Você já reparou como qualquer nicho de mercado, que se tornou popular, atrai profissionais de marketing do comércio de segurança da informação com medo? Eles o convencem de que, no caso de um ataque cibernético, a empresa não poderá lidar com nenhuma das tarefas para responder ao incidente. E aqui, é claro, aparece um tipo de assistente - um provedor de serviços pronto para uma certa quantia para salvar o cliente de qualquer aborrecimento e da necessidade de tomar decisões. Explicamos por que essa abordagem pode ser perigosa não apenas para a carteira, mas também para o nível de segurança da empresa, quais benefícios práticos o envolvimento de um provedor de serviços pode trazer e quais decisões devem sempre permanecer na área de responsabilidade do cliente.

Antes de mais, trataremos da terminologia. Quando se trata de gerenciamento de incidentes, costuma-se ouvir duas abreviações, SOC e CSIRT, cuja importância é importante entender para evitar manipulações de marketing.
SOC (centro de operações de segurança) - uma unidade dedicada às tarefas operacionais de segurança da informação. Na maioria das vezes, ao falar sobre as funções do SOC, as pessoas significam monitorar e identificar incidentes. No entanto, geralmente a responsabilidade do SOC inclui todas as tarefas relacionadas aos processos de segurança da informação, incluindo responder e eliminar as consequências de incidentes, atividades metodológicas para melhorar a infraestrutura de TI e aumentar o nível de segurança da empresa. Ao mesmo tempo, o SOC geralmente é uma unidade de equipe independente, incluindo especialistas de vários perfis.
CSIRT (equipe de resposta a incidentes de segurança cibernética) - uma equipe ou unidade temporariamente formada por um grupo / grupo responsável por responder a incidentes emergentes. O CSIRT geralmente possui um backbone permanente, composto por profissionais de segurança da informação, administradores do SZI e um grupo de peritos forenses. No entanto, em cada caso, a composição final da equipe é determinada pelo vetor de ameaça e pode ser complementada pelo serviço de TI, pelos proprietários dos sistemas de negócios e até pela gerência da empresa com um serviço de relações públicas (para nivelar o fundo negativo na mídia).
Apesar de, em suas atividades, o CSIRT ser mais frequentemente guiado pelo padrão NIST, que inclui um ciclo completo de gerenciamento de incidentes, atualmente a ênfase no espaço de marketing é mais frequentemente colocada nas atividades de resposta, negando essa função ao SOC e contrastando esses dois termos.
O conceito de SOC é mais amplo em relação ao CSIRT? Na minha opinião sim. Em suas atividades, o SOC não se limita a incidentes, pode contar com dados de inteligência cibernética, previsões e análises do nível de segurança da organização e incluir tarefas mais amplas de segurança.
Mas voltando ao padrão NIST, como uma das abordagens mais populares que descrevem o procedimento e as fases do gerenciamento de incidentes. O procedimento geral do padrão NIST SP 800-61 é o seguinte:
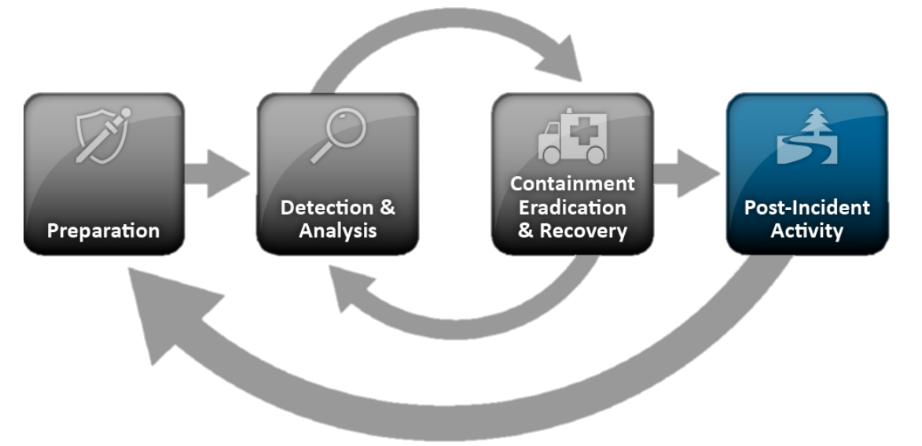
- Preparação:
- Criando a infraestrutura técnica necessária para trabalhar com incidentes
- Criar regras de detecção de incidentes
- Identificação e análise de incidentes:
- Monitoramento e identificação
- Análise de incidentes
- Priorização
- Alerta
- Localização, neutralização e recuperação:
- Localização de incidentes
- Coleta, armazenamento e documentação de sinais de incidentes
- Mitigação de desastres
- Recuperação pós-incidente
- Atividade metódica:
- Resumo do incidente
- Preenchimento da base de conhecimento + inteligência de ameaças
- Medidas organizacionais e técnicas
Apesar do fato do padrão NIST ser dedicado à resposta a incidentes, uma parte significativa da resposta é ocupada pela seção "Detecção e análise de incidentes", que na verdade descreve as tarefas clássicas de monitoramento e processamento de incidentes. Por que eles recebem tanta atenção? Para responder à pergunta, vamos dar uma olhada em cada um desses blocos.
Preparação
A tarefa de identificar incidentes começa com a criação e o "desembarque" de um modelo de ameaça e um modelo de intruso nas regras para identificação de incidentes. Você pode detectar incidentes analisando eventos de segurança da informação (logs) de várias ferramentas de proteção de informações, componentes da infraestrutura de TI, sistemas de aplicativos, elementos de sistemas tecnológicos (ACS) e outros recursos de informações. Obviamente, você pode fazer isso manualmente, com scripts, relatórios, mas para a detecção em tempo real de incidentes de segurança da informação, ainda são necessárias soluções especializadas.
Os sistemas SIEM vêm em socorro aqui, mas sua operação não é menos uma busca do que a análise de logs "brutos" e, em cada estágio, desde a conexão de fontes até a criação de regras de incidentes. As dificuldades estão relacionadas ao fato de que eventos provenientes de fontes diferentes devem ter uma aparência uniforme, e os principais parâmetros de eventos devem mapear os mesmos campos de eventos no SIEM, independentemente da classe / fabricante do sistema ou hardware.
As regras para detecção de incidentes, listas de indicadores de comprometimento, tendências de ameaças cibernéticas formam o chamado "conteúdo" do SIEM. Ele deve executar as tarefas de coleta de perfis de atividades da rede e do usuário, coleta de estatísticas de eventos de vários tipos e identificação de incidentes típicos de segurança da informação. A lógica para acionar as regras de detecção de incidentes deve levar em consideração a infraestrutura e os processos de negócios de uma empresa em particular.
Como não há infraestrutura padrão da empresa e dos processos de negócios, não pode haver conteúdo unificado do sistema SIEM. Portanto, todas as alterações na infraestrutura de TI da empresa devem ser refletidas em tempo hábil, tanto nas configurações e ajustes dos equipamentos de segurança quanto no SIEM. Se o sistema foi configurado apenas uma vez, no início da prestação de serviços, ou é atualizado uma vez por ano, isso reduz as chances de detectar incidentes militares e filtrar com êxito os falsos positivos várias vezes.
Portanto, configurar recursos de segurança, conectar fontes ao sistema SIEM e adaptar o conteúdo do SIEM são tarefas primordiais na resposta a incidentes, uma base sem a qual é impossível seguir em frente. Afinal, se o incidente não foi registrado em tempo hábil e não passou pelas fases de identificação e análise, não estamos mais falando sobre nenhuma resposta, podemos apenas trabalhar com suas conseqüências.
Detecção e análise de incidentes
O serviço de monitoramento deve trabalhar com incidentes no modo em tempo real 24 horas por dia e sete dias por semana. Essa regra, como os princípios básicos de segurança, está escrita em sangue: aproximadamente metade dos ataques cibernéticos críticos começa à noite, muitas vezes na sexta-feira (esse foi o caso, por exemplo, do vírus ransomware WannaCry). Se você não tomar medidas de proteção dentro da primeira hora, já pode ser muito brega. Nesse caso, basta transferir todos os incidentes registrados para a próxima etapa descrita no padrão NIST, ou seja, para o estágio de localização, é impraticável, e aqui está o porquê:
- Obter informações adicionais sobre o que está acontecendo ou filtrar um falso positivo é mais fácil e mais correto no estágio da análise, em vez da localização do incidente. Isso permite minimizar o número de incidentes referidos nos próximos estágios do processo de resposta a incidentes, nos quais especialistas de nível superior devem estar envolvidos em sua consideração - gerentes de gerenciamento de incidentes, equipes de resposta, sistemas de TI e administradores de SIS. É mais lógico criar o processo de forma a não escalar cada ninharia, inclusive falsos positivos, para o nível CISO.
- A resposta e a "supressão" de um incidente sempre traz riscos aos negócios. Responder a um incidente pode incluir trabalho para bloquear o acesso suspeito, isolar o host e subir para o nível de liderança. No caso de um falso positivo, cada uma dessas etapas afetará diretamente a disponibilidade dos elementos de infraestrutura e forçará a equipe de gerenciamento de incidentes a "extinguir" sua própria escalação por um longo tempo com relatórios e memorandos de várias páginas.
Geralmente, a primeira linha de engenheiros trabalha no serviço de monitoramento 24 horas por dia, 7 dias por semana, diretamente envolvidos no processamento de incidentes em potencial registrados pelo sistema SIEM. O número de incidentes desse tipo pode atingir vários milhares por dia (mais uma vez - ainda mais no estágio de localização?), Mas, felizmente, a maioria deles se encaixa em padrões conhecidos. Portanto, para aumentar a velocidade do processamento, você pode usar scripts e instruções que descrevem passo a passo as ações necessárias.
Essa é uma prática comprovada que permite reduzir a carga nas linhas 2 e 3 dos analistas - eles serão transferidos apenas para os incidentes que não se encaixam em nenhum dos scripts existentes. Caso contrário, a escalada de incidentes na segunda e terceira linha de monitoramento chegará a 80% ou na primeira linha será necessário colocar especialistas caros com alta experiência e um longo período de treinamento.
Assim, além dos funcionários de primeira linha, são necessários analistas e arquitetos que criem scripts e instruções, treinam especialistas de primeira linha, criam conteúdo no SIEM, conectam fontes, mantêm operacionalidade e integram o SIEM aos sistemas de classe IRP, CMDB e muito mais.
Uma tarefa importante de monitoramento é a pesquisa, processamento e implementação de vários bancos de dados de reputação, relatórios APT, boletins e assinaturas no sistema SIEM, que acabam se transformando em indicadores de comprometimento (IoC). São eles que permitem identificar ataques encobertos por invasores à infraestrutura, malware que não é detectado por fornecedores de antivírus e muito mais. No entanto, como conectar fontes de eventos ao sistema SIEM, adicionar todas essas informações sobre ameaças exige a resolução de várias tarefas:
- Automação de adição de indicadores
- Avaliação de sua aplicabilidade e relevância
- Priorização e contabilização da obsolescência da informação
- E o mais importante - uma compreensão dos meios de proteção que você pode obter informações para verificar esses indicadores. Se tudo é muito simples com os de rede - verificando firewalls e proxies, então com os de host é mais difícil - com o que comparar hashes, como em todos os hosts para verificar processos em execução, ramificações de registro e arquivos gravados no disco rígido?
Acima, mencionei apenas uma parte dos aspectos do processo de monitoramento e análise de incidentes que qualquer empresa que criar um processo de resposta a incidentes terá que enfrentar. Na minha opinião, essa é a tarefa mais importante em todo o processo, mas vamos seguir em frente e avançar para a unidade de trabalho com incidentes de segurança da informação já registrados e analisados.
Localização, neutralização e recuperação
Este bloco, de acordo com alguns especialistas em segurança da informação, é o fator determinante na diferença entre a equipe de monitoramento e a equipe de resposta a incidentes. Vamos dar uma olhada no que o NIST coloca nele.
Localização de incidentes
De acordo com o NIST, a principal tarefa no processo de localização de incidentes é desenvolver uma estratégia, ou seja, determinar medidas para impedir a propagação do incidente na infraestrutura da empresa. O complexo dessas medidas pode incluir várias ações - isolar os hosts envolvidos no incidente no nível da rede, alternar os modos operacionais das ferramentas de proteção de informações e até interromper os processos de negócios da empresa para minimizar os danos causados pelo incidente. De fato, a estratégia é um manual, que consiste em uma matriz de ações, dependendo do tipo de incidente.
A implementação dessas ações pode estar relacionada à área de responsabilidade da mudança do suporte técnico de TI, proprietários e administradores de sistemas (incluindo sistemas de negócios), empresa terceirizada e serviço de segurança da informação. As ações podem ser executadas manualmente, pelos componentes do EDR e até scripts auto-escritos usados pelo comando.
Como as decisões tomadas nesse estágio podem afetar diretamente os processos de negócios da empresa, a decisão de aplicar uma estratégia específica na grande maioria dos casos permanece como tarefa de um gerente interno de segurança da informação (geralmente envolvendo proprietários de sistemas de negócios), e
essa tarefa não pode ser terceirizada. empresa . O papel do provedor de serviços de segurança da informação na localização do incidente é reduzido à aplicação operacional da estratégia escolhida pelo cliente.
Coleta, armazenamento e documentação dos sinais de incidentes
Depois que medidas operacionais foram tomadas para localizar o incidente, uma investigação completa deve ser realizada, reunindo todas as informações para avaliar a extensão. Esta tarefa é dividida em duas subtarefas:
- Transferindo informações adicionais para a equipe de monitoramento, conectando fontes adicionais de eventos de segurança da informação envolvidos no incidente ao sistema de coleta e análise de eventos.
- Conectando a equipe forense para analisar imagens de disco rígido, analisar despejos de memória, amostras de malware e ferramentas usadas por criminosos cibernéticos neste incidente.
Uma pessoa também deve ser designada para coordenar as atividades de todas as unidades dentro da estrutura da investigação do incidente. Esse especialista deve ter a autoridade e os contatos de todo o pessoal envolvido na investigação. Um funcionário contratado pode desempenhar essa função? Provavelmente não, sim. É mais lógico confiar essa função a um especialista ou ao chefe do serviço de segurança de informações do cliente.
Mitigação de desastres
Tendo recebido uma imagem completa do incidente de vários departamentos, o coordenador desenvolve medidas para eliminar as conseqüências do incidente. Este procedimento pode incluir:
- Remoção de indicadores identificados de comprometimento e vestígios da presença de malware / intrusos.
- "Recarregando" hosts infectados e alterando senhas de usuários.
- Instalar as atualizações mais recentes e desenvolver medidas compensatórias para eliminar vulnerabilidades críticas usadas no ataque.
- Alterando os perfis de segurança do GIS.
- Controle sobre a integridade das ações executadas pelas unidades envolvidas e a ausência de comprometimento dos sistemas pelos invasores.
Ao desenvolver medidas, recomendamos que o coordenador consulte as unidades especializadas responsáveis por sistemas específicos, os administradores do sistema de segurança da informação, o grupo forense e o serviço de monitoramento de incidentes de SI. Mas, novamente, a decisão final sobre a aplicação de certas medidas é tomada pelo coordenador do grupo de análise de incidentes.
Recuperação pós-incidente
Nesta seção, o NIST fala sobre as tarefas do departamento de TI e do serviço de operações de sistemas de negócios. Todo o trabalho é reduzido para restaurar e verificar o desempenho dos sistemas de TI e processos de negócios da empresa. Não faz sentido insistir nesse ponto, já que a maioria das empresas enfrenta a solução desses problemas, se não como resultado de incidentes de segurança da informação, pelo menos após falhas que ocorrem periodicamente, mesmo nas instalações de sistemas mais estáveis e tolerantes a falhas.
Atividade metódica
A quarta seção da metodologia de resposta a incidentes é dedicada ao trabalho em bugs e à melhoria das tecnologias de segurança da empresa.
Para a preparação de um relatório de incidente, preenchendo a base de conhecimento e a TI, como regra, a equipe forense é responsável em conjunto com o serviço de monitoramento. Se uma estratégia de localização não foi desenvolvida no momento para este incidente, sua gravação será incluída neste bloco.
Bem, é óbvio que um ponto muito importante no trabalho com bugs é desenvolver uma estratégia para evitar incidentes semelhantes no futuro:
- Alterando a arquitetura da infraestrutura de TI e o GIS existente.
- A introdução de novas ferramentas de segurança da informação.
- Introdução do processo de gerenciamento de patches e monitoramento de incidentes de segurança da informação (se ausentes).
- Correção de processos de negócios da empresa.
- Pessoal adicional no departamento de segurança da informação.
- Mudança de autoridade dos funcionários de segurança da informação.
Função de Provedor de Serviços
Assim, a possível participação do provedor de serviços em vários estágios de resposta a incidentes pode ser representada na forma de uma matriz:
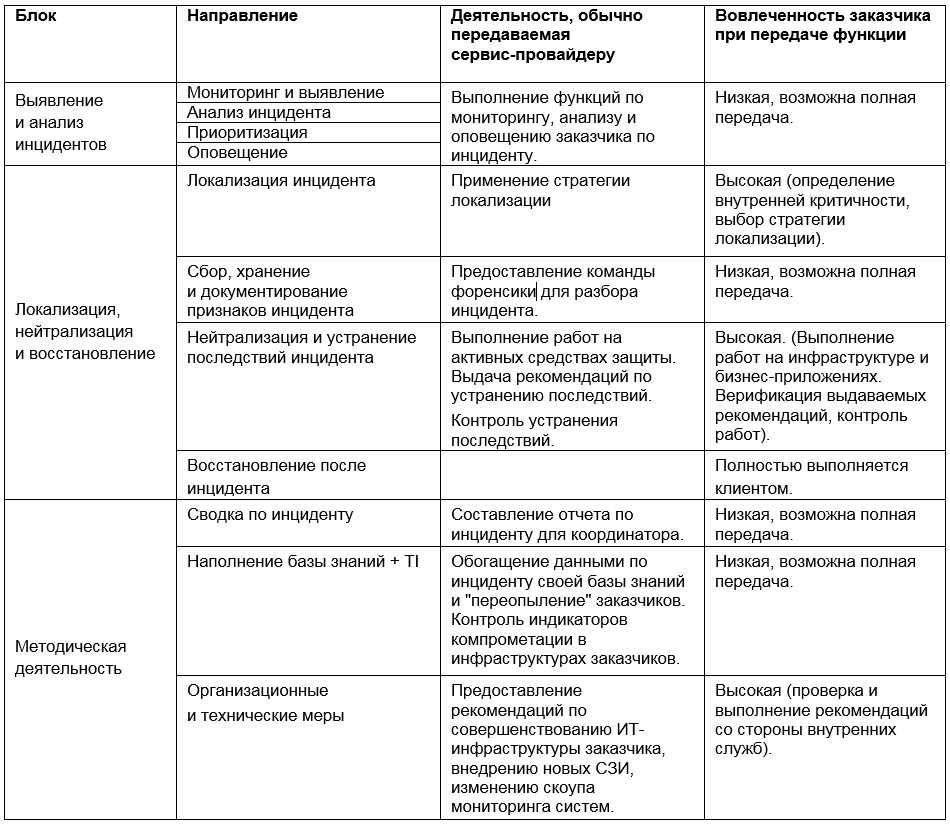
A escolha de ferramentas e abordagens para o gerenciamento de incidentes é uma das tarefas mais difíceis de segurança da informação. A tentação de confiar nas promessas de um provedor de serviços e fornecer todas as funções pode ser grande, mas aconselhamos uma avaliação sólida da situação e um equilíbrio entre o uso de recursos internos e externos - no interesse da eficiência econômica e do processo.