Você já foi solicitado a calcular a quantidade de algo com base nos dados do banco de dados do último mês, agrupando o resultado por alguns valores e dividindo tudo por dia / hora?
Se sim - então você já imagina que precisa escrever algo assim, só que pior
SELECT hour(datetime), somename, count(*), sum(somemetric) from table where datetime > :monthAgo group by 1, 2 order by 1 desc, 2
De tempos em tempos, uma grande variedade de solicitações começa a aparecer e, se você perseverar e ajudar uma vez, infelizmente, surgirão recursos no futuro.
Mas essas solicitações são ruins, pois consomem bem os recursos do sistema em tempo de execução, e pode haver tantos dados que mesmo uma réplica para essas solicitações será uma pena (e é o tempo).
Mas e se eu disser que, no PostgreSQL, você pode criar uma visão de que apenas levará em conta os novos dados recebidos em uma consulta diretamente semelhante, como acima?
Então - ele pode fazer a extensão PipelineDB
Demonstração de seu site como funciona O PipelineDB era anteriormente um projeto separado, mas agora está disponível como uma extensão para o PG 10.1 e superior.
E embora as oportunidades oferecidas existam há muito tempo em outros produtos projetados especificamente para coletar métricas em tempo real, o PipelineDB tem uma vantagem significativa: um limite de entrada mais baixo para desenvolvedores que já conhecem SQL.
Talvez para alguns não seja essencial. Pessoalmente, não tenho preguiça de tentar tudo o que parece adequado para resolver um problema específico, mas não vou me mexer imediatamente para usar uma nova solução para todos os casos. Portanto, neste artigo, não desejo descartar tudo e instalar o PipelineDB imediatamente, isso é apenas uma visão geral da funcionalidade principal, como a coisa me pareceu curiosa.
E assim, em geral, eles têm boa documentação, mas quero compartilhar minha experiência sobre como experimentar esse negócio na prática e trazer os resultados para a Grafana.
Para não desarrumar a máquina local, implanto tudo na janela de encaixe.
Imagens usadas:
postgres:latest ,
grafana/grafanaInstale o PipelineDB no Postgres
Em uma máquina com postgres, execute sequencialmente:
apt updateapt install curlcurl -s http://download.pipelinedb.com/apt.sh | bashapt install pipelinedb-postgresql-11cd /var/lib/postgresql/data- Abra o arquivo
postgresql.conf em qualquer editor - Encontre a chave
shared_preload_libraries , remova o comentário e defina o valor pipelinedb - Chave
max_worker_processes configurada para 128 (estações de recomendação) - Reinicialize o servidor
Criando um fluxo e visualização no PipelineDB
Após a reinicialização pg - observe os logs para que exista uma coisa dessas - O banco de dados no qual trabalharemos:
CREATE DATABASE testpipe; - Criando uma extensão:
CREATE EXTENSION pipelinedb; - Agora, o mais interessante é criar um fluxo. É nele que você precisa adicionar dados para processamento adicional:
CREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
Na verdade, é muito parecido com a criação de uma tabela comum, você não pode obter dados desse fluxo com uma simples select - você precisa de uma visualização - na verdade, como criá-lo:
CREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
Eles são chamados de Visualizações contínuas e padronizados para se materializar, ou seja, com preservação do estado.
A WITH passa parâmetros adicionais.
No meu caso, ttl = '3 month' significa que você precisa armazenar dados apenas nos últimos 3 meses e pegar a data / hora da coluna M O processo do reaper segundo plano reaper dados obsoletos e os exclui.
Para quem não sabe, a função minute retorna uma data / hora sem segundos. Assim, todos os eventos que ocorreram em um minuto terão o mesmo tempo como resultado da agregação. - Essa visualização é quase uma tabela, porque o índice por data para amostragem será útil se muitos dados forem armazenados
create index on viewflow (m desc, action);
Usando o PipelineDB
Lembre-se: insira dados no fluxo e leia a partir da visualização que assina
insert into flow_stream VALUES (now(), 'act1', 21); insert into flow_stream VALUES (now(), 'act2', 33); select * from viewflow order by m desc, action limit 4; select now()
Eu executo a solicitação manualmente Primeiro, assisto como os dados mudam aos 46 minutos
Assim que o 47º chega, o anterior para de atualizar e o minuto atual começa a contar.
Se você prestar atenção ao plano de consulta, poderá ver a tabela original com dados
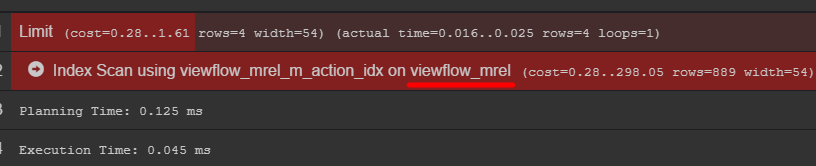
Eu recomendo ir lá e descobrir como seus dados são realmente armazenados
Gerador de Eventos em C # using Npgsql; using System; using System.Threading; namespace PipelineDbLogGenerator { class Program { private static Random _rnd = new Random(); private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" }; static void Main(string[] args) { var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe"; using (var conn = new NpgsqlConnection(connString)) { conn.Open(); while (true) { var dt = DateTime.UtcNow; using (var cmd = new NpgsqlCommand()) { var act = GetAction(); cmd.Connection = conn; cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)"; cmd.Parameters.AddWithValue("dtmsk", dt); cmd.Parameters.AddWithValue("action", act); cmd.Parameters.AddWithValue("duration", GetDuration(act)); var res = cmd.ExecuteNonQuery(); Console.WriteLine($"{res} {dt}"); } Thread.Sleep(_rnd.Next(50, 230)); } } } private static int GetDuration(string act) { var c = 0; for (int i = 0; i < act.Length; i++) { c += act[i]; } return _rnd.Next(c); } private static string GetAction() { return _actions[_rnd.Next(_actions.Length)]; } } }
Conclusão em Grafana
Para obter dados do postgres, você precisa adicionar a fonte de dados apropriada:
Crie um novo painel e adicione um painel do tipo Graph a ele; depois disso, você precisará editar o painel:
Próximo - selecione uma fonte de dados, alterne para o modo de gravação de consultas sql e digite o seguinte:
select m as time,
E então você obtém uma programação normal, é claro, se você iniciou o gerador de eventos
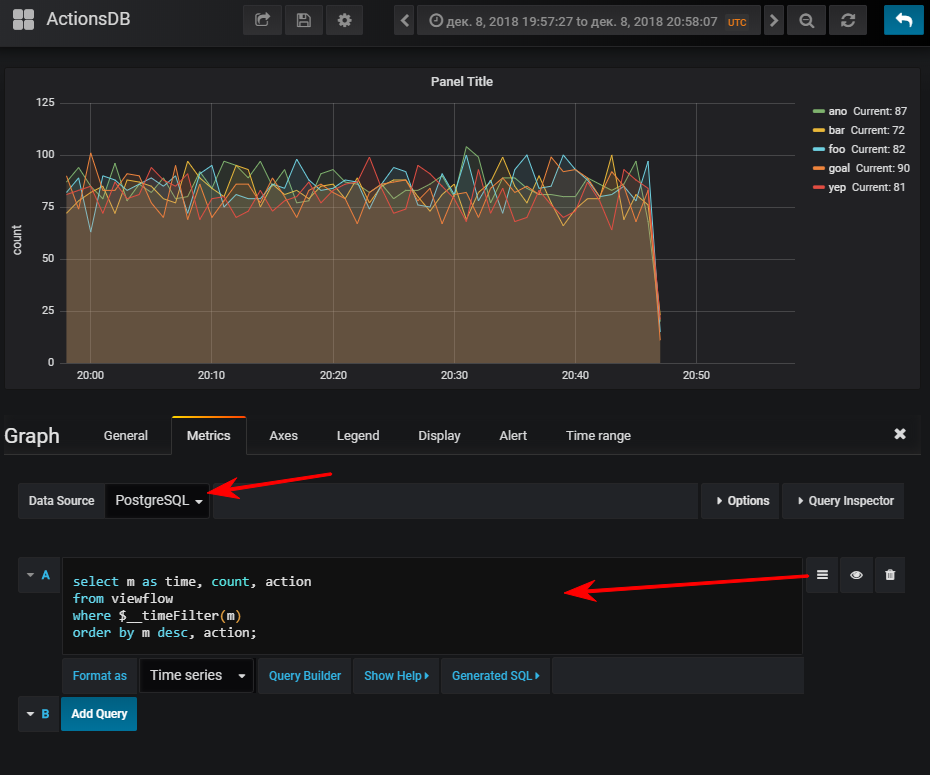
Para sua informação: ter um índice pode ser muito importante. Embora seu uso dependa do volume da tabela resultante. Se você planeja armazenar um pequeno número de linhas em um curto período de tempo, pode ser muito fácil descobrir que a verificação seq será mais barata e o índice adicionará apenas extra. carregar ao atualizar valores
Várias visualizações podem ser inscritas em um fluxo.
Suponha que eu queira ver quantos métodos de API são executados por percentis
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS select minute(dtmsk) m, action, percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50, percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95, percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99 from flow_stream group by 1, 2; create index on viewflow_per (m desc);
Eu faço o mesmo truque com grafana e obtenho: Total
Em geral, a coisa está funcionando, comportou-se bem, sem queixas. Embora sob a janela de encaixe, o download do banco de dados demo no arquivo morto (2,3 GB) acabou sendo um pouco longo.
Quero observar - não realizei testes de estresse.
Documentação oficialPode ser interessante