Na Rostelecom, usamos o Hadoop para armazenar e processar dados baixados de várias fontes usando aplicativos java. Agora, passamos para uma nova versão do hadoop com a autenticação Kerberos. Ao me mover, encontrei vários problemas, incluindo o uso da API do YARN. O trabalho do Hadoop com a autenticação Kerberos merece um artigo separado, mas neste artigo falaremos sobre a depuração do Hadoop MapReduce.

Ao executar tarefas no cluster, o lançamento do depurador é complicado pelo fato de não sabermos qual nó processará essa ou aquela parte dos dados de entrada e não podemos configurar nosso depurador antecipadamente.
Você pode usar o
System.out.println("message") testado pelo tempo. Mas como analisar a saída de
System.out.println("message") espalhada por esses nós?
Podemos enviar mensagens para o fluxo de erro padrão. Tudo escrito em stdout ou stderr,
enviado ao arquivo de log apropriado, que pode ser encontrado na página da Web de informações da tarefa estendida ou nos arquivos de log.
Também podemos incluir ferramentas de depuração em nosso código, atualizar mensagens de status de tarefas e usar contadores personalizados para nos ajudar a entender a escala do desastre.
O aplicativo Hadoop MapReduce pode ser depurado nos três modos em que o Hadoop pode funcionar:
- autônomo
- modo pseudo-distribuído
- totalmente distribuído
Em mais detalhes, vamos nos concentrar nos dois primeiros.
Modo pseudo-distribuído
O modo pseudo-distribuído é usado para simular um cluster real. E pode ser usado para testes em um ambiente o mais próximo possível da produtividade. Nesse modo, todos os daemons do Hadoop funcionarão em um nó!
Se você tiver um servidor de desenvolvimento ou outra sandbox (por exemplo, Máquina Virtual com um ambiente de desenvolvimento personalizado, como Hortonworks Sanbox com HDP), poderá depurar o programa de controle usando ferramentas de depuração remota.
Para iniciar a depuração, você precisa definir o valor da variável de ambiente:
YARN_OPTS . O seguinte é um exemplo. Por conveniência, você pode criar o arquivo startWordCount.sh e adicionar os parâmetros necessários para iniciar o aplicativo.
Agora, executando o script
`./startWordCount.sh` , veremos uma mensagem
Listening for transport dt_socket at address: 6000
Resta configurar o IDE para depuração remota. Eu estou usando intellij IDEA. Vá para o menu Executar -> Editar configurações ... Adicione uma nova configuração
Remote .
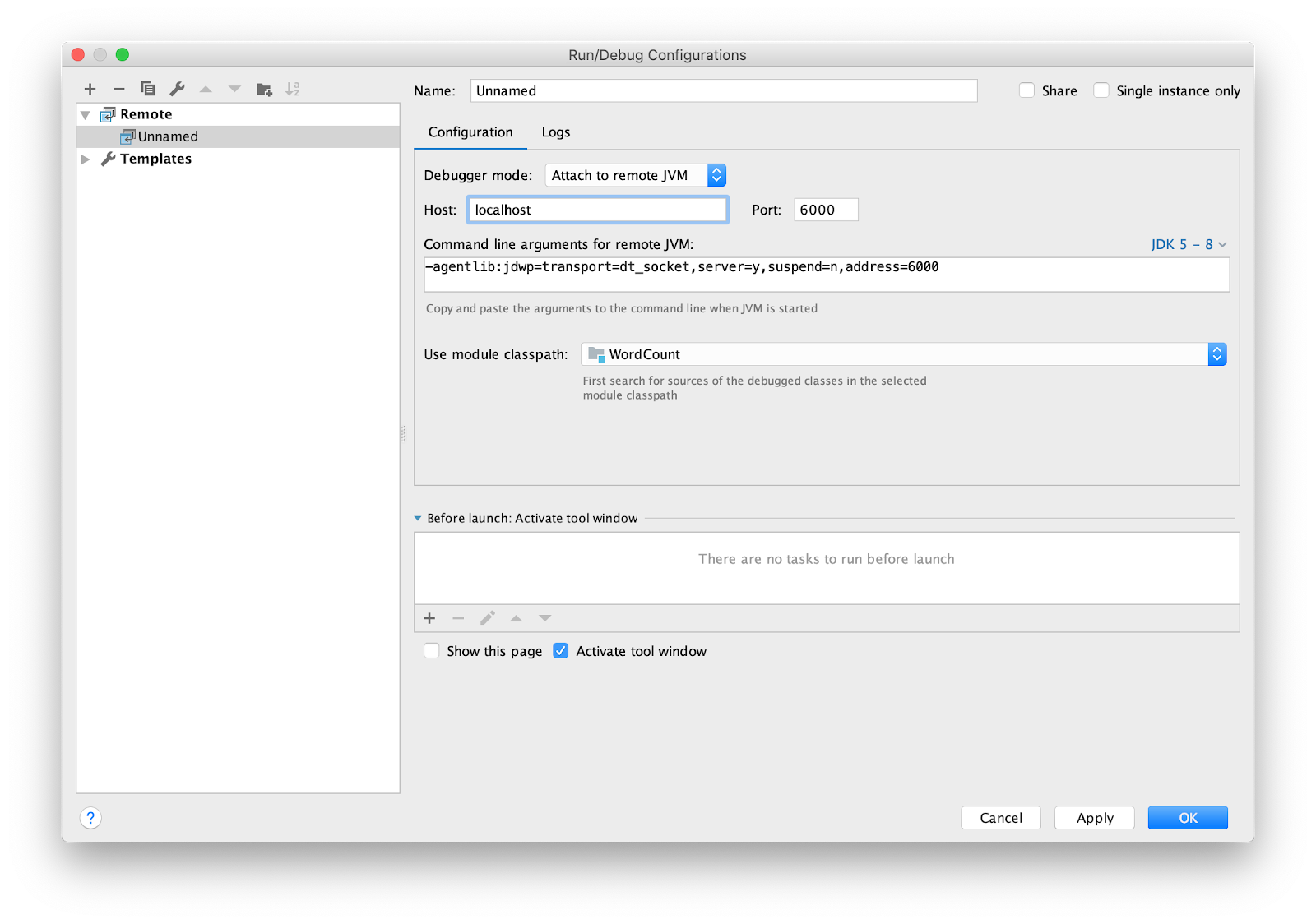
Defina o ponto de interrupção como principal e execute.
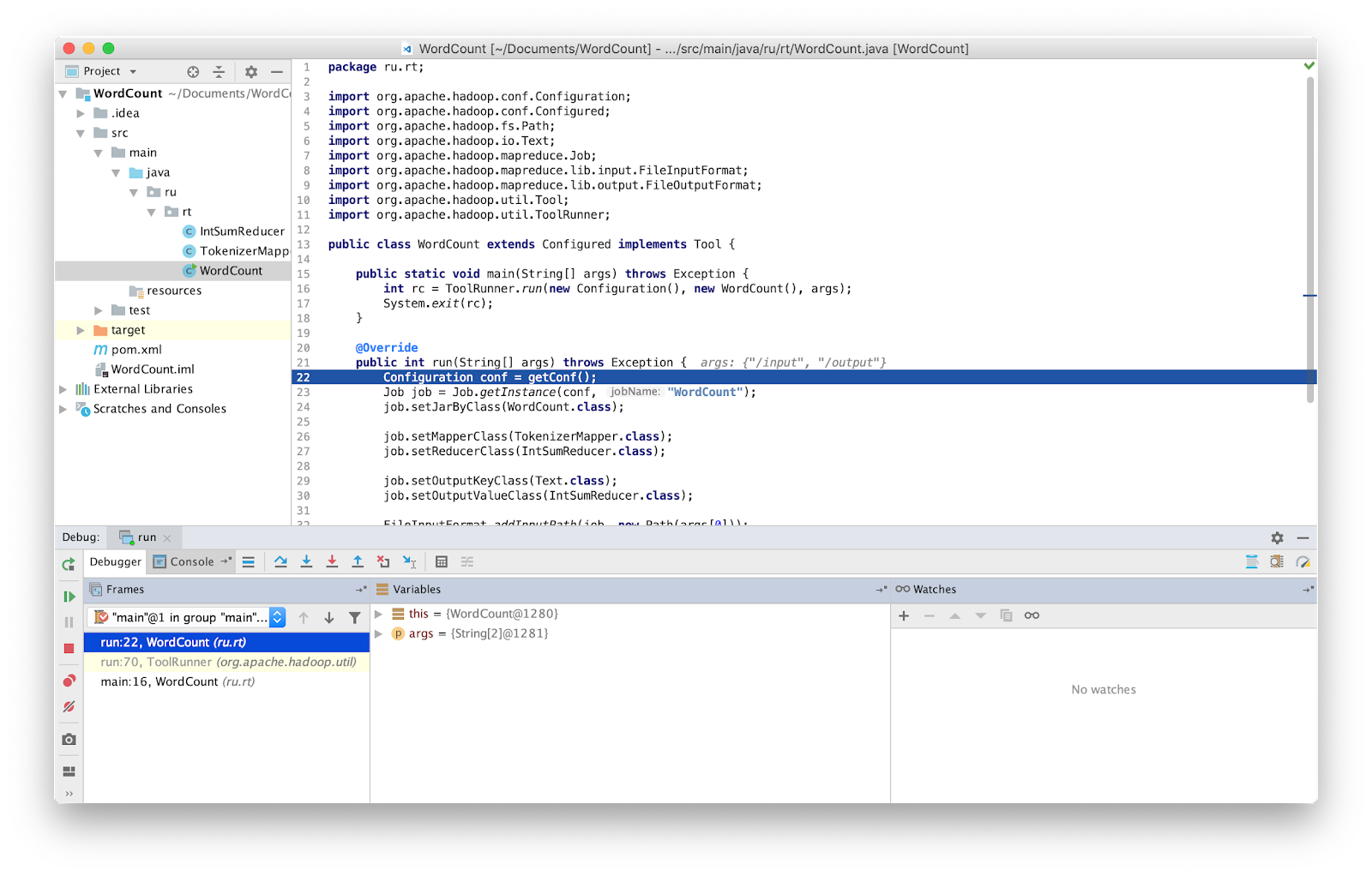
É isso, agora podemos depurar o programa como de costume.
ATENÇÃO Você deve verificar se está trabalhando com a versão mais recente do código-fonte. Caso contrário, você pode ter diferenças nas linhas em que o depurador para.
Nas versões anteriores do Hadoop, era fornecida uma classe especial que permitia reiniciar uma tarefa com falha - isolatedRunner. Os dados que causaram a falha foram salvos no disco no endereço especificado na variável de ambiente Hadoop mapred.local.dir. Infelizmente, nas versões recentes do Hadoop, essa classe não é mais fornecida.
Autônomo (início local)
Independente é o modo padrão no qual o Hadoop funciona. É adequado para depuração onde o HDFS não é usado. Com essa depuração, você pode usar entrada e saída através do sistema de arquivos local. O modo autônomo geralmente é o modo mais rápido do Hadoop, pois usa o sistema de arquivos local para todos os dados de entrada e saída.
Como mencionado anteriormente, você pode injetar ferramentas de depuração no seu código, como contadores. Os contadores são definidos pela
enumeração Java. O nome da enumeração define o nome do grupo e os campos de enumeração determinam os nomes dos contadores. Um contador pode ser útil para avaliar um problema,
e pode ser usado como uma adição à saída de depuração.
Declaração e uso do contador:
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private Text word = new Text(); enum Word { TOTAL_WORD_COUNT, } @Override public void map(LongWritable key, Text value, Context context) { String[] stringArr = value.toString().split("\\s+"); for (String str : stringArr) { word.set(str); context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); } } } }
Para incrementar o contador, use o método
increment(1) .
... context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); ...
Depois que o MapReduce é concluído com êxito, a tarefa exibe os contadores no final.
Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 ru.rt.example.Map$Word TOTAL_WORD_COUNT=655
Dados errados podem ser enviados para stderr ou stdout ou gravar saída em hdfs usando a classe
MultipleOutputs para análises adicionais. Os dados recebidos podem ser transmitidos para a entrada do aplicativo no modo autônomo ou ao gravar testes de unidade.
O Hadoop possui a biblioteca MRUnit, que é usada em conjunto com estruturas de teste (por exemplo, JUnit). Ao escrever testes de unidade, verificamos que a função produz o resultado esperado na saída. Usamos a classe MapDriver do pacote MRUnit, nas propriedades das quais definimos a classe testada. Para fazer isso, use o método
withMapper() , os valores de entrada
withInputValue() e o resultado esperado
withOutput() ou
withMultiOutput() se várias saídas forem usadas.
Aqui está o nosso teste.
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mrunit.mapreduce.MapDriver; import org.apache.hadoop.mrunit.types.Pair; import org.junit.Before; import org.junit.Test; import java.io.IOException; public class TestWordCount { private MapDriver<Object, Text, Text, IntWritable> mapDriver; @Before public void setUp() { Map mapper = new Map(); mapDriver.setMapper(mapper) } @Test public void mapperTest() throws IOException { mapDriver.withInput(new LongWritable(0), new Text("msg1")); mapDriver.withOutput(new Pair<Text, IntWritable>(new Text("msg1"), new IntWritable(1))); mapDriver.runTest(); } }
Modo totalmente distribuído
Como o nome sugere, este é um modo no qual todo o poder do Hadoop é usado. O programa MapReduce iniciado pode ser executado em 1000 servidores. É sempre difícil depurar o programa MapReduce, pois você tem mapeadores em execução em máquinas diferentes com dados de entrada diferentes.
Conclusão
Como se viu, testar o MapReduce não é tão fácil quanto parece à primeira vista.
Para economizar tempo procurando erros no MapReduce, usei todos os métodos listados acima e aconselho a todos que os apliquem também. Isso é especialmente útil no caso de grandes instalações, como as que funcionam no Rostelecom.