Queremos compartilhar a história que aconteceu em um de nossos projetos para o Ano Novo. A essência do projeto é que ele automatize o trabalho dos médicos em instituições médicas. Durante a visita do paciente, o médico grava informações no gravador e o áudio é transcrito. Após o processo de transcrição - ou seja, transformando a gravação de áudio em texto - um documento médico é formado de acordo com os padrões relevantes e enviado de volta à clínica, de onde veio a gravação de áudio, de onde o médico que a envia recebe, verifica e aprova. Após passar nas verificações obrigatórias, o documento é enviado aos pacientes finais.
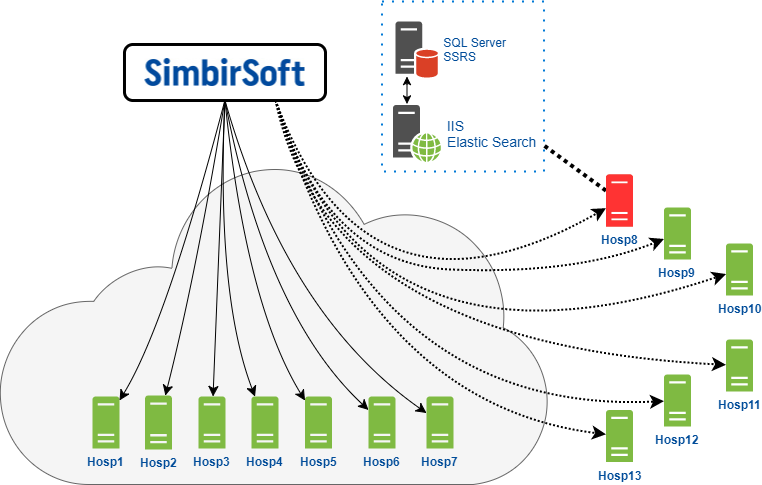
Todas as instituições médicas que usam o produto podem ser divididas condicionalmente em dois grandes grupos:
- Hospedagem no data center de nosso cliente, que é totalmente responsável pela funcionalidade do aplicativo, tanto por software quanto por hardware. Por exemplo, se o espaço em disco acabar ou se não houver desempenho suficiente do servidor na CPU;
- Auto-hospedado: eles colocam todos os equipamentos diretamente em casa e são responsáveis por seu desempenho. Nosso cliente fornece o aplicativo e seu suporte.
É assim que nossa equipe interage com servidores finais hospedados diretamente na nuvem de nossos clientes.

Temos acesso a esses servidores para realizar todo o trabalho e manutenção programados necessários.
O segundo grupo - clientes auto-hospedados - para eles, a nuvem do cliente atua como um gateway através do qual nos conectamos a esses servidores. Nesse caso, temos direitos limitados, geralmente não podemos executar nenhuma operação devido a configurações de segurança. Nós nos conectamos aos servidores através do RDP, o Remote Desktop Protocol no Windows OS. Naturalmente, tudo isso funciona através de uma VPN.
Deve-se ter em mente que cada servidor representado no diagrama é realmente uma combinação de um servidor de aplicativos e um servidor de banco de dados. O DBMS MS SQL Server e o serviço de relatório SSRS são instalados no servidor de banco de dados, respectivamente. Além disso, a versão do MSSQL Server é diferente em todas as clínicas: 2008, 2012, 2014. Além das próprias versões, diferentes Service Packs e patches estão instalados em todos os lugares. Em geral, um zoológico completo.
No servidor de aplicativos, instalamos o servidor Web IIS e ElasticSearch. O ElasticSearch é um mecanismo de pesquisa que também implementa a pesquisa de texto completo.
A principal essência em termos de nosso produto é "trabalho". O trabalho é uma entidade abstrata que vincula todas as informações relacionadas à recepção de um paciente em particular. Esta informação inclui:
- dados sobre o médico;
- dados do paciente;
- dados sobre a visita;
- arquivo de áudio (discurso do médico);
- documentos (várias versões);
- histórico de processamento do trabalho;
- informações da filial etc.
Este diagrama mostra um esquema de banco de dados simplificado a partir do qual você pode ver os relacionamentos entre as tabelas principais. Esta é apenas a parte básica; de fato, o banco de dados possui mais de 200 tabelas.

Um pouco sobre a clínica onde o incidente aconteceu:
- 1500-2000 obras por dia;
- 1000 usuários ativos (médicos + secretárias);
- Auto-hospedado.
DB:
- Tamanho: 800+ Gb (750K + trabalhos, 2M + documentos);
- DBMS: MS SQL Server 2008 R2;
- Modelo de recuperação: simples.
Aqui eu quero fazer uma pequena explicação. Existem três modelos de recuperação no SQL Server: simples, com logon em massa e completos. Não vou falar sobre o terceiro agora, vou explicar sobre o primeiro e o segundo. A principal diferença é que, no modelo simples, não armazenamos o histórico de transações no log - assim que a transação for confirmada, o registro do log de transações será excluído. Ao usar o modo de recuperação total, todo o histórico de alterações de dados é armazenado em um log de transações. O que isso nos dá? No caso de alguma situação imprevista, quando precisamos reverter o banco de dados a partir de backups, podemos retornar não apenas a um backup específico, mas também a qualquer momento, até uma transação específica, ou seja, armazenamos em backups, não apenas um determinado estado do banco de dados no momento do backup, mas também há todo um histórico de alterações de dados.
Acho que não vale a pena explicar que o modo simples é usado apenas no desenvolvimento, nos servidores de teste e seu uso na produção é inaceitável. De jeito nenhum.
Mas a clínica, aparentemente, tinha seus próprios pensamentos sobre esse assunto;)
Iniciar
Alguns dias depois do Ano Novo, todos estão se preparando para o feriado, comprando presentes, decorando árvores de Natal, passando festas corporativas e aguardando um longo fim de semana.
22 de dezembro (sexta-feira) 1 dia
14:31 O cliente disse que não recebeu o próximo relatório diário. O relatório chega pelo correio duas vezes por dia em uma programação; é necessário controlar o envio de dados para um sistema de integração externo, o que não é muito crítico.
Pode haver vários motivos:
- Problemas com SMTP, as cartas não foram entregues (elas mudaram a senha, por exemplo, e não disseram a ninguém);
- Problemas no lado do servidor dos relatórios;
- Algo aconteceu com o banco de dados.
16:03 Às vezes, a clínica altera a senha para SMTP, sem avisar ninguém, portanto, após concluir as tarefas atuais, verificamos o relatório com calma manualmente, iniciando pela interface da web - recebemos um erro que indica problemas no banco de dados.
Um exemplo do erro que recebemos ao iniciar o relatório.
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x9876641f; actual: 0xa3255fbf). It occurred during a read of page (1:876) in database ID 7 at offset 0x000000006d8000 in file 'D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\ServerLive.mdf'.
Isso indica que o banco de dados possui páginas corrompidas. Tivemos uma leve sensação de ansiedade.
20:53 Para avaliar a extensão do dano, executamos uma verificação do banco de dados usando o comando
DBCC CHECKDB especial. Dependendo do tamanho do dano, o comando test pode demorar um pouco, então executamos o comando à noite. Aqui temos a sorte de ter acontecido na tarde de sexta-feira, ou seja, tivemos pelo menos todos os dias de folga para resolver esse problema.
Nesse momento, a situação era a seguinte:
23 de dezembro (sábado) 2º dia
10:02 De manhã, descobrimos que a verificação do banco de dados com o CHECKDB é flexível - isso ocorreu devido à falta de espaço livre em disco, porque durante o processo de verificação, o banco de dados temporário do tempdb é usado ativamente e, em algum momento, o espaço livre em disco acabou.
Portanto, decidimos, em vez de verificar o banco de dados inteiro, iniciar imediatamente uma varredura de tabela. Para fazer isso, use o
comando DBCC CHECKTABLE .
10:46 Decidimos começar com a tabela JobHistory, que provavelmente está corrompida, pois foi usada para gerar o relatório. Esta tabela, como o nome indica, preserva o histórico de todas as obras, ou seja, transições de trabalho entre etapas.
Execute
DBCC CHECKTABLE ('dbo.JobHistory') .
A verificação dessa tabela revela tabelas danificadas no banco de dados, o que era esperado em princípio.
12:00 No momento, se o banco de dados usasse o modelo de recuperação completo, poderíamos restaurar as páginas danificadas do backup, e isso terminaria, mas nosso banco de dados estava no modo simples. Portanto, a única opção para reparar danos continua sendo o lançamento do mesmo comando com o parâmetro especial
REPAIR_ALLOW_DATA_LOSS . Isso pode resultar em perda de dados.
Começamos. A verificação termina novamente com um erro - obtemos um erro de que a restauração desta tabela é impossível até que as tabelas relacionadas sejam restauradas. A tabela de histórico refere-se à tabela de trabalho (Jobs) pela chave estrangeira, portanto, concluímos que também há danos na tabela de trabalho principal (Jobs).
13:30 O próximo passo é verificar a tabela Jobs, ao mesmo tempo - esperamos que o dano esteja no índice e não nos dados. Nesse caso, será suficiente reconstruir o índice para recuperação de dados.
17:33 Depois de um tempo, descobrimos que nosso servidor não está disponível via RDP. Provavelmente foi desativado, a verificação não foi concluída, o trabalho foi suspenso. Informamos à clínica que o servidor não está disponível, por favor, aumente.
A ansiedade leve assume formas muito específicas.
24 de dezembro (domingo) 3º dia
14:31 Mais perto do jantar, o servidor é criado, reexecutamos a verificação da tabela Jobs.
DBCC CHECKTABLE ('dbo.Jobs')16:05 A verificação não foi concluída, o servidor não está disponível. Novamente.
Depois de algum tempo, o servidor não está disponível novamente, antes de concluirmos a verificação da tabela. Nesse ponto, o serviço de TI da clínica realiza uma série de verificações no servidor. Estamos aguardando a conclusão do trabalho.
Devido aos feriados, a comunicação entre nós e o cliente era lenta - esperávamos respostas às perguntas por várias horas.
25 de dezembro (segunda-feira - Natal) 4º dia
16:00 No dia seguinte, o servidor foi criado, o cliente tem Natal e novamente começamos a verificar a tabela, mas desta vez excluímos os índices da verificação e deixamos apenas a verificação de dados. E depois de algum tempo, o servidor não está disponível novamente.
O que está havendo?
Nesse momento, começam a surgir pensamentos de que isso não é apenas uma coincidência, e há uma suspeita de que possa haver danos no nível do ferro (um disco rígido caiu). Assumimos que existem setores defeituosos no disco e, quando a verificação tenta ler dados desses setores, o sistema trava. Informamos nosso cliente sobre nossa suposição.
O cliente executa uma verificação de disco na máquina host.
17:19 O serviço de TI da clínica informou que o arquivo da máquina virtual está danificado - isso é ruim!
Ainda não podemos trabalhar e aguardamos um sinal quando eles resolverem o problema e podemos continuar nosso trabalho.
26 de dezembro (terça-feira) Dia 5
14:05 O serviço de clínica de TI inicia outro processo de recuperação de disco. Fomos informados de que podemos executar CHECKTABLE em paralelo para verificar a tabela. Iniciamos o teste novamente - a máquina virtual trava novamente, informamos ao cliente que o arquivo da máquina virtual ainda está corrompido.
Hoje em dia, todas as comunicações com o cliente são muito lentas, com um grande atraso devido aos feriados.
27 de dezembro (quarta-feira) Dia 6
14:00 Iniciamos a verificação do disco usando o Windows - disco de verificação dentro da máquina virtual - nenhum problema foi detectado.
O banco de dados está no modo Simples, portanto, as chances de corrigir o banco de dados atual com as ferramentas DBMS tendem a zero, porque não podemos recuperar páginas danificadas individuais.
Estamos começando a considerar a opção de reverter e restaurar o banco de dados a partir do backup.
Verificamos os backups do banco de dados e descobrimos que os backups não foram feitos usando o DBMS, o último backup foi em 2014, ou seja, Não há backups do banco de dados. Por que eles não fizeram isso, é uma questão separada, é responsabilidade da clínica garantir a eficiência e a segurança do banco de dados.
Há uma alta probabilidade de que não funcione para restaurar o banco de dados atual. Começamos a considerar outras opções de reversão.
Vamos discutir mais detalhadamente a situação com backups na clínica.
A situação com backups:
- Não há backups de banco de dados (!!!)
- Não há instantâneos da máquina virtual (!?)
- Mas há backups de disco (completo + inc)
O banco de dados está no disco D, respectivamente, eles fizeram backups completos semanais e backups incrementais diários.
- toda sexta-feira às 20:00 backup completo
- backup incremental diário
- existe um backup completo dos dias 15 e 22
- existem backups diários até o dia 21
I.e. em princípio, podemos reverter para o estado antes que o problema ocorra.
Estamos aguardando uma atualização da clínica para iniciar a reversão do banco de dados a partir do backup.
Ao mesmo tempo, a clínica enviou uma solicitação ao fornecedor de ferro (HP) marcado como "urgente".
28 de dezembro (quinta-feira) Dia 7
13:13 O serviço de TI da clínica começa a configurar uma nova máquina virtual, como Não é possível corrigir o dano no arquivo da máquina virtual antiga.
19:09 Uma nova
máquina virtual
está disponível com o SQL Server instalado.
A próxima etapa é restaurar o banco de dados a partir do backup em disco. Para começar, decidimos reverter para o 22º dia, se o problema ainda estiver presente, reverter para os dias 21, 20 e assim por diante, até chegarmos ao estado de funcionamento.
Era o 28º dia no quintal, estávamos na festa corporativa e aqui eles nos dizem que a clínica tem problemas com a restauração de backups, porque os backups estão vazios!
Aqui estão as novidades!
Ao restaurar um backup da unidade D a partir do dia 21, acontece que ele está vazio, como todos os outros. Os backups diretos do shredder são obtidos - eles parecem estar lá, mas ao mesmo tempo não estão. Não está completamente claro como isso aconteceu, mas, até onde pudemos entender, o ponto é o espaço insuficiente em disco para armazenar backups em disco. Eles alocaram 500 Gb de backups para armazenamento, mas no momento do incidente, o banco de dados já pesava 800 Gb, portanto, em princípio, o backup não podia ser bem-sucedido. I.e. os backups eram feitos regularmente de acordo com o cronograma, mas devido à falta de espaço, eles acabaram com um erro e, portanto, estavam vazios, e o serviço de TI da clínica nem teve a ideia de verificar se estava tudo bem com eles. Não faça isso.
29 de dezembro (sexta-feira) Dia 8
13:11 Discussão de outras ações. Possíveis opções:
- Tentativa de copiar arquivos de banco de dados (arquivos .ldf + .two) - as chances de sucesso são muito baixas;
- Tentar fazer backup do banco de dados é novamente muito pouca chance;
- Configurar replicação - pode funcionar.
Uma unidade de 1 TB foi alocada no novo servidor, o que obviamente não é suficiente se tentarmos fazer backup e restaurar a partir dele, porque no pior dos casos, sem compactação, os backups ocupam tanto espaço quanto o banco de dados original, ou seja, 800 Gb.
Por favor, adicione lugares no novo servidor e continue copiando os arquivos do banco de dados.
Um banco de dados foi criado no novo servidor e o esquema do banco de dados foi restaurado - isso permitirá pelo menos processar novo trabalho. A clínica poderá pelo menos aceitar novos pacientes usando esse sistema.
14:36 Portanto, seguimos para a opção número um, embora não esperemos muito sucesso.
Pare o SQL Server, comece a copiar o arquivo de dados (mdf) e o log (ldf).
16:13 Depois de metade do arquivo de log, ele foi copiado com êxito (48 Gb) e 50 GB do arquivo de dados já foram copiados (795 de 846 GB restantes). A essa velocidade, levará cerca de 12 horas para concluir a cópia.
16:30 O servidor de banco de dados antigo foi desligado ao copiar o arquivo, o que é bastante esperado.
17:09 Portanto, passamos para a próxima opção - configurar a replicação, enquanto podemos especificar quais dados serão replicados, ou seja, podemos primeiro excluir tabelas danificadas deliberadamente e primeiro copiar os dados não danificados e depois transferir as tabelas problemáticas em partes. Mas essa opção, infelizmente, também não funciona, porque não podemos nem criar uma publicação com determinadas tabelas devido à corrupção do banco de dados.
Também estamos considerando opções de transferência de dados.
20:01 Como resultado, começamos a simplesmente transferir dados do antigo para o novo servidor importando e exportando em ordem de prioridade.
21:35 Primeiro, os dados mais críticos, depois arquivados e menos críticos (~ 300 GB). Na primeira onda de exportação, restavam menos de 300 GB de dados. A tabela Documentos (300 GB) também é excluída. Iniciamos o processo de cópia à noite.
30 de dezembro (sábado) Dia 9
15:00 Continuamos a transferir dados. A tabela Trabalhos não está disponível. A maioria das tabelas foi copiada nesse momento.
Mas sem
Jobs, tudo é inútil, porque é o principal elo entre todos os dados e lhes dá significado e valor do ponto de vista comercial. Sem ele, temos apenas um conjunto de dados díspares que simplesmente não podemos usar.
Além disso, neste ponto, a recuperação do esquema do banco de dados foi concluída.
As consequências do incidente:Neste ponto, temos uma enorme perda de dados ao vivo.
I.e. formalmente, temos alguns dados no banco de dados, mas, de fato, não há como usá-los ou conectá-los, para que possamos falar sobre a perda completa de dados.
Dados perdidos em mais de 750.000 internações de pacientes.
Isso é realmente triste!
- Esse é um grande golpe para a reputação de nosso cliente, que pode se tornar um grande problema para eles nos negócios ao concluir novos contratos e encontrar novos clientes.
- Perder tantos dados para a clínica pode levar a sérios problemas e multas, porque São dados confidenciais que contêm sigilo médico e, no sentido literal, dependem da vida das pessoas.
Começamos a pensar no que podemos fazer nessa situação. Eles começaram a vasculhar o sistema por ossos para encontrar pistas.
15:16 Analisando todos os aspectos do sistema, entendemos que podemos tentar extrair os dados ausentes do índice ElasticSearch. O fato é que, devido à configuração incorreta dos índices ElasticSearch, ele armazena não apenas os campos pelos quais a pesquisa de texto completo é realizada, mas, em geral, tudo, isto é, na verdade, há uma cópia completa dos dados e, teoricamente, podemos extrair dados de lá. sobre trabalhos e devolva-os ao nosso banco de dados. Espera-se que os dados ainda possam se recuperar.
Um bug ao qual você pode colocar um monumento!
 18:00
18:00 Um utilitário foi escrito rapidamente para extrair os dados e, após algumas horas, garantimos que a abordagem funcione e que os dados possam ser restaurados.
20:00 A restauração do trabalho do ElasticSearch com a ajuda de um utilitário escrito foi iniciada. A abordagem funcionou, podemos restaurar os dados no trabalho. Paralelamente, começamos a extrair as versões mais recentes do documento para cada trabalho.
31 de dezembro (domingo - ano novo) Dia 10
14:09 Durante a noite, 188 811 obras foram restauradas.
20:13 Vendo nosso sucesso, a clínica decide adiar a transferência do servidor para o serviço HP, a fim de nos dar tempo para extrair o máximo de dados do servidor antigo.
Com essas novidades, comemoramos o Ano Novo))
01 de janeiro (segunda-feira) 11º dia
11:23 Preparando-se para iniciar o sistema após o incidente:
- reconfigurou o IIS no servidor de aplicativos;
- reconfigurou todos os serviços necessários para trabalhar com o novo servidor de banco de dados;
- gatilhos, procedimentos armazenados, funções restauradas.
14:28 Então eles começaram a copiar a tabela de documentos, que foi ignorada devido ao grande tamanho durante a transferência inicial.
- O servidor de banco de dados antigo é encerrado novamente. Obviamente, a tabela Documentos também está corrompida; é com ela que todas as informações do paciente são armazenadas. Felizmente, não está completamente danificado, podemos fazer solicitações e, quando uma solicitação para nós retorna um registro danificado, nesse momento o servidor trava e é encerrado. Podemos extrair alguns dos dados.
Nesse sentido, sinalizamos para o cliente, eles elevam o servidor e, paralelamente, continuamos a preparar o novo banco de dados para o lançamento do sistema.
18:01 Recuperação de todas as restrições de integridade após a transferência da parte principal dos dados.
22:02 Restauração de restrições concluída. Simplesmente transferimos os dados brutos ao máximo. A presença de restrições de integridade complicaria bastante nossa tarefa.
02 de janeiro (terça-feira) Dia 12
05:52 O antigo servidor de banco de dados foi desligado novamente ao copiar o documento. Ele é prontamente criado para que possamos continuar trabalhando.
09:00 Foi possível recuperar em lote cerca de 200.000 documentos (aproximadamente 20%)
Começamos a usar métodos de recuperação diferentes: classificando por colunas diferentes para obter dados do final ou do início da tabela, até encontrarmos alguma parte danificada da tabela.
13:42 Começou a copiar trabalhos de arquivo na tabela - felizmente, não está danificado.
17:08 Restaurado todo o trabalho de arquivo (491 380 peças).
O sistema está pronto para o lançamento: os usuários podem criar e processar novos trabalhos.
Infelizmente, devido a danos parciais na tabela de documentos, você não pode simplesmente transferir todos os dados dela, como em outras tabelas, porque a mesa está parcialmente danificada. Portanto, ao tentar recuperar todos os dados, a solicitação falha ao tentar ler páginas corrompidas. Portanto, extraímos os dados no sentido do ponto, usando diferentes tipos e tamanhos de amostra:
- Classificando por diferentes campos (ID, DateTime);
- Classifique ascendente, descendente;
- Trabalhe com pequenos grupos de linhas (1000, 100);
- Buscando trabalhos por ID.
03 de janeiro (quarta-feira) Dia 13
08:58 Continuou o processo de restauração de documentos. Os documentos foram restaurados apenas para trabalho ativo e incompleto. Neste ponto, 1000 trabalhos (ativos) sem documentos.
11:38 Migrou todos os trabalhos SQL
13:17 5 funciona sem documentos, 231 não funciona, mas há um arquivo de áudio, é necessário sincronizar novamente.
04 de janeiro (quinta-feira) Dia 14
A recuperação manual e a verificação do trabalho restante foram iniciadas.
O sistema funciona, monitorando e corrigindo erros online.
05 de janeiro (sexta-feira) Dia 15
Relatar a migração para o SSRS planejada.
A transferência para um novo servidor não é possível, porque a clínica instalou uma versão mais antiga do SQL Server e não funcionará para transferir o banco de dados do servidor antigo.
Opções:
- Atualize o SQL Server de 2008 para 2008 R2;
- Configure tudo do zero.
Decidiu-se aguardar a atualização do SQL Server.
09:21 A restauração em segundo plano dos documentos para o trabalho concluído foi iniciada - o processo é longo e levará vários dias.
13:28 Alteração de prioridade da restauração de documentos por departamentos.
18:18 A clínica deu acesso ao SMTP, configuração de correio
Resultado:
- Quase todos os dados foram restaurados (apenas 5 trabalhos foram perdidos);
- Recomendações sobre manutenção de banco de dados foram emitidas para evitar tais situações;
- Os backups do banco de dados são configurados usando o SQL Server;
- Monitoramento adicional de backups de nossa parte, alertas em caso de falha.