
Você está pronto para novos desafios? Convidamos todos os amadores e profissionais do campeonato para o design e administração de serviços altamente carregados
HighLoad Cup # 2 !
A competição começou no ano passado. Sabíamos então que a HighLoad Cup é exatamente o campeonato que estava faltando em vários projetos do Mail.Ru Group. A primeira competição piloto contou com a presença de 449 pessoas. Havia muito código e muito suor tanto dos organizadores quanto dos participantes (8789 soluções diferentes). Havia nuances na implementação técnica, mas o mais importante é que todos gostaram! Os organizadores passaram muitas noites no data center, vários dias de folga no escritório. Pronto para isso de novo! No final do artigo, você encontrará materiais úteis de nós e dos participantes, o que o ajudará a entender a mecânica e a encontrar algumas soluções de melhores práticas.
Desta vez, eles tentaram preparar para você um negócio mais difícil. Além disso, expandimos o público, agora usuários de língua inglesa podem participar da competição. Participe da comunidade de língua russa no
Telegram . Lá você terá muitas idéias sobre a competição :)
Então seja bem-vindo a bordo!
A mecânica
Comparado ao ano passado, nada mudou conceitualmente na competição.
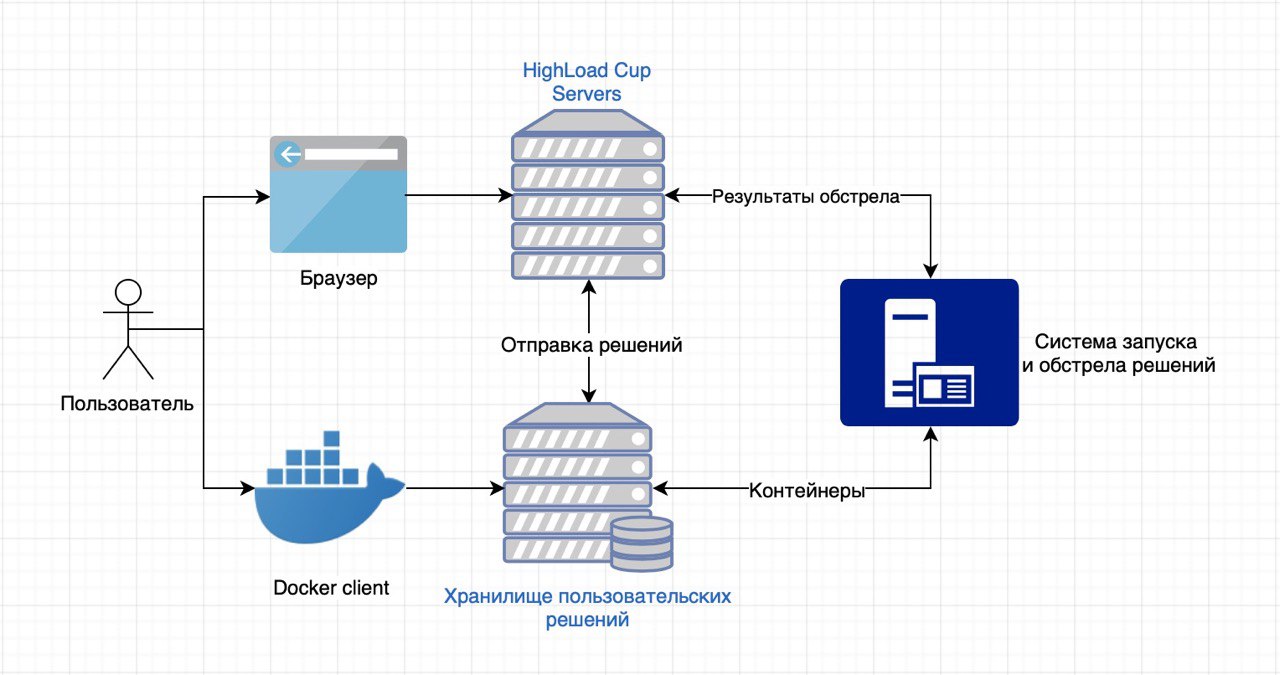
Os participantes têm a tarefa de criar um pequeno serviço da web que trabalha com dados de uma determinada estrutura e implementa uma API para esses dados. Um contêiner (Docker) com o serviço implementado é carregado em nossos servidores, onde o iniciamos e começamos a descascar com solicitações HTTP.
As soluções são enviadas para nós usando um cliente Docker instalado localmente em um repositório especial (cada um possui seu próprio). Em seguida, o serviço enviado a nós é verificado automaticamente pelo sistema CodeHub-CodeRunner desenvolvido pela equipe do Laboratório Mail.Ru Group Technopark.
Então começamos a "martelar" o contêiner em uma máquina de teste com um processador Intel Core i7. A solução receberá 4 núcleos de 2,4 GHz, 2 GB de RAM e 10 GB de espaço em disco rígido. Em resumo, um "tanque" é lançado com o motor fantasma, que dispara em vários fluxos com um perfil de carga que cresce linearmente. Antes do início do bombardeio, a solução do usuário tem vários minutos (a quantidade exata depende da tarefa) para processar os dados do arquivo JSON recebido. O trabalho correto com esses dados é uma condição necessária para a vitória. Descascar apenas dois, curtos e longos.
Com base nos resultados de tais ataques, calculamos o número de respostas corretas e incorretas, RPS e velocidade de resposta e formamos uma tabela de classificação para uma determinada métrica. O autor do serviço mais rápido e mais tolerante a falhas será o vencedor.
Use qualquer tecnologia da Web que você possa encontrar ou criar. Escolha sua própria linguagem e estrutura de programação. Pode ser C ++, Java + Tomcat, Python + Django, Ruby + RoR, GoLang, JavaScript + NodeJs, Haskell, pelo menos Assembler ou qualquer outra coisa, a seu critério. Para armazenamento de dados: MySQL, PostgreSQL, Redis, MongoDB, caches. Liberdade completa!
Como resultado do bombardeio, são obtidos logs e métricas, que serão mostrados aos participantes na forma de gráficos na página de decisão. Rastreado separadamente:
- métricas básicas;
- resposta correta;
- velocidade de resposta a uma solicitação;
- número de respostas por segundo.
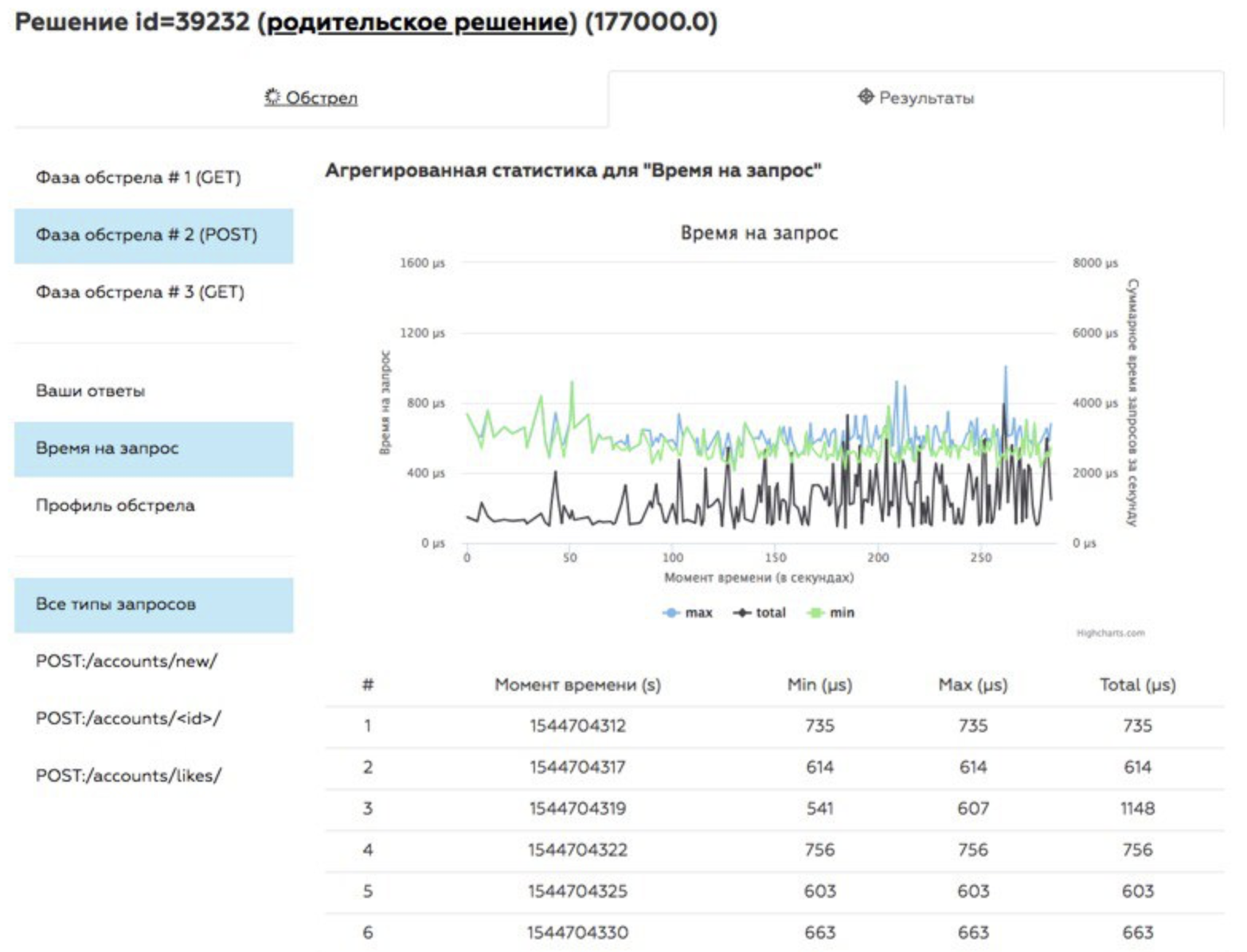
A classificação da solução é calculada da seguinte forma: tomamos o tempo de todas as respostas corretas que a API conseguiu dar durante o bombardeio, adicionamos um tempo de penalidade para cada resposta ou solicitação incorreta da qual não pudemos receber resposta (o tempo de penalidade é sempre igual ao tempo limite total da solicitação). O participante, cujo tempo total é menor que os outros, é maior na tabela de classificação e tem chance de se tornar o vencedor do campeonato.
Desafio
Nossa equipe pensou por muito tempo que tarefa dar este ano. Eles queriam algo que igualasse as chances da maioria (para que algumas motos feitas em C / C ++ não vencessem).
A redação é a seguinte:
Em uma realidade alternativa, a humanidade decidiu criar e lançar um sistema de busca global para o "segundo semestre". Ele foi projetado para reduzir o número de pessoas solteiras no mundo e ajudar a criar famílias fortes.
Nos dados de teste e de "combate" para vários bombardeios, há entradas sobre uma entidade: Conta. Ele descreve todas as informações conhecidas sobre o usuário - seu nome, contatos, interesses e simpatia revelada por outros usuários. A precisão dos dados fornecidos é garantida de acordo com os tipos e limitações indicados abaixo. Todos os dados foram gerados e inventados por nós de acordo com certas leis.
Os seguintes dados pessoais estão contidos em um registro da conta:
- id - identificador externo exclusivo do usuário. É instalado pelo sistema de teste e, em seguida, usado para verificar as respostas do servidor. Type é um número inteiro de 32 bits.
- email - o endereço de email do usuário. Tipo - sequência unicode com até 100 caracteres. Exclusividade garantida.
- fname e sname - nome e sobrenome, respectivamente. Tipo - cadeias unicode com até 50 caracteres. Os campos são opcionais e podem não estar presentes em um registro específico.
- telefone - número de celular. Type é uma string unicode com até 16 caracteres. O campo é opcional, mas a exclusividade é garantida para os valores especificados. É preenchido muito raramente.
- o sexo é uma cadeia unicode, "m" significa masculino e "f" significa feminino.
- data de nascimento, registrada como o número de segundos desde o início da era UNIX no UTC (em outras palavras, esse é um carimbo de data / hora). Limitado abaixo de 01/01/1950, acima de 01/01/2005.
- país - país de residência. Type é uma string unicode com até 50 caracteres. O campo é opcional.
- cidade - cidade de residência. Type é uma string unicode com até 50 caracteres. O campo é opcional e raramente é especificado. Cada cidade está localizada em um país específico.
Além disso, em um registro da conta, existem campos específicos para o mecanismo de pesquisa para o segundo semestre:
- ingressou - data do registro no sistema. Tipo - registro de data e hora com restrições: abaixo de 01.01.2011, acima de 01.01.2018.
- status - o status atual do usuário no sistema. Digite - uma linha das seguintes opções: "livre", "ocupado", "tudo é complicado". Não preste atenção aos finais estranhos :)
- interesses - interesses do usuário na vida cotidiana. Tipo - uma matriz de cadeias unicode, possivelmente vazia. As linhas não excedem 100 caracteres.
- premium - o início e o final do período premium no sistema (quando os usuários realmente queriam encontrar uma “alma gêmea” e pagavam pelo serviço). No JSON, esse campo é representado por um objeto aninhado com os campos de início e término, onde os registros de data e hora com um limite inferior são registrados em 01/01/2018.
- likes - um conjunto de curtidas conhecidas do usuário, possivelmente vazias. Todas as simpatias são diferentes e cada uma representa um objeto dos seguintes campos:
- id - o identificador de outra conta que o usuário gosta. A conta sempre pode ser encontrada nos dados de origem por ID. Observe que nos dados pode haver vários gostos com o mesmo ID.
- ts - hora, isto é, carimbo de data e hora, quando a simpatia foi registrada no sistema.
Você precisa implementar a API.
- Obtendo uma lista de usuários: / accounts / filter /
Este método de API está planejado para ser usado para procurar usuários em campos previamente conhecidos ou desejados. Por exemplo, alguém queria ver todas as pessoas de uma certa idade e sexo vivendo em uma cidade específica. - Agrupando usuários: / accounts / group /
Este método de API está planejado para ser usado para criar relatórios sobre a operação do sistema. Os campos usados para o agrupamento são passados nas chaves de parâmetro GET separadas por vírgulas. Eles não são tão numerosos quanto na solicitação de filtragem do usuário. Existem apenas cinco campos para agrupar - sexo, status, interesses, país, cidade. - Recomendações de compatibilidade: / accounts / id / recommend /
Esta consulta é usada para procurar a "segunda metade" nos dados do usuário especificados. A solicitação passa o ID do usuário para quem são pesquisados aqueles que melhor se adequam a status, idade e interesses. A decisão deve verificar a compatibilidade apenas com o sexo oposto (não somos contra minorias sexuais e condenamos a discriminação, apenas aconteceu :)). Se o país ou a cidade com as chaves do país e da cidade, respectivamente, for transmitido na solicitação GET, será necessário pesquisar apenas entre aqueles que moram no local especificado. - Correspondência de gostos semelhantes: / accounts / id / Suggest /
Esse tipo de consulta é semelhante ao anterior, pois também trata da pesquisa de "almas gêmeas". O id do usuário para quem estamos procurando uma alma gêmea também é enviado, o parâmetro limit GET é usado. Diferenças na implementação: procuramos pessoas do mesmo sexo com "gostos" semelhantes e oferecemos àqueles de quem recentemente gostaram. Se a solicitação receber o parâmetro GET do país ou cidade, será necessário procurar "simpatias semelhantes" apenas em um determinado local.
Contar tudo em um artigo não é possível. As regras detalhadas serão publicadas no dia do lançamento (hoje) no site do campeonato e no repositório do
GitHub , mas agora você sabe o que o espera.
Horário
Sim, sabemos que os feriados (com o próximo), então o campeonato será muito longo :)
- Teste beta (os resultados não são levados em consideração): inicie em 13 de dezembro às 19:00 e termine em 21 de dezembro às 19:00.
- Fase de qualificação: de 21 de dezembro às 19:00 e 31 de janeiro às 19:00.
- Rodada final: até 5 de fevereiro.
Durante o teste beta, as regras e condições da tarefa podem mudar (na presença de bugs e por outros motivos).
Fase de qualificação - as regras não mudam.
A rodada final é totalmente automática, mas antes dela os finalistas (N usuários que passaram nos resultados da rodada de qualificação e pelo menos 50 pessoas) escolhem uma solução que será disparada em várias ondas. O resultado é formado pelo melhor resultado para todas as ondas.
Apresenta
O primeiro lugar é o novo MacBook Air.
Segundo e terceiro lugar - Apple iPad.
Quarto, quinto e sexto lugares - Samsung Gear S3.
O participante tem o direito de pedir outra doação de valor equivalente em troca. Todos os participantes que se qualificarem para as finais receberão camisetas com a marca do nosso campeonato.
Comunidade
Se você for à nossa sala de bate-papo do
Telegram , é improvável que já a deixe. Estamos esperando por você, e boa sorte!
Agradecimentos
Este artigo não aborda problemas de atualização do sistema. Fizemos muito trabalho para eliminar erros de infraestrutura, revisamos todos os
problemas dos participantes do GitHub, já implementamos algo e o colocamos na lista TODO para o próximo ano. Quero expressar minha
profunda gratidão a Maxim
@ xammi- Kislenko, Ilya
@liofz Lebedev, Eugene
@gunicorn Ivanov, Irina
@aithelle Lukyanova, Vasily
@vasidmi Dmitriev e toda a equipe que participou da competição, incluindo toda a comunidade do campeonato. Obrigada
Literatura útil sobre os resultados da HighLoad Cup 2017