Desafio
Uma das grandes tarefas do aplicativo para armazenar e analisar compras é procurar produtos idênticos ou muito próximos no banco de dados, que contém nomes variados e obscuros de produtos obtidos de recibos. Existem dois tipos de solicitação de entrada:
- Um nome específico com abreviações, que só pode ser entendido por caixas em um supermercado local ou compradores ávidos.
- Uma consulta de idioma natural inserida pelo usuário na cadeia de pesquisa.
Normalmente, os pedidos do primeiro tipo são provenientes dos produtos no próprio cheque, quando o usuário precisa encontrar produtos mais baratos. Nossa tarefa é selecionar o produto análogo mais semelhante no check-in em outras lojas próximas. É importante escolher a marca de produto mais adequada e, se possível, o volume.
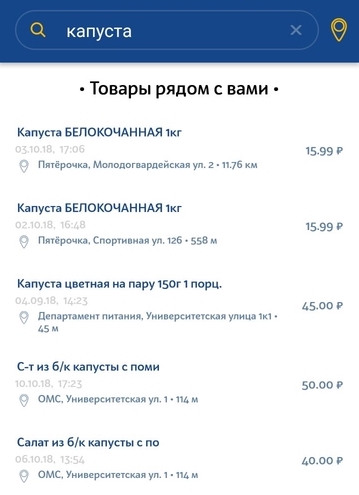
O segundo tipo de solicitação é uma solicitação simples do usuário para procurar um produto específico na loja mais próxima. A solicitação pode ser uma descrição muito geral e não exclusiva do produto. Pode haver pequenos desvios da solicitação. Por exemplo, se um usuário procurar leite 3,2% e, em nosso banco de dados, apenas 2,5% leite, ainda queremos mostrar pelo menos esse resultado.
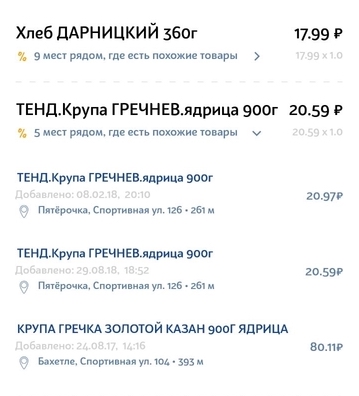
Conjunto de dados de recursos - problemas a serem resolvidos
As informações no recibo do produto estão longe de serem ideais. Nem sempre existem muitas abreviações claras, erros gramaticais, erros de digitação, várias traduções, letras latinas no meio do alfabeto cirílico e conjuntos de caracteres que fazem sentido apenas para a organização interna de uma loja em particular.
Por exemplo, um purê de maçã e banana com queijo cottage pode ser facilmente escrito no cheque da seguinte maneira:

Sobre a tecnologia
O Elasticsearch é uma tecnologia bastante popular e acessível para implementar a pesquisa. Este é um mecanismo de pesquisa da API JSON REST usando Lucene e escrito em Java. As principais vantagens do Elastic são velocidade, escalabilidade e tolerância a falhas. Mecanismos semelhantes são usados para pesquisas complexas no banco de dados de documentos. Por exemplo, uma pesquisa levando em consideração a morfologia do idioma ou uma pesquisa por coordenadas geográficas.
Instruções para experimentação e aprimoramento
Para entender como você pode melhorar sua pesquisa, é necessário analisar o sistema de pesquisa em seus componentes personalizados. Para o nosso caso, a estrutura do sistema se parece com isso.
- A sequência de entrada da pesquisa passa pelo analisador, que de certa maneira divide a sequência em tokens - unidades de pesquisa que pesquisam entre dados que também são armazenados como tokens.
- Depois, há uma pesquisa direta desses tokens para cada documento no banco de dados existente. Após localizar o token em um determinado documento (que também é apresentado no banco de dados como um conjunto de tokens), sua relevância é calculada de acordo com o modelo de similaridade selecionado (o chamaremos de Modelo de Relevância). Pode ser um TF / IDF simples (Termo Frequência - Frequência Inversa de Documento) ou pode ser outros modelos mais complexos ou específicos.
- No próximo estágio, o número de pontos marcados por cada token individual é agregado de uma certa maneira. Os parâmetros de agregação são definidos pela semântica da consulta. Um exemplo dessas agregações pode ser pesos adicionais para determinados tokens (valor agregado), condições para a presença obrigatória de um token, etc. O resultado desse estágio é Pontuação - a avaliação final da relevância de um documento específico do banco de dados em relação à solicitação inicial.

É possível distinguir três componentes configuráveis separadamente do dispositivo de pesquisa, em cada um dos quais você pode destacar suas próprias maneiras e métodos de aprimoramento.
- Analisadores
- Modelo de similaridade
- Melhorias no tempo de consulta
A seguir, consideraremos cada componente individualmente e analisaremos configurações de parâmetros específicas que ajudaram a melhorar a pesquisa no caso de nomes de produtos.
Melhorias no tempo de consulta
Para entender o que podemos melhorar na solicitação, damos um exemplo da solicitação inicial.
{ "query": { "multi_match": { "query": " 105", "type": "most_fields", "fields": ["name"], "minimum_should_match": "70%" } }, “size”: 100, “min_score”: 15 }
Usamos o tipo de consulta most_fields, pois prevemos a necessidade de uma combinação de vários analisadores para o campo "nome do produto". Esse tipo de consulta permite combinar resultados de pesquisa para diferentes atributos do objeto que contém o mesmo texto, analisados de maneiras diferentes. Uma alternativa a essa abordagem é usar as consultas best_fields ou cross_fields, mas elas não são adequadas para o nosso caso, pois a pesquisa é calculada entre os vários atributos do objeto (por exemplo: nome e descrição). Somos confrontados com a tarefa de levar em consideração vários aspectos de um atributo - o nome do produto.
O que pode ser configurado:
- Combinação ponderada de diferentes analisadores.
Inicialmente, todos os elementos de pesquisa têm o mesmo peso - e, portanto, a mesma importância. Isso pode ser alterado adicionando o parâmetro 'boost', que aceita valores numéricos. Se o parâmetro for maior que 1, o elemento de pesquisa terá um impacto maior nos resultados, respectivamente, menor que 1 - menor. - Separação dos analisadores em 'should' e 'must'.
Nomeadamente, certos analisadores devem coincidir e alguns são opcionais, ou seja, insuficientes. No nosso caso, o analisador de números pode ser um exemplo dos benefícios dessa separação. Se apenas o número corresponder no nome do produto na solicitação e no nome do produto no banco de dados, isso não será uma condição suficiente para sua equivalência. Não queremos ver esses produtos como resultado. Ao mesmo tempo, se a solicitação for "creme 10%", queremos que todo creme com 10% de gordura tenha uma grande vantagem sobre o creme com 20% de gordura. - O parâmetro minimum_should_match. Quantos tokens devem necessariamente corresponder na solicitação e no documento do banco de dados? Este parâmetro trabalha em conjunto com o tipo de nossa solicitação (most_fields) e verifica o número mínimo de tokens correspondentes para cada um dos campos (no nosso caso, para cada analisador).
- Parâmetro Min_score. Documentos de triagem de limite com pontos insuficientes. O problema é que não há velocidade máxima conhecida. A pontuação resultante depende de uma solicitação específica e de um banco de dados específico de documentos. Às vezes, pode ser 150, e às vezes 2, mas esses dois valores significam que o objeto do banco de dados é relevante para a solicitação. Não podemos comparar as pontuações dos resultados de diferentes consultas.
- Constante
Após o monitoramento suficiente dos valores finais da velocidade para consultas diferentes, é possível identificar uma borda aproximada, após a qual, para a maioria das consultas, os resultados se tornam inapropriados. Essa é a decisão mais fácil, mas também a mais estúpida, o que leva a uma pesquisa de baixa qualidade. - Tente analisar as pontuações obtidas para uma solicitação específica após realizar uma pesquisa com mínimo ou zero min_score.
A ideia é que, após um certo momento, você possa observar um salto acentuado na direção da diminuição da velocidade. Resta apenas determinar esse salto para parar a tempo. Essa abordagem funcionaria bem em consultas semelhantes:
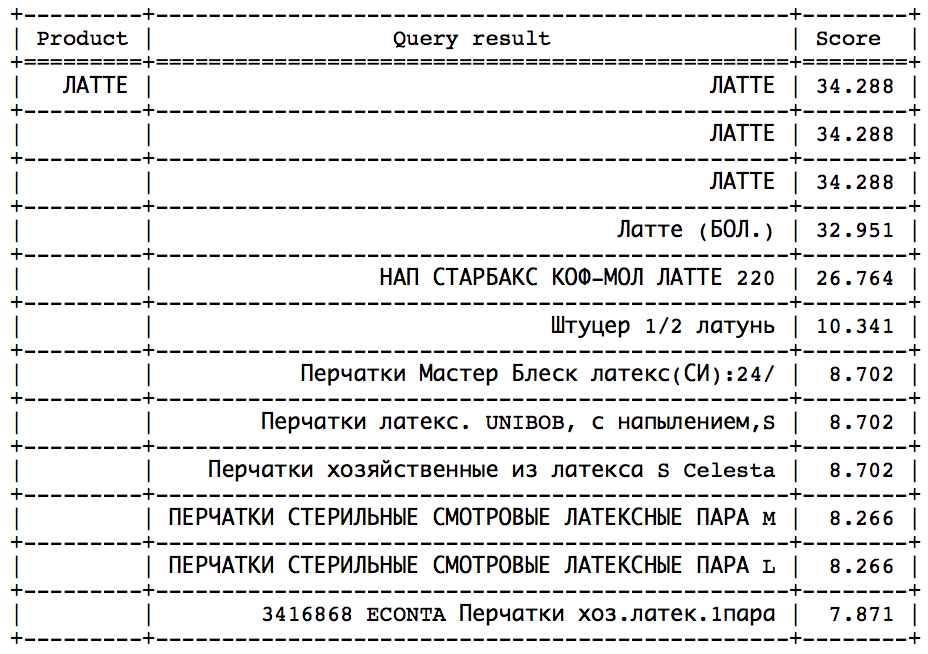
O salto pode ser encontrado por métodos estatísticos. Infelizmente, porém, nem em todas as solicitações esse salto está presente e é facilmente identificável. - Calcule a velocidade ideal e defina min_score como uma certa fração do ideal, o que pode ser feito de duas maneiras:
- A partir da descrição detalhada dos cálculos fornecidos pelo próprio Elastic ao definir o parâmetro explique: true. Essa é uma tarefa difícil, exigindo um entendimento completo da arquitetura de consulta e dos algoritmos computacionais usados pelo Elastic.
- Por um pequeno truque. Recebemos uma solicitação, adicionamos um novo produto ao nosso banco de dados com o mesmo nome, fazemos uma pesquisa e obtemos a velocidade máxima. Como haverá uma correspondência de 100% no nome, o valor resultante será ideal. É essa abordagem que usamos em nosso sistema, pois as preocupações com o alto custo dessa operação em relação ao tempo não foram confirmadas.
- Altere o algoritmo de pontuação, responsável pelo valor final da relevância. Isso pode levar em consideração a distância da loja (dê mais pontos aos produtos mais próximos), preços dos produtos (dê mais pontos aos produtos com o preço mais provável) etc.
Analisadores
O analisador analisa a sequência de entrada em três estágios e gera tokens na saída - unidades de pesquisa:

Primeiro, as alterações ocorrem no nível do caractere da sequência. Isso pode substituir, excluir ou adicionar caracteres a uma sequência. Em seguida, um tokenizador entra em ação, projetado para dividir a string em tokens. O tokenizador padrão divide a string em tokens de acordo com os sinais de pontuação. Na última etapa, os tokens recebidos são filtrados e processados.
Considere quais variações das etapas se tornaram úteis no nosso caso.
Filtros de caracteres
- De acordo com as especificidades do idioma russo, seria útil processar caracteres como th e e substituí-los por e e e, respectivamente.
- Executar transliteração - a transferência de caracteres de uma escrita por caracteres de outra escrita. No nosso caso, esse é o processamento de nomes escritos em latim ou misturados com os dois alfabetos. A transliteração pode ser implementada usando o plug-in ( ICU Analysis Plugin ) como um filtro de token (ou seja, ele processa não a string original, mas os tokens finais). Decidimos escrever nossa transliteração, pois não estávamos muito felizes com o algoritmo no plug-in. A idéia é substituir primeiro as ocorrências do conjunto de quatro caracteres (por exemplo, "SHCH => u”), depois as ocorrências de três caracteres, etc. A ordem na qual os filtros de símbolos são usados é importante, pois o resultado dependerá da ordem.
- Substitua Latin c, cercado por cirílico, por russo p. A necessidade disso foi identificada após a análise dos nomes no banco de dados - muitos nomes em cirílico incluíam o latim c, que significa cirílico c. Quando como se o nome estivesse completamente em latim, o latim C significa cirílico k ou c. Portanto, antes da transliteração, é necessário substituir o caractere c.
- Removendo números muito grandes de nomes. Às vezes, nos nomes dos produtos, há um número de identificação interno (por exemplo, 3387522 K.Ts. Maslo sunflower.raf. 0,9l), que não tem nenhum significado no caso geral.
- Substituindo vírgulas por pontos. Por que isso é necessário? Para que os números, por exemplo, o teor de gordura do leite 3.2 e 3.2 sejam equivalentes
Tokenizer
- Tokenizador padrão - separa as linhas de acordo com o espaço e os sinais de pontuação (por exemplo, "twix extra 2" -> "twix extra", "extra", "2")
- Token EdgeNGram - divide cada palavra em tokens de um determinado comprimento (geralmente um intervalo de números), começando com o primeiro caractere (por exemplo, para N = [3, 6]: "twix extra 2" -> "twee", "tweak", “Twix”, “ex”, “ext”, “ext”, “extra”)
- Tokenizer for numbers - seleciona apenas números de uma string pesquisando uma expressão regular (por exemplo, “twix extra 2 4.5” -> “2”, “4.5”)
Filtro de token
- Filtro em minúsculas
- Filtro de Stamming - executa um algoritmo de stamming para cada token. Stemming é determinar a forma inicial de uma palavra (por exemplo, "arroz" -> "arroz")
- Análise fonética. É necessário para minimizar a influência de erros de digitação e diferentes maneiras de escrever a mesma palavra nos resultados da pesquisa. A tabela mostra os vários algoritmos disponíveis para análise fonética e o resultado de seu trabalho em casos problemáticos. No primeiro caso (Shampoo / champanhe / champignon / champignon), o sucesso é determinado pela geração de codificações diferentes, no restante - o mesmo.

Modelo de similaridade
O modelo de relevância é necessário para determinar em que medida a coincidência de um token afeta a relevância do objeto do banco de dados em relação à solicitação. Suponha que se o token na solicitação e o produto do banco de dados corresponderem - isso certamente não é ruim, mas diz pouco sobre a conformidade do produto com a solicitação. Assim, a coincidência de diferentes tokens carrega valores diferentes. Para levar isso em consideração, é necessário um modelo de relevância. Elastic fornece muitos modelos diferentes. Se você realmente os entende, pode escolher um modelo muito específico e adequado para um caso específico. A escolha pode ser baseada no número de palavras usadas com frequência (como o mesmo token), uma avaliação da importância de tokens longos (quanto mais longo significa melhor? Pior? Não importa?), Que resultados queremos ver no final etc. Exemplos de modelos propostos no Elastic podem ser TF-IDF (o modelo mais simples e compreensível), Okapi BM25 (TF-IDF aprimorado, o modelo padrão), Divergência ao acaso, Divergência à independência, etc. Cada modelo também possui opções personalizáveis. Após várias experiências com o modelo, o modelo padrão Okapi BM25 apresentou o melhor resultado, mas com parâmetros diferentes dos predefinidos.
Usando categorias
No decorrer do trabalho com a pesquisa, informações adicionais muito importantes sobre o produto - sua categoria - foram disponibilizadas. Você pode ler mais sobre como implementamos a categorização no artigo.Como eu entendo, como muitos doces, ou a classificação de mercadorias, verificando o aplicativo . Até então, baseamos nossa pesquisa apenas na comparação de nomes de produtos, agora é possível comparar a categoria de solicitação e produtos no banco de dados.
As opções possíveis para usar essas informações são uma correspondência obrigatória no campo categoria (formatado como um filtro de resultados), uma vantagem adicional na forma de pontos para produtos com a mesma categoria (como no caso de números) e a classificação dos resultados por categoria (primeira correspondência e depois todas as outras). Para o nosso caso, a última opção funcionou melhor. Isso ocorre porque nosso algoritmo de categorização é bom demais para usar o segundo método e não bom o suficiente para usar o primeiro. Estamos confiantes o suficiente no algoritmo e queremos que a correspondência de categoria seja uma grande vantagem. No caso de adicionar pontos adicionais à velocidade (segundo método), as mercadorias da mesma categoria subirão na lista, mas ainda perderão para algumas mercadorias mais correspondidas por nome. No entanto, o primeiro método também não nos convém, pois ainda são possíveis erros na categorização. Às vezes, a solicitação pode conter informações insuficientes para determinar corretamente a categoria ou há muito poucos produtos nessa categoria no raio imediato do usuário. Nesse caso, ainda queremos mostrar resultados com uma categoria diferente, mas ainda relevantes pelo nome do produto.
O segundo método também é bom porque não "estraga" a velocidade dos produtos como resultado da pesquisa e permite que você continue usando a velocidade mínima calculada sem obstáculos.
A implementação específica da classificação pode ser vista na consulta final.
Modelo final
A seleção do modelo final de pesquisa incluiu a geração de vários mecanismos de pesquisa, sua avaliação e comparação. Na maioria das vezes, a comparação foi baseada em um dos parâmetros. Suponha que em um caso específico precisássemos calcular o melhor tamanho para o tokenizador edgeNgram (ou seja, escolha o intervalo mais eficaz de N). Para isso, geramos os mesmos mecanismos de pesquisa, com apenas uma diferença no tamanho desse intervalo. Depois disso, foi possível determinar o melhor valor para esse parâmetro.
Os modelos foram avaliados usando a métrica nDCG (ganho cumulativo descontado descontado normalizado), uma métrica para avaliar a qualidade do ranking. Consultas predefinidas foram enviadas para cada modelo de pesquisa, após o qual a métrica nDCG foi calculada com base nos resultados de pesquisa recebidos.
Analisadores que entraram no modelo final:



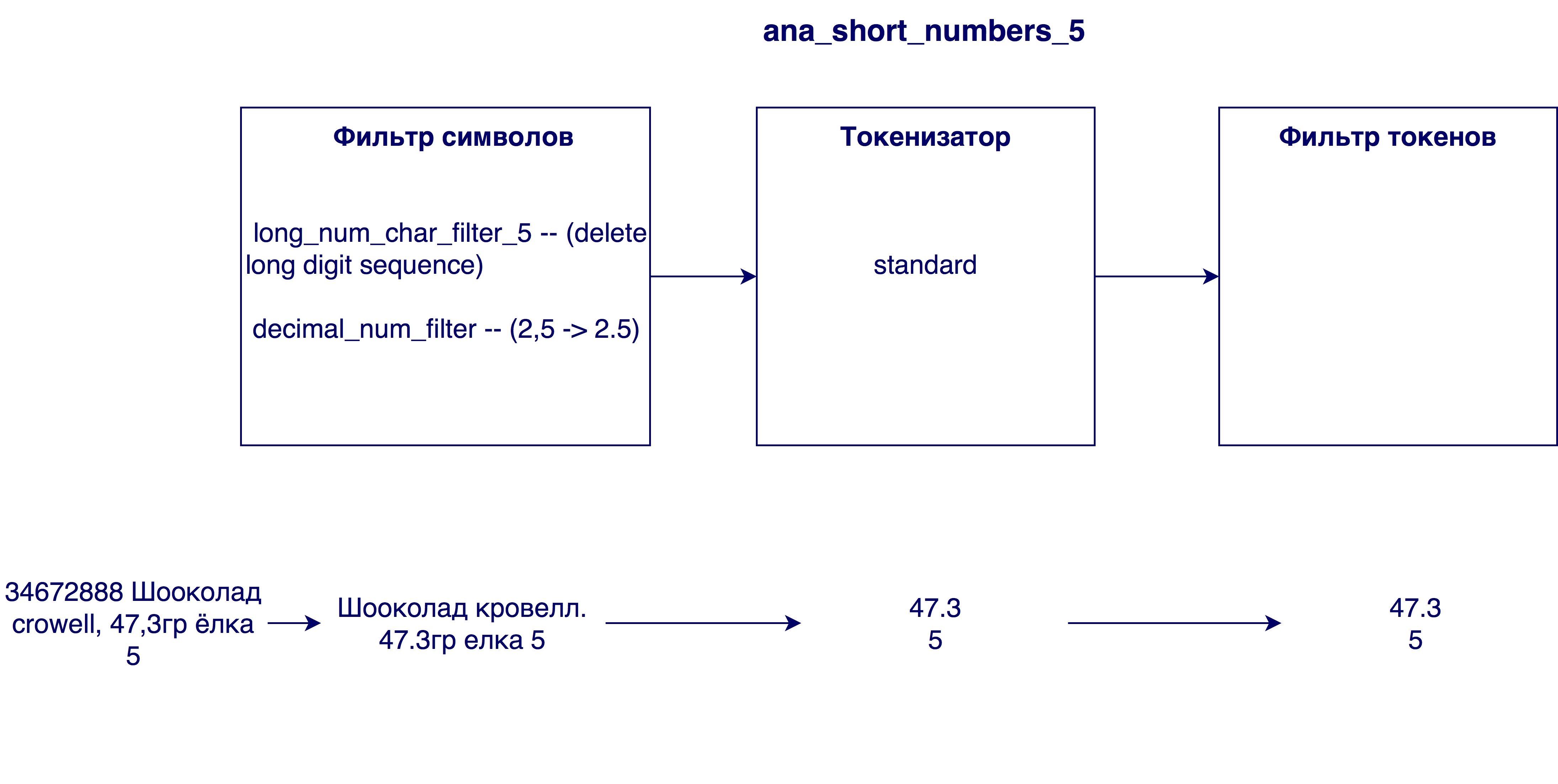
O modelo padrão (Okapi - BM25) com o parâmetro b = 0,5 foi escolhido como modelo de relevância. O valor padrão é 0,75. Este parâmetro mostra até que ponto o comprimento do nome do produto normaliza a variável tf (termo frequência). Um número menor, no nosso caso, funciona melhor, pois um nome longo geralmente não afeta o significado de uma única palavra. Ou seja, a palavra "chocolate" no nome "chocolate com avelãs trituradas em um pacote de 25 peças" não perde seu valor pelo fato de o nome ser longo o suficiente.
A consulta final é assim:
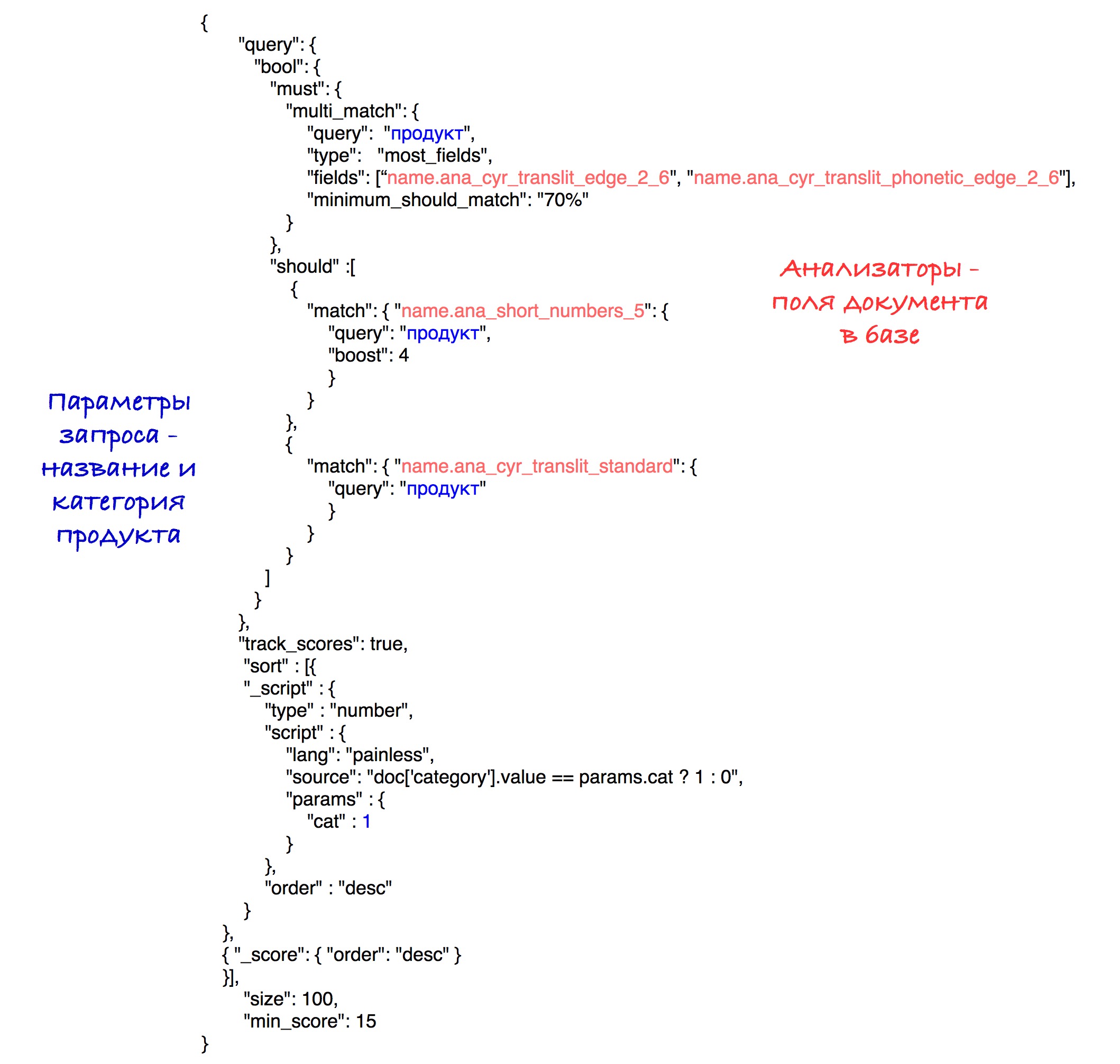
Experimentalmente, a melhor combinação de analisadores e pesos foi revelada.
Como resultado da classificação, os produtos com a mesma categoria vão para o início dos resultados e depois para todos os outros. A classificação pelo número de pontos (velocidade) é armazenada em cada subconjunto.
Por simplicidade, o limite de velocidade é definido como 15 nesta solicitação, embora em nosso sistema utilizemos o parâmetro calculado que foi descrito anteriormente.
No futuro
Pensamos em melhorar a pesquisa, resolvendo um dos problemas mais embaraçosos do nosso algoritmo, que é a existência de um milhão e uma maneira diferente de encurtar uma palavra de 5 letras. Pode ser resolvido pelo processamento inicial de nomes para revelar abreviações. Uma maneira de resolver isso é tentar comparar o nome abreviado do nosso banco de dados com um dos nomes do banco de dados com os nomes completos "corretos". Essa decisão encontra seus obstáculos definitivos, mas parece uma mudança promissora.