A estrutura interna dos dicionários em Python não se limita apenas a buckets e hashes fechados. Este é um mundo incrível de chaves compartilhadas, cache de hash, DKIX_DUMMY e comparações rápidas, que podem ser feitas ainda mais rapidamente (ao custo de um bug com uma probabilidade aproximada de 2 ^ -64).
Se você não sabe o número de elementos no dicionário que acabou de criar, quanta memória é gasta para cada elemento, por que agora (CPython 3.6 em diante) o dicionário é implementado em duas matrizes e como ele se relaciona com a manutenção da ordem de inserção, ou você simplesmente não assistiu à apresentação de Raymond Hettinger “Modern Python Dicionários Uma confluência de uma dúzia de grandes idéias ". Então seja bem vindo.
No entanto, as pessoas familiarizadas com a palestra também podem encontrar alguns detalhes e informações atualizadas. Para os novatos que não estão familiarizados com balde e hash fechado, o artigo também será interessante.
Os dicionários no CPython estão em toda parte, classes, variáveis globais, parâmetros kwargs são baseados neles, o
intérprete cria milhares de dicionários , mesmo que você mesmo não tenha adicionado colchetes ao seu script. Mas, para resolver muitos problemas aplicados, também são usados dicionários, não é de surpreender que sua implementação continue a melhorar e que cada vez mais cresçam em truques diferentes.
Implementação básica de dicionários (via Hashmap)
Se você estiver familiarizado com o trabalho do Hashmap padrão e do hash privado, poderá seguir para o próximo capítulo.
A idéia subjacente aos dicionários é simples: se tivermos uma matriz na qual objetos do mesmo tamanho são armazenados, teremos acesso fácil ao objeto desejado, conhecendo o índice.
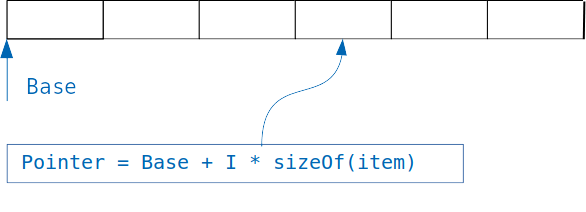
Simplesmente adicionamos um índice multiplicado pelo tamanho do objeto ao deslocamento da matriz e obtemos o endereço do objeto desejado.
Mas e se quisermos organizar uma pesquisa não por um índice inteiro, mas por uma variável de outro tipo, por exemplo, para encontrar usuários em seus endereços de email?
No caso de uma matriz simples, teremos que examinar os e-mails de todos os usuários da matriz e compará-los com a pesquisa, essa abordagem é chamada pesquisa linear e, obviamente, é muito mais lenta do que acessar o objeto pelo índice.
A pesquisa linear pode ser significativamente acelerada se limitarmos o tamanho da área em que você deseja pesquisar. Isso geralmente é alcançado com o restante do
hash . O campo pesquisado é a chave.
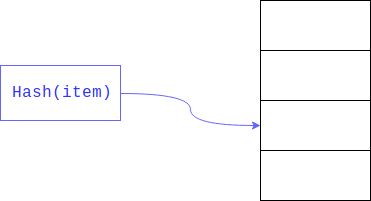
Como resultado, uma pesquisa linear é realizada não em toda a grande variedade, mas ao longo de sua parte.
Mas e se já houver um elemento lá? Isso poderia muito bem acontecer, pois ninguém garantiu que os resíduos da divisão do hash seriam únicos (como o próprio hash). Nesse caso, o objeto será colocado no próximo índice; se estiver ocupado, mudará para outro índice e assim sucessivamente até encontrar um livre. Ao recuperar um item, todas as chaves com o mesmo hash serão exibidas.
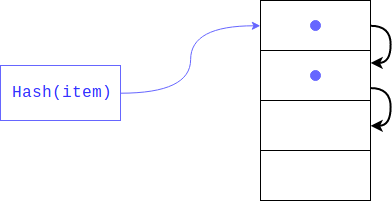
Esse tipo de hash é chamado de privado. Se houver poucas células livres no dicionário, essa pesquisa ameaça degenerar em uma linear; portanto, perderemos todos os ganhos para os quais o dicionário foi criado, para evitar isso, o intérprete mantém a matriz preenchida 1/2 - 2/3. Se não houver células livres suficientes, uma nova matriz será criada duas vezes maior que a anterior e os elementos da antiga serão transferidos para a nova de cada vez.
O que fazer se o item foi excluído? Nesse caso, uma célula vazia é formada na matriz e o algoritmo de pesquisa por chave não pode ser distinguido; essa célula está vazia porque um elemento com esse hash não estava no dicionário ou porque foi excluído. Para evitar a perda de dados durante a exclusão, a célula é marcada com um sinalizador especial (DKIX_DUMMY). Se esse sinalizador for encontrado durante uma pesquisa de elemento, a pesquisa continuará, a célula será considerada ocupada; se inserida, a célula será substituída.
Recursos de implementação em Python
Cada elemento do dicionário deve conter um link para o objeto e chave de destino. A chave deve ser armazenada para o processamento de colisão, o objeto - por razões óbvias. Como a chave e o objeto podem ser de qualquer tipo e tamanho, não podemos armazená-los diretamente na estrutura, eles ficam na memória dinâmica e os links para eles são armazenados na estrutura do item da lista. Ou seja, o tamanho de um elemento deve ser igual ao tamanho mínimo de dois ponteiros (16 bytes em sistemas de 64 bits). No entanto, o intérprete também armazena o hash, isso é feito para não recalcular com cada aumento no tamanho do dicionário. Em vez de calcular o hash de cada chave de uma nova maneira e dividir o restante pelo número de buckets, o intérprete simplesmente lê o valor já salvo. Mas e se o objeto principal for alterado? Nesse caso, o hash deve ser recalculado e o valor armazenado estará incorreto? Tal situação é impossível, pois tipos mutáveis não podem ser chaves de dicionário.
A estrutura do elemento do dicionário é definida da seguinte maneira:
typedef struct { Py_hash_t me_hash;
O tamanho mínimo do dicionário é declarado pela constante PyDict_MINSIZE, que é 8. Os desenvolvedores decidiram que esse é o tamanho ideal para evitar desperdício desnecessário de memória para armazenar valores vazios e tempo para expansão dinâmica da matriz. Assim, ao criar um dicionário (até a versão 3.6), você precisava de no mínimo 8 elementos no dicionário * 24 bytes na estrutura = 192 bytes (isso não leva em consideração os campos restantes: o custo da própria variável do dicionário, o contador do número de elementos etc.)
Os dicionários também são usados para implementar campos de classe personalizados. O Python permite alterar dinamicamente o número de atributos, essa dinâmica não requer custos adicionais, pois adicionar / remover um atributo é essencialmente equivalente à operação correspondente no dicionário. No entanto, uma minoria de programas usa essa funcionalidade; a maioria está limitada aos campos declarados em __init__. Mas cada objeto deve armazenar seu próprio dicionário, com suas chaves e hashes, apesar de coincidirem com outros objetos. Uma melhoria lógica aqui é o armazenamento de chaves compartilhadas em apenas um local, que é exatamente o que foi implementado no
PEP 412 - Dicionário de Compartilhamento de Chaves . A capacidade de alterar dinamicamente o dicionário não desapareceu: se a ordem ou o número de chaves for alterado, o dicionário será convertido das chaves de divisão para a normal.
Para evitar colisões, o "carregamento" máximo do dicionário é 2/3 do tamanho atual da matriz.
#define USABLE_FRACTION(n) (((n) << 1)/3)
Assim, a primeira extensão ocorrerá quando o sexto elemento for adicionado.
A matriz acaba por ser bastante descarregada, durante a operação do programa, de metade a um terço das células permanecem vazias, o que leva ao aumento do consumo de memória. Para contornar essa limitação e, se possível, armazenar apenas os dados necessários, foi adicionado um novo
nível de abstração da matriz.
Em vez de armazenar uma matriz esparsa, por exemplo:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
A partir da versão 3.6, os dicionários estão organizados da seguinte maneira:
indices = [None, 1, None, None, None, 0, None, 2] entries = [[-9092791511155847987, 'timmy', 'red'], [-8522787127447073495, 'barry', 'green'], [-6480567542315338377, 'guido', 'blue']]
I.e. apenas os registros realmente necessários são armazenados, eles são retirados da tabela de hash em uma matriz separada e apenas os índices dos registros correspondentes são armazenados na tabela de hash. Se inicialmente a matriz tiver 192 bytes, agora será de apenas 80 (3 * 24 bytes para cada registro + 8 bytes para índices). Compressão alcançada em 58%. [2]
O tamanho de um elemento nos índices também muda dinamicamente, inicialmente é igual a um byte, ou seja, toda a matriz pode ser colocada em um registro, quando o índice começa a caber em 8 bits, os elementos se expandem para 16 e depois para 32 bits. Existem constantes especiais DKIX_EMPTY e DKIX_DUMMY, para um elemento vazio e excluído, respectivamente, a expansão de índices para 16 bytes ocorre quando há mais de 127 elementos no dicionário.
Novos objetos são adicionados às entradas, ou seja, ao expandir o dicionário, não há necessidade de movê-los, basta aumentar o tamanho dos índices e preenchê-lo com índices.
Ao iterar sobre um dicionário, a matriz de índices não é necessária, os elementos são retornados sequencialmente das entradas, porque Sempre que elementos são adicionados ao final das entradas, o dicionário salva automaticamente a ordem de ocorrência dos elementos. Assim, além de reduzir a memória necessária para armazenar o dicionário, recebemos expansão dinâmica mais rápida e preservação da ordem das chaves. A redução da memória é boa em si mesma, mas, ao mesmo tempo, pode aumentar o desempenho, pois permite que mais registros entrem no cache do processador.
Os desenvolvedores do CPython gostaram tanto dessa implementação que agora são necessários dicionários para manter a ordem de inserção por especificação. Se anteriormente a ordem dos dicionários fosse determinada, ou seja, foi estritamente determinado pelo hash e inalterado do início ao início; em seguida, foi acrescentada uma pequena aleatoriedade para que as chaves fossem diferentes a cada vez, agora as chaves do dicionário devem manter a ordem. Quanto isso foi necessário e o que fazer se uma implementação ainda mais eficaz do dicionário aparecer, mas não preservar a ordem de inserção, não está claro.
No entanto, houve pedidos para implementar um mecanismo para preservar a declaração de atributos em
classes e em
kwargs , e essa implementação permite que você feche esses problemas sem mecanismos especiais.
Aqui está o que parece no
código CPython :
struct _dictkeysobject { Py_ssize_t dk_refcnt; Py_ssize_t dk_size; dict_lookup_func dk_lookup; Py_ssize_t dk_usable; Py_ssize_t dk_nentries; char dk_indices[]; };
Mas a iteração é mais complicada do que você imagina inicialmente, existem mecanismos adicionais de verificação de que o dicionário não foi alterado durante a iteração, um deles é uma
versão de 64 bits
do dicionário que armazena cada dicionário.
Finalmente, consideramos o mecanismo para resolver colisões. O problema é que, em python, os valores de hash são facilmente previsíveis:
>>>[hash(i) for i in range(4)] [0, 1, 2, 3]
E, ao criar um dicionário a partir desses hashes, o restante da divisão é obtido e, de fato, eles determinam para qual intervalo o registro irá, apenas os últimos bits da chave (se for inteiro). Você pode imaginar uma situação em que muitos objetos “querem” entrar nos buckets vizinhos; nesse caso, você terá que olhar para muitos objetos que estão fora de lugar durante a pesquisa. Para reduzir o número de colisões e aumentar o número de bits que determinam para qual intervalo o registro irá, o seguinte mecanismo foi implementado:
perturb é uma variável inteira inicializada por um hash. Note-se que, no caso de um grande número de colisões, ele é redefinido para zero e o seguinte índice é calculado pela fórmula:
j = (5 * j + 1) % n
Ao extrair um elemento do dicionário, a mesma pesquisa é realizada: o índice do slot no qual o elemento deve estar localizado é calculado; se o slot estiver vazio, é lançada a exceção "valor não encontrado". Se houver um valor nesse slot, você precisará verificar se a chave corresponde à que você está procurando, isso pode não ser possível se ocorrer uma colisão. No entanto, a chave pode ser praticamente qualquer objeto, incluindo um para o qual a operação de comparação leva um tempo considerável. Para evitar uma operação de comparação demorada, vários truques são usados no Python:
primeiro, os ponteiros são comparados, se o ponteiro principal do objeto desejado for igual ao ponteiro do objeto que está sendo pesquisado, ou seja, eles apontam para a mesma área de memória, então a comparação retorna imediatamente verdadeira. Mas isso não é tudo. Como você sabe, objetos iguais devem ter hashes iguais, o que significa que objetos com hashes diferentes não são iguais. Depois de verificar os ponteiros, os hashes são verificados; se eles não forem iguais, falso será retornado. E somente se os hashes forem iguais, uma comparação honesta será chamada.
Qual é a probabilidade de tal resultado? Aproximadamente 2 ^ -64, é claro, devido à fácil previsibilidade do valor do hash, você pode facilmente pegar um exemplo, mas, na realidade, essa verificação nem sempre chega a quanto? Raymond Hettinger montou o intérprete alterando a última operação de comparação com um simples retorno true. I.e. o intérprete considerava os objetos iguais se seus hashes fossem iguais. Em seguida, ele definiu testes automatizados de muitos projetos populares nesse intérprete, que foram finalizados com sucesso. Pode parecer estranho considerar objetos com hashes iguais iguais, não para verificar adicionalmente seu conteúdo e confiar inteiramente apenas no hash, mas você faz isso regularmente ao usar os protocolos git ou torrent. Eles consideram os arquivos (blocos de arquivos) iguais se seus hashes forem iguais, o que pode levar a erros, mas seus criadores (e todos nós) esperam que valha a pena notar, sem razão, que a probabilidade de uma colisão é extremamente pequena.
Agora você deve finalmente entender a estrutura do dicionário, que se parece com isso:
typedef struct { PyObject_HEAD Py_ssize_t ma_used; uint64_t ma_version_tag; PyDictKeysObject *ma_keys; PyObject **ma_values; } PyDictObject;
Mudanças futuras
No capítulo anterior, consideramos o que já foi implementado e pode ser usado por todos em seu trabalho, mas as melhorias, obviamente, não se limitam a: os planos para a versão 3.8 incluem
suporte para dicionários reversos . De fato, nada impede em vez de iterar desde o início de uma matriz de elementos e aumentar índices, começando pelo final e diminuindo índices.
Materiais adicionais
Para uma imersão mais profunda no tópico, é recomendável familiarizar-se com os seguintes materiais:
- Registro do relatório no início do artigo
- Proposta para uma nova implementação de dicionários
- Código-fonte do dicionário no CPython