
Todos os dias, um milhão e meio de pessoas pesquisam na Ozon uma variedade de produtos, e para cada um deles o serviço deve selecionar produtos similares (se o aspirador de pó ainda precisar de um mais potente) ou similares (se forem necessárias baterias para o dinossauro que canta). Quando há muitos tipos de produtos, o modelo Word2Vec ajuda a resolver o problema. Entendemos como ele funciona e como criar representações vetoriais para objetos arbitrários.
Motivação
Para construir e treinar o modelo, usamos a técnica de incorporação, padrão para aprendizado de máquina, quando cada objeto se transforma em um vetor de comprimento fixo e os vetores próximos correspondem a objetos próximos. Quase todos os modelos conhecidos exigem que os dados de entrada tenham um comprimento fixo, e um conjunto de vetores é uma maneira fácil de trazê-los para esse formulário.
Um dos primeiros métodos de incorporação é o word2vec. Nós adaptamos esse método para nossa tarefa, usamos produtos como palavras e sessões do usuário como sentenças. Se tudo estiver claro para você, fique à vontade para folhear os resultados.
A seguir, falarei sobre a arquitetura do modelo e como ele funciona. Como estamos lidando com mercadorias, precisamos aprender a construir tais descrições delas que, por um lado, contenham informações suficientes e, por outro, sejam compreensíveis para o algoritmo de aprendizado de máquina.
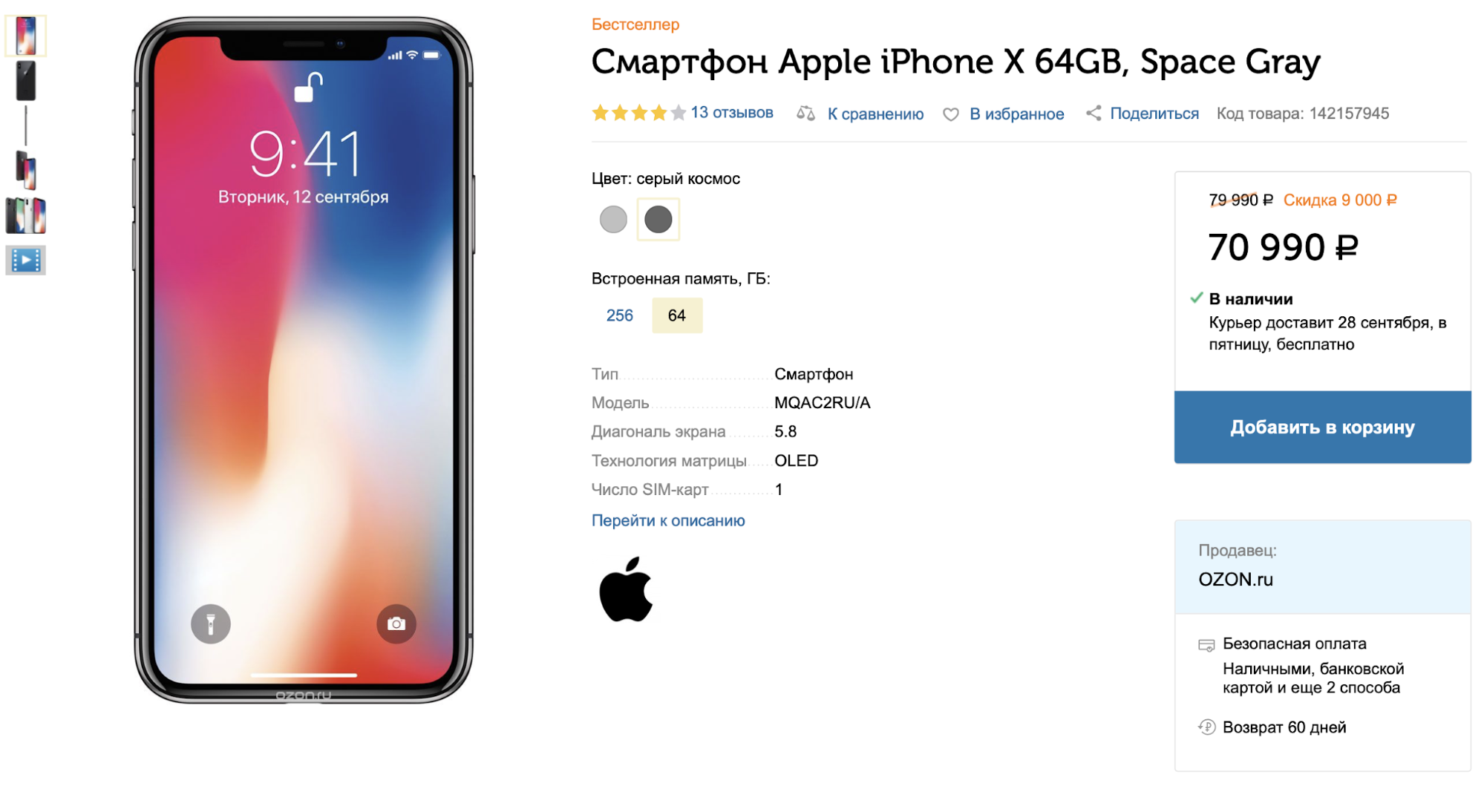
No site, cada produto possui um cartão. Consiste em um título, descrição do texto, especificações e fotografias. Também à nossa disposição, existem dados sobre a interação dos usuários com o produto: visualizações, acréscimos ao carrinho ou favoritos são armazenados nos registros.
Existem duas maneiras fundamentalmente diferentes de construir uma descrição vetorial de um produto:
- usar conteúdo - redes neurais convolucionais para extrair recursos de fotos, redes recorrentes ou um pacote de palavras para analisar uma descrição de texto;
- uso de dados nas interações do usuário com o produto: quais produtos e com que frequência eles são exibidos / adicionados ao carrinho junto com os dados.
Vamos nos concentrar no segundo método.
Dados para o modelo Prod2Vec
Primeiro, vamos descobrir quais dados usamos. Temos à disposição todos os cliques de usuários no site, eles podem ser divididos em sessões de usuário - sequências de cliques com intervalos de no máximo 30 minutos entre cliques adjacentes. Para treinar o modelo, usamos dados de cerca de 100 milhões de sessões de usuário, em cada uma das quais estamos interessados apenas em visualizar e adicionar produtos à cesta.
Um exemplo de uma sessão real do usuário:

Cada produto na sessão corresponde ao seu contexto - todos os produtos que o usuário adicionou à cesta nesta sessão, bem como os produtos visualizados com isso. O modelo prod2vec baseia-se no pressuposto de que produtos similares geralmente têm contextos semelhantes.
Por exemplo:

Portanto, se a suposição for verdadeira, por exemplo, casos para o mesmo modelo de telefone terão contextos semelhantes (o mesmo telefone). Testaremos essa hipótese construindo vetores de produtos.
Modelo Prod2Vec
Quando introduzimos os conceitos de um produto e seu contexto, descrevemos o próprio modelo. Esta é uma rede neural com duas camadas totalmente conectadas. O número de entradas da primeira camada é igual ao número de produtos para os quais queremos construir vetores. Cada produto na entrada será codificado por um vetor de zeros com uma única unidade - o local desse produto no dicionário.
O número de neurônios na saída da primeira camada é igual à dimensão dos vetores que queremos obter, por exemplo 64. Na saída da última camada, novamente, há um número de neurônios igual ao número de mercadorias.

Treinaremos o modelo para prever o contexto, conhecendo o produto. Essa arquitetura é chamada Skip-gram (sua alternativa é CBOW, onde previmos o produto de acordo com seu contexto). Durante o treinamento, as mercadorias são entregues na entrada, espera-se que as mercadorias sejam produzidas a partir de seu contexto (um vetor de zeros com uma unidade no local correspondente).
Em essência, esta é uma classificação multiclasse e a perda de entropia cruzada pode ser usada para treinar o modelo. Para um par de palavras e palavras do contexto, está escrito da seguinte maneira:
L=−pc+ log sumVi=1exp(pi)
onde pc - previsão de rede para o produto a partir do contexto, V - o número total de mercadorias pi - previsão de rede para o produto i .
Após o treinamento do modelo, podemos descartar a segunda camada - não será necessário obter vetores. A matriz de pesos da primeira camada (tamanho do número de mercadorias x 64) é um dicionário de vetores de mercadorias. Cada produto corresponde a uma linha de uma matriz de comprimento 64 - este é o vetor correspondente ao produto, que pode ser usado em outros algoritmos.
Mas esse procedimento não funciona para um grande número de produtos. E nós os temos, lembre-se, um milhão e meio.
Por que o Prod2Vec não funciona
- A função de perda contém muitas operações de obtenção do expoente - este é um longo e instável computacionalmente.
- Como resultado, os gradientes são considerados para todos os pesos de rede - e pode haver dezenas de milhões.
Para resolver esses problemas, o método de amostragem negativa é adequado, usando o que ensinamos à rede não apenas para prever o contexto do produto, mas também ensinamos a não prever os produtos que não estão exatamente no contexto. Para fazer isso, precisamos gerar exemplos negativos - para cada produto, selecione aqueles que não precisam ser previstos. E aqui a disponibilidade de uma enorme quantidade de mercadorias nos ajuda. Ao escolher um par aleatório para um produto, temos uma probabilidade muito pequena de que se torne um produto do contexto.
Como resultado, para cada produto no contexto, geramos aleatoriamente de 5 a 10 produtos que não estão incluídos no contexto. Além disso, os bens não são amostrados por uma distribuição uniforme, mas proporcional à frequência de sua ocorrência.
A função de perda agora é semelhante à usada na classificação binária. Para um par de palavras e palavras, no contexto, fica assim:
L=− log sigma(uTwOvwI)− sumwn log sigma(−uTwnvwI)
Nesta notação uwO denota uma coluna da matriz de peso da segunda camada correspondente ao produto do contexto, uwn - o mesmo para um produto selecionado aleatoriamente, vwI - a linha da matriz de pesos da primeira camada correspondente ao produto principal (este é exatamente o vetor que estamos construindo para ele). Função sigma(x)= frac11+exp(−x) .
A diferença da versão anterior é que não precisamos atualizar todos os pesos de rede em cada iteração, precisamos apenas atualizar aqueles que correspondem a um pequeno número de produtos (o primeiro produto é aquele para o qual previmos, o restante é um produto de seu contexto ou selecionado aleatoriamente ) Ao mesmo tempo, nos livramos de um grande número de capturas exponenciais a cada iteração.
Outra técnica, que por sua vez melhora a qualidade do modelo resultante, é a subamostragem. Nesse caso, intencionalmente, levamos mercadorias encontradas com menos frequência para treinamento, a fim de obter o melhor resultado para mercadorias raras.
Resultados
Produtos Relacionados
Então, aprendemos como obter vetores para mercadorias, agora precisamos verificar a adequação e a aplicabilidade do nosso modelo.
A figura a seguir mostra o produto e seus vizinhos mais próximos na medida do cosseno de proximidade.
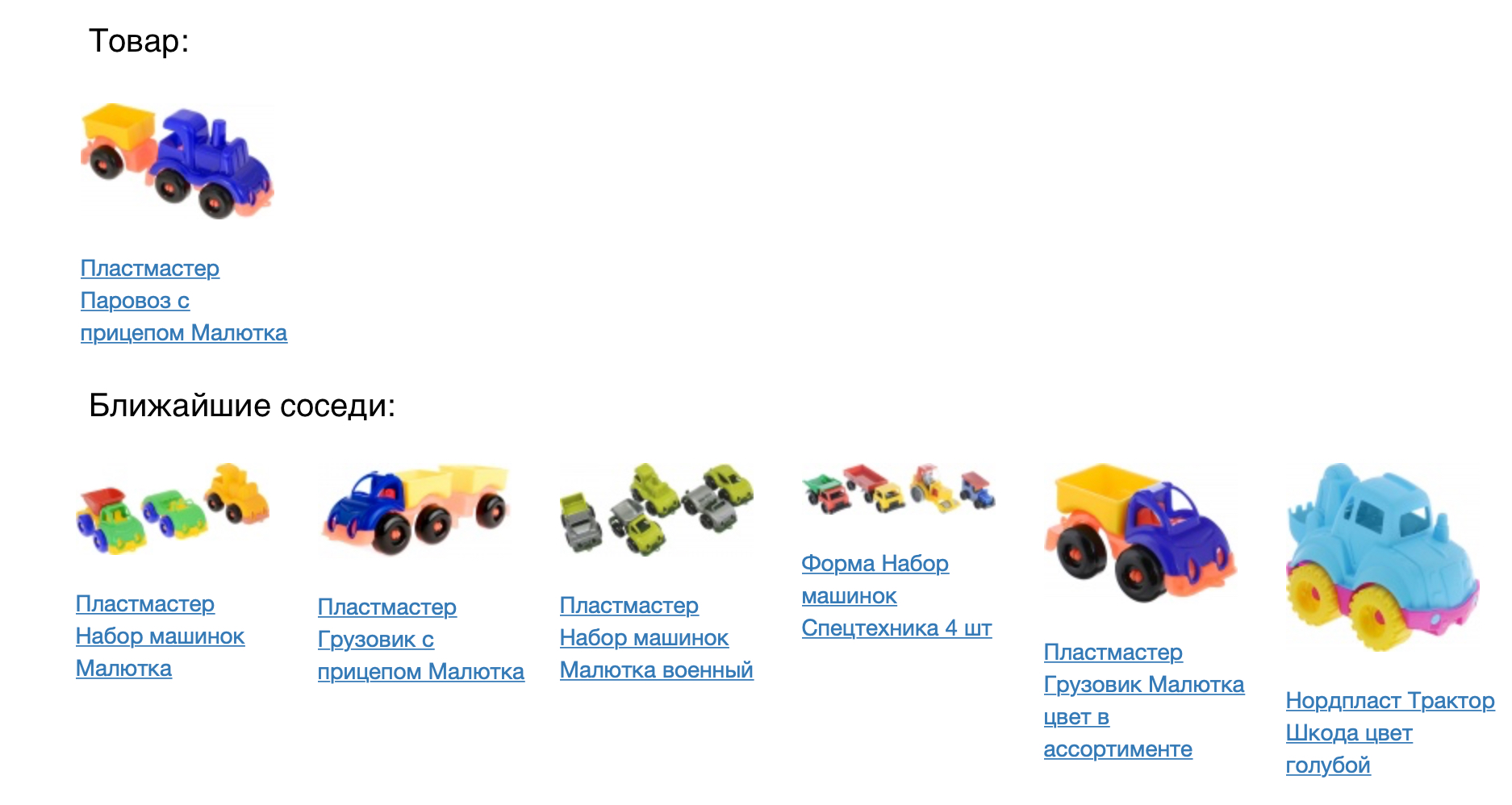
O resultado parece bom, mas você precisa verificar numericamente quão bom é o nosso modelo. Para fazer isso, aplicamos à tarefa de recomendações de produtos. Para cada produto, é recomendável entrar em um espaço vetorial construído. Comparamos o modelo prod2vec com um modelo muito mais simples, com base em estatísticas de visualizações conjuntas e adicionando itens ao carrinho. Para cada produto na sessão, foi feita uma lista de 7 recomendações. A combinação de todos os produtos recomendados na sessão foi comparada com o que uma pessoa realmente adicionou à cesta. Usando o prod2vec, em mais de 40% das sessões, recomendamos pelo menos um produto, que foi adicionado ao carrinho. Para comparação, um algoritmo mais simples mostra uma qualidade de 34%.
A descrição vetorial resultante nos permite não apenas procurar os mais próximos (o que pode ser feito por um modelo mais simples, embora com pior qualidade). Podemos considerar quais efeitos colaterais interessantes podem ser mostrados usando nosso modelo.
Aritmética de vetor
Para ilustrar que os vetores carregam o significado real das mercadorias, podemos tentar usar a aritmética vetorial para eles. Como no exemplo de livro didático da word2vec (rei - homem + mulher = rainha), podemos, por exemplo, nos perguntar qual produto está aproximadamente à mesma distância da impressora que o saco de pó do aspirador. O senso comum determina que deve ser algum tipo de consumível, a saber, um cartucho. Nosso modelo é capaz de capturar esses padrões:

Visualização do espaço do produto
Para entender melhor os resultados, podemos visualizar o espaço vetorial de mercadorias no plano, reduzindo a dimensão para duas (neste exemplo, usamos t-SNE).

Vê-se claramente que produtos relacionados formam agrupamentos. Por exemplo, aglomerados com têxteis para o quarto, roupas masculinas e femininas, sapatos são claramente visíveis. Mais uma vez, observamos que esse modelo é construído apenas com base no histórico de interações do usuário com as mercadorias; não usamos a semelhança de imagens ou descrições de texto durante o treinamento.
Na ilustração do espaço, você também pode ver como, usando o modelo, é possível selecionar acessórios para mercadorias. Para fazer isso, você precisa levar as mercadorias do cluster mais próximo, por exemplo, recomendar artigos esportivos para camisetas e bonés para suéteres quentes.
Planos
Agora estamos introduzindo o modelo prod2vec em produção para calcular as recomendações do produto. Além disso, os vetores obtidos podem ser usados como recursos para outros algoritmos de aprendizado de máquina nos quais nossa equipe está envolvida (previsão da demanda por produtos, classificação em pesquisas e catálogos, recomendações pessoais).
No futuro, planejamos implementar os incorporamentos recebidos no site em tempo real. Para todas as mercadorias visualizadas, as próximas estarão na sessão, que serão refletidas instantaneamente na entrega personalizada. Também planejamos integrar análise de imagem e análise de similaridade de acordo com a descrição do vetor em nosso modelo, o que melhorará bastante a qualidade dos vetores resultantes.
Se você sabe a melhor forma de fazer isso (ou refazer) - visite-o (e trabalhe ainda melhor).
Referências:
- Mikolov, Tomas, et al. "Representações distribuídas de palavras e frases e sua composição." Avanços nos sistemas de processamento de informações neurais. 2013.
- Grbovic, Mihajlo, et al. "Comércio eletrônico na sua caixa de entrada: recomendações de produtos em grande escala". Anais da 21ª Conferência Internacional ACM SIGKDD sobre Descoberta de Conhecimento e Mineração de Dados. ACM, 2015.
- Grbovic, Mihajlo e Haibin Cheng. "Personalização em tempo real usando a classificação de casamentos para pesquisa no Airbnb." Anais da 24ª Conferência Internacional ACM SIGKDD sobre Descoberta de Conhecimento e Mineração de Dados. ACM, 2018.