
17 bilhões de eventos, 60 milhões de sessões de usuários e um grande número de datas virtuais ocorrem diariamente no Badoo. Cada evento é armazenado ordenadamente em bancos de dados relacionais para posterior análise no SQL e além.
Bancos de dados transacionais distribuídos modernos com dezenas de terabytes de dados - um verdadeiro milagre da engenharia. Mas o SQL, como a personificação da álgebra relacional na maioria das implementações padrão, ainda não nos permite formular consultas em termos de tuplas ordenadas.
No último artigo de uma série sobre máquinas virtuais , falarei sobre uma abordagem alternativa para encontrar sessões interessantes - o mecanismo de expressão regular ( Pig Match ), que é definido para sequências de eventos.
Máquina virtual, bytecode e compilador estão incluídos gratuitamente!
Parte I, Introdutória
Parte Dois, Otimizando
Parte III, aplicada (atual)
Sobre eventos e sessões
Suponha que já tenhamos um data warehouse que permita visualizar rápida e sequencialmente os eventos de cada uma das sessões do usuário.
Queremos encontrar sessões por solicitações como "contar todas as sessões em que há uma subsequência especificada de eventos", "encontrar partes de uma sessão descrita por um determinado padrão", "retornar a parte da sessão que ocorreu após um determinado padrão" ou "contar quantas sessões atingiram certas partes modelo ". Isso pode ser útil para vários tipos de análise: pesquisa de sessões suspeitas, análise de funil, etc.
As subsequências desejadas devem ser descritas de alguma forma. Em sua forma mais simples, essa tarefa é semelhante a encontrar uma substring em um texto; queremos ter uma ferramenta mais poderosa - expressões regulares. As implementações modernas de mecanismos de expressão regular costumam usar (você adivinhou!) Máquinas virtuais.
A criação de pequenas máquinas virtuais para combinar sessões com expressões regulares será discutida abaixo. Mas primeiro, esclareceremos as definições.
Um evento consiste em um tipo de evento, hora, contexto e um conjunto de atributos específicos para cada tipo.
O tipo e o contexto de cada evento são números inteiros de listas predefinidas. Se tudo estiver claro com os tipos de eventos, o contexto será, por exemplo, o número da tela na qual o evento especificado ocorreu.
Um atributo de evento é um número inteiro arbitrário cujo significado é determinado pelo tipo de evento. Um evento pode não ter atributos ou pode haver vários.
Uma sessão é uma sequência de eventos classificados por hora.
Mas vamos finalmente ao que interessa. O zumbido, como se costuma dizer, diminuiu, e eu fui para o palco.
Compare em um pedaço de papel
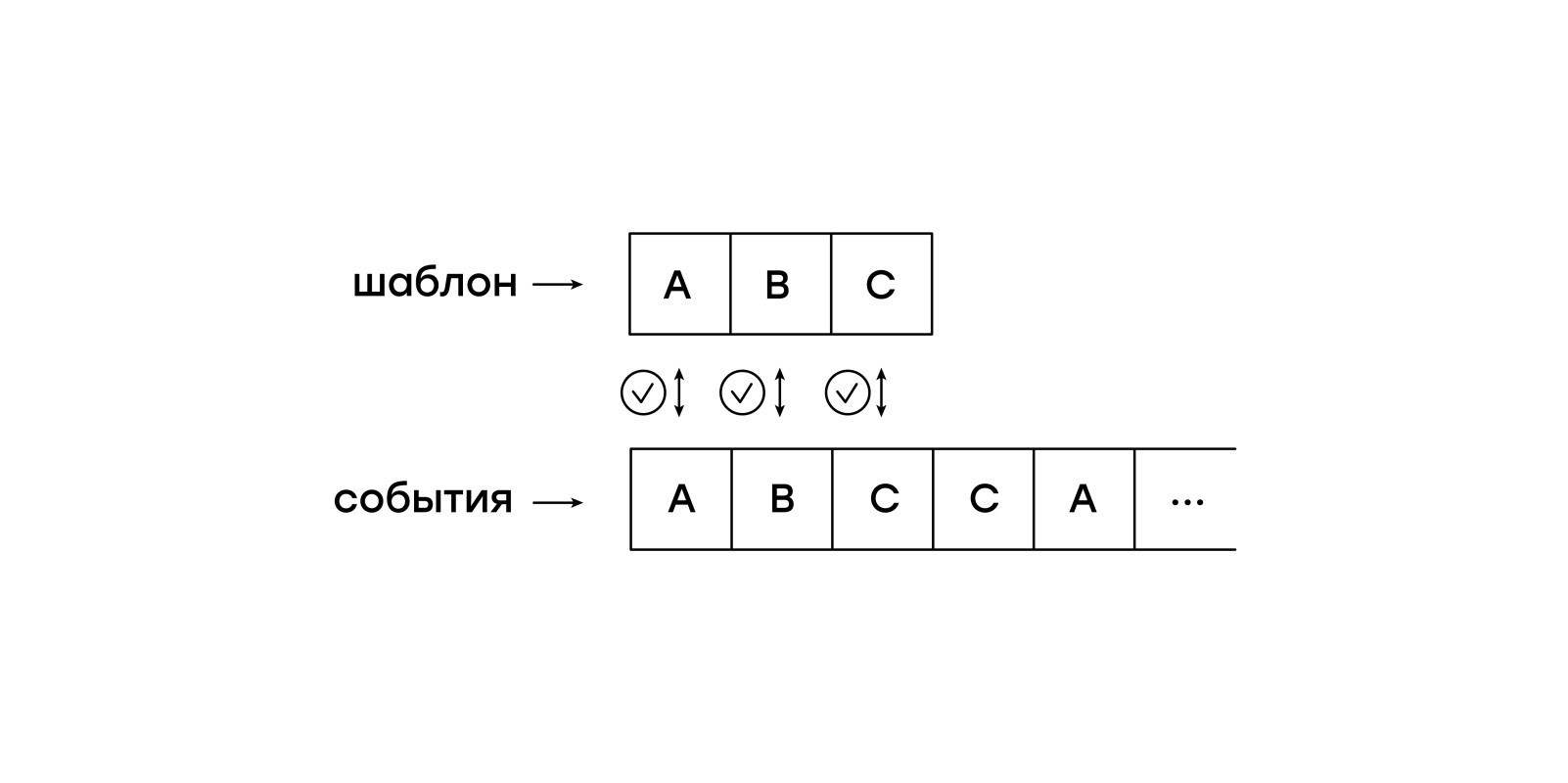
Um recurso desta máquina virtual é a passividade em relação aos eventos de entrada. Não queremos manter a sessão inteira na memória e permitir que a máquina virtual alterne independentemente de evento para evento. Em vez disso, alimentaremos os eventos da sessão na máquina virtual, um por um.
Vamos definir funções de interface:
matcher *matcher_create(uint8_t *bytecode); match_result matcher_accept(matcher *m, uint32_t event); void matcher_destroy(matcher *matcher);
Se tudo estiver claro com as funções matcher_create e matcher_destroy, vale a pena comentar o matcher_accept. A função matcher_accept recebe uma instância da máquina virtual e o próximo evento (32 bits, onde 16 bits para o tipo de evento e 16 bits para o contexto) e retorna um código explicando o que o código do usuário deve fazer a seguir:
typedef enum match_result {
Opcodes da máquina virtual:
typedef enum matcher_opcode {
O loop principal de uma máquina virtual:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP() \ (*m->ip++) #define NEXT_ARG() \ ((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1]) for (;;) { uint8_t instruction = NEXT_OP(); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(); if (event_name(next_event) != name) return MATCH_FAIL; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(); if (event_screen(next_event) != screen) return MATCH_FAIL; break; } case OP_NEXT:{ return MATCH_NEXT; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } #undef NEXT_OP #undef NEXT_ARG }
Nesta versão simples, nossa máquina virtual combina sequencialmente o padrão descrito pelo bytecode com os eventos recebidos. Como tal, isso simplesmente não é uma comparação muito concisa dos prefixos de duas linhas: o modelo desejado e a linha de entrada.
Prefixos são prefixos, mas queremos encontrar os padrões desejados não apenas no início, mas também em um local arbitrário na sessão. A solução ingênua é reiniciar a correspondência de cada evento da sessão. Mas isso implica a visualização múltipla de cada um dos eventos e a ingestão de bebês algorítmicos.
O exemplo do primeiro artigo da série, na verdade, simula o reinício de uma correspondência usando a reversão (retrocesso em inglês). O código no exemplo parece, é claro, mais fino que o fornecido aqui, mas o problema não desapareceu: cada um dos eventos terá que ser verificado muitas vezes.
Você não pode viver assim.
Eu, eu de novo e eu de novo

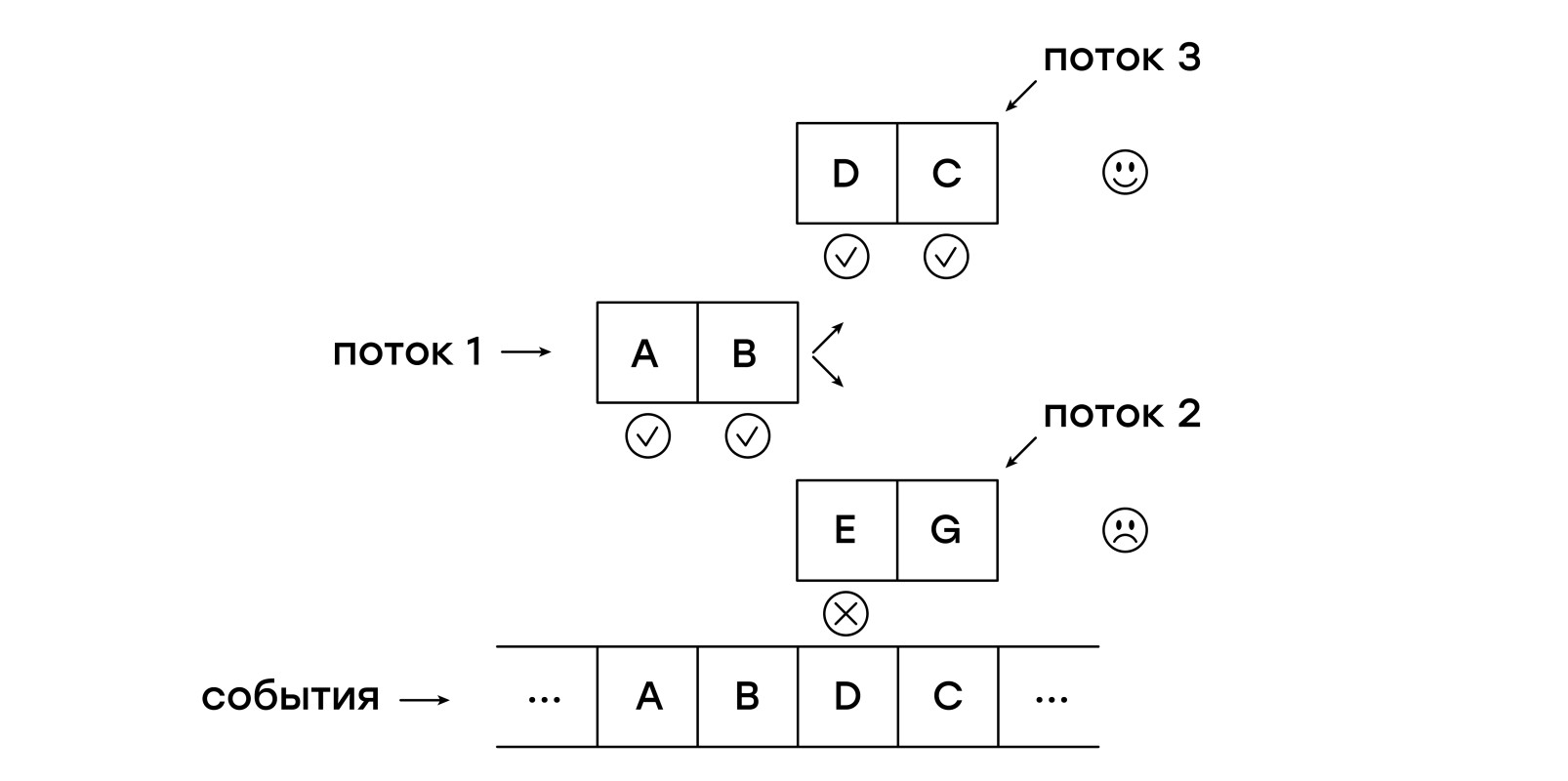
Vamos esboçar mais uma vez o problema: precisamos combinar o modelo com os eventos recebidos, iniciando a partir de cada um dos eventos iniciando uma nova comparação. Então, por que não fazemos exatamente isso? Deixe a máquina virtual acompanhar os eventos recebidos em vários segmentos!
Para fazer isso, precisamos obter uma nova entidade - um fluxo. Cada thread armazena um único ponteiro - para a instrução atual:
typedef struct matcher_thread { uint8_t *ip; } matcher_thread;
Naturalmente, agora na própria máquina virtual não armazenaremos o ponteiro explícito. Ele será substituído por duas listas de threads (mais sobre elas abaixo):
typedef struct matcher { uint8_t *bytecode; matcher_thread current_threads[MAX_THREAD_NUM]; uint8_t current_thread_num; matcher_thread next_threads[MAX_THREAD_NUM]; uint8_t next_thread_num; } matcher;
E aqui está o loop principal atualizado:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP(thread) \ (*(thread).ip++) #define NEXT_ARG(thread) \ ((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1]) /* - */ add_current_thread(m, initial_thread(m)); // for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) { matcher_thread current_thread = m->current_threads[thread_i]; bool thread_done = false; while (!thread_done) { uint8_t instruction = NEXT_OP(current_thread); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(current_thread); // , , // next_threads, if (event_name(next_event) != name) thread_done = true; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(current_thread); if (event_screen(next_event) != screen) thread_done = true; break; } case OP_NEXT:{ // , .. // next_threads add_next_thread(m, current_thread); thread_done = true; break; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } } /* , */ swap_current_and_next(m); return MATCH_NEXT; #undef NEXT_OP #undef NEXT_ARG }
Em cada evento recebido, primeiro adicionamos um novo segmento à lista current_threads, verificando o modelo desde o início, após o qual começamos a rastrear a lista current_threads, seguindo cada ponteiro seguindo as instruções.
Se uma instrução NEXT for encontrada, o encadeamento será colocado na lista next_threads, ou seja, aguarda o recebimento do próximo evento.
Se o padrão de encadeamento não corresponder ao evento recebido, esse encadeamento simplesmente não será adicionado à lista next_threads.
A instrução MATCH sai imediatamente da função, relatando um código de retorno que o padrão corresponde à sessão.
Após a conclusão do rastreamento da lista de threads, as listas atual e seguinte são trocadas.
Na verdade, é tudo. Podemos dizer que estamos literalmente fazendo o que queríamos: ao mesmo tempo, estamos verificando vários modelos, lançando um novo processo de correspondência para cada um dos eventos da sessão.
Várias identidades e ramificações em modelos
Procurar um modelo que descreva uma sequência linear de eventos é, obviamente, útil, mas queremos obter expressões regulares completas. E os fluxos que criamos no estágio anterior também são úteis aqui.
Suponha que desejemos encontrar uma sequência de dois ou três eventos que nos interessem, algo como uma expressão regular nas linhas: "a? Bc". Nesta sequência, o símbolo "a" é opcional. Como expressá-lo em bytecode? Fácil!
Podemos iniciar dois threads, um para cada caso: com o símbolo "a" e sem ele. Para isso, introduzimos uma instrução adicional (do tipo SPLIT addr1, addr2), que inicia dois threads a partir dos endereços especificados. Além do SPLIT, o JUMP também é útil para nós, que simplesmente continua a execução com a instrução especificada no argumento direto:
typedef enum matcher_opcode { OP_ABORT, OP_NAME, OP_SCREEN, OP_NEXT,
O loop em si e o restante das instruções não mudam - apenas apresentamos dois novos manipuladores:
Observe que as instruções adicionam threads à lista atual, ou seja, continuam funcionando no contexto do evento atual. O segmento no qual ocorreu a ramificação não entra na lista dos seguintes segmentos.
A coisa mais surpreendente sobre essa máquina virtual de expressão regular é que nossos threads e este par de instruções são suficientes para expressar quase todas as construções geralmente aceitas ao combinar strings.
Expressões regulares em eventos
Agora que temos uma máquina virtual e ferramentas adequadas para isso, podemos lidar com a sintaxe de nossas expressões regulares.
A gravação manual de opcodes para programas mais graves se cansa rapidamente. Da última vez, não fiz um analisador completo, mas o usuário do true grue mostrou os recursos de sua biblioteca raddsl usando a minilíngua PigletC como exemplo . Fiquei tão impressionado com a brevidade do código que, com a ajuda do raddsl, escrevi um pequeno compilador de expressões regulares de strings em cem ou duzentos em Python. O compilador e as instruções para seu uso estão no GitHub. O resultado do compilador na linguagem assembly é entendido por um utilitário que lê dois arquivos (um programa para uma máquina virtual e uma lista de eventos da sessão para verificação).
Para começar, nos restringimos ao tipo e contexto do evento. O tipo de evento é indicado por um único número; se você precisar especificar um contexto, especifique-o através de dois pontos. O exemplo mais simples:
> python regexp/regexp.py "13" # , 13 NEXT NAME 13 MATCH
Agora um exemplo com contexto:
python regexp/regexp.py "13:12" # 13, 12 NEXT NAME 13 SCREEN 12 MATCH
Eventos sucessivos devem ser separados de alguma forma (por exemplo, por espaços):
> python regexp/regexp.py "13 11 10:9" 08:40:52 NEXT NAME 13 NEXT NAME 11 NEXT NAME 10 SCREEN 9 MATCH
Modelo mais interessante:
> python regexp/regexp.py "12|13" SPLIT L0 L1 L0: NEXT NAME 12 JUMP L2 L1: NEXT NAME 13 L2: MATCH
Preste atenção nas linhas que terminam com dois pontos. Essas são tags. A instrução SPLIT cria dois threads que continuam a execução dos rótulos L0 e L1, e o JUMP no final do primeiro ramo de execução simplesmente prossegue para o final do ramo.
Você pode escolher entre cadeias de expressões mais verdadeiramente agrupando subseqüências entre parênteses:
> python regexp/regexp.py "(1 2 3)|4" SPLIT L0 L1 L0: NEXT NAME 1 NEXT NAME 2 NEXT NAME 3 JUMP L2 L1: NEXT NAME 4 L2: MATCH
Um evento arbitrário é indicado por um ponto:
> python regexp/regexp.py ". 1" NEXT NEXT NAME 1 MATCH
Se queremos mostrar que a subsequência é opcional, colocamos um ponto de interrogação depois dela:
> python regexp/regexp.py "1 2 3? 4" NEXT NAME 1 NEXT NAME 2 SPLIT L0 L1 L0: NEXT NAME 3 L1: NEXT NAME 4 MATCH
Obviamente, várias repetições regulares (mais ou asterisco) também são comuns em expressões regulares:
> python regexp/regexp.py "1+ 2" L0: NEXT NAME 1 SPLIT L0 L1 L1: NEXT NAME 2 MATCH
Aqui, simplesmente executamos a instrução SPLIT várias vezes, iniciando novos threads em cada ciclo.
Da mesma forma com um asterisco:
> python regexp/regexp.py "1* 2" L0: SPLIT L1 L2 L1: NEXT NAME 1 JUMP L0 L2: NEXT NAME 2 MATCH

Perspectiva
Outras extensões para a máquina virtual descrita podem ser úteis.
Por exemplo, ele pode ser facilmente expandido verificando os atributos do evento. Para um sistema real, suponho usar uma sintaxe como “1: 2 {3: 4, 5:> 3}”, o que significa: evento 1 no contexto 2 com o atributo 3 com valor 4 e com o valor 5 maior que 3. Atributos aqui você pode simplesmente transmiti-lo em uma matriz para a função matcher_accept.
Se você também passar o intervalo de tempo entre os eventos para matcher_accept, poderá adicionar uma sintaxe ao idioma do modelo que permite pular o tempo entre os eventos: "1 mindelta (120) 2", o que significa: evento 1, período de pelo menos 120 segundos, evento 2 Combinado com a preservação de uma subsequência, isso permite coletar informações sobre o comportamento do usuário entre duas subsequências de eventos.
Outras coisas úteis que são relativamente fáceis de adicionar são: preservar subsequências de expressões regulares, separar operadores ávidos e comuns de asteriscos e mais, e assim por diante. Em termos da teoria dos autômatos, nossa máquina virtual é um autômato finito não determinístico, cuja implementação não é difícil de fazer.
Conclusão
Nosso sistema foi desenvolvido para interfaces de usuário rápidas, portanto, o mecanismo de armazenamento de sessões é auto-escrito e otimizado especificamente para a passagem por todas as sessões. Todos os bilhões de eventos divididos em sessões são comparados com os padrões em segundos em um único servidor.
Se a velocidade não for tão crítica para você, um sistema semelhante pode ser projetado como uma extensão para um sistema de armazenamento de dados mais padrão, como um banco de dados relacional tradicional ou um sistema de arquivos distribuído.
A propósito, nas versões mais recentes do padrão SQL, um recurso semelhante ao descrito no artigo já apareceu, e bancos de dados individuais ( Oracle e Vertica ) já o implementaram. O Yandex ClickHouse, por sua vez, implementa sua própria linguagem semelhante a SQL, mas também possui funções semelhantes .
Distraindo-me de eventos e expressões regulares, quero repetir que a aplicabilidade das máquinas virtuais é muito mais ampla do que parece à primeira vista. Essa técnica é adequada e amplamente utilizada em todos os casos em que é necessário distinguir claramente entre as primitivas que o mecanismo do sistema entende e o subsistema "front", ou seja, por exemplo, alguma linguagem de programação ou DSL.
Isso conclui uma série de artigos sobre os vários usos de intérpretes de bytecode e máquinas virtuais. Espero que os leitores de Habr tenham gostado da série e, é claro, ficarei feliz em responder a quaisquer perguntas sobre o assunto.
Os intérpretes de bytecode para linguagens de programação são um tópico específico e há relativamente pouca literatura sobre eles. Pessoalmente, gostei do livro Virtual Machines de Ian Craig, apesar de descrever não tanto a implementação de intérpretes quanto as máquinas abstratas - os modelos matemáticos subjacentes a várias linguagens de programação.
Em um sentido mais amplo, outro livro é dedicado às máquinas virtuais - “Máquinas Virtuais: Plataformas Flexíveis para Sistemas e Processos” ("Máquinas Virtuais: Plataformas Versáteis para Sistemas e Processos"). Esta é uma introdução aos vários aplicativos de virtualização, cobrindo a virtualização de linguagens, processos e arquiteturas de computadores em geral.
Os aspectos práticos do desenvolvimento de mecanismos de expressão regular raramente são discutidos na literatura popular sobre compiladores. O Pig Match e o exemplo do primeiro artigo são baseados em idéias de uma incrível série de artigos de Russ Cox, um dos desenvolvedores do mecanismo Google RE2.
A teoria das expressões regulares é apresentada em todos os livros acadêmicos sobre compiladores. É costume se referir ao famoso "Livro dos Dragões" , mas eu recomendaria começar pelo link acima.
Enquanto trabalhava neste artigo, usei pela primeira vez um sistema interessante para o rápido desenvolvimento de compiladores para o Python raddsl , que pertence à caneta do usuário true-grue (obrigado, Peter!). Se você se deparar com a tarefa de criar um protótipo de uma linguagem ou desenvolver rapidamente algum tipo de DSL, preste atenção nela.