
Nos dias 6 e 7 de dezembro, a quinta conferência Heisenbag foi realizada em Moscou.
O slogan dela é “Teste. Não apenas para testadores! ”, E por dois anos de visitas regulares aos Heisenbags, eu (anteriormente desenvolvedor Java, agora líder técnico em uma pequena empresa que nunca havia trabalhado em controle de qualidade), aprendi muito em testes e implementou muito em nossa equipe. Quero compartilhar uma revisão subjetiva dos relatórios que me lembro dessa vez.
Isenção de responsabilidade. Obviamente, essa é apenas uma pequena fração (8 em 30) dos relatórios selecionados com base em minhas preferências pessoais. Quase todos esses relatórios estão de alguma forma relacionados ao Java e não há um único sobre desenvolvimento front-end e móvel. Em alguns lugares, me permitirei uma polêmica com o orador. Se você estiver interessado em uma revisão mais completa e neutra, por tradição, ela deve aparecer
no blog dos organizadores . Mas, talvez, seja interessante para alguém descobrir exatamente sobre esses relatórios que eles não puderam acessar.
As fotos do artigo são do twitter oficial da conferência.Baruch Sadogursky. Temos DevOps. Vamos demitir todos os testadores
 (Na foto - o hype quando Baruch distribuiu o livro Liquid Software )
(Na foto - o hype quando Baruch distribuiu o livro Liquid Software )Aqueles envolvidos em Java e participando de conferências do Grupo JUGRU, Baruch Sadogursky não precisa de apresentações. No entanto, ele se apresentou pela primeira vez no Heisenbug.
Em poucas palavras - foi um relatório de revisão sobre as principais idéias do DevOps. A necessidade do público por esses relatórios permanece, porque, quando perguntados "Dê a definição de DevOps" ao público, as pessoas ainda respondem antes de tudo "Esta é uma pessoa ..."
Mas mesmo aqueles que já aprenderam algo sobre esse assunto, será muito interessante aprender sobre os estudos da associação DORA
devops-research.com , que recebeu porcentagens de variedades de trabalho manual em equipes com desempenho diferente. E sobre a curva que liga a velocidade e a qualidade da entrega (em algum momento, a velocidade diminui, porque precisamos de tempo para "testar melhor", mas à medida que a equipe se desenvolve, a correlação se torna direta):
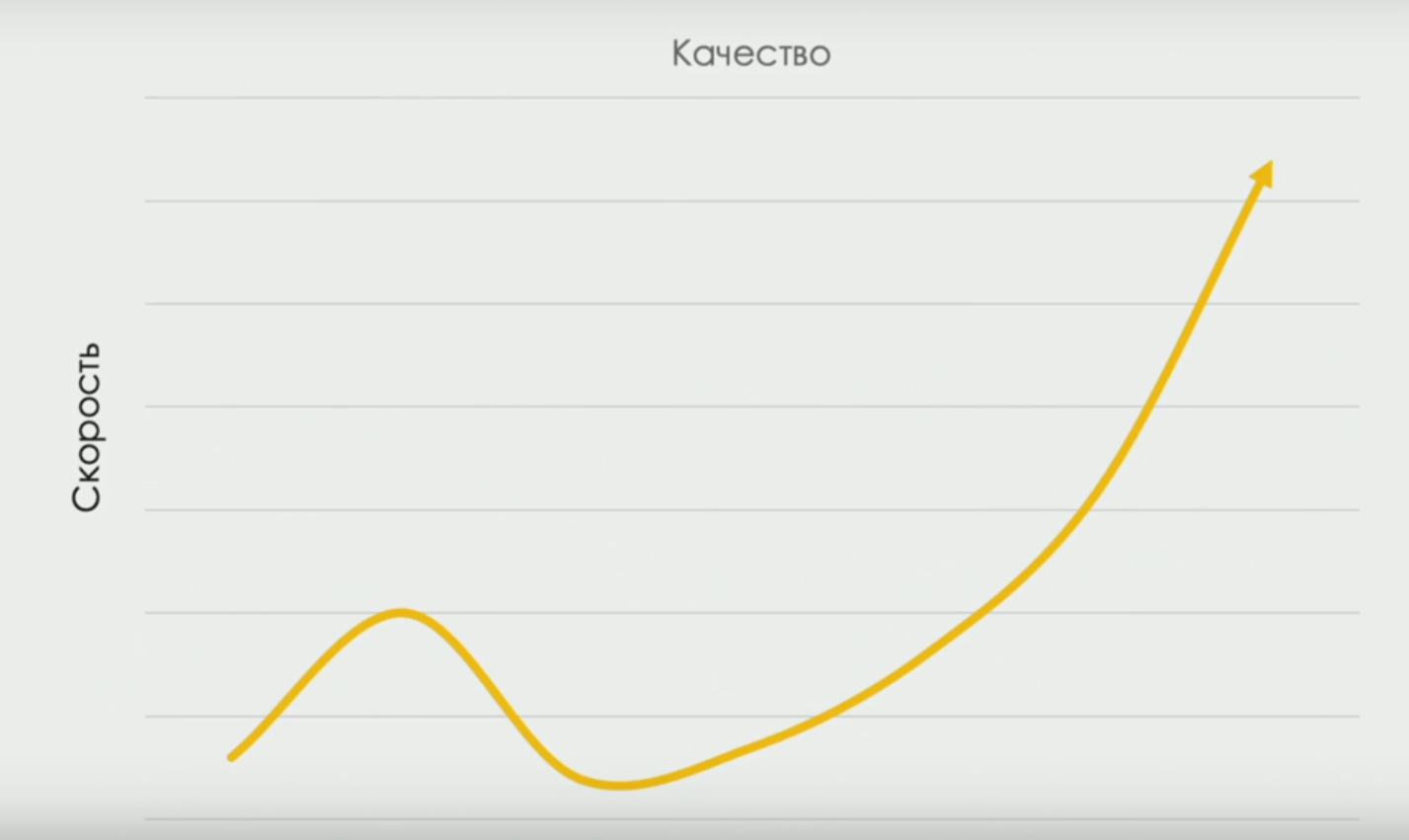
Embora o título do relatório tenha sido provocativo e, no cronograma, o relatório tenha sido marcado com a categoria “queimará”, seu conteúdo, na minha opinião, era bastante popular. Evidentemente, não se tratava da demissão de testadores sob as condições da transformação do Devops, mas de uma mudança na natureza do trabalho dos testadores.
Alan Page e Nikolai Alimenkov falaram muito sobre essas coisas há um ano. Tanto a mudança de papéis quanto o desenvolvimento “horizontal” de habilidades em forma de T foram discutidos há um ano na mesa redonda “o
que um testador deve saber em 2018 ”.
“Claro, se você não quer mudar, há trabalho para você, embora não seja tão interessante. Até o momento, ainda há trabalho para quem deseja dar suporte a sistemas escritos em COBOL nos anos 70 ”, disse Baruch.
Artyom Eroshenko. Precisa refatorar um projeto? Tenha uma IDÉIA!

Artyom está familiarizado com os participantes da Heisenbag com relatórios sobre o sistema de relatórios Allure (por exemplo,
aqui está seu relatório sobre as oportunidades da Allure que apareceram em 2018 a partir da Heisenbug anterior em São Petersburgo). O próprio Allure nasceu no contexto de projetos com milhares, dezenas de milhares e até mais de centenas de milhares de testes e foi projetado para simplificar a interação entre desenvolvedores e testadores. Ele tem a capacidade de vincular testes a recursos externos, como sistemas de emissão de bilhetes e confirmações no sistema de controle de versão. Em nossa micro equipe, enquanto a contagem de testes passou apenas por dezenas, lidamos completamente com os meios padrão. Mas como o número de testes em um dos produtos atingiu 700 e a tarefa geral era criar relatórios de alta qualidade para os clientes, comecei a olhar para o Allure.
No entanto, este relatório não era sobre Allure, embora também sobre ele.
Artyom convenceu o público de que escrever plugins para o IntelliJ IDEA é uma atividade simples e fascinante. Por que isso seria necessário? Para automatizar a modificação do código em massa. Por exemplo, para converter um grande número de códigos-fonte de JUnit4 em JUnit5. Ou do uso do Allure 1 ao Allure 2. Ou para automatizar a marcação dos testes com a comunicação com o sistema de marcação.
Quem trabalha com o IDEA sabe quais truques ele pode fazer com o código (por exemplo, traduza automaticamente o código usando loops para código usando o Java Streams e vice-versa, ou traduza instantaneamente o Java para o Kotlin). Quanto mais interessante foi ver como é aberto o véu de sigilo sobre as transformações de código no IDEA, somos convidados a participar disso e a criar nossos próprios plugins para nossas necessidades exclusivas. Na próxima vez, quando precisar fazer algo com uma grande base de códigos, lembrarei deste relatório e verei como ele pode ser automatizado usando um plug-in genérico no IDEA.
Kirill Merkushev. Projeto Java e Reactor - e os testes?

Parece-me que esse relatório poderia ter sido realizado nas conferências Joker ou JPoint Java. Kirill falou sobre como ele usa a estrutura
projectreactor.io em uma arquitetura de microsserviço com um único log de eventos (Kafka), um pouco sobre a essência da codificação em "fluxos reativos", incluindo como os aplicativos que usam essa estrutura podem ser depurados e testados.
A vida também está incentivando nossa equipe a usar a arquitetura com um único log de eventos, e também analisamos o Kafka. É verdade que, para eventos de streaming, estamos experimentando a API Kafka Streams (onde, ao que me parece, mais coisas como processamento com estado são implementadas de forma transparente para o desenvolvedor) e não o Reator. No entanto, como sempre acontece com as novas tecnologias, o "rake" e as "armadilhas" não são conhecidos antecipadamente. Portanto, era importante ouvir a história de um especialista que já está trabalhando com tecnologia.
Leonid Rudenko. Gerenciando um cluster Selenoid com Terraform

Se o relatório anterior lembrava uma conferência da JPoint, este certamente é sobre o
DevOops . Leonid falou sobre como usar as especificações do Terraform para aumentar e configurar um cluster Selenoid. Sobre o que o próprio Selenoid era, havia
um relatório sobre o Heisenbug do ano passado - é um rico sistema distribuído que funciona como um serviço elástico e permite executar um grande número de testes de Selenium em vários navegadores. Como qualquer sistema que exija implantação em várias máquinas, a instalação manual do Selenoid é difícil. Aqui, os sistemas modernos de configuração como código são úteis.
Leonid fez uma visão geral bastante detalhada dos recursos do Terraform - um sistema que provavelmente não era familiar para a maioria do público, mas na verdade já era bem conhecido pela automação do DevOps (por exemplo, na conferência Devoops-2018, houve
um excelente relatório de Anton Babenko sobre as melhores práticas para criar e manter o código Terraform). Além disso, foi mostrado como usar os scripts do Terraform para descrever os parâmetros dos contêineres do docker com o Selenoid para cada uma das máquinas no cluster e os parâmetros das próprias máquinas virtuais do cluster.
Embora o caso específico considerado por Leonid possa certamente facilitar a tarefa de implantar o Selenoid, não concordo com o orador em tudo. Essencialmente, ele usa o Terraform para duas tarefas diferentes: criar recursos e configurá-los. E isso leva ao fato de que Leonid é forçado a lançar o Terraform uma vez para criar máquinas virtuais e mais uma vez para cada uma das máquinas virtuais elevar contêineres de docker sobre elas. Na minha opinião, o Terraform, que resolve bem o problema de criar recursos, não resolve muito bem o problema de configuração. Seria possível evitar a multiplicação de projetos de terraform e seu lançamento repetido usando sistemas de configuração especiais, por exemplo, Ansible ou outras soluções.
Mas, em geral, como um "programa educacional" para testadores no campo de Infraestrutura como Código, este relatório é muito útil.
Andrey Markelov. Teste de integração elegante do zoológico de microsserviço com TestContainers e JUnit 5 usando o exemplo da plataforma global de SMS

E novamente sobre microsserviços! Desta vez, a conversa foi sobre como executar testes que exigem o lançamento e a interação de vários serviços ao mesmo tempo. A JUnit5, com seu
sistema de extensão e a conhecida (e excelente) estrutura TestContainers, foi proposta como base da solução (consulte, por exemplo,
o relatório do ano passado de Sergey Egorov ).
Se você está escrevendo algo em Java e ainda não sabe o que é o TestContainers, recomendo com urgência que você o estude. O TestContainers permite, usando a tecnologia Docker, diretamente no código de teste, coletar bancos de dados reais e outros serviços, conectá-los pela rede e, como resultado, executar testes de integração no ambiente criado no momento em que os testes foram iniciados e destruídos imediatamente após. Ao mesmo tempo, tudo funciona diretamente do código Java, se conecta como uma dependência do Maven e não requer a instalação de nada além do Docker na máquina / servidor de IC do desenvolvedor. Estamos usando o TestContainers há mais de um ano.
Andrei mostrou um exemplo bastante impressionante de como você pode especificar a configuração do ambiente de teste para testes de ponta a ponta usando as extensões JUnit5, anotações personalizadas e TestContainers. Por exemplo, escrevendo anotações sobre seu teste (código condicional)
@Billing @Messaging
podemos, relativamente falando, escrever
@Test void systemIsDoingRightThings(BillingService b, MessagingService m) {...}
nos parâmetros pelos quais as interfaces Java serão passadas através das quais você pode se comunicar com serviços reais gerados (despercebidos pelo desenvolvedor de teste) em contêineres.
Esses exemplos parecem muito elegantes. Para mim, como usuário ativo do TestContainers e JUnit 5, eles são compreensíveis e relativamente fáceis de implementar.
Mas, em geral, com essa abordagem, a grande questão permanece por resolver, relacionada ao fato de que a maneira de configurar os sistemas de teste e produção é fundamentalmente diferente.
A implementação de lançamentos rápidos na produção sem medo de quebrar tudo é possível apenas se durante o teste de ponta a ponta, não apenas o sistema inteiro tiver sido testado, mas também a maneira de configurá-lo. Se executássemos repetidamente o script de implantação do sistema durante o processo de desenvolvimento e teste, não teríamos dúvida de que esse script funcionaria mesmo quando iniciado na produção. A função do código que configura o ambiente de teste no exemplo de Andrey é desempenhada por anotações. Mas, na produção, organizamos o sistema usando um código completamente diferente - Ansible, Kubernetes, qualquer coisa - não envolvido de forma alguma com esse teste do sistema. E isso limita esses testes, que não são completamente de ponta a ponta.
Andrey Glazkov. Testando sistemas com dependências externas: problemas, soluções, Mountebank

Para aqueles para quem o tópico deste relatório é relevante, recomendo que você assista também a uma
brilhante apresentação de Andrei Solntsev sobre uma abordagem baseada em princípios para testar sistemas que dependem de serviços externos. Solntsev fala de maneira convincente sobre a necessidade de usar zombarias de sistema externo para testes abrangentes. E Andrei Glazkov, em seu relatório, descreve um dos sistemas para esse molhamento - o Mountebank, escrito no NodeJS.
Você pode elevar o Mountebank como servidor e "treinar" as respostas às solicitações pela rede de maneira semelhante à forma como treinamos as simulações de interface ao escrever testes de unidade. A única diferença é que é uma simulação de um serviço de rede. Um caso curioso de usar o Mountebank é a capacidade de usá-lo como proxy - enviando algumas solicitações para um sistema externo real.
Deve-se notar aqui que eu recomendaria que os desenvolvedores Java (e Andrei concordaram na área de discussão) também procurem a biblioteca WireMock, que é criada em Java e pode ser executada no modo incorporado, ou seja, diretamente dos testes sem instalar nenhum Serviços para a máquina do desenvolvedor ou servidor de IC (embora também possa funcionar como um servidor independente). Como o Mountebank, o WireMock suporta o modo proxy. Temos alguma experiência positiva com o WireMock.
A vantagem do Mountebank, no entanto, é o suporte a protocolos de nível inferior (o WireMock funciona apenas para HTTP) e a capacidade de trabalhar em um "zoológico" de diferentes tecnologias (existem bibliotecas para diferentes idiomas para o Mountebank).
Kirill Tolkachev. Testando e chorando com o Spring Boot Test

E novamente Java, microsserviços e JUnit 5. Kirill é outro orador das conferências Joker e JPoint, bem conhecidas da comunidade Java, que falaram pela primeira vez na Heisenbug.
Este relatório é uma versão modificada do relatório
Spring Curse do ano passado, com exemplos modificados para JUnit5 e Spring Boot 2. Vários problemas práticos relacionados à configuração de testes do Spring Boot em testes de componentes / microsserviços são examinados em profundidade. Por exemplo, fiquei impressionado com o exemplo de usar o
@SpringBootConfiguration StopConfiguration vazio no lugar certo na árvore de origem para interromper o processo de verificação da configuração, bem como a possibilidade de usar
@MockBean e
@SpyBean vez de zombarias. Como outros relatórios de Cyril e Evgeny Borisov, este é um material que faz sentido retornar ao processo de uso prático do Spring Framework.
Andrey Karpov. O que os analisadores estáticos podem fazer, o que os programadores e testadores não podem

A análise de código estático é uma coisa boa. De acordo com os cânones da Entrega Contínua, deve ser a primeira fase do pipeline de entrega, filtrando o código com problemas que podem ser detectados pela "leitura" do código. A análise estática é boa porque é rápida (muito mais rápida que os testes) e barata (não requer esforços adicionais da equipe na forma de escrever testes: todas as verificações já foram escritas pelos autores do analisador).
Andrey Karpov, um dos fundadores do projeto PVS-Studio (familiar aos leitores da Habr em seu
blog ) criou um relatório sobre exemplos de quais erros na análise de código de produtos conhecidos foram encontrados usando o PVS-Studio. O PVS Studio em si é um produto poliglota, suporta C, C ++, C # e, mais recentemente, Java.
Apesar de os exemplos acima serem interessantes e a utilidade da análise estática deles ser óbvia, na minha opinião, o relatório de Andrey apresentava falhas.
Em primeiro lugar, o relatório foi elaborado exclusivamente com base no produto PVS-Studio (para o qual, segundo o orador, "o preço médio é de US $ 10.000"). Mas vale a pena mencionar que, de fato, em muitos idiomas existem muitos sistemas de análise estática OpenSource desenvolvidos. Somente em Java - o Checkstyle e o SpotBugs gratuitos (o sucessor do projeto FindBugs congelado), bem como o analisador IntelliJ IDEA, que pode ser executado separadamente do IDE e receber um relatório, fizeram um tremendo progresso.
Em segundo lugar, falando em análise estática, parece-me que sempre vale a pena mencionar as limitações fundamentais desse método. Nem todo mundo passou pela teoria dos algoritmos na universidade e está familiarizado com o "problema do desligamento", por exemplo.
E, finalmente, os problemas de introdução da análise estática na base de códigos existente não foram levantados, o que ainda impede muitos do uso regular de analisadores em projetos. Por exemplo, executamos o analisador em um grande projeto herdado e encontramos 100.500 vorings. Não há tempo e esforço para corrigi-los no local, e alterar massivamente algo no código é um risco. O que fazer com isso, como fazer a análise estática funcionar como uma porta de qualidade? Esse problema foi discutido na área de discussão com Andrei, mas esse problema não foi considerado no próprio relatório.
Em geral, desejo a Andrey e sua equipe todo sucesso. Seu produto é interessante e a idéia de ocupar seu nicho nessa área é muito ousada.
***
Talvez eu não diga nada sobre as notas finais do primeiro e do segundo dia: ambos eram programas de direitos autorais que você só precisa assistir. Falar sobre eles é como recontar palavras, por exemplo, uma performance de uma banda de rock.
No meu relatório de um
ano atrás, eu já tentei transmitir a atmosfera geral da conferência e falei sobre o que está acontecendo nas áreas de discussão, no almoço e na festa, para não me repetir.
Concluindo, gostaria de agradecer aos organizadores por outra conferência lindamente realizada. Pelo que entendi, o interesse na conferência excedeu um pouco as expectativas, houve algumas reservas em excesso e nem todos tinham lembranças suficientes. Mas, com certeza, todos tinham coisas mais importantes: relatórios interessantes, espaço para discussões, alimentos e bebidas. Estou ansioso para novas reuniões!