
Na continuação de nossos artigos práticos sobre como facilitar a vida no trabalho diário com o Kubernetes, falamos sobre duas histórias do mundo das operações: a alocação de nós individuais para tarefas específicas e a configuração do php-fpm (ou outro servidor de aplicativos) para cargas pesadas. Como antes, as soluções descritas aqui não afirmam ser ideais, mas são oferecidas como ponto de partida para seus casos específicos e base para reflexão. Perguntas e melhorias nos comentários são bem-vindas!
1. A alocação de nós individuais para tarefas específicas
Estamos criando um cluster Kubernetes em servidores virtuais, nuvens ou servidores bare metal. Se você instalar todo o software do sistema e aplicativos clientes nos mesmos nós, é provável que ocorram problemas:
- o aplicativo cliente de repente começará a "vazar" da memória, embora seus limites sejam muito altos;
- solicitações complexas únicas para loghouse, Prometheus ou Ingress * levam ao OOM, como resultado do aplicativo cliente;
- um vazamento de memória devido a um bug no software do sistema mata o aplicativo cliente, embora os componentes possam não estar logicamente conectados entre si.
* Entre outras coisas, era relevante para versões mais antigas do Ingress, quando, devido ao grande número de conexões de websocket e recarregamentos constantes do nginx, "processos pendentes do nginx" apareceram, que chegaram a milhares e consumiram uma enorme quantidade de recursos.O caso real é com a instalação do Prometheus com um grande número de métricas, nas quais, ao visualizar o painel "pesado", onde é apresentado um grande número de contêineres de aplicativos, a partir de cada um dos gráficos, o consumo de memória rapidamente cresceu para ~ 15 GB. Como resultado, o OOM killer poderia "entrar" no sistema host e começar a matar outros serviços, o que por sua vez levou a "um comportamento incompreensível dos aplicativos no cluster". E devido à alta carga de CPU no aplicativo cliente, é fácil obter um tempo instável de processamento de consultas do Ingress ...
A solução rapidamente surgiu: era necessário alocar máquinas individuais para diferentes tarefas. Identificamos três tipos principais de grupos de tarefas:
- Frentes , onde colocamos apenas o Ingresss, para garantir que nenhum outro serviço possa afetar o tempo de processamento das solicitações;
- Nós do sistema nos quais implantamos VPNs , loghouse , Prometheus , Dashboard, CoreDNS, etc;
- Nós para aplicativos - na verdade, onde os aplicativos clientes são lançados. Eles também podem ser alocados para ambientes ou funcionalidades: dev, prod, perf, ...
Solução
Como implementamos isso? Muito simples: dois mecanismos nativos do Kubernetes. O primeiro é o
nodeSelector para selecionar o nó desejado para onde o aplicativo deve ir, com base nos rótulos
instalados em cada nó.
Digamos que temos um
kube-system-1 . Adicionamos um rótulo adicional a ele:
$ kubectl label node kube-system-1 node-role/monitoring=
... e em
Deployment , que deve ser implementada neste nó, escrevemos:
nodeSelector: node-role/monitoring: ""
O segundo mecanismo são
tensões e tolerâncias . Com sua ajuda, indicamos explicitamente que nessas máquinas somente os contêineres podem ser lançados com tolerância a essa contaminação.
Por exemplo, existe uma
kube-frontend-1 na qual apenas
kube-frontend-1 Ingress. Inclua mácula neste nó:
$ kubectl taint node kube-frontend-1 node-role/frontend="":NoExecute
... e na
Deployment , criamos tolerância:
tolerations: - effect: NoExecute key: node-role/frontend
No caso de kops, grupos de instâncias individuais podem ser criados para as mesmas necessidades:
$ kops create ig --name cluster_name IG_NAME
... e você obtém algo como esta configuração de grupo de instâncias no kops:
apiVersion: kops/v1alpha2 kind: InstanceGroup metadata: creationTimestamp: 2017-12-07T09:24:49Z labels: dedicated: monitoring kops.k8s.io/cluster: k-dev.k8s name: monitoring spec: image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14 machineType: m4.4xlarge maxSize: 2 minSize: 2 nodeLabels: dedicated: monitoring role: Node subnets: - eu-central-1c taints: - dedicated=monitoring:NoSchedule
Portanto, os nós desse grupo de instâncias adicionam automaticamente um rótulo e uma mancha adicionais.
2. Configurando php-fpm para cargas pesadas
Existe uma grande variedade de servidores que são usados para executar aplicativos da Web: php-fpm, gunicorn e similares. Seu uso no Kubernetes significa que há várias coisas em que você deve sempre pensar:
- É necessário entender aproximadamente quantos trabalhadores estamos dispostos a alocar em php-fpm em cada contêiner. Por exemplo, podemos alocar 10 trabalhadores para processar solicitações de entrada, alocar menos recursos para pod e escalar com o número de pods - essa é uma boa prática. Outro exemplo é alocar 500 trabalhadores para cada pod e ter 2-3 desses pods em produção ... mas essa é uma péssima idéia.
- Testes de vida útil / prontidão são necessários para verificar a operação correta de cada pod e, caso o pod esteja bloqueado devido a problemas de rede ou devido ao acesso ao banco de dados (pode haver alguma das suas opções e motivo). Em tais situações, você precisa recriar o pod problemático.
- É importante registrar explicitamente a solicitação e limitar os recursos para cada contêiner, para que o aplicativo não "flua" e não comece a prejudicar todos os serviços neste servidor.
Soluções
Infelizmente,
não existe uma bala de prata que o ajude a entender imediatamente quantos recursos (CPU, RAM) um aplicativo pode precisar. Uma opção possível é observar o consumo de recursos e sempre selecionar os valores ideais. Para evitar kill'ov injustificado do OOM e limitação da CPU, que afetam bastante o serviço, você pode oferecer:
- adicione os testes corretos de disponibilidade / prontidão para garantir que este contêiner esteja funcionando corretamente. Provavelmente, será uma página de serviço que verifica a disponibilidade de todos os elementos de infraestrutura (necessários para que o aplicativo funcione no pod) e retorna um código de resposta 200 OK;
- selecione corretamente o número de trabalhadores que processarão solicitações e distribua-as corretamente.
Por exemplo, temos 10 pods que consistem em dois contêineres: nginx (para enviar solicitações estáticas e de proxy ao back-end) e php-fpm (na verdade, o back-end, que processa páginas dinâmicas). O pool de php-fpm está configurado para um número estático de trabalhadores (10). Assim, em uma unidade de tempo, podemos processar 100 solicitações ativas para back-end. Deixe cada solicitação ser processada pelo PHP em 1 segundo.
O que acontece se mais uma solicitação chegar em um pod específico, no qual 10 solicitações estão sendo processadas ativamente agora? O PHP não poderá processá-lo e o Ingress o enviará para tentar novamente no próximo pod, se for uma solicitação GET. Se houve uma solicitação POST, ele retornará um erro.
E se levarmos em conta que, durante o processamento de todas as 10 solicitações, receberemos uma verificação do kubelet (sonda liveness), ela terminará com um erro e o Kubernetes começará a pensar que algo está errado com esse contêiner e o matará. Nesse caso, todas as solicitações processadas no momento terminarão com um erro (!). No momento da reinicialização do contêiner, ele ficará desequilibrado, o que implicará em um aumento nas solicitações de todos os outros back-ends.
Claramente
Suponha que tenhamos 2 pods, cada um com 10 trabalhadores de php-fpm configurados. Aqui está um gráfico que exibe informações durante o "tempo de inatividade", ou seja, quando o único solicitante do php-fpm é o exportador do php-fpm (temos um trabalhador ativo cada):
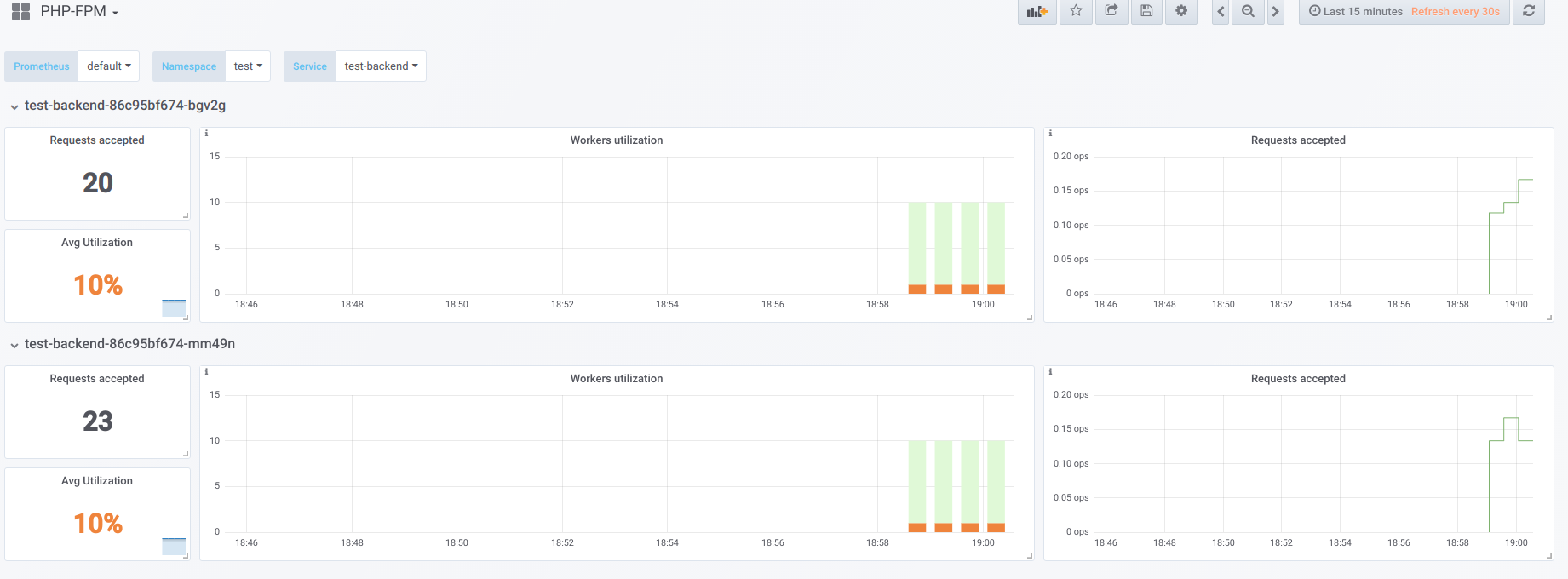
Agora inicie a inicialização com a concorrência 19:
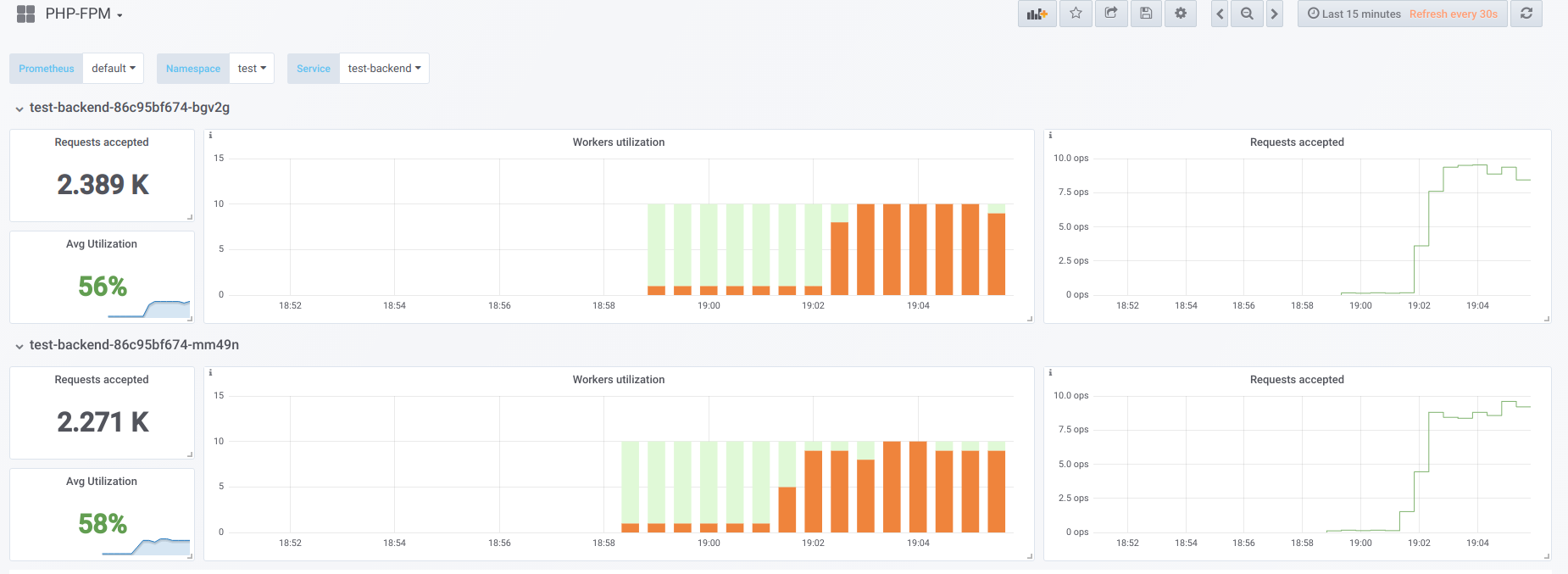
Agora vamos tentar aumentar a simultaneidade do que conseguimos (20) ... digamos 23. Então todos os trabalhadores de php-fpm estão ocupados processando solicitações de clientes:

Os vorkers não são mais suficientes para processar uma amostra de vivacidade, por isso, vemos esta imagem no painel do Kubernetes (ou
describe pod ):

Agora, quando um dos pods é reiniciado,
ocorre um
efeito de avalanche : as solicitações começam a cair no segundo pod, que também não é capaz de processá-las, devido ao qual recebemos um grande número de erros dos clientes. Depois que os pools de todos os contêineres estão cheios, aumentar o serviço é problemático - isso só é possível por um aumento acentuado no número de pods ou trabalhadores.
Primeira opção
Em um contêiner com PHP, você pode configurar conjuntos de 2 fpm: um para processar solicitações de clientes e outro para verificar a capacidade de sobrevivência do contêiner. Em seguida, no contêiner nginx, você precisará fazer uma configuração semelhante:
upstream backend { server 127.0.0.1:9000 max_fails=0; } upstream backend-status { server 127.0.0.1:9001 max_fails=0; }
Tudo o que resta é enviar a amostra de animação para processamento para o upstream chamado
backend-status .
Agora que o probe liveness é processado separadamente, ainda ocorrerão erros em alguns clientes, mas pelo menos não há problemas associados à reinicialização do pod e à desconexão do restante dos clientes. Assim, reduziremos bastante o número de erros, mesmo que nossos back-end não consigam lidar com a carga atual.
Essa opção, é claro, é melhor que nada, mas também é ruim porque algo pode acontecer com o pool principal, que não saberemos sobre o uso do teste de animação.
Segunda opção
Você também pode usar o módulo nginx não muito popular chamado
nginx-limit-upstream . Então, no PHP, especificaremos 11 trabalhadores e, no contêiner com nginx, faremos uma configuração semelhante:
limit_upstream_zone limit 32m; upstream backend { server 127.0.0.1:9000 max_fails=0; limit_upstream_conn limit=10 zone=limit backlog=10 timeout=5s; } upstream backend-status { server 127.0.0.1:9000 max_fails=0; }
No nível do frontend, o nginx limitará o número de solicitações que serão enviadas ao backend (10). Um ponto interessante é que um backlog especial é criado: se a 11ª solicitação de nginx vier do cliente e o nginx perceber que o pool php-fpm está ocupado, essa solicitação será colocada no backlog por 5 segundos. Se, durante esse período, o php-fpm não for liberado, somente o Ingress entrará em ação, o que tentará novamente a solicitação para outro pod. Isso suaviza a imagem, já que sempre teremos 1 trabalhador PHP grátis para processar uma amostra dinâmica - podemos evitar o efeito de avalanche.
Outros pensamentos
Para opções mais versáteis e bonitas para resolver esse problema, vale a pena procurar na direção do
Envoy e seus análogos.
Em geral, para que Prometheus tenha um emprego claro de trabalhadores, o que, por sua vez, ajudará a encontrar rapidamente o problema (e notificá-lo), recomendo que
exportadores prontos para converter dados do software no formato Prometheus.
PS
Outro do ciclo de dicas e truques do K8s:
Leia também em nosso blog: