você é bem-vindo em cat…
Quem mais reconhece
Há um ano, estudei esse mercado e constatamos que poucos serviços e softwares podem funcionar com os números de países exUSSR. Abaixo está uma lista de empresas com as quais trabalhamos:
- Existe uma versão de código aberto e comercial. A versão Opensource apresentava uma taxa de reconhecimento muito baixa, além disso, exigia dependências específicas para sua montagem e operação (não gostamos particularmente). A versão comercial, ou melhor, o serviço comercial funciona bem. Capaz de trabalhar com números russos e ucranianos. Os preços são moderados - 49 $ / 50 mil reconhecimentos por mês. Demonstração on-line do OpenALPR
- Estamos usando este serviço há cerca de um ano. A qualidade é boa Ele encontra a área com o número muito bem. O serviço não sabe trabalhar com números ucranianos e europeus. Vale destacar o bom trabalho com imagens de baixa qualidade (na neve, fotos em baixa resolução, ...). O preço do serviço também é aceitável, mas eles relutam em assumir pequenos volumes.
Existem muitos sistemas comerciais com software fechado, mas não encontramos uma boa implementação de código aberto. De fato, isso é muito estranho, já que as ferramentas de código aberto subjacentes à solução para esse problema existem há muito tempo.
Quais ferramentas são necessárias para reconhecer números
Encontrar objetos em uma imagem ou em um fluxo de vídeo é uma tarefa do campo da visão computacional, resolvida por diferentes abordagens, mas na maioria das vezes com a ajuda das chamadas redes neurais convolucionais. Precisamos encontrar não apenas a área da foto em que o objeto desejado é encontrado, mas também separar todos os seus pontos de outros objetos ou do plano de fundo. Esse tipo de tarefa é chamado "Segmentação de instância". A ilustração abaixo visualiza diferentes tipos de tarefas de visão computacional.
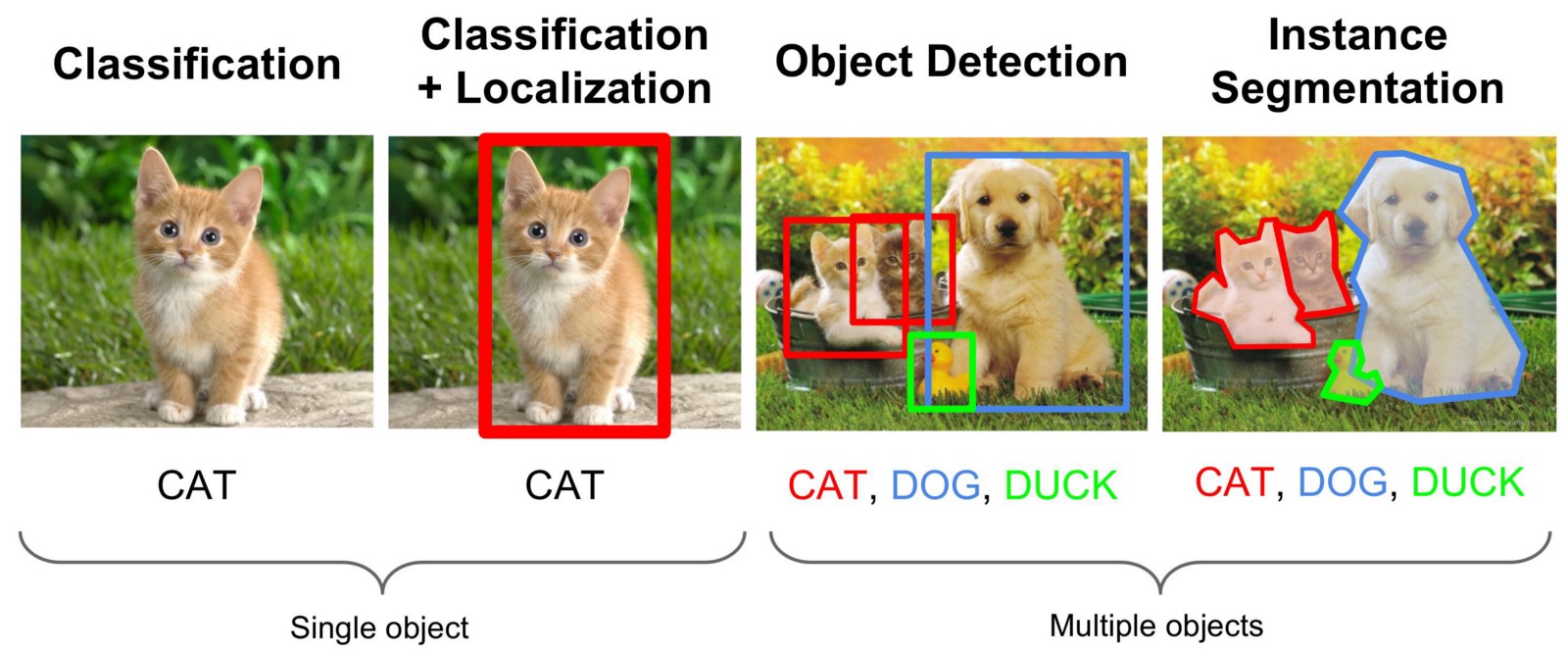
Não vou escrever muita teoria sobre como a rede de convolução funciona, essa informação é suficiente na rede e relatórios no youtube.
Nas arquiteturas modernas de matrizes convolucionais para tarefas de segmentação, elas costumam usar:
U-Net ou
Mask R-CNN . Nós escolhemos Mask R-CNN.
A segunda ferramenta de que precisamos é uma biblioteca de reconhecimento de texto que possa funcionar com diferentes idiomas e que possa ser facilmente personalizada para as especificidades dos textos que reconheceremos. Aqui a escolha não é tão boa, o mais avançado é o
tesseract do Google.
Há também um número menor de ferramentas "globais" com as quais precisaremos normalizar a área com a placa do veículo (traga-a de forma que o reconhecimento de texto seja possível). Normalmente, o opencv é usado para essas conversões.
Além disso, será possível tentar determinar o país e o tipo ao qual o número da placa pertence, para que, no pós-processamento, apliquemos um modelo de refinamento específico para esse país e esse tipo de número. Por exemplo, a matrícula ucraniana, iniciada em 2015, decorada em azul e amarelo, consiste no modelo "duas letras, quatro números, duas letras".

Além disso, tendo estatísticas sobre a frequência de "reunião" nas placas de uma combinação específica de letras ou números, você pode melhorar a qualidade do pós-processamento em situações "controversas". "
Rede Nomeroff
A partir do título do artigo, está claro que todos implementamos e
nomeamos o projeto
Nomeroff Net . Agora, parte do código deste projeto já está trabalhando na produção no
AUTO.RIA.com . Obviamente, ainda está longe de análogos comerciais; tudo funciona bem apenas para números ucranianos. Além disso, uma velocidade aceitável é alcançada apenas com o suporte do tensorflow do módulo GPU! Sem uma GPU, você também pode tentar, mas não no Raspberry Pi :).
Todo o material do nosso projeto: conjuntos de dados marcados e modelos treinados , publicamos publicamente com permissão do RIA.com sob uma licença Creative Commons CC BY 4.0
Do que precisamos
Dmitry e eu estamos rodando no Fedora 28, tenho certeza que tudo pode ser instalado em qualquer outra distribuição Linux. Eu não gostaria de transformar este post em instruções para instalar e configurar o tensorflow, se você quiser tentar e algo não der certo - pergunte nos comentários, responderei e direi.
Para acelerar a instalação, planejamos criar um arquivo docker - esperamos nas próximas atualizações do projeto.
Nomeroff Net "Olá, mundo"
Vamos tentar reconhecer algo. Estamos clonando um
repositório com o código do
github . Fazemos o download na pasta de modelos,
modelos treinados para pesquisar e classificar números, ajustaremos ligeiramente as variáveis com a localização das pastas para nós mesmos.
UPD: este código está obsoleto, ele funcionará apenas
no ramo 0.1.0 ,
veja os exemplos mais recentes aqui :
Tudo pode ser reconhecido:
import os import sys import json import matplotlib.image as mpimg
Demonstração online
Eles esboçaram uma
demonstração simples para quem não deseja instalar e executar tudo isso :). Seja indulgente e paciente com a velocidade do script.
Se você precisar de exemplos de números ucranianos (para verificar a operação dos algoritmos de correção), use um exemplo
nesta pasta.O que vem a seguir
Entendo que o tópico é muito nicho e é improvável que cause grande interesse entre uma ampla gama de programadores. Além disso, o código e os modelos ainda são bastante "brutos" em termos de qualidade de reconhecimento, velocidade, consumo de memória, etc. Mas ainda há esperança de que haja entusiastas quem estará interessado em modelos de treinamento para suas necessidades, seu país, quem ajudará e informará onde há problemas e, juntos, farão com que o projeto não seja pior do que as contrapartes comerciais.
Problemas conhecidos
- O projeto não possui documentação, apenas exemplos básicos de código.
- Como módulo de reconhecimento, o OCR tesseract universal é selecionado e pode ler muito, mas comete muitos erros. No caso do reconhecimento de números ucranianos, um sistema de correção especializado é escrito lá, que até agora compensa alguns dos erros, mas há um palpite de que muito mais pode ser feito aqui.
- Os números "quadrados" (matrículas com proporção de 1: 2) são bastante raros e nós apenas começamos a lidar com eles, portanto haverá mais erros com eles.
- Às vezes, em vez de uma placa, nosso modelo encontra placas de trânsito com o nome da vila, um painel dentro da cabine e outros artefatos.
- Com baixa qualidade do número ou baixa resolução, uma região de 4 pontos não é completamente determinada
Anúncio
Se for interessante para alguém, na segunda parte, falaremos sobre como e como marcar seu conjunto de dados e como treinar seus modelos que podem funcionar melhor para o seu conteúdo (seu país, seu tamanho de foto). Também falaremos sobre como criar seu próprio classificador, o que, por exemplo, ajudará a determinar se o número está esboçado na foto.
Alguns exemplos no caderno Jupyter:
Links úteis